Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Быстрое копирование помогает быстрее перемещать большие объемы данных в потоке данных 2-го поколения. Думайте об этом, как переключение на более мощный механизм, когда необходимо обрабатывать терабайты данных.
При работе с потоками данных сначала необходимо принять данные, а затем преобразовать их. С помощью горизонтального масштабирования потока данных с помощью вычислений хранилища данных SQL можно преобразовать данные в большом масштабе. Быстрая копия обеспечивает обработку, предоставляя простой поток данных с мощной серверной частью компонента копирования конвейера.
Вот как это работает: после включения быстрого копирования потоки данных автоматически переключаются на более быструю серверную часть, когда размер данных проходит определенное пороговое значение. При создании потоков данных не нужно ничего изменять. После обновления потока данных можно проверить журнал обновления, чтобы узнать, используется ли быстрая копия, глядя на тип движка, указанный там.
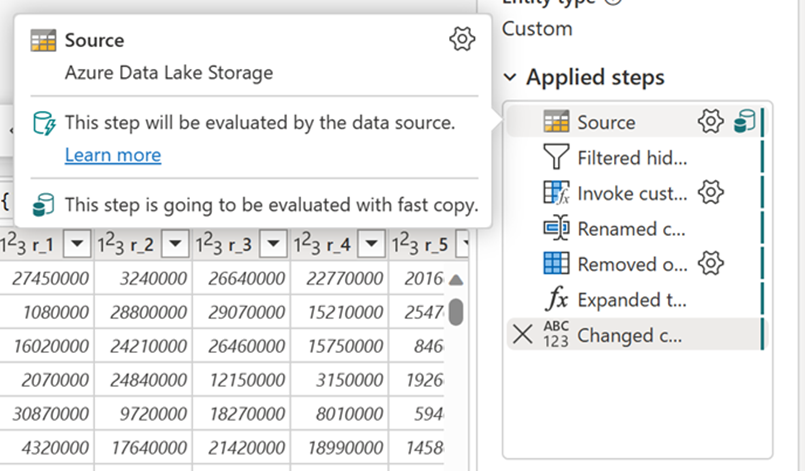
Если включить параметр "Требовать быструю копию ", обновление потока данных останавливается, если быстрая копия не может использоваться по какой-либо причине. Это помогает избежать тайм-аута и может оказаться полезным при отладке. Индикаторы быстрого копирования в области шагов запроса можно использовать, чтобы проверить возможность выполнения запроса с помощью быстрой копии.
Prerequisites
Прежде чем использовать быструю копию, вам потребуется:
- Емкость Fabric
- Для файловых данных: CSV-файлы или файлы Parquet размером от 100 МБ и больше, хранящиеся в хранилище Azure Data Lake Storage (ADLS) Gen2 или BLOB-хранилище
- Для баз данных (включая базу данных SQL Azure и PostgreSQL): 5 миллионов строк или больше данных в источнике данных
Note
Пороговое значение можно обойти, чтобы принудительно скопировать, выбрав параметр "Требовать быструю копию ".
Поддержка соединителя
Быстрое копирование работает с этими соединителями Dataflow Gen2:
- ADLS Gen2
- Хранилище данных типа BLOB
- База данных SQL Azure
- Lakehouse
- PostgreSQL
- Локальный SQL Server
- Warehouse
- Oracle
- Snowflake
- База данных SQL в Fabric
Ограничения преобразования
При подключении к источникам файлов действие копирования поддерживает только следующие преобразования:
- Объединение файлов
- Выбор столбцов
- Изменение типов данных
- Переименование столбца
- Удаление столбца
Если вам нужны другие преобразования, вы можете разделить работу на отдельные запросы. Создайте один запрос, чтобы получить данные и другой запрос, ссылающийся на первый. Таким образом, вы можете использовать вычислительные ресурсы DW для преобразований.
Для источников SQL любая трансформация, которая является частью собственного запроса, работает хорошо.
Назначения выходных данных
Сейчас быстрая копия поддерживает только загрузку непосредственно в место назначения Lakehouse. Если вы хотите использовать другое назначение выходных данных, сначала можно выполнить запрос и ссылаться на него в последующем запросе с предпочитаемым назначением.
Как использовать быструю копию
Вот как настроить и использовать быструю копию:
В Fabric перейдите в рабочую область премиум и создайте Dataflow Gen2.
На вкладке "Главная" нового потока данных выберите "Параметры":
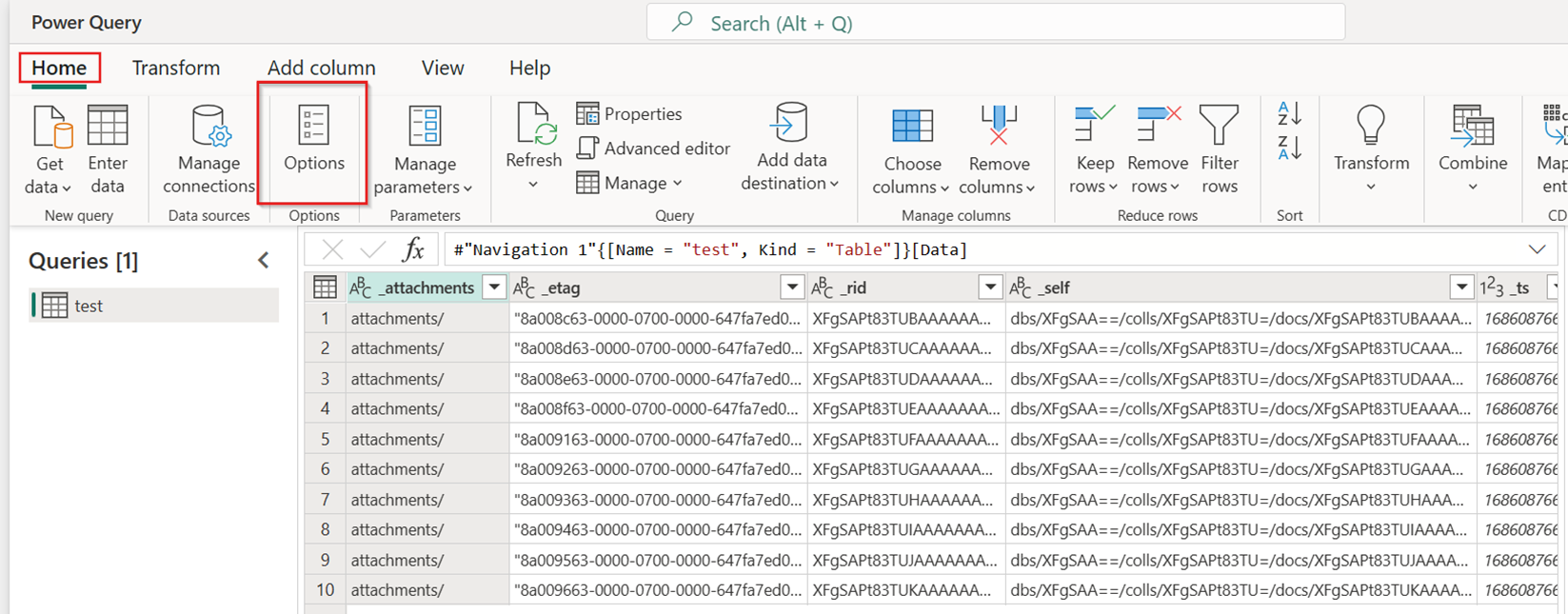
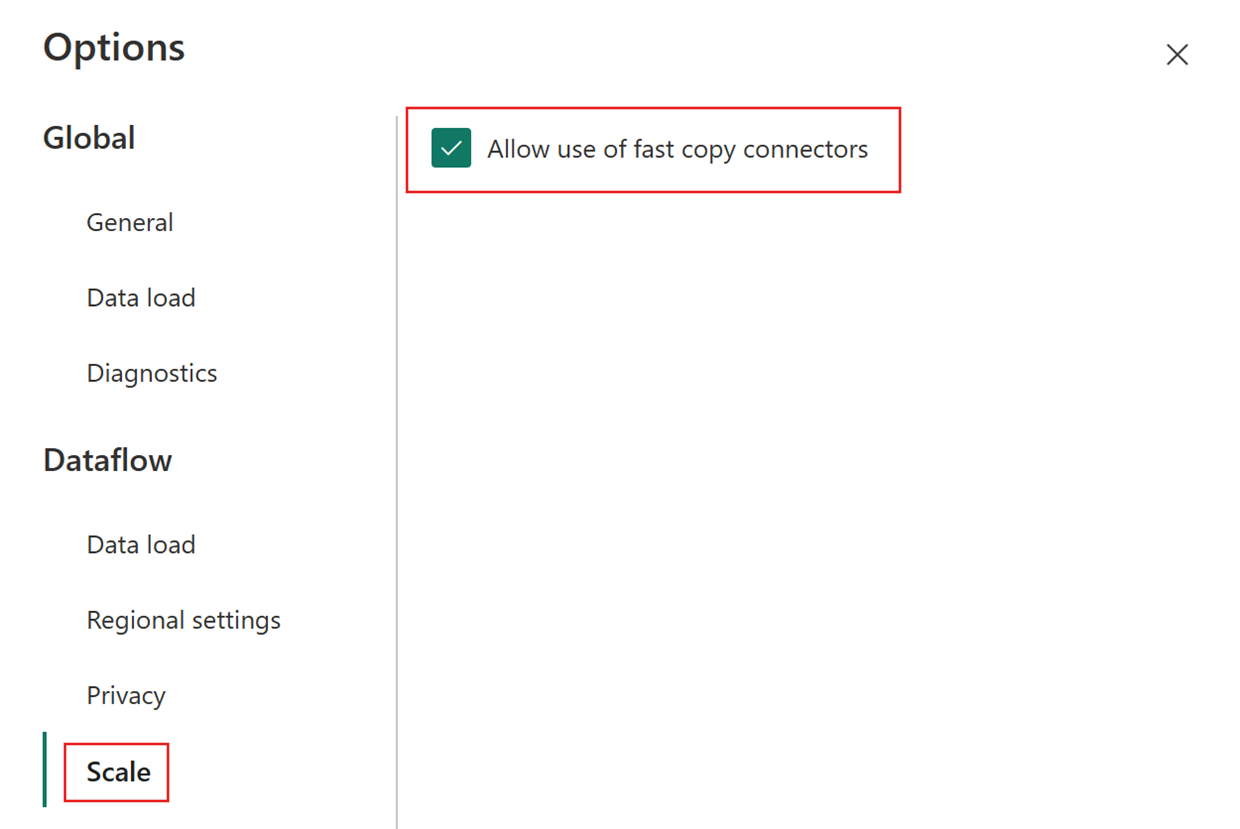
В диалоговом окне "Параметры " выберите вкладку "Масштаб ", а затем включите включение быстрого использования соединителей копирования. Закройте диалоговое окно "Параметры " после завершения.
Выберите "Получить данные", выберите источник ADLS 2-го поколения и укажите сведения о контейнере.
Нажмите кнопку "Объединить ".
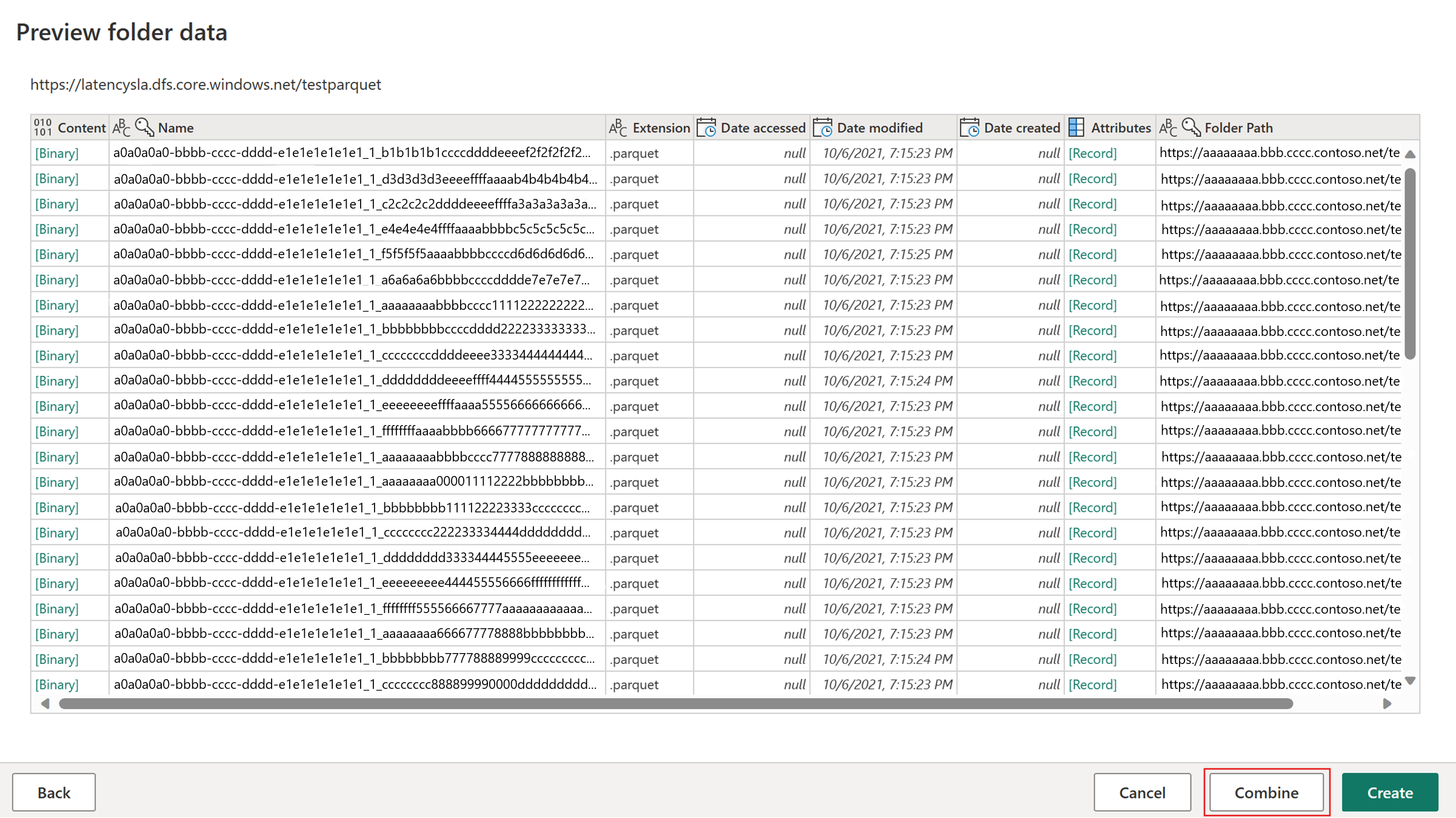
Чтобы убедиться, что быстрая копия работает, применяются только преобразования, перечисленные в разделе поддержки соединителя . Если вам нужны другие преобразования, сначала выполните этапный запрос и наведите ссылку на промежуточный запрос в последующем запросе. Примените другие преобразования к запросу, на который ссылается ссылка.
(Необязательно) Вы можете требовать быструю копию для запроса, щелкнув правой кнопкой мыши по запросу и выбрав Требовать быструю копию.
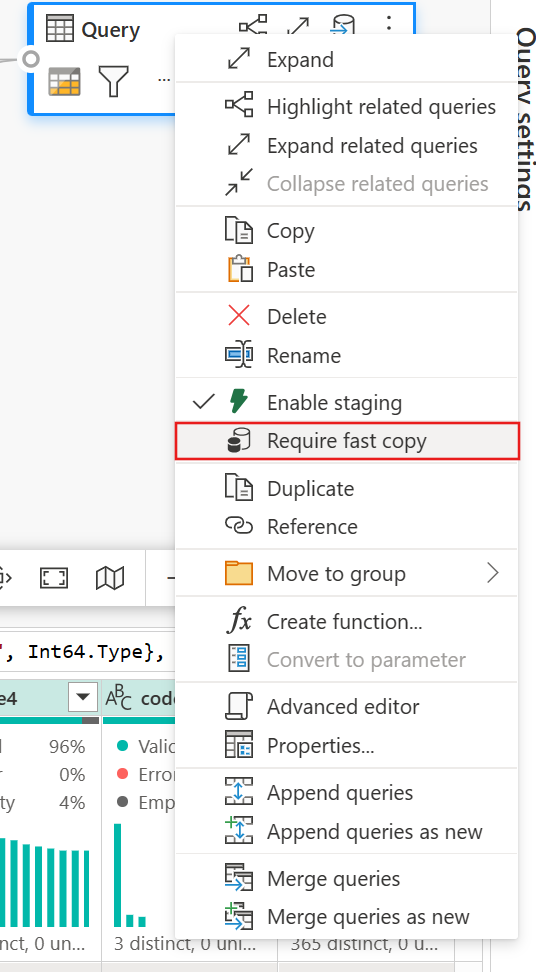
(Необязательно) Сейчас вы можете настроить только Lakehouse в качестве назначения вывода. Для любого другого назначения подготовьте запрос, чтобы позже использовать его в другом запросе, где можно вывести данные в любой источник.
Проверьте индикаторы быстрого копирования, чтобы убедиться, что запрос может выполняться с быстрым копированием. Если это может, тип Engine отображает CopyActivity.

Опубликуйте поток данных.
После завершения обновления проверьте, используется ли быстрая копия.



Как разделить запрос для использования быстрого копирования
При работе с большими объемами данных можно получить лучшую производительность, используя быстрое копирование для приема данных на промежуточный этап, а затем преобразовать его в крупном масштабе с помощью вычислительных возможностей SQL DW.
Индикаторы быстрого копирования помогают понять, как распределить выполнение запроса на две части: загрузку данных в область промежуточной обработки и крупномасштабное преобразование с использованием вычислительных ресурсов хранилища данных SQL DW. Попробуйте перенести как можно больше оценки запросов в быстрый копирование для оптимизации приема данных. Когда индикаторы быстрого копирования показывают, что оставшиеся шаги не могут выполняться с быстрым копированием, можно разделить остальную часть запроса с включенным промежуточным режимом.
Индикаторы диагностики шагов
| Indicator | Icon | Description |
|---|---|---|
| Этот шаг будет оцениваться с помощью оперативного копирования | 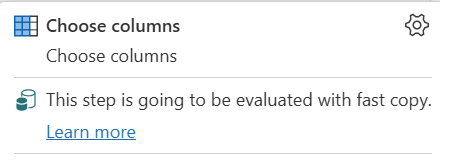
|
Индикатор быстрого копирования показывает, что запрос до этого шага поддерживает быструю копию. |
| Этот шаг не поддерживается функцией «быстрое копирование» | 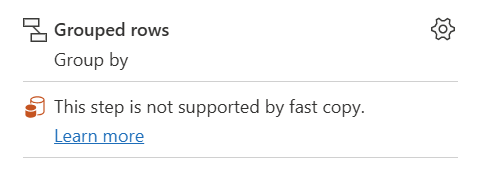
|
Индикатор быстрого копирования показывает, что этот шаг не поддерживает быструю копию. |
| Один или несколько шагов в запросе не поддерживаются функцией быстрого копирования | 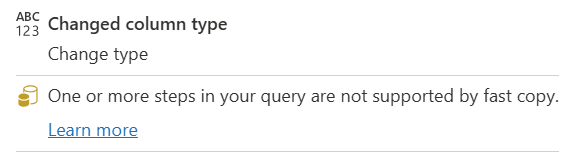
|
Индикатор быстрого копирования показывает, что некоторые шаги в этом запросе поддерживают быструю копию, а другие — нет. Чтобы оптимизировать, разделите запрос на желтые шаги (потенциально поддерживаемые быстрой копией) и красные шаги (не поддерживаемые). |
Пошаговое руководство
После завершения логики преобразования данных в Dataflow 2-го поколения индикатор быстрого копирования оценивает каждый шаг, чтобы выяснить, сколько шагов может использовать быстрое копирование для повышения производительности.
В этом примере на последнем шаге показан красный значок, что означает, что шаг Группировка по не поддерживается быстрым копированием. Однако все предыдущие шаги с желтыми значками могут поддерживаться методом быстрого копирования.

Если вы публикуете и запускаете поток данных 2-го поколения на этом этапе, он не будет использовать модуль быстрого копирования для загрузки данных.

Чтобы использовать движок быстрого копирования и повысить производительность Dataflow Gen2, вы можете разделить ваш запрос на две части: прием данных для промежуточного хранения и крупномасштабного преобразования с помощью вычислений SQL DW. Это делается следующим образом:
Удалите все преобразования, показывающие красные значки (это означает, что они не поддерживаются быстрой копией) вместе с назначением (если вы определили его).
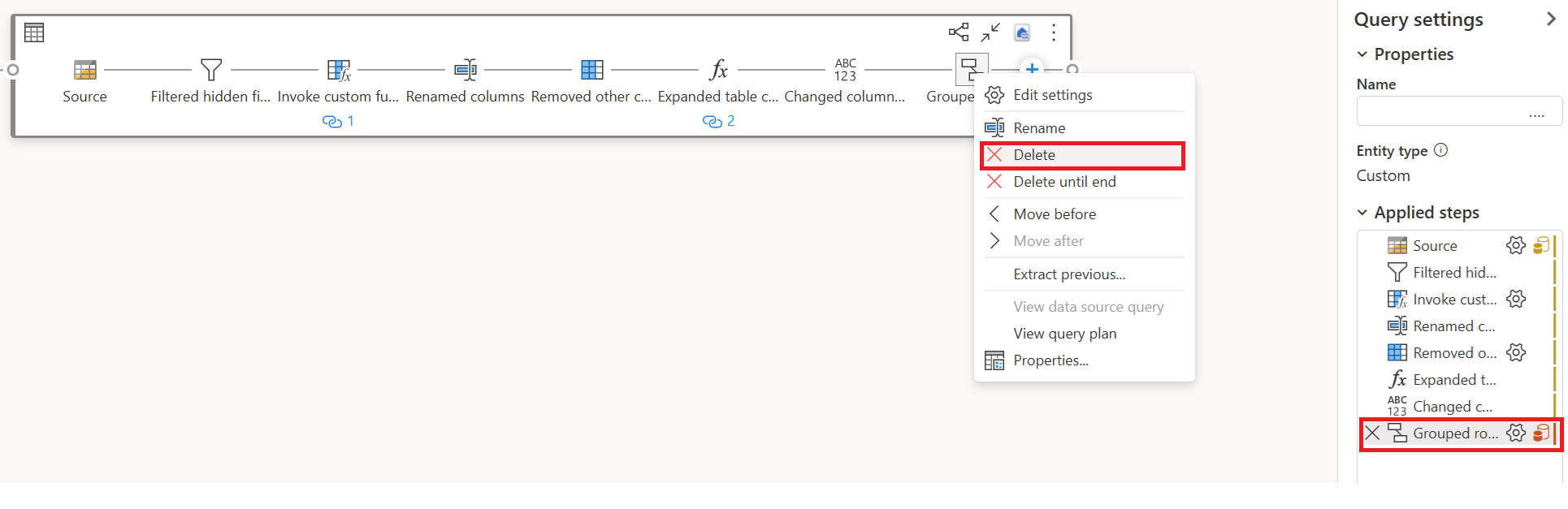
Индикатор быстрого копирования теперь отображается зеленым цветом для оставшихся шагов, что означает, что первый запрос может использовать быструю копию для повышения производительности.
Щелкните правой кнопкой мыши свой первый запрос, выберите "Включить промежуточный этап", затем снова щелкните правой кнопкой мыши на своем первом запросе и выберите Ссылка.
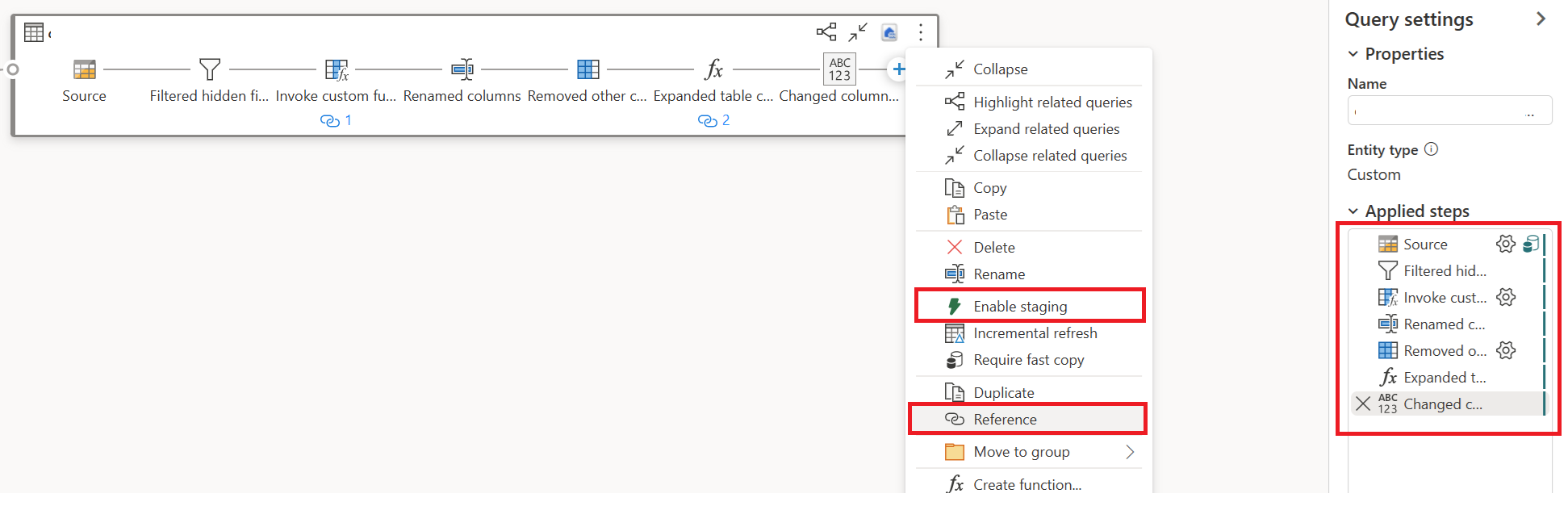
В вашем новом ссылочном запросе добавьте трансформацию "Group By" и пункт назначения (если применимо).
Публикация и обновление потока данных 2-го поколения. Теперь у вас есть два запроса в потоке данных 2-го поколения, а общая длительность короче.
Первый запрос загружает данные в промежуточное хранилище с использованием быстрого копирования.
Второй запрос выполняет крупномасштабные преобразования с помощью вычислений DW SQL.
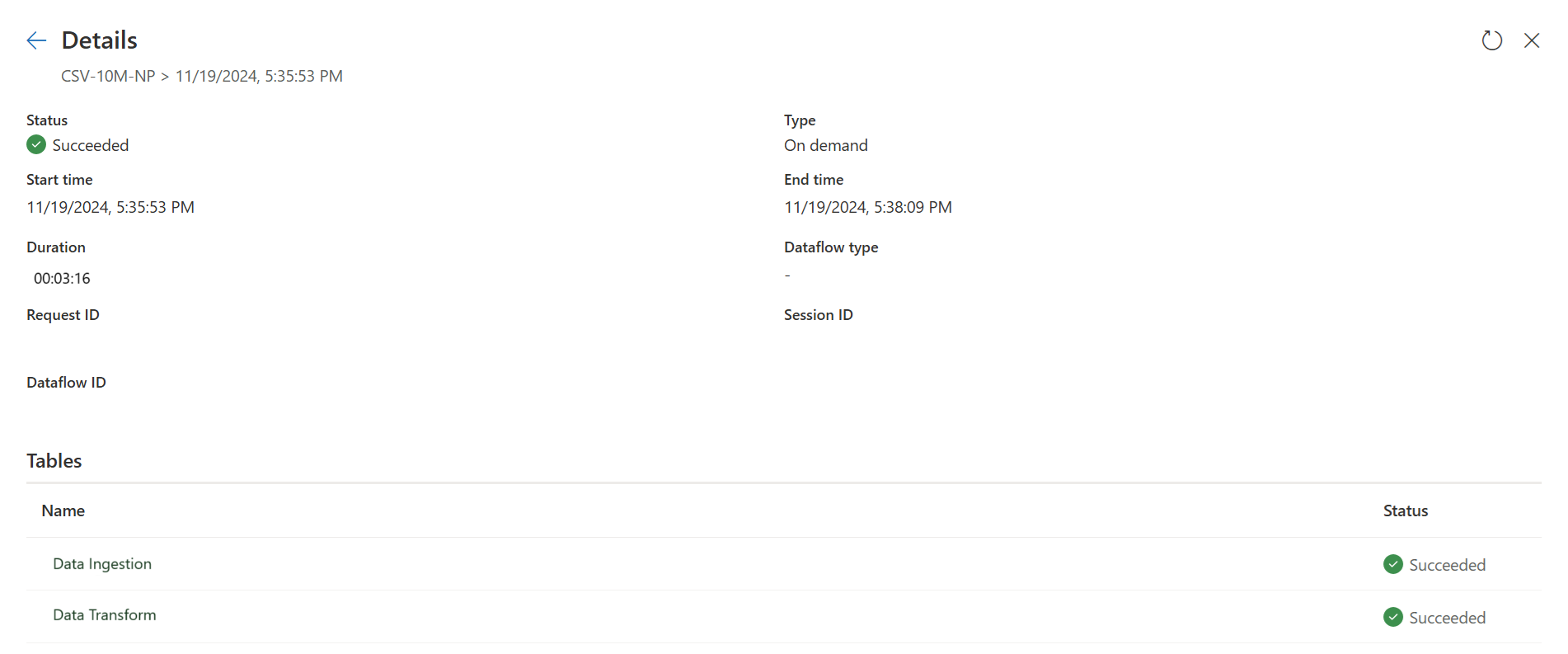
Первые сведения о запросе:
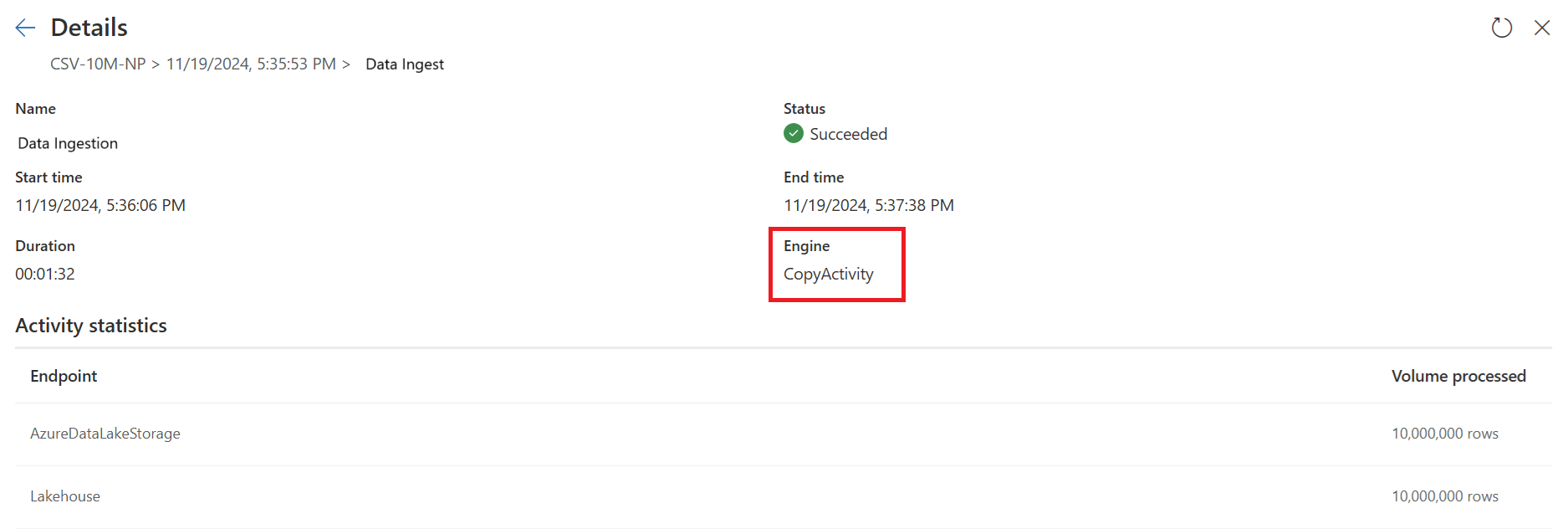
Подробности второго запроса:
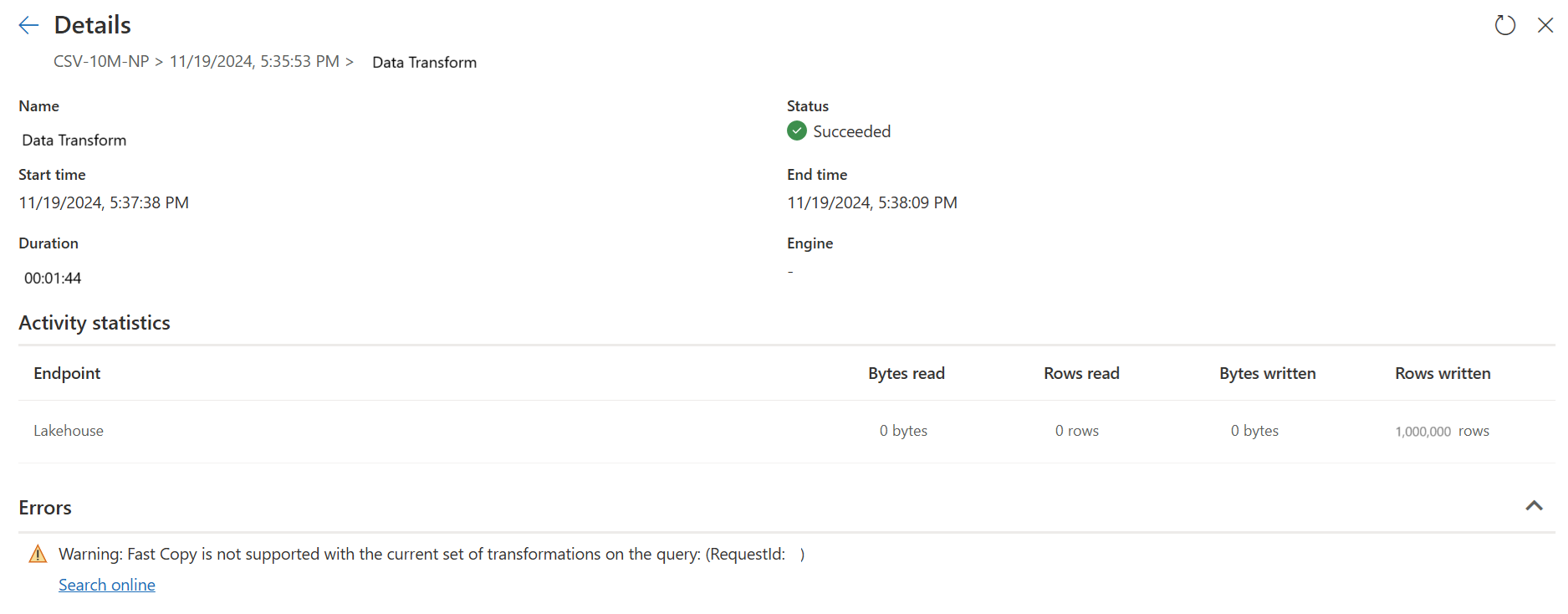




Известные ограничения
Ниже приведены текущие ограничения для быстрого копирования:
- Для поддержки быстрого копирования требуется локальный шлюз данных версии 3000.214.2 или более поздней версии.
- Жёсткая схема не поддерживается.
- Назначение пункта на основе схемы не поддерживается