Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
После очистки и подготовки данных с помощью потока данных 2-го поколения вы захотите сохранить его где-то полезно. Поток данных 2-го поколения позволяет выбирать из нескольких направлений, таких как SQL Azure, Fabric Lakehouse и другие. После выбора места назначения Dataflow Gen2 записывает ваши данные туда, и их можно использовать для анализа и создания отчетов.
Следующий список содержит поддерживаемые места назначения данных.
- Базы данных SQL Azure
- Azure Data Explorer (Kusto)
- Azure Datalake 2-го поколения
- Таблицы Fabric Lakehouse
- Файлы Fabric Lakehouse
- Склад Fabric
- База данных KQL Fabric
- База данных SQL Fabric
- Файлы SharePoint
- База данных Snowflake
Примечание.
Чтобы загрузить данные в Fabric Warehouse, вы можете использовать коннектор Azure Synapse Analytics (SQL Data Warehouse), получив строку подключения для SQL. Дополнительные сведения: подключение к хранилищу данных в Microsoft Fabric
Точки входа
Каждый запрос данных в Dataflow второго поколения может иметь пункт назначения данных. К табличным запросам можно применять только места назначения, так как функции и списки не поддерживаются. Вы можете задать назначение данных для каждого запроса по отдельности, и вы можете использовать разные назначения в одном потоке данных.
Существует три способа настройки назначения данных:
Через верхнюю ленту.
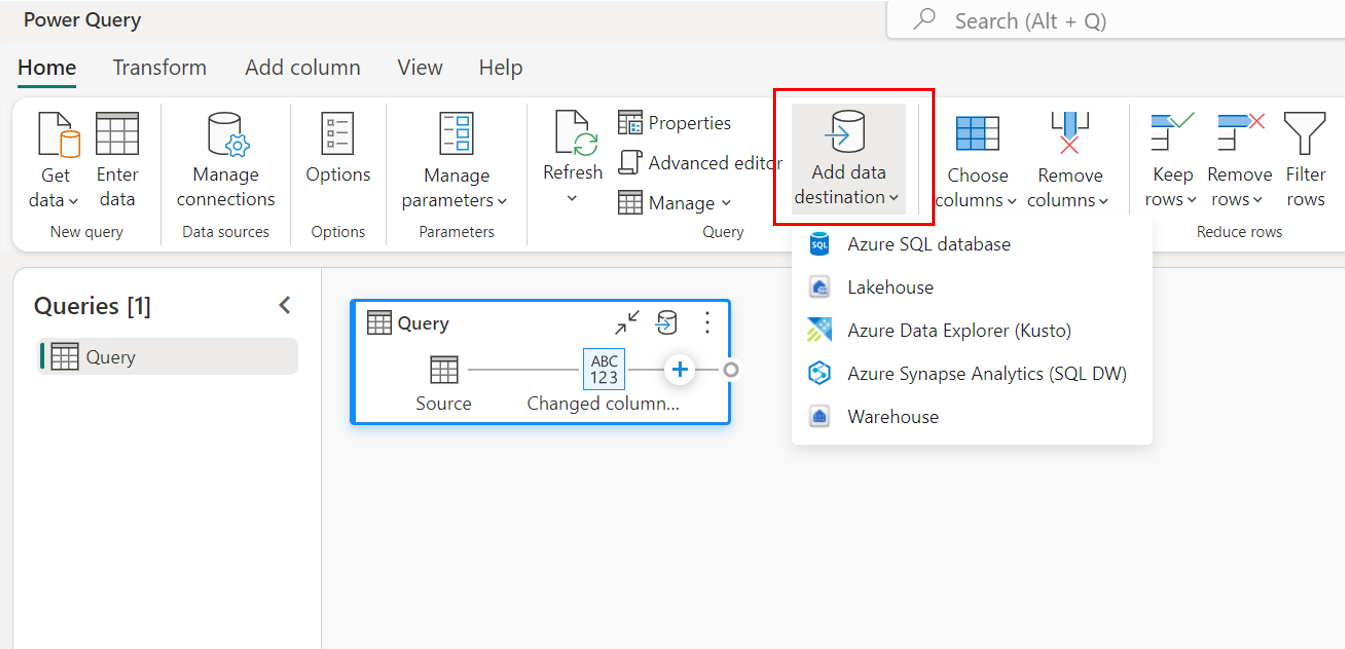
С помощью параметров запроса.
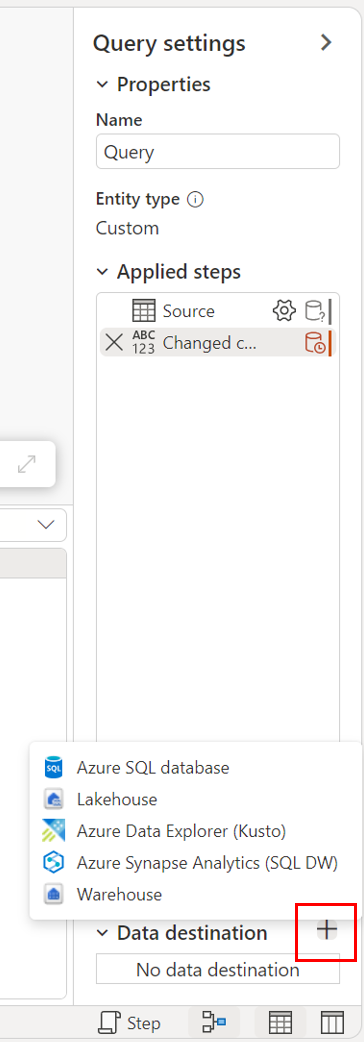
С помощью представления схемы.
