Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как использовать действие копирования в конвейере для копирования данных из и в базу данных SQL.
Поддерживаемая конфигурация
Для настройки каждой вкладки в действии копирования перейдите к следующим разделам соответственно.
Общие
Ознакомьтесь с руководством по общим параметрам , чтобы настроить вкладку "Общие параметры".
источник
Следующие свойства поддерживаются для базы данных SQL на вкладке источника действия копирования.

Требуются следующие свойства:
Подключение: выберите существующую базу данных SQL, ссылаясь на шаг в этой статье.
Используйте запрос: вы можете выбрать таблицу, запрос или хранимую процедуру. В следующем списке описана конфигурация каждого параметра:
таблица. Укажите имя базы данных SQL для чтения данных. Выберите существующую таблицу из раскрывающегося списка или выберите Введите вручную, чтобы ввести имя схемы и таблицы.
Запрос: определите настраиваемый SQL-запрос для чтения данных. Примером является
select * from MyTable. Или щелкните значок карандаша для редактирования в редакторе кода.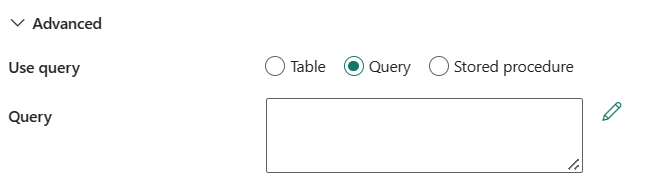
хранимая процедура: выберите хранимую процедуру из раскрывающегося списка.

В разделе "Дополнительно" можно указать следующие поля:
время ожидания запроса (минуты): укажите время ожидания для выполнения команды запроса, значение по умолчанию — 120 минут. Если для этого свойства задан параметр, допустимые значения имеют интервал времени, например "02:00:00" (120 минут).
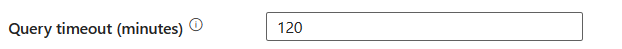
Уровень изоляции: указывает поведение блокировки транзакций для источника SQL. Допустимые значения: чтение с фиксацией, чтение без фиксации, повторяемое чтение, сериализуемоеили снимок. В разделе IsolationLevel Enum см. дополнительные сведения.
Параметр раздела: Укажите параметры разделения данных, используемые для загрузки данных из базы данных SQL. Допустимые значения: Нет (по умолчанию), физические секции таблицы и динамический диапазон. Если опция секции включена (то есть не Нет), степень параллелизма для параллельной загрузки данных из базы данных SQL управляется Степень параллелизма копирования на вкладке настроек действия копирования.
Нет. Выберите этот параметр, чтобы не использовать секцию.
Физические разделы таблицы: при использовании физического раздела столбец раздела и механизм автоматически определяются на основе определения физической таблицы.
динамический диапазон: при использовании запроса с включенной параллельной обработкой требуется параметр разбиения диапазона (
?DfDynamicRangePartitionCondition). Пример запроса:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Имя столбца секционирования: укажите имя исходного столбца в целочисленном или типе даты или даты и времени (
int,smallint,bigint,date,smalldatetime,datetime,datetime2, илиdatetimeoffset), используемый для секционирования диапазоном для параллельной копии. Если он не указан, индекс или первичный ключ таблицы обнаруживаются автоматически и используются в качестве столбца секционирования.Если вы используете запрос для получения исходных данных, задействуйте
?DfDynamicRangePartitionConditionв условии WHERE. Пример см. в разделе Параллельное копирование из базы данных SQL.Верхняя граница секции: укажите максимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. Пример см. в разделе Параллельное копирование из базы данных SQL.
Нижняя граница секции: укажите минимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. Пример см. в разделе Параллельное копирование из базы данных SQL.
дополнительные столбцы: добавьте дополнительные столбцы данных для хранения относительного пути или статического значения исходных файлов. Выражение поддерживается для последнего. Дополнительные сведения см. в разделе Добавление дополнительных столбцов во время копирования.


