Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Поток данных 2-го поколения помогает легко формировать и преобразовывать данные. Он предлагает интерфейс с низким кодом и более 300 встроенных данных и преобразований искусственного интеллекта, на основе знакомых возможностей Power Query, которые вы найдете в Excel, Power BI, Power Platform и Dynamics 365.
При публикации потока данных создается определение, которое выполняется во время обновления. Модуль потока данных 2-го поколения использует это определение для планирования и управления выполнением запросов между источниками данных, шлюзами и вычислительными ядрами. Он создает таблицы в промежуточном хранилище или отправляет их в выбранный пункт назначения, поэтому вы получаете надежные результаты без тяжелой работы.
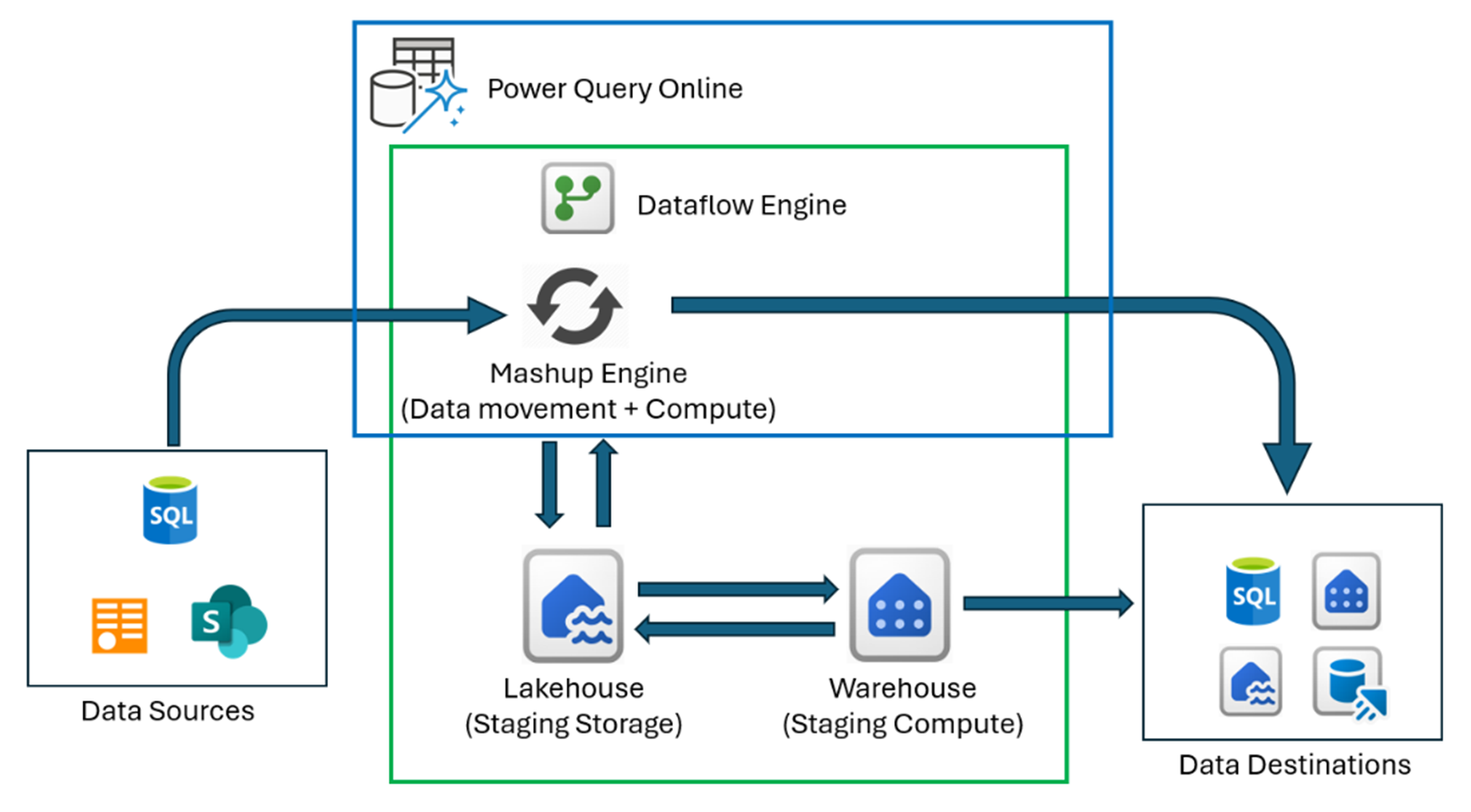
На диаграмме показаны компоненты архитектуры Data Factory Dataflow Gen2, включая Lakehouse, используемый для приема данных, и элемент Warehouse, используемый в качестве вычислительного двигателя для более быстрой записи результатов на промежуточный или выходной этап. Если не удается использовать вычислительные ресурсы хранилища или если промежуточное хранение отключено для запроса, модуль Mashup будет извлекать, преобразовывать или загружать данные в промежуточное хранение или места назначения данных. Дополнительные сведения о том, как работает поток данных 2-го поколения в этом блоге: Центр внимания фабрики данных: поток данных 2-го поколения.