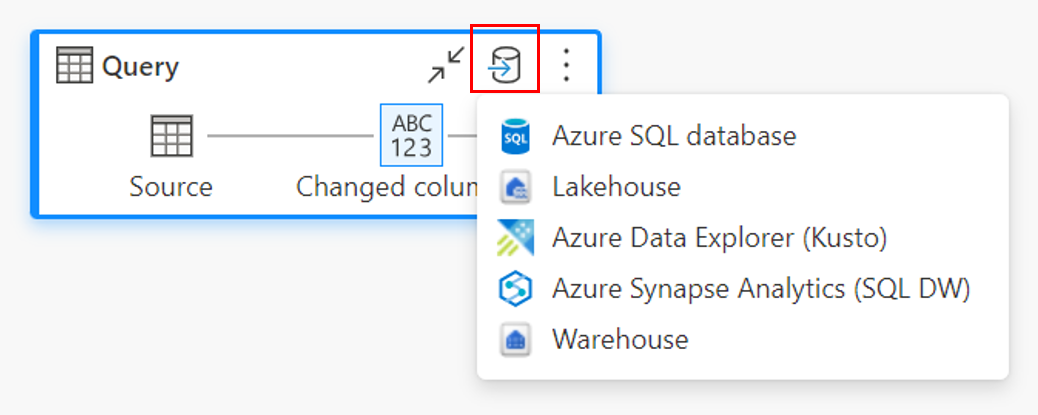
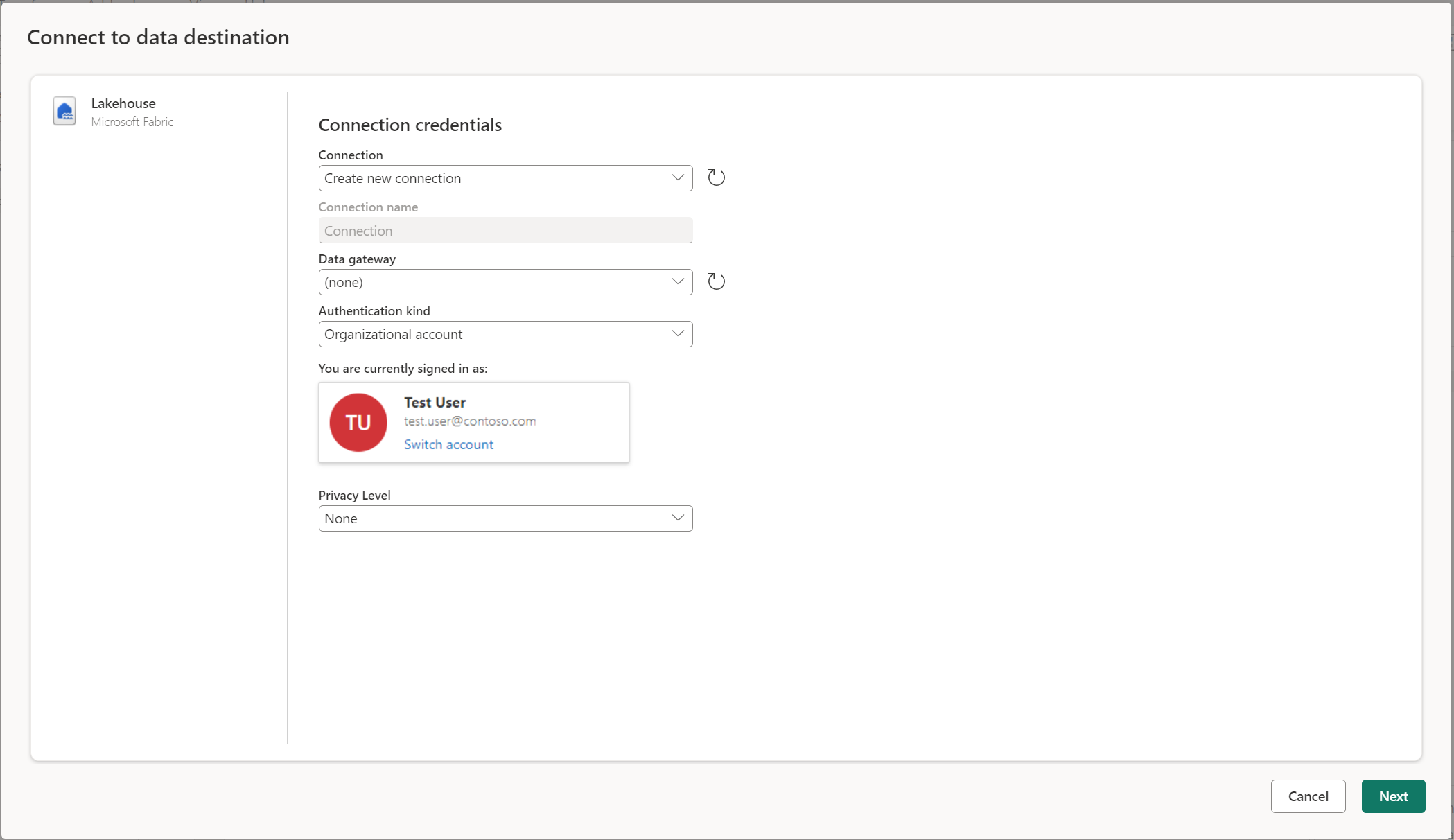
Подключение к назначению данных
Подключение к назначению данных работает так же, как подключение к источнику данных. Подключения можно использовать как для чтения, так и записи данных, если у вас есть правильные разрешения на источник данных. Вам потребуется создать новое подключение или выбрать существующую, а затем нажмите кнопку "Далее".
Настроить точки назначения на основе файлов
При выборе назначения на основе файлов (например, SharePoint) необходимо настроить параметры в зависимости от выбранного формата файла.
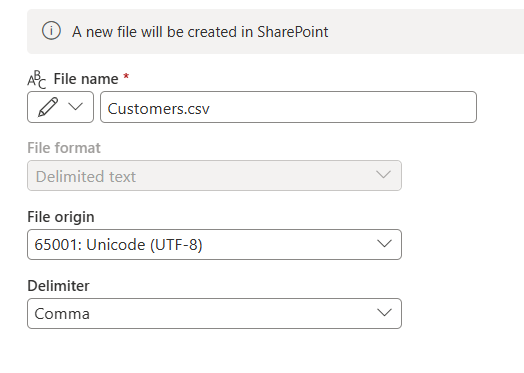
Формат текста с разделителями
При выборе текста с разделителями в качестве формата файла настройте следующие параметры:
- Имя файла: имя файла, который создается в месте назначения. По умолчанию имя файла соответствует имени запроса.
- Источник файла: кодировка, используемая для создания файла в назначении. По умолчанию для этого параметра задано значение 65001: Юникод (UTF-8).
-
Разделитель: разделитель, используемый для разделения значений в файле. Варианты включают:
- Двоеточие
- Запятая (по умолчанию)
- Знак равенства
- Точка с запятой
- Космос
- Tab
Формат Excel (предварительная версия)
Примечание.
Формат Excel для файловых мест назначения в настоящее время находится в стадии предварительного просмотра.
При выборе Excel в качестве формата файла у вас есть три варианта формата: один лист, многолистный и расширенный.
Формат одного листа
Формат одного листа записывает данные в один лист в файле Excel. Настройте следующие параметры:
-
Имя файла: Название файла Excel, который создается в месте назначения. По умолчанию имя файла соответствует имени запроса с расширением
.xlsx. -
Тип вывода: выберите способ представления данных на листе:
- Лист. Вывод данных в виде стандартной таблицы Excel.
-
Диаграмма: вывод данных в виде диаграммы. При выборе диаграммы необходимо настроить дополнительные параметры:
- Имя листа: имя листа, на котором создается диаграмма.
- Тип диаграммы: тип создаваемой диаграммы (например, область).
- Столбцы оси: столбцы, используемые для оси диаграммы.
- Столбцы значений: столбцы, используемые для значений диаграммы.
- Столбец основной оси: столбец, используемый в качестве основной оси (необязательно).
- Имя листа: имя листа, в котором записываются данные (если тип вывода — лист).
Многолистый формат
Формат нескольких листов секционирует данные по нескольким листам на основе значения столбца. Настройте следующие параметры:
- Имя файла: Название файла Excel, который создается в месте назначения.
- Столбец секционирования листа: столбец, используемый для секционирования данных по нескольким листам. Каждое уникальное значение в этом столбце создает отдельный лист.
Расширенный формат
Расширенный формат обеспечивает более широкий контроль над выходными данными Excel, что позволяет создавать сложные книги с несколькими листами, диаграммами и настраиваемым форматированием с помощью таблиц навигации. Дополнительные сведения см. в статье "Дополнительное назначение данных Excel".