Назначение
Следующие свойства поддерживаются для базы данных SQL на вкладке назначения

Требуются следующие свойства:
Подключение: выберите существующую базу данных SQL, ссылаясь на шаг в этой статье.
опция таблицы: выберите использовать существующую или автоматически создать таблицу.
Если выбрать Использовать существующие:
- таблица. Укажите имя базы данных SQL для записи данных. Выберите существующую таблицу из раскрывающегося списка или выберите Введите вручную, чтобы ввести имя схемы и таблицы.
Если выбрать автоматическое создание таблицы:
- таблица: она автоматически создает таблицу (если она отсутствует) в исходной схеме, которая не поддерживается при использовании хранимой процедуры в качестве поведения записи.
В разделе "Дополнительно" можно указать следующие поля:
Поведение записи: определяет поведение записи, когда источник является файлами из файлового хранилища данных. Вы можете выбрать команду Insert, Upsert или Хранимую процедуру.

Вставка: Выберите этот параметр, если в исходных данных есть вставки.
Upsert: выберите этот параметр, если исходные данные имеют как вставки, так и обновления.
Использование TempDB: укажите, следует ли использовать глобальную временную таблицу или физическую таблицу в качестве промежуточной таблицы для upsert. По умолчанию служба использует глобальную временную таблицу в качестве промежуточной таблицы, а этот флажок установлен.
При записи большого объема данных в базу данных SQL снимите этот флажок и укажите имя схемы, в котором фабрика данных создаст промежуточную таблицу для загрузки данных вверх и автоматической очистки после завершения. Убедитесь, что у пользователя есть разрешение на создание таблицы в базе данных и разрешение на изменение схемы. Если это не указано, глобальная временная таблица используется в качестве промежуточной.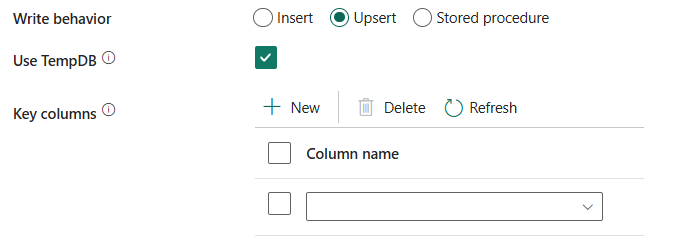
Выбор схемы базы данных пользователя. Если Use TempDB не выбран, укажите имя схемы, под которым Data Factory создаст промежуточную таблицу для загрузки входящих данных и автоматически удалит их после завершения. Убедитесь, что у вас есть разрешение на таблицу в базе данных и измените разрешение на схему.
Заметка
Необходимо иметь разрешение на создание и удаление таблиц. По умолчанию промежуточная таблица будет иметь ту же схему, что и целевая таблица.
Ключевые столбцы: выберите, какой столбец используется для определения того, соответствует ли строка из источника строке из назначения.
имя хранимой процедуры: выберите хранимую процедуру из раскрывающегося списка.
Блокировка таблицы при массовой вставке: выберите «Да» или «Нет». Используйте эту настройку, чтобы улучшить производительность копирования во время массовой вставки данных в таблицу без индекса из нескольких клиентов. Дополнительные сведения см. в BULK INSERT (Transact-SQL)
скрипт предварительного копирования. Укажите скрипт для выполнения действия копирования перед записью данных в целевую таблицу в каждом запуске. Это свойство можно использовать для очистки предварительно загруженных данных.
время ожидания пакетной записи: укажите время ожидания завершения операции пакетной вставки перед истечением тайм-аута. Допустимое значение — интервал времени. Значение по умолчанию — "00:30:00" (30 минут).
Размер пакета записи: укажите количество строк для вставки в таблицу SQL в одном пакете. Допустимое значение — целое число (число строк). По умолчанию служба динамически определяет соответствующий размер пакета на основе размера строки.
Максимальное число одновременных подключений. Укажите верхний предел одновременных подключений, установленных в хранилище данных во время выполнения действия. Укажите значение только в том случае, если требуется ограничить одновременные подключения.