При обновлении или публикации элемента потока данных 2-го поколения единицы емкости Fabric используются для следующих подсистем:
- Стандартные вычисления: плата взимается за это на основе времени оценки запросов во всех запросах потока данных, выполняемых через подсистему Mashup.
- Вычисления с высоким уровнем масштабируемости потоков данных: плата взимается при включении промежуточного хранения на основе длительности потребления SQL-движка хранилища Lakehouse (промежуточного хранилища) и хранилища Warehouse (вычислительных ресурсов).
- Быстрая копия: плата взимается при активации соединителей быстрого копирования, которые могут быть использованы в потоке данных. Начисление происходит за длительность выполнения задания копирования.
Модель ценообразования потока данных 2-го поколения
Как определяются цены
Цены на поток данных 2-го поколения зависят от того, как каждый запрос использует вычислительные ресурсы. Для стандартных вычислений запросы выполняются в системе mashup. В зависимости от того, является ли ваш поток данных Dataflow Gen2 (CI/CD), оценка будет различаться.
В Dataflow Gen2 (CI/CD) применяется двухуровневая ставка на продолжительность запроса.
- Если запрос выполняется менее чем за 10 минут, он оценивается на 12 CU
- Если он работает дольше, каждая дополнительная секунда рассчитывается по 1,5 CU.
Если ваша система Dataflow Gen2 не предназначена для CI/CD, то ставка 16 CU применяется ко всей длительности выполнения запроса.
Для высокомасштабируемых сценариев (при включении промежуточного хранения) запросы выполняются в подсистеме Lakehouse или Warehouse SQL. Каждая секунда времени вычислений использует 6 CU-секунд, поэтому более длительные запросы требуют больше ресурсов.
Если включить быстрое копирование, установлен отдельный тариф на перемещение данных: 1.5 CU в зависимости от продолжительности операции.
В конце каждого запуска Dataflow Gen2 суммирует использование CU из каждой машины и выставляет плату на основе ценообразования емкости Fabric в вашем регионе.
Таблица ставок CU
| Тип ядра Dataflow Gen2 | Счетчики потребления | Скорость потребления cu Fabric | Степень детализации отчетов о потреблении |
|---|---|---|---|
| Стандартные вычисления (поток данных 2-го поколения (CI/CD)) | На основе продолжительности выполнения каждого запроса в движке mashup в секундах. Стандартные вычисления имеют две ценовые категории в зависимости от длительности запроса. | — каждые секунды до 10 минут, 12 CU - За каждую секунду после 10 минут, 1,5 CU |
Элемент потока данных 2-го поколения |
| Стандартные вычисления (не CI/CD) | На основе продолжительности выполнения каждого запроса в движке mashup в секундах. | 16 вычислительных единиц (CU) | Элемент потока данных 2-го поколения |
| Масштабные вычисления потоков данных | На основе выполнения ядра SQL Lakehouse или Warehouse (с включенной промежуточной обработкой) длительность в секундах. | 6 CU | В расчете на рабочую область |
| Перемещение данных | На основе времени выполнения Fast Copy в секундах и используемых ресурсов интеллектуальной оптимизации. | 1.5 CU | Элемент потока данных 2-го поколения |
Цены на шлюз данных виртуальной сети с Dataflow Gen2
Шлюз данных виртуальной сети взимается как плата за аддитивную инфраструктуру, связанную с емкостью Fabric. Это означает, что у него есть собственный счетчик, и он получает счет, который последовательно применяется и является дополнительным ко всем запускам элементов Fabric.
Общий счет за выполнение потока данных 2-го поколения через шлюз данных виртуальной сети рассчитывается как плата за поток данных 2-го поколения и плата за шлюз данных виртуальной сети.