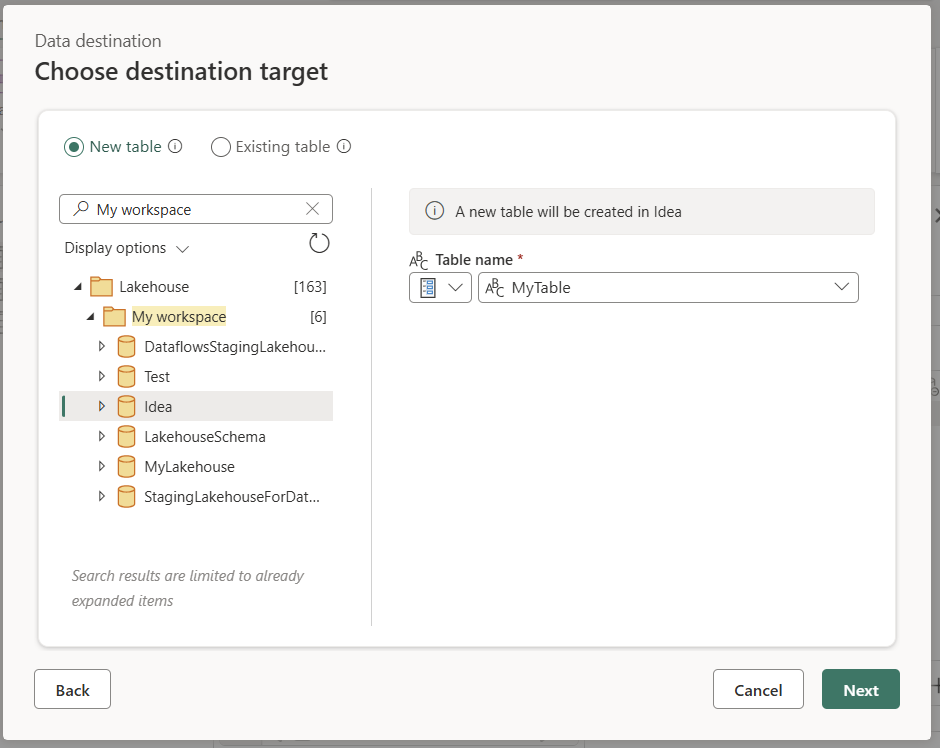
Создание новой таблицы или выбор существующей таблицы
При загрузке в место назначения данных можно создать новую таблицу или выбрать существующую.
Создать новую таблицу
При выборе создания новой таблицы Dataflow Gen2 создает новую таблицу в целевой базе данных во время обновления. Если таблица будет удалена позже (если вы вручную перейдете в место назначения и удалите ее), поток данных повторно создает таблицу во время следующего обновления.
По умолчанию имя таблицы соответствует имени запроса. Если имя таблицы содержит какие-либо символы, которые не поддерживаются целевым объектом, имя таблицы автоматически корректируется. Например, многие пункты назначения не поддерживают пробелы или специальные символы.
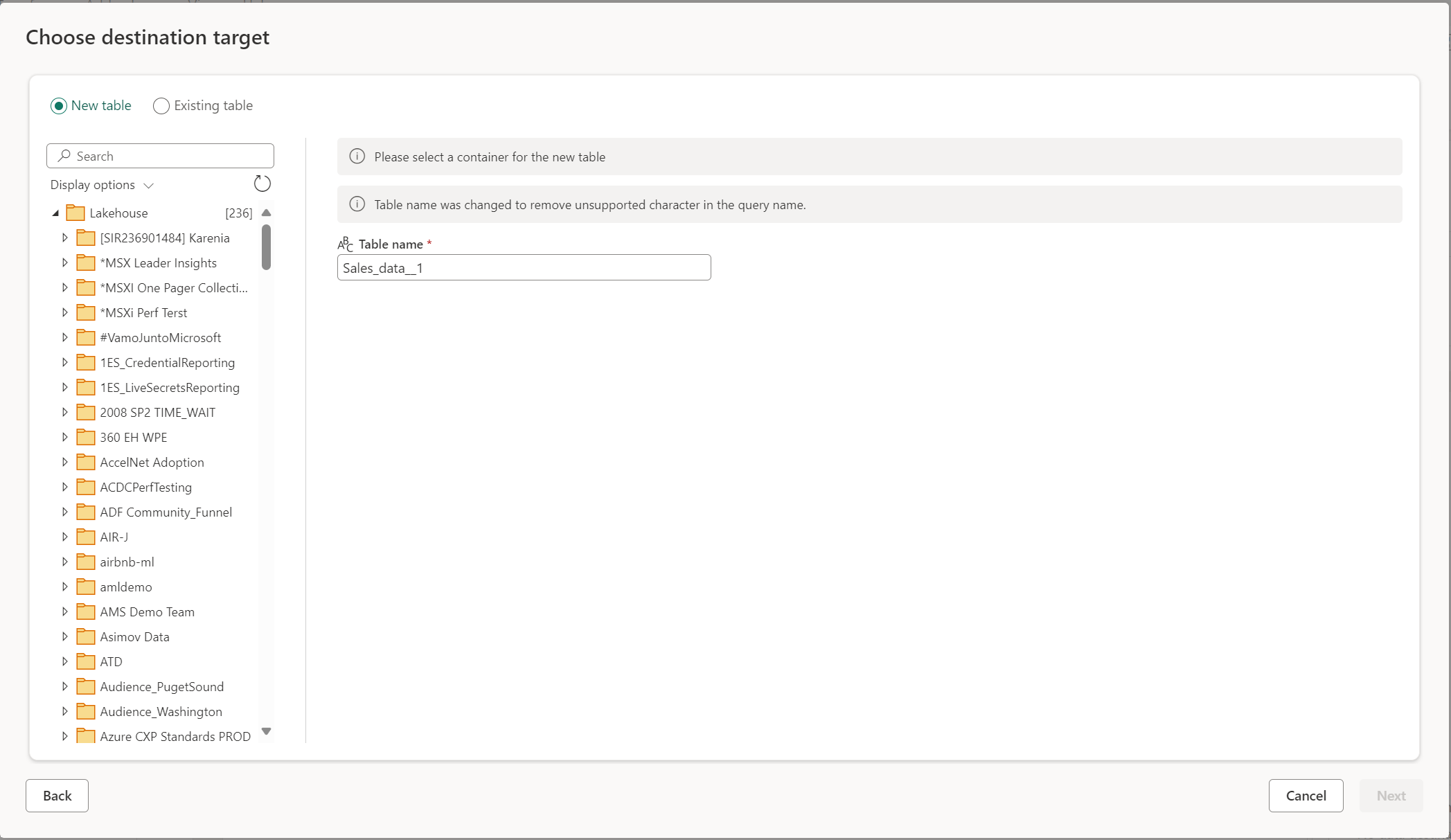
Затем необходимо выбрать целевой контейнер. Если вы выбрали любой из назначений данных Fabric, вы можете использовать навигатор, чтобы выбрать элемент Fabric, где вы хотите загрузить ваши данные. Для назначений Azure можно указать базу данных во время создания подключения или выбрать базу данных из интерфейса навигатора.
Использовать существующую таблицу
Чтобы выбрать существующую таблицу, используйте переключатель в верхней части навигатора. При выборе существующей таблицы необходимо с помощью навигатора выбрать как элемент и базу данных Fabric, так и таблицу.
При использовании существующей таблицы невозможно повторно создать таблицу в любом сценарии. Если удалить таблицу вручную из назначения данных, Dataflow Gen2 не создаст таблицу при следующем обновлении данных.