Сопоставление
Для конфигурации вкладки Mapping, если вы не применяете базу данных SQL с автоматическим созданием таблицы в качестве назначения, перейдите к Mapping.
Если вы используете базу данных SQL с автоматическим созданием таблиц в качестве назначения, то кроме конфигурации в сопоставления, вы можете изменить тип для столбцов назначения. После выбора схемы импорта можно указать тип столбца в назначении.
Например, тип столбца идентификатора в источнике является int, и его можно изменить на float type при сопоставлении с целевым столбцом.

Настройки
Для настройки вкладки перейдите к Настройка других параметров на вкладке "Параметры".
Параллельная копия из базы данных SQL
Коннектор базы данных SQL в операции копирования обеспечивает встроенное секционирование данных для параллельного копирования. Параметры секционирования данных можно найти на вкладке Источник в действии копирования.
При включении секционированного копирования действие копирования выполняет параллельные запросы к источнику базы данных SQL для загрузки данных по секциям. Степень параллелизма управляется степенью параллелизма копирования на вкладке параметров действия копирования. Например, если степень параллелизма копирования установлена в четыре, служба одновременно создает и выполняет четыре запроса на основе указанной опции разбивки и настроек, а каждый запрос извлекает часть данных из вашей базы данных SQL.
Рекомендуется включить параллельную копию с секционированием данных, особенно при загрузке большого объема данных из базы данных SQL. Ниже приведены рекомендации по конфигурациям для различных сценариев. При копировании данных в хранилище данных на основе файлов рекомендуется записать в папку в виде нескольких файлов (только указать имя папки), в этом случае производительность лучше, чем запись в один файл.
Лучшие практики загрузки данных с опцией разделения:
- Выберите отличительный столбец в качестве столбца секционирования (например, первичный ключ или уникальный ключ), чтобы избежать отклонения данных.
- Если в таблице есть встроенные секции, используйте параметр " Физические секции таблицы " для повышения производительности.
Пример запроса для проверки физического раздела
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Если в таблице есть физическая секция, вы увидите HasPartition как "да" как показано ниже.