Плата за шлюз данных виртуальной сети пропорциональна использованию шлюза данных виртуальной сети, где использование определяется как время простоя или в любой момент, когда шлюз данных виртуальной сети включен.
Скорость потребления CU шлюза данных виртуальной сети: 4 CU
Дополнительные сведения см. в разделе "Цены на шлюзы данных виртуальной сети" и "Выставление счетов".
Изменения уровня потребления ресурсов в Microsoft Fabric
Ставки потребления в любое время изменяются. Корпорация Майкрософт использует разумные усилия для предоставления уведомлений по электронной почте и в продукте. Изменения вступают в силу в дату, указанную в замечаниях к выпуску и блоге Microsoft Fabric. Если любое изменение скорости потребления рабочей нагрузки Microsoft Fabric существенно увеличивает единицу емкости (CU), необходимую для использования определенной рабочей нагрузки, клиенты могут использовать варианты отмены, доступные для выбранного метода оплаты.
Вычисление предполагаемых затрат с помощью приложения метрик Fabric и журнала обновления потока данных
Приложение метрик емкости Microsoft Fabric обеспечивает видимость использования емкости для всех рабочих областей Fabric, привязанных к емкости. Он используется администраторами емкости для мониторинга производительности рабочих нагрузок и их использования по сравнению с приобретенной емкостью. Использование приложения метрик является наиболее точным способом оценки затрат на запуски обновления потока данных 2-го поколения. Чтобы понять, как многоуровневые цены повлияли на стандартные затраты на вычислительные ресурсы, также необходимо использовать журнал обновления потока данных.
В этих упражнениях показано, как проверить затраты на потоки данных CI/CD и не CI/CD. Для потока данных CI/CD со стандартными вычислениями мы будем использовать пример, и мы предоставим инструкции для всех остальных сценариев.
Упражнение 1. Стандартное вычисление для потока данных CI/CD
Следующий поток данных содержит два запроса, включающих преобразование, и промежуточный режим отключен.
Dataflow Gen2 будет использовать только стандартные вычисления.
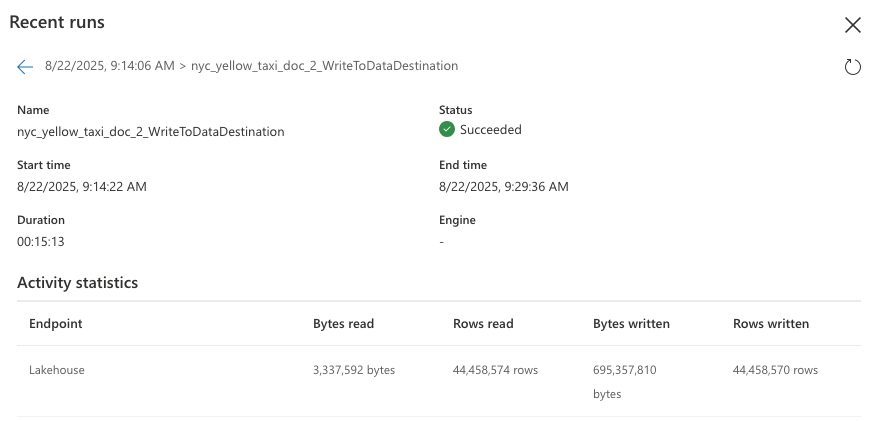
Для каждого запроса доступ к длительности запроса можно получить из журнала обновления, и затем примените следующую формулу для вычисления потребления CU для каждого запроса.
Для первого запроса длительность составляет 2131 секунды.
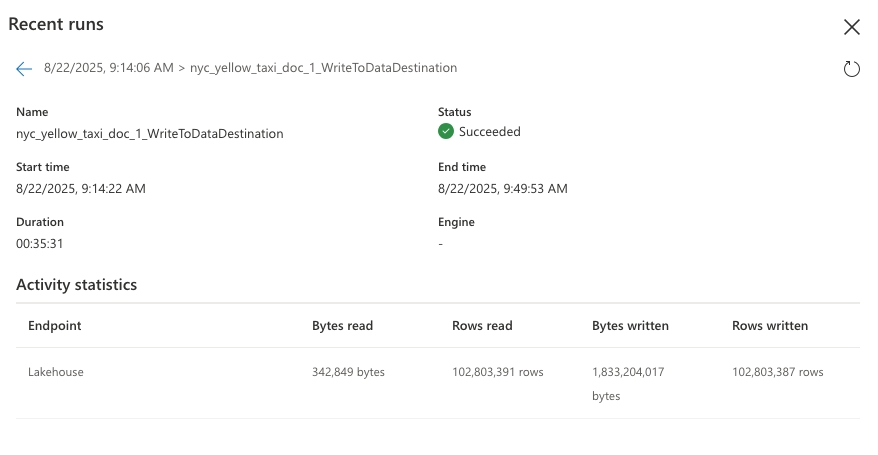
Аналогичным образом, для второго запроса длительность составляет 913 секунд
StandardComputeCapacityConsumptionInCUSeconds = if(QueryDurationInSeconds < 600, QueryDurationInSeconds x 12, (QueryDurationInSeconds - 600) x 1.5 + 600 x 12)
Для запроса 1 вычисленное потребление составляет 9497 CU секунд и для запроса 2 вычисленное потребление составляет 7670 секунд cu.