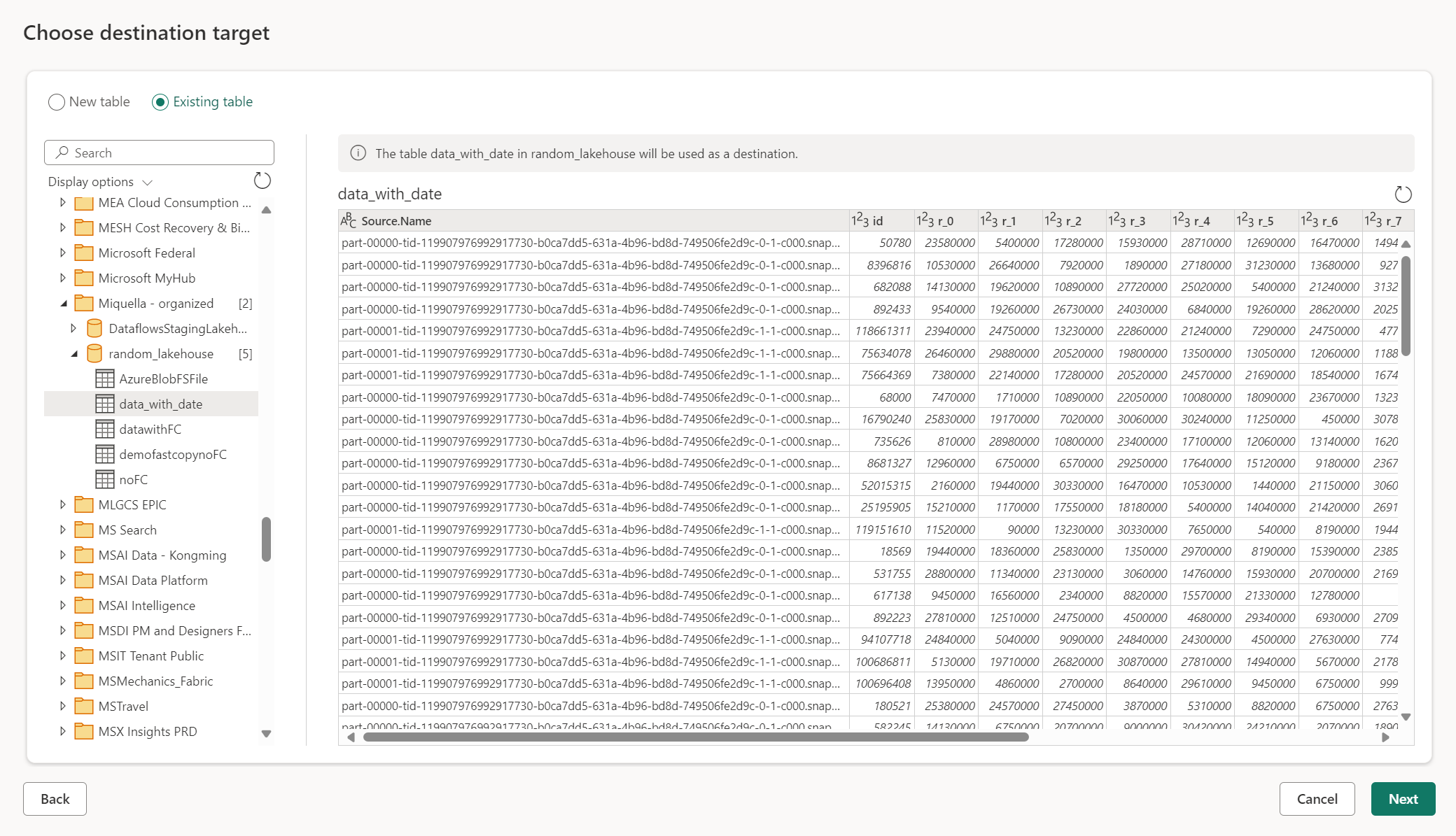
Файлы или таблицы Lakehouse
Для Lakehouse у вас есть возможность создать либо файлы, либо таблицы в Lakehouse. Это уникально, так как большинство целевых точек поддерживают только одно или другое. Это обеспечивает большую гибкость в структуре данных в lakehouse.
Чтобы переключаться между файлами и таблицами, можно использовать переключатель при просмотре вашего Lakehouse.

Управляемые параметры для новых таблиц
При загрузке в новую таблицу автоматические параметры включены по умолчанию. Если вы используете автоматические настройки, Dataflow Gen2 управляет сопоставлением для вас. Вот что делают автоматические параметры:
Замена метода обновления: данные заменяются при каждом обновлении потока данных. Все данные в месте назначения удаляются. При этом данные в назначении заменяются выходными данными процесса обработки данных.
Управляемое сопоставление: сопоставление автоматически управляется для вас. Если необходимо внести изменения в данные или запрос, чтобы добавить другой столбец или изменить тип данных, сопоставление автоматически настраивается для этого изменения при повторной публикации потока данных. При повторной публикации потока данных вам не нужно переходить в интерфейс назначения данных при каждом внесении изменений в поток данных. Это упрощает изменение схемы при повторной публикации потока данных.
Удаление и повторное создание таблицы. Чтобы разрешить эти изменения схемы, таблица удаляется и воссоздается при каждом обновлении потока данных. Обновление потока данных может привести к удалению связей или мер, которые были добавлены ранее в таблицу.
Примечание.
В настоящее время автоматические параметры поддерживаются только для Lakehouse и базы данных SQL Azure в качестве назначения данных.
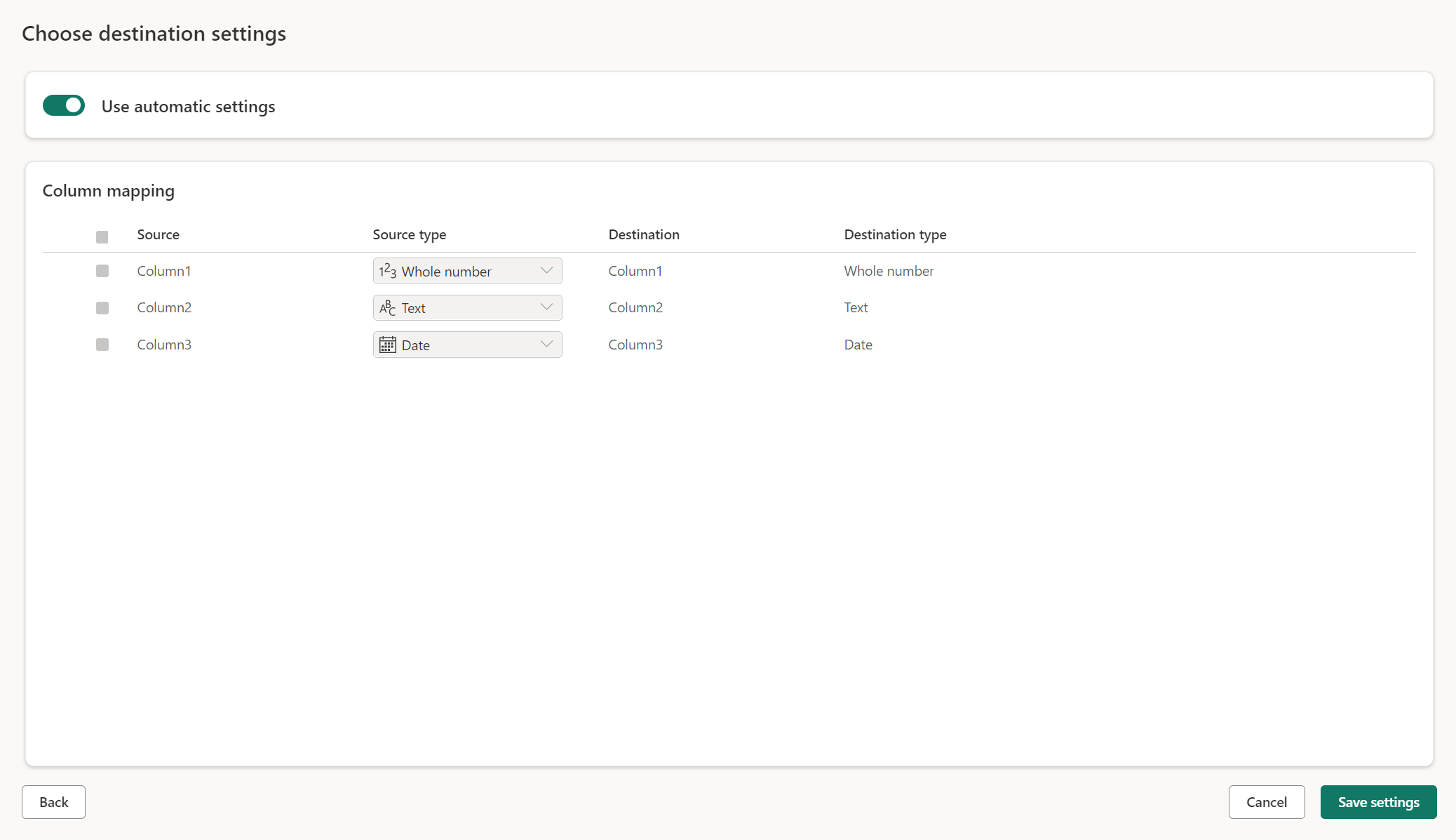
Ручные настройки
Выключив использование автоматических настроек, вы получаете полный контроль над тем, как загружать ваши данные в место назначения данных. Вы можете внести любые изменения в сопоставление столбцов, изменив тип источника или исключив любой столбец, который не требуется в назначении данных.
