Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Модель Azure OpenAI gpt-4o можно использовать для преобразования эскиза или диаграммы на доске в рабочий конвейер в Data Factory в Microsoft Fabric. В этой статье описывается отправка образа в Lakehouse, его анализ с помощью gpt-4o и создание конвейера из созданного JSON с помощью интерфейсов REST API Fabric.
Prerequisites
Перед созданием решения убедитесь, что в Azure и Fabric настроены следующие предварительные требования:
- Рабочая область с поддержкой Microsoft Fabric.
- Учетная запись Azure OpenAI с ключом API и развернутой
gpt-4oмоделью. - Изображение того, как выглядит конвейер.
Предупреждение
Ключи API — это конфиденциальная информация, а рабочие ключи всегда должны храниться безопасно в Azure Key Vault или других безопасных хранилищах. В этом примере используется ключ OpenAI только для демонстрационных целей. Для рабочего кода рекомендуется использовать идентификатор Microsoft Entra вместо проверки подлинности ключа для более безопасной среды, которая не зависит от общего доступа к ключам или риска нарушения безопасности, если ключ скомпрометирован.
Шаг 1. Отправка изображения в Lakehouse
Прежде чем проанализировать изображение, необходимо загрузить его в Lakehouse. Войдите в учетную запись Microsoft Fabric и перейдите в рабочую область. Выберите + Новый элемент и создайте новый Lakehouse.
После настройки Lakehouse создайте новую папку под файлами, называемыми изображениями, и отправьте его туда.

Шаг 2. Создание записной книжки в рабочей области
Теперь необходимо создать записную книжку для выполнения кода Python, который суммирует и создает конвейер в рабочей области.
Создайте записную книжку в рабочей области:
В области кода введите следующий код, который настраивает необходимые библиотеки и конфигурацию и кодирует изображение:
# Configuration
AZURE_OPENAI_KEY = "<Your Azure OpenAI key>"
AZURE_OPENAI_GPT4O_ENDPOINT = "<Your Azure OpenAI gpt-4o deployment endpoint>"
IMAGE_PATH = "<Path to your uploaded image file>" # For example, "/lakehouse/default/files/images/pipeline.png"
# Install the OpenAI library
!pip install semantic-link --q
!pip uninstall --yes openai
!pip install openai
%pip install openai --upgrade
# Imports
import os
import requests
import base64
import json
import time
import pprint
import openai
import sempy.fabric as fabric
import pandas as pd
# Load the image
image_bytes = open(IMAGE_PATH, 'rb').read()
encoded_image = base64.b64encode(image_bytes).decode('ascii')
## Request headers
headers = {
"Content-Type": "application/json",
"api-key": AZURE_OPENAI_KEY,
}
Выполните этот блок кода, чтобы настроить среду.
Шаг 3. Использование gpt-4o для описания конвейера (необязательно)
Этот шаг является необязательным, но показывает, насколько просто извлечь сведения из изображения, которые могут быть актуальными для ваших целей. Если вы не выполните этот шаг, можно будет создать файл JSON конвейера на следующем этапе.
Сначала нажмите кнопку "Изменить " в главном меню записной книжки, а затем нажмите кнопку +Добавить ячейку кода ниже на панели инструментов, чтобы добавить новый блок кода после предыдущего.
Затем добавьте следующий код в новый раздел. В этом коде показано, как gpt-4o интерпретировать и суммировать изображение, чтобы понять его содержимое.
# Summarize the image
## Request payload
payload = {
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant that helps an Azure engineer understand an image that likely shows a Data Factory in Microsoft Fabric pipeline. Show list of pipeline activities and how they are connected."
}
]
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
}
}
]
}
],
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 800
}
## Send request
try:
response = requests.post(AZURE_OPENAI_GPT4O_ENDPOINT, headers=headers, json=payload)
response.raise_for_status() # Will raise an HTTPError if the HTTP request returned an unsuccessful status code
except requests.RequestException as e:
raise SystemExit(f"Failed to make the request. Error: {e}")
response_json = response.json()
## Show AI response
print(response_json["choices"][0]['message']['content'])
Запустите этот блок кода, чтобы просмотреть сводку ИИ изображения и его компонентов.
Шаг 4. Создание JSON конвейера
Добавьте в записную книжку еще один блок кода и добавьте следующий код. Этот код анализирует изображение и генерирует JSON для конвейера.
# Analyze the image and generate the pipeline JSON
## Setup new payload
payload = {
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant that helps an Azure engineer understand an image that likely shows a Data Factory in Microsoft Fabric pipeline. Succeeded is denoted by a green line, and Fail is denoted by a red line. Generate an ADF v2 pipeline JSON with what you see. Return ONLY the JSON text required, without any leading or trailing markdown denoting a code block."
}
]
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
}
}
]
}
],
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 800
}
## Send request
try:
response = requests.post(AZURE_OPENAI_GPT4O_ENDPOINT, headers=headers, json=payload)
response.raise_for_status() # Will raise an HTTPError if the HTTP request returned an unsuccessful status code
except requests.RequestException as e:
raise SystemExit(f"Failed to make the request. Error: {e}")
## Get JSON from request and show
response_json = response.json()
pipeline_json = response_json["choices"][0]['message']['content']
print(pipeline_json)
Запустите этот блок кода, чтобы создать JSON пайплайна из изображения.