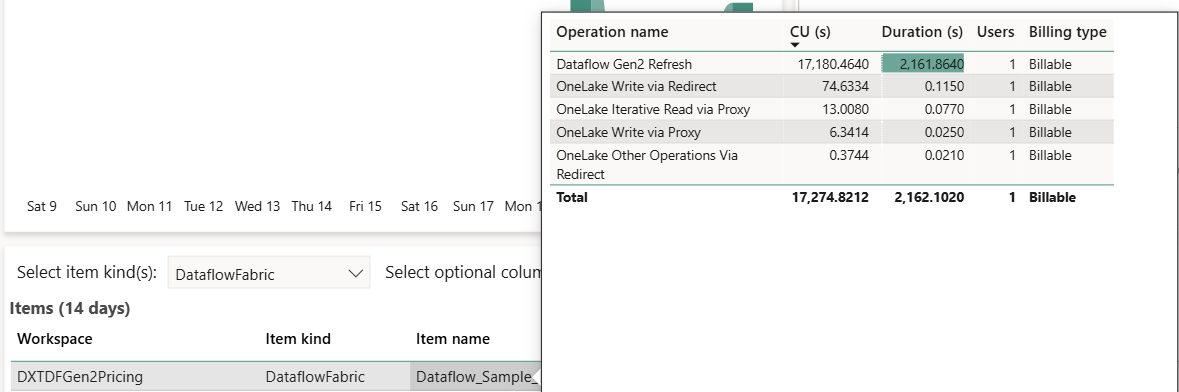
Агрегируйте потребление емкости в CU-секундах и проверьте потребление в приложении метрик емкости Fabric. В этом сценарии приложение метрик показывает 17 180 сек. CU как стандартное использование вычислительных ресурсов, которое хорошо сопоставляется с рассчитанным потреблением в 17 167 сек. CU. Любые несоответствия могут быть вызваны округлением в периодическом отчете об использовании.
Упражнение 2. Стандартное вычисление для потока данных, отличного от CI/CD
Если поток данных включает преобразование и промежуточный режим отключен, поток данных 2-го поколения будет использовать только стандартные вычисления.
Для каждого запроса доступ к длительности запроса можно получить из журнала обновления, и затем примените следующую формулу для вычисления потребления CU для каждого запроса.
StandardComputeCapacityConsumptionInCUSeconds = QueryDurationInSeconds x 16
Агрегируйте потребление емкости в CU-секундах и проверьте потребление в приложении метрик емкости Fabric.
Упражнение 3: Понимание высокомасштабируемого использования вычислительных ресурсов (как потоков данных CI/CD, так и не CI/CD-потоков данных)
Если в вашем потоке данных используется промежуточная среда, чтобы узнать, сколько вычислительной мощности High Scale вы использовали, откройте приложение Fabric для отслеживания метрик емкости и отфильтруйте по имени вашего потока данных. Щелкните правой кнопкой мыши имя, найдите высокомасштабируемые вычисления в списке операций и проверьте длительность.
HighScaleComputeCapacityConsumptionInCUSeconds = QueryDurationInSeconds x 6
Упражнение 4. Понимание быстрого использования вычислительных ресурсов копирования (как CI/CD, так и не CI/CD)
Если в потоке данных используется быстрая копия, чтобы узнать, сколько вычислительных ресурсов перемещения данных вы использовали, откройте приложение Fabric Capacity Metrics и отфильтруйте данные по имени вашего потока данных. Щелкните правой кнопкой мыши по имени, найдите в списке операций «Перемещение данных» и проверьте его длительность.
FastCopyComputeCapacityConsumptionInCUSeconds = QueryDurationInSeconds x 1.5