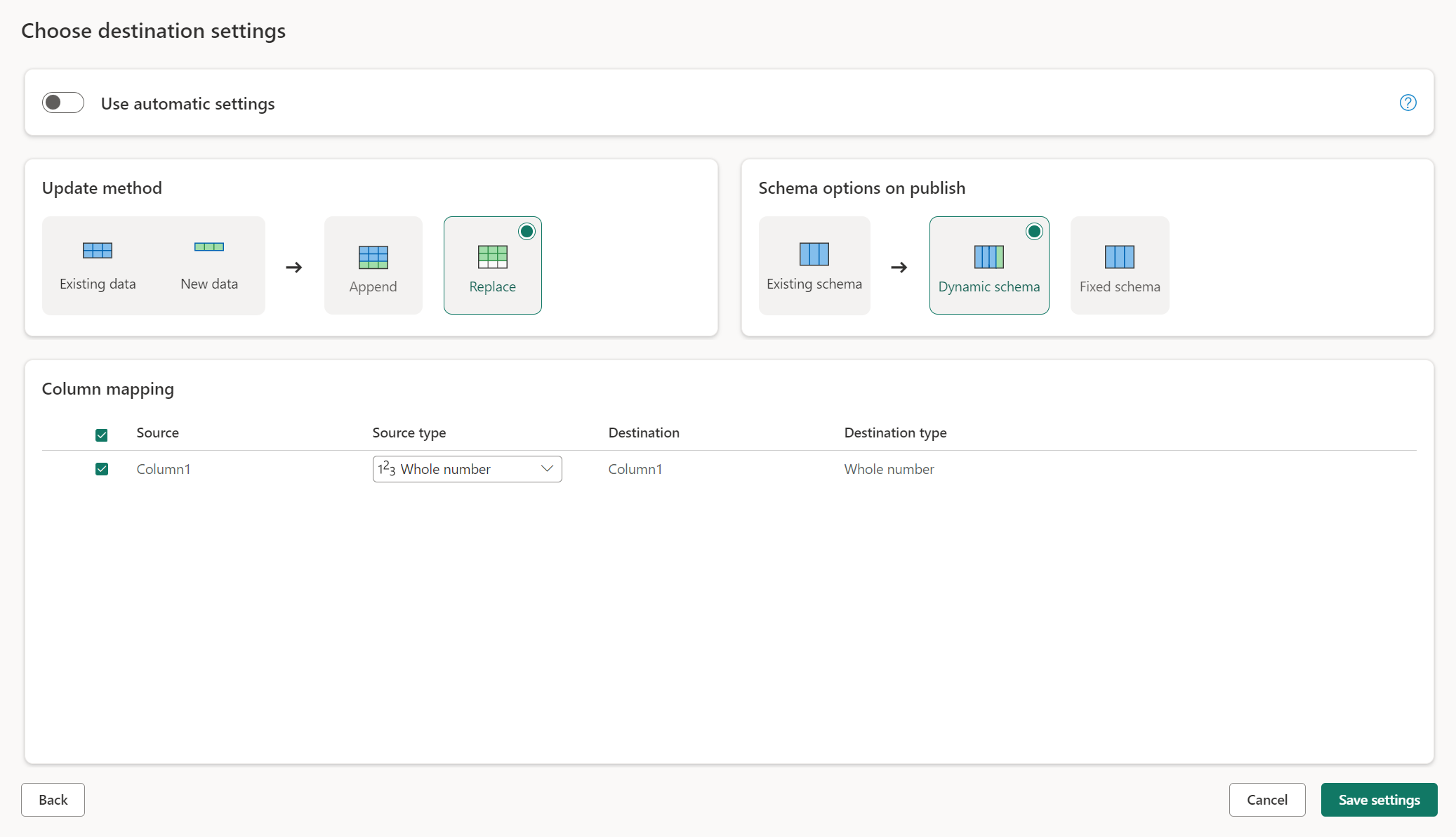
Обновление методов
Большинство мест поддерживают как добавление, так и замену в качестве методов обновления. Однако базы данных KQL Fabric и Azure Data Explorer не поддерживают замену в качестве метода обновления.
Замена. При каждом обновлении потока данных данные удаляются из назначения и заменяются выходными данными потока данных.
Добавление. При каждом обновлении потока данных выходные данные из потока данных добавляются к существующим данным в целевой таблице данных.
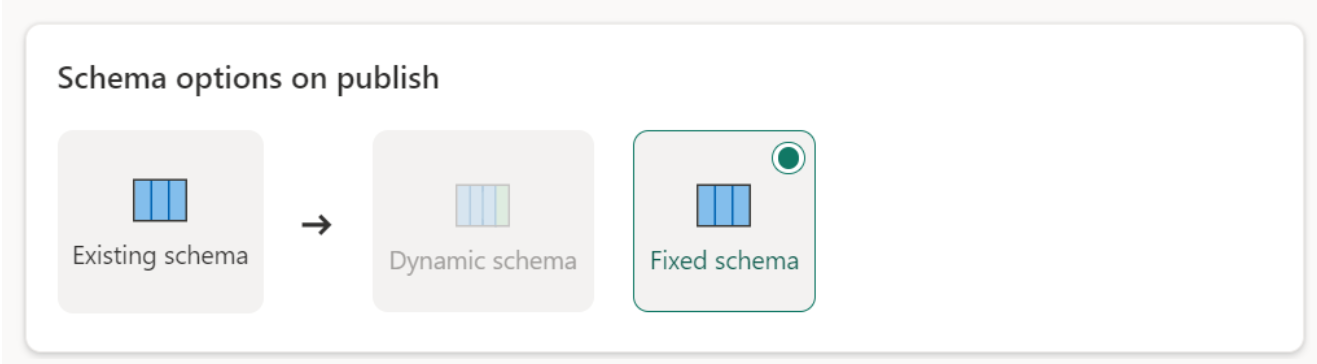
Параметры схемы при публикации
Параметры схемы при публикации применяются только при замене метода обновления. При добавлении данных изменения схемы не возможны.