Шаг 5. Создание конвейера с помощью интерфейсов REST API Fabric
Теперь, когда вы получили JSON конвейера, его можно создать непосредственно с помощью REST API Fabric. Добавьте в записную книжку еще один блок кода и добавьте следующий код. Этот код создает конвейер в рабочей области.
# Convert pipeline JSON to Fabric REST API request
json_data = json.loads(pipeline_json)
# Extract the activities from the JSON
activities = json_data["properties"]["activities"]
# Prepare the pipeline JSON definition
data = {}
activities_list = []
idx = 0
# Name mapping used to track activity name found in image to dynamically generated name
name_mapping = {}
for activity in activities:
idx = idx + 1
activity_name = activity["type"].replace("Activity","")
objName = f"{activity_name}{idx}"
# store the name mapping so we can deal with dependency
name_mapping[activity["name"]] = objName
if 'dependsOn' in activity:
activity_dependent_list = activity["dependsOn"]
dependent_activity = ""
if ( len(activity_dependent_list) > 0 ):
dependent_activity = activity_dependent_list[0]["activity"]
match activity_name:
case "Copy":
activities_list.append({'name': objName, 'type': "Copy", 'dependsOn': [],
'typeProperties': { "source": { "datasetSettings": {} },
"sink": { "datasetSettings": {} } }})
case "Web":
activities_list.append({'name': objName, 'type': "Office365Outlook",
"dependsOn": [
{
"activity": name_mapping[dependent_activity] ,
"dependencyConditions": [
"Succeeded"
]
}
]
}
)
case "ExecutePipeline":
activities_list.append({'name': "execute pipeline 1", 'type': "ExecutePipeline",
"dependsOn": [
{
"activity": name_mapping[dependent_activity] ,
"dependencyConditions": [
"Succeeded"
]
}
]
}
)
case _:
continue
else:
# simple activities with no dependencies
match activity_name:
case "Copy":
activities_list.append({'name': objName, 'type': "Copy", 'dependsOn': [],
'typeProperties': { "source": { "datasetSettings": {} } , "sink": { "datasetSettings": {} } }})
case "SendEmail":
activities_list.append({'name': "Send mail on success", 'type': "Office365Outlook"})
case "Web":
activities_list.append({'name': "Send mail on success", 'type': "Office365Outlook"})
case "ExecutePipeline":
activities_list.append({'name': "execute pipeline 1", 'type': "ExecutePipeline"})
case _:
print("NoOp")
# Now that the activities_list is created, assign it to the activities tag in properties
data['properties'] = { "activities": activities_list}
# Convert data from dict to string, then Byte Literal, before doing a Base-64 encoding
data_str = str(data).replace("'",'"')
createPipeline_json = data_str.encode(encoding="utf-8")
createPipeline_Json64 = base64.b64encode(createPipeline_json)
# Create a new pipeline in Fabric
timestr = time.strftime("%Y%m%d-%H%M%S")
pipelineName = f"Pipeline from image with AI-{timestr}"
payload = {
"displayName": pipelineName,
"type": "DataPipeline",
"definition": {
"parts": [
{
"path": "pipeline-content.json",
"payload": createPipeline_Json64,
"payloadType": "InlineBase64"
}
]
}
}
print(f"Creating pipeline: {pipelineName}")
# Call the Fabric REST API to generate the pipeline
client = fabric.FabricRestClient()
workspaceId = fabric.get_workspace_id()
try:
response = client.post(f"/v1/workspaces/{workspaceId}/items",json=payload)
if response.status_code != 201:
raise FabricHTTPException(response)
except WorkspaceNotFoundException as e:
print("Workspace is not available or cannot be found.")
except FabricHTTPException as e:
print(e)
print("Fabric HTTP Exception. Check that you have the correct Fabrric API endpoints.")
response = client.get(f"/v1/workspaces/{workspaceId}/Datapipelines")
df_items = pd.json_normalize(response.json()['value'])
print("List of pipelines in the workspace:")
df_items
Выходные данные подтверждают имя созданного конвейера и показывают список конвейеров вашей рабочей области, чтобы вы могли убедиться в его наличии.
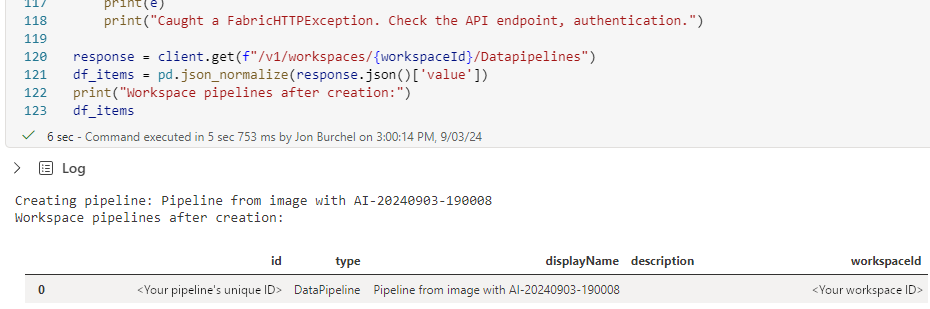
Шаг 6. Использование конвейера
После создания потока обработки его можно изменить в рабочей области Fabric, чтобы увидеть, как образ реализуется в виде потока обработки. Вы можете выбрать каждое действие, чтобы настроить его, а затем запустить и отслеживать его по мере необходимости.