Сводка таблицы
В следующих таблицах содержатся дополнительные сведения о действии копирования в базе данных SQL.
источник
| Имя | Описание | Ценность | Обязательно | Свойство скрипта JSON |
|---|---|---|---|---|
| Подключение | Подключение к исходному хранилищу данных. | <ваше подключение> | Да | связь |
| Использовать запрос | Способ чтения данных. Примените таблицу для чтения данных из указанной таблицы или применения запроса к чтению данных с помощью запросов SQL. | • таблицы • Запрос • хранимая процедура |
Да | / |
| Для таблицы | ||||
| Имя схемы | Имя схемы. | < имя вашей схемы > | Нет | схема |
| имя таблицы | Имя таблицы. | < имя вашей таблицы > | Нет | стол |
| для запроса | ||||
| Запрос | Укажите настраиваемый SQL-запрос для чтения данных. Например: SELECT * FROM MyTable. |
< sql-запросы > | Нет | sqlReaderQuery |
| Для хранимой процедуры | ||||
| имя хранимой процедуры | Имя хранимой процедуры. | < имя вашей хранимой процедуры > | Нет | sqlReaderStoredProcedureName |
| время ожидания запроса (минуты) | Время ожидания выполнения команды запроса по умолчанию — 120 минут. Если для этого свойства задан параметр, допустимые значения имеют интервал времени, например "02:00:00" (120 минут). | интервал времени | Нет | время ожидания запроса |
| Уровень изоляции | Указывает поведение блокировки транзакций для источника SQL. | • Чтение с фиксацией • Чтение незакоммиченных данных • Повторяемое чтение •Сериализуемый •Снимок |
Нет | уровень изоляции • Read Committed (чтение с фиксацией) • ReadUncommitted (чтение без фиксации) • RepeatableRead (Повторяемое чтение) •Сериализуемый •Снимок |
| Опция разбиения | Параметры секционирования данных, используемые для загрузки данных из базы данных SQL. | • Нет • Физические разделы таблицы •Динамический диапазон |
Нет | опция разделения • ФизическиеРазделыТаблицы • DynamicRange |
| Для динамического диапазона | ||||
| имя столбца раздела | Имя исходного столбца типа целое число или дата/дата и время (int, smallint, bigint, date, smalldatetime, datetime, datetime2или datetimeoffset), которое используется для диапазонного секционирования при параллельном копировании. Если он не указан, индекс или первичный ключ таблицы обнаруживаются автоматически и используются в качестве столбца секционирования. Если вы используете запрос для получения исходных данных, задействуйте ?DfDynamicRangePartitionCondition в условии WHERE. |
< имена ваших столбцов для секционирования > | Нет | partitionColumnName |
| верхняя граница раздела | Максимальное значение столбца разделения для разбиения диапазона. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. | < верхняя граница раздела > | Нет | верхняя граница раздела |
| нижняя граница раздела | Минимальное значение столбца секционирования для разделения диапазона секционирования. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. | < ваша нижняя граница раздела > | Нет | partitionLowerBound |
| Дополнительные столбцы | Добавьте дополнительные столбцы данных для хранения относительного пути или статического значения исходных файлов. Выражение поддерживается для последнего. | •Имя •Ценность |
Нет | дополнительныеСтолбцы •имя •ценность |
Назначение
| Имя | Описание | Ценность | Обязательно | Свойство скрипта JSON |
|---|---|---|---|---|
| Подключение | Подключение к целевому хранилищу данных. | <ваше подключение > | Да | связь |
| Параметр таблицы | Таблица данных назначения. Выберите Использовать существующие или автоматическое создание таблицы. | Используйте существующие • Автоматическая создание таблицы |
Да | схема стол |
| Поведение при записи | Определяет поведение записи, когда источник является файлами из файлового хранилища данных. | •Вставка • обновление или добавление записи • хранимая процедура |
Нет | writeBehavior: •вставить • обновление или вставка • имя хранимой процедуры записи SQL |
| Блокировка на уровне таблицы при массовой вставке | Используйте эту настройку, чтобы улучшить производительность копирования во время массовой вставки данных в таблицу без индекса из нескольких клиентов. | Да или нет (по умолчанию) | Нет | sqlWriterUseTableLock: true или false (по умолчанию) |
| Для вставки или обновления | ||||
| Использовать TempDB | Следует ли использовать глобальную временную или физическую таблицу в качестве промежуточной таблицы для upsert. | выбрано (по умолчанию) или не выбрано | Нет | useTempDB: true (по умолчанию) или false |
| Ключевые столбцы | Выберите столбец, используемый для определения того, соответствует ли строка из источника строке из назначения. | < вашей ключевой колонки> | Нет | Ключи |
| Для хранимой процедуры | ||||
| имя хранимой процедуры | Это свойство — имя хранимой процедуры, которая считывает данные из исходной таблицы. Последняя инструкция SQL должна быть инструкцией SELECT в хранимой процедуре. | < имя хранимой процедуры > | Нет | имя_хранимой_процедуры_sqlWriter |
| сценарий предварительного копирования | Скрипт для выполнения действия копирования перед записью данных в целевую таблицу каждого запуска. Это свойство можно использовать для очистки предварительно загруженных данных. |
<скрипт предварительного копирования> (строка) |
Нет | PreCopyScript |
| время ожидания выполнения пакета | Время ожидания завершения операции пакетной вставки до истечения таймаута. Допустимое значение — интервал времени. Значение по умолчанию — "00:30:00" (30 минут). | интервал времени | Нет | writeBatchTimeout |
| размер пакета записи | Количество строк для вставки в таблицу SQL на пакет. По умолчанию служба динамически определяет соответствующий размер пакета на основе размера строки. |
<количество строк> (целое число) |
Нет | writeBatchSize |
| Максимальное число одновременных подключений | Верхний предел одновременных подключений, установленных для хранилища данных во время выполнения действия. Укажите значение только в том случае, если требуется ограничить одновременные подключения. |
<верхний предел одновременных подключений> (целое число) |
Нет | максимальное количество одновременных подключений |