Динамическая схема: при выборе динамической схемы можно разрешить изменения схемы в назначении данных при повторной публикации потока данных. Так как вы не используете управляемое сопоставление, вам по-прежнему потребуется обновить сопоставление столбцов в мастере назначения потока данных при внесении изменений в запрос. Когда обновление обнаруживает разницу между конечной схемой и ожидаемой схемой, таблица удаляется, а затем повторно создается для выравнивания с ожидаемой схемой. Обновление потока данных может привести к удалению связей или мер, которые были добавлены ранее в таблицу.
Фиксированная схема: при выборе фиксированной схемы изменения схемы невозможны. При обновлении потока данных только строки в таблице удаляются и заменяются выходными данными из потока данных. Любые связи или меры в таблице остаются неизменными. При внесении изменений в запрос в потоке данных публикация потока данных завершается ошибкой, если обнаружено, что схема запроса не соответствует схеме места назначения данных. Используйте этот параметр, если вы не планируете изменять схему и когда в целевой таблице уже добавлены связи или меры.
Примечание.
При загрузке данных в хранилище поддерживается только фиксированная схема. При загрузке данных в базу данных Snowflake поддерживается только фиксированная схема. Если изменить схему исходного запроса, необходимо вручную настроить отображение на объект назначения.
Параметризация
Параметры — это основная функция потока данных 2-го поколения. После создания или использования параметра Always Allow мини-приложение ввода становится доступным для определения имени таблицы или файла для назначения.
Примечание.
Параметры в назначении данных также можно применять непосредственно с помощью скрипта M, созданного для запросов, связанных с ним. Вы можете вручную изменить скрипт запросов назначения данных, чтобы применить параметры к вашим требованиям. Однако пользовательский интерфейс в настоящее время поддерживает параметризацию только для поля имени таблицы или файла.
Скрипт Mashup для запросов назначения данных
При использовании функции назначения данных параметры, определенные для загрузки данных в место назначения, определяются в документе mashup потока данных. Приложение потока данных изначально создает два компонента:
- Запрос, содержащий шаги навигации в целевом месте. Он следует шаблону исходного имени запроса с суффиксом _DataDestination. Рассмотрим пример.
shared #"Orders by Region_DataDestination" = let
Pattern = Lakehouse.Contents([CreateNavigationProperties = false, EnableFolding = false]),
Navigation_1 = Pattern{[workspaceId = "cfafbeb1-8037-4d0c-896e-a46fb27ff229"]}[Data],
Navigation_2 = Navigation_1{[lakehouseId = "b218778-e7a5-4d73-8187-f10824047715"]}[Data],
TableNavigation = Navigation_2{[Id = "Orders by Region", ItemKind = "Table"]}?[Data]?
in
TableNavigation;
- Запись атрибута DataDestinations для запроса, содержащего логику, используемую для загрузки данных в место назначения. Запись содержит указатель на запрос, содержащий шаги навигации к вашей цели, а также общие параметры назначения, такие как методы обновления, параметры схемы и тип целевого назначения, например, таблица или другой тип. Рассмотрим пример.
[DataDestinations = {[Definition = [Kind = "Reference", QueryName = "Orders by Region_DataDestination", IsNewTarget = true], Settings = [Kind = "Automatic", TypeSettings = [Kind = "Table"]]]}]
Эти фрагменты скриптов M не отображаются внутри приложения потока данных, но вы можете получить доступ к этой информации:
- REST API Fabric для определения потока данных GET
- Документ Mashup.pq при использовании интеграции Git
Поддерживаемые типы источников данных для каждого назначения
| Поддерживаемые типы данных для каждого расположения хранилища | DataflowStagingLakehouse | Выходные данные Базы данных Azure (SQL) | Результаты Azure Data Explorer | Выходные данные Fabric Lakehouse (LH) | Выходные данные хранилища Fabric WH | Выходные данные базы данных SQL Fabric (SQL) | Выходные данные Snowflake |
|---|---|---|---|---|---|---|---|
| Действие | нет | нет | нет | нет | нет | нет | нет |
| Любое | нет | нет | нет | нет | нет | нет | нет |
| Бинарный | нет | нет | нет | нет | нет | нет | нет |
| Валюта | Да | Да | Да | Да | нет | Да | Да |
| Часовой пояс даты и времени | Да | Да | Да | нет | нет | Да | нет |
| Продолжительность | нет | нет | Да | нет | нет | нет | нет |
| Функция | нет | нет | нет | нет | нет | нет | нет |
| нет | нет | нет | нет | нет | нет | нет | нет |
| Недействительный | нет | нет | нет | нет | нет | нет | нет |
| Время | Да | Да | нет | нет | нет | Да | Да |
| Тип | нет | нет | нет | нет | нет | нет | нет |
| Структурировано (список, запись, таблица) | нет | нет | нет | нет | нет | нет | нет |
При работе с типами данных, такими как валюта или процент, мы обычно преобразуем их в десятичные эквиваленты для большинства целей. Однако при повторном подключении к этим назначениям и следуя существующему пути таблицы, могут возникнуть трудности, например, при сопоставлении валюты с десятичным столбцом. В таких случаях попробуйте изменить тип данных в редакторе на десятичное, так как это упрощает сопоставление существующей таблицы и столбца.
Дополнительные разделы
Использование промежуточного хранения перед загрузкой в место назначения
Чтобы повысить производительность обработки запросов, промежуточное хранение можно использовать в потоке данных 2-го поколения для использования вычислений Fabric для выполнения запросов.
При включении промежуточного хранения для ваших запросов (это поведение по умолчанию), данные загружаются в промежуточное расположение, которое является внутренним и доступно только самим потокам данных в Lakehouse.
Использование промежуточных расположений может повысить производительность в некоторых случаях, когда сворачивание запроса в конечную точку аналитики SQL быстрее, чем обработка в памяти.
При загрузке данных в Lakehouse или в другие места назначения, отличные от хранилища, по умолчанию мы отключаем функцию промежуточного хранения, чтобы повысить производительность. При загрузке данных в назначение данных данные записываются непосредственно в место назначения данных без использования промежуточного хранения. Если вы хотите использовать стейджирование для вашего запроса, его можно включить снова.
