Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как использовать действие копирования в конвейере для переноса данных из и в Fabric Lakehouse. По умолчанию данные записываются в таблицу Lakehouse в V-Order, и вы можете перейти к оптимизации таблиц Delta Lake и V-Order для получения дополнительных сведений.
Этот соединитель поддерживает Lakehouse в рабочей области с активированной функцией приватной ссылки. Дополнительные сведения о конфигурации см. в разделе "Настройка и использование приватных ссылок".
Чтобы поддерживать приватный канал на уровне рабочей области в локальном шлюзе данных (версия 3000.286.12 или более поздней), необходимо добавить *.dfs.fabric.microsoft.com в список разрешений, чтобы соединитель Lakehouse смог получить доступ к API Onelake через сеть.
Поддерживаемые форматы
Lakehouse поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат разделённого текста
- формат Excel
- Формат JSON
- Формат ORC
- Формат Parquet
- ФОРМАТ XML
Поддерживаемая конфигурация
Для настройки каждой вкладки в действии копирования перейдите к следующим разделам соответственно.
General
Для конфигурации вкладки "Общие" перейдите к разделу "Общие".
Source
Следующие свойства поддерживаются для Lakehouse на вкладке "Источник " действия копирования.

Требуются следующие свойства:
Подключение. Выберите подключение Lakehouse из списка подключений. Если подключение не существует, создайте новое подключение Lakehouse. Если вы используете команду Use dynamic content для указания вашей Lakehouse, добавьте параметр и укажите идентификатор объекта Lakehouse в качестве значения параметра. Чтобы получить идентификатор объекта Lakehouse, откройте Lakehouse в рабочей области, и после
/lakehouses/в URL-адресе вы найдете идентификатор.
Lakehouse: выберите существующий Lakehouse, который вы хотите использовать.
Корневая папка: выберите таблицы или файлы, указывающие виртуальное представление управляемой или неуправляемой области в озере. Для получения дополнительной информации см. введение в Lakehouse.
Если выбрать таблицы:
-
Используйте запрос: выберите из таблицы или запроса T-SQL (предварительная версия).
Если выбрать таблицу :
Таблица: выберите существующую таблицу из списка таблиц или укажите имя таблицы в качестве источника. Вы также можете выбрать "Создать" , чтобы создать новую таблицу.

При применении Lakehouse с схемами в соединении выберите существующую таблицу со схемой из списка таблиц или укажите таблицу с схемой в качестве источника. Вы также можете выбрать "Создать" , чтобы создать новую таблицу со схемой. Если имя схемы не указано, служба будет использовать dbo в качестве схемы по умолчанию.

В разделе "Дополнительно" можно указать следующие поля:
- Метка времени: укажите для запроса старого моментального снимка по метке времени.
- Версия. Укажите запрос к более старой моментальному снимку по версии.
- Дополнительные столбцы данных: добавьте дополнительные столбцы данных к относительному пути исходных файлов хранилища или статическому значению. Выражение поддерживается для последнего.
Если выбрать запрос T-SQL (предварительная версия):
Запрос T-SQL (предварительная версия): укажите настраиваемый SQL-запрос для чтения данных через конечную точку аналитики SQL Lakehouse. Например:
SELECT * FROM MyTable. Обратите внимание, что режим запроса таблицы Lakehouse не поддерживает частные ссылки на уровне рабочей области.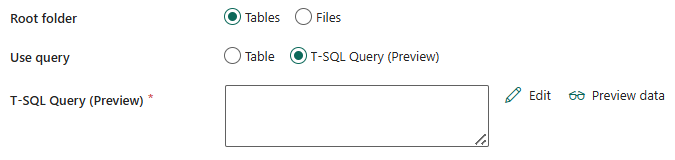
Note
Запрос T-SQL (предварительная версия) поддерживается только при чтении Lakehouse через подключение, настроенное в разделе "Управление подключениями и шлюзами".
В разделе "Дополнительно" можно указать следующие поля:
время ожидания запроса (минуты): укажите время ожидания для выполнения команды запроса, значение по умолчанию — 120 минут.
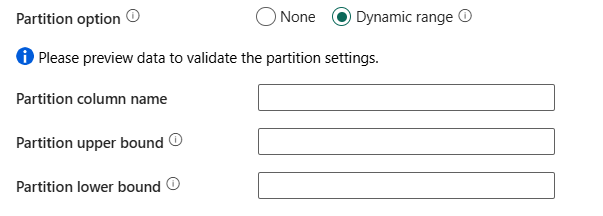
Параметр секционирования: задает параметры секционирования данных, используемые для загрузки данных из режима запроса таблицы Lakehouse. Вы можете выбрать None (по умолчанию) или Динамический диапазон.
Если выбрать None, вы выбираете не использовать раздел.
При выборе динамического диапазона, при использовании запроса с включённой параллельной обработкой требуется параметр секционирования диапазона(
?DfDynamicRangePartitionCondition). Пример запроса:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Имя столбца секционирования: укажите имя исходного столбца в целочисленном типе, используемом секционированием диапазона для параллельной копии. Если он не указан, индекс или первичный ключ таблицы обнаруживаются автоматически и используются в качестве столбца секционирования. Если вы используете запрос для получения исходных данных, задействуйте
?DfDynamicRangePartitionConditionв условии WHERE. Пример см. в разделе "Параллельная копия" из таблиц Lakehouse с помощью раздела T-SQL Query (предварительная версия).Верхняя граница секции: укажите максимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. Пример см. в разделе "Параллельная копия" из таблиц Lakehouse с помощью раздела T-SQL Query (предварительная версия).
Нижняя граница секции: укажите минимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. Пример см. в разделе "Параллельная копия" из таблиц Lakehouse с помощью раздела T-SQL Query (предварительная версия).
Дополнительные столбцы данных: добавьте дополнительные столбцы данных к относительному пути исходных файлов хранилища или статическому значению. Выражение поддерживается для последнего.
-
Используйте запрос: выберите из таблицы или запроса T-SQL (предварительная версия).
Если выбрать "Файлы":
Тип пути к файлу: можно выбрать путь к файлу, путь с подстановочными знаками или список файлов в качестве типа пути к файлу. В следующем списке описана конфигурация каждого параметра:

Путь к файлу: нажмите кнопку "Обзор" , чтобы выбрать файл, который требуется скопировать, или указать путь вручную.
Путь к файлу с подстановочными знаками: укажите папку или путь к файлу с подстановочными знаками в заданной неуправляемой области Lakehouse (в разделе "Файлы") для фильтрации исходных папок или файлов. Допустимые знаки подстановки:
*(соответствует нулю или нескольким символам) и?(соответствует нулю или одному символу). Используйте^, чтобы экранировать, если в имени папки или файла есть подстановочный знак или этот символ экранирования.Путь к папке с маской: путь к папке внутри данного контейнера. Если вы хотите использовать подстановочный знак для фильтрации папки, пропустите этот параметр и укажите эти сведения в параметрах источника действия.
Имя файла-образца: Имя файла в заданной неуправляемой области Lakehouse (в разделе "Файлы") и в указанном пути к папке.

Список файлов: указывает на копирование заданного набора файлов.
- Путь к папке: указывает на папку, содержащую файлы, которые нужно скопировать.
- Путь к списку файлов: указывает на текстовый файл, содержащий список файлов, которые требуется скопировать, один файл на строку, который является относительным путем к указанному пути к файлу.

Рекурсивно: указывает, считываются ли данные рекурсивно из вложенных папок или только из указанной папки. При включении все файлы во входной папке и ее вложенных папках обрабатываются рекурсивно. Это свойство не применяется при настройке типа пути к файлу в качестве списка файлов.
Формат файла: выберите формат файла из раскрывающегося списка. Нажмите кнопку "Параметры", чтобы настроить формат файла. Сведения о параметрах различных форматов файлов см. в статьях в поддерживаемом формате .
В разделе "Дополнительно" можно указать следующие поля:
-
Фильтр по последнему изменению: файлы фильтруются на основе последних измененных дат. Это свойство не применяется при настройке типа пути к файлу в качестве списка файлов.
- Время начала: файлы выбираются, если время последнего изменения больше или равно заданному времени.
- Время окончания: файлы выбираются, если время последнего изменения меньше настроенного времени.
-
Включение обнаружения секций: для файлов, секционированных, укажите, следует ли анализировать секции из пути к файлу и добавлять их в качестве дополнительных исходных столбцов.
- Корневой путь к партициям: Если обнаружение партиций включено, укажите абсолютный корневой путь, чтобы читать партицированные папки как столбцы данных.
- Максимальное число одновременных подключений: указывает верхний предел одновременных подключений, установленных в хранилище данных во время выполнения действия. Указывайте значение только при необходимости ограничить количество одновременных подключений.
-
Фильтр по последнему изменению: файлы фильтруются на основе последних измененных дат. Это свойство не применяется при настройке типа пути к файлу в качестве списка файлов.




Destination
Следующие свойства поддерживаются для Lakehouse на вкладке "Назначение " операции копирования.

Требуются следующие свойства:
Подключение. Выберите подключение Lakehouse из списка подключений. Если подключение не существует, создайте новое подключение Lakehouse. Если вы используете команду Use dynamic content для указания вашей Lakehouse, добавьте параметр и укажите идентификатор объекта Lakehouse в качестве значения параметра. Чтобы получить идентификатор объекта Lakehouse, откройте Lakehouse в рабочей области, и после
/lakehouses/в URL-адресе вы найдете идентификатор.
Корневая папка: выберите таблицы или файлы, указывающие виртуальное представление управляемой или неуправляемой области в озере. Для получения дополнительной информации см. введение в Lakehouse.
Если выбрать таблицы:
Таблица: выберите существующую таблицу из списка таблиц или укажите имя таблицы в качестве назначения. Вы также можете выбрать "Создать" , чтобы создать новую таблицу.

При применении Lakehouse со схемами в контексте подключения выберите существующую таблицу со схемой из списка таблиц или укажите таблицу со схемой в качестве назначения. Вы также можете выбрать "Создать" , чтобы создать новую таблицу со схемой. Если имя схемы не указано, служба будет использовать dbo в качестве схемы по умолчанию.

Note
Имя таблицы должно быть по крайней мере одним символом, без символов "/" или "\", без конечных точек, а также без начальных или конечных пробелов.
Действия таблицы: укажите операцию для выбранной таблицы.
Добавление: добавление новых значений в существующую таблицу. В параметрах "Дополнительно" можно включить партиционирование в целевой таблице.
-
Включение секции. Этот выбор позволяет создавать секции в структуре папок на основе одного или нескольких столбцов. Каждое отдельное значение столбца (пара) — это новая секция. Например, "год=2000/месяц=01/файл".
- Имя столбца раздела: выберите из столбцов назначения в сопоставлении схемы при добавлении данных в новую таблицу. При добавлении данных в