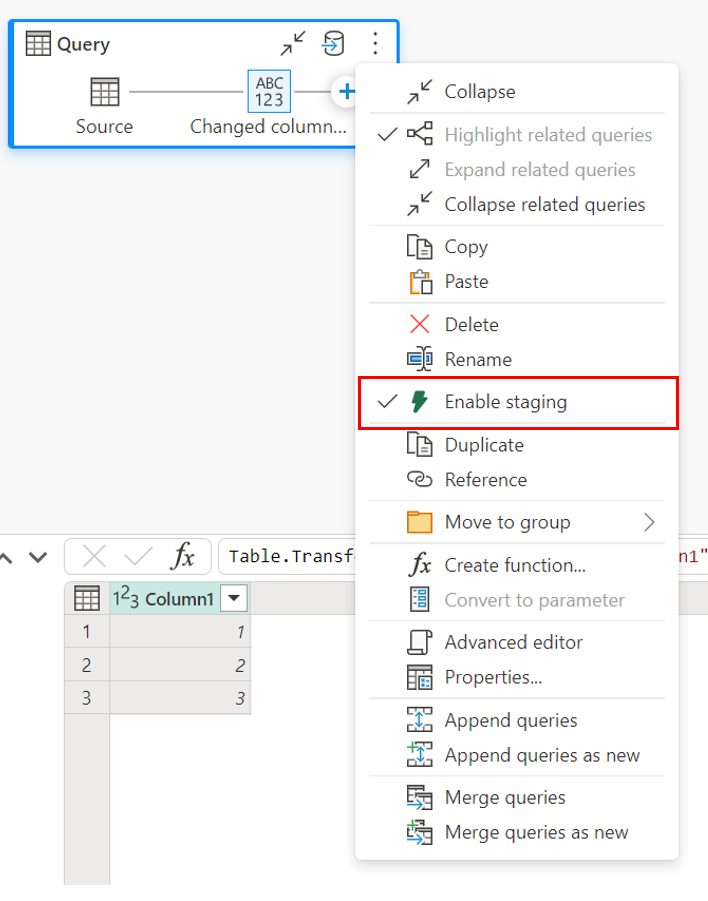
Чтобы включить стадию, щелкните правой кнопкой мыши запрос и активируйте стадию, нажав кнопку "Включить стадию". Затем запрос становится синим.
Ограничения предварительной версии назначения Snowflake
Snowflake в качестве назначения данных имеет следующие известные ограничения:
- Динамическая схема не поддерживается. При изменении столбцов в исходном запросе (добавление, переименование или удаление столбцов) необходимо вручную перенастроить сопоставление назначения. Другие направления, такие как Fabric Lakehouse, поддерживают динамическую схему, но Snowflake еще не поддерживает.
- Назначение по умолчанию работает только для новых таблиц. При использовании интерфейса назначения по умолчанию с Snowflake создается новая таблица при первом обновлении. Однако если позже изменить схему потока данных, то целевая схема не обновляется автоматически.
- Шлюз не поддерживается. Snowflake в качестве назначения данных в настоящее время доступен только для облачных потоков данных. Поддержка шлюза скоро появится.
Загрузка данных в хранилище
При загрузке данных в хранилище необходима промежуточная обработка перед операцией записи в целевое хранилище данных. Это требование повышает производительность. В настоящее время поддерживается только загрузка в ту же рабочую область, что и поток данных. Убедитесь, что промежуточный режим включен для всех запросов, загружаемых в хранилище.
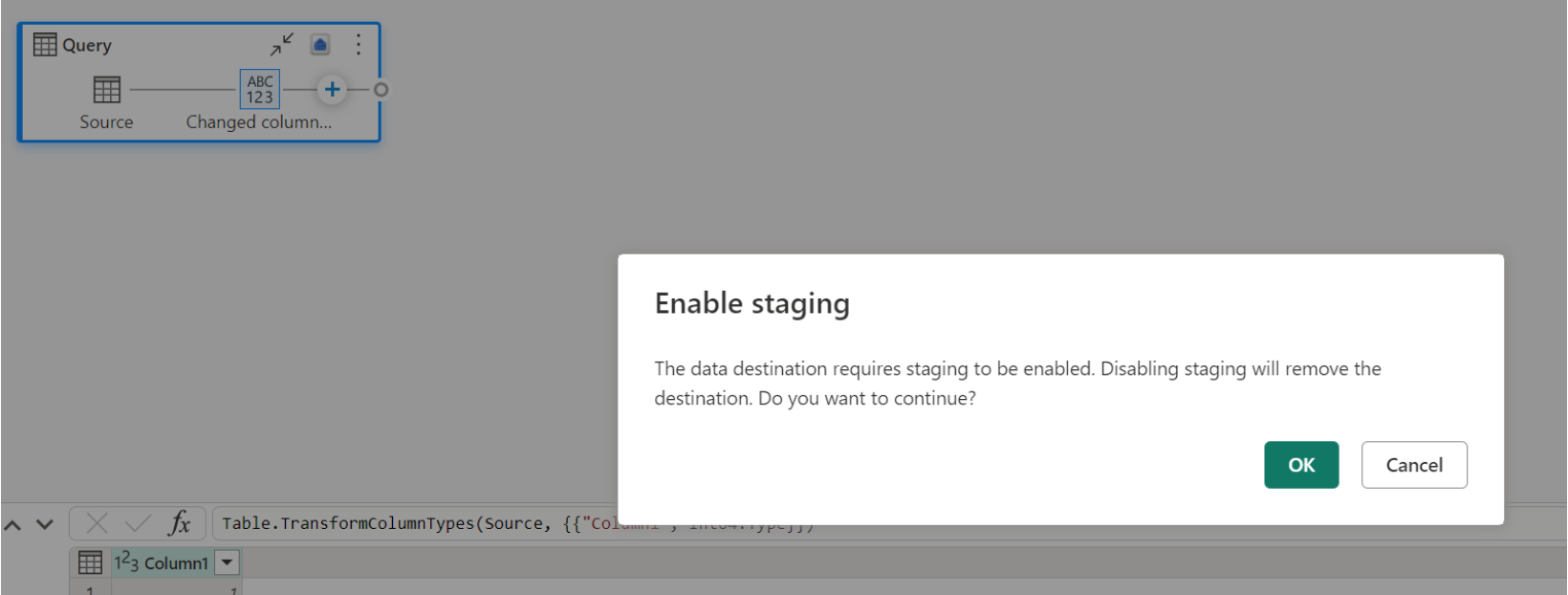
При отключении промежуточного хранения и выборе Warehouse в качестве выходного назначения вы получите предупреждение о необходимости сначала включить промежуточное хранение, прежде чем настраивать назначение данных.
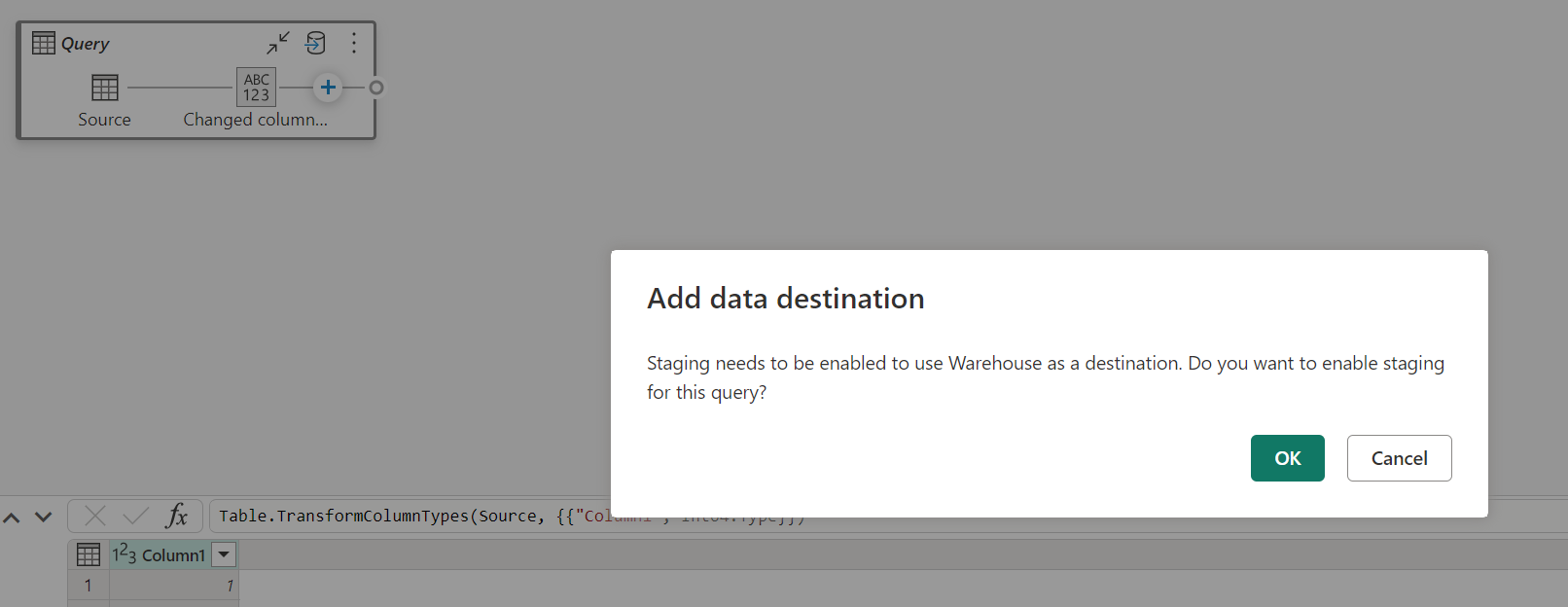
Если у вас уже есть хранилище как место назначения, и если вы попытаетесь отключить промежуточное хранение, отобразится предупреждение. Вы можете удалить хранилище в качестве места назначения или закрыть промежуточное действие.
Поддержка схемы для баз данных Lakehouse, Warehouse и SQL
Базы данных Lakehouse, Warehouse и SQL в Microsoft Fabric поддерживают возможность создания схемы для данных. Это означает, что вы можете структурировать данные таким образом, чтобы упростить управление и запросы. Чтобы иметь возможность записывать схемы в этих назначениях, необходимо включить навигацию с помощью полной иерархии в расширенных параметрах при настройке подключения. Если этот параметр не включен, вы не сможете выбрать или просмотреть схемы в целевом расположении. Ограничение версии предварительного просмотра для включения Навигации с помощью полной иерархии заключается в том, что быстрая копия может не работать должным образом. Для использования этой функции в сочетании с шлюзом требуется по крайней мере 3000.290 версии шлюза.

Автоматическая синхронизация метаданных конечных точек аналитики SQL для целей Lakehouse.
При обновлении Dataflow Gen2 данные записываются в таблицу Lakehouse, метаданные конечной точки SQL-аналитики автоматически синхронизируются в рамках этого обновления. Это означает, что ваши данные немедленно запрашиваются через точку подключения аналитики SQL сразу после того, как будет выполнено успешное обновление, без необходимости дополнительных действий или отдельного вызова API.
Это поведение контролируется параметром Синхронизация метаданных конечной точки SQL Analytics, который находится в разделе "Дополнительные параметры" подключения (видимый при создании или изменении подключения к данным Lakehouse). Параметр по умолчанию имеет значение True .
В большинстве сценариев этот параметр следует оставить включенным таким образом, чтобы подчиненные потребители (Power BI семантические модели, записные книжки, запросы SQL) всегда отображают последние данные после обновления потока данных.
Этот параметр можно задать значение False в пограничных случаях, когда:
- Вы не запрашиваете Lakehouse через конечную точку аналитики SQL и не требуется синхронизация метаданных.
- Вы замечаете заметно более долгие времена обновления из-за большого отставания в обработке разностного журнала на целевом Lakehouse, и вы хотите пропустить шаг синхронизации до тех пор, пока отставание не будет устранено (например, с помощью обслуживания таблиц и вакуумирования).
Если для параметра задано значение False, метаданные конечной точки аналитики SQL не обновляются потоком данных, а конечные точки SQL ниже могут видеть устаревшие данные до следующей синхронизации (вручную или запланированной).
Очистка назначения данных Lakehouse
При использовании Lakehouse в качестве назначения для потока данных 2-го поколения в Microsoft Fabric важно выполнять регулярное обслуживание, чтобы обеспечить оптимальную производительность и эффективное управление хранилищем. Основная задача обслуживания — пылесосить ваш пункт назначения данных. Этот процесс помогает удалить старые файлы, на которые больше не ссылается журнал разностной таблицы, что оптимизирует затраты на хранилище и обеспечивает целостность данных.
Почему вакуумирование важно
- Оптимизация хранилища. Со временем разностные таблицы накапливают старые файлы, которые больше не нужны. Вакуум помогает очистить эти файлы, освободить место в хранилище и сократить затраты.
- Улучшение производительности. Удаление ненужных файлов может повысить производительность запросов, уменьшая количество файлов, которые необходимо сканировать во время операций чтения.
- Целостность данных. Обеспечение сохранения только соответствующих файлов помогает поддерживать целостность данных, предотвращая потенциальные проблемы с незафиксированными файлами, которые могут привести к сбоям чтения или повреждению таблиц.
Как очистить место хранения данных
Чтобы очистить таблицы Delta в Lakehouse, выполните следующие действия.
- Перейдите в Lakehouse: из учетной записи Microsoft Fabric откройте соответствующий Lakehouse.
- Доступ к обслуживанию таблиц: в обозревателе Lakehouse щелкните правой кнопкой мыши таблицу, которую вы хотите сохранить или использовать многоточие для доступа к контекстном меню.
- Выберите параметры обслуживания: выберите запись меню "Обслуживание " и выберите параметр "Вакуум ".
- Выполните команду вакуума: задайте порог хранения (по умолчанию — семь дней) и выполните команду вакуума, выбрав команду "Выполнить сейчас".
Лучшие практики
- Период хранения: установите интервал хранения не менее семи дней, чтобы убедиться, что старые моментальные снимки и неподтверждённые файлы не удаляются преждевременно, что может нарушить одновременную работу читателей и записывающих данных таблиц.
- Регулярное обслуживание. Планирование регулярного вакуумирования в рамках подпрограммы обслуживания данных для обеспечения оптимизации и готовности таблиц Delta к аналитике.
- Добавочные обновления: если вы используете добавочные обновления, убедитесь, что вакуумирование отключено, так как оно может повлиять на процесс добавочных обновлений.
Включив вакуумирование данных в стратегию обслуживания, вы можете убедиться, что платформа Lakehouse остается эффективной, экономичной и надежной для операций с потоками данных.
Дополнительную информацию об обслуживании таблиц в Lakehouse см. в документации по обслуживанию таблиц Delta.
Допускает значение NULL
В некоторых случаях, когда у вас есть столбец, разрешающий значение NULL, Power Query ошибочно определяет его как не допускающий значения NULL, и при записи данных в пункт назначения тип столбца также определяется как не допускающий значения NULL. Во время обновления возникает следующая ошибка:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Чтобы принудительно использовать столбцы, допускающие значение NULL, можно выполнить следующие действия.
Удалите таблицу из места назначения данных.
Удалите пункт назначения данных из потока данных.
Перейдите в поток данных и обновите типы данных с помощью следующего кода Power Query:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Добавьте назначение данных.
Преобразование типов данных и масштабирование
В некоторых случаях тип данных в потоке данных отличается от того, что поддерживается в назначении данных. Ниже приведены некоторые преобразования по умолчанию, которые мы размещаем, чтобы убедиться, что данные по-прежнему можно получить в назначении данных:
| Назначение | Тип данных потока | Целевой тип данных |
|---|---|---|
| Склад Fabric | Int8.Type | Int16.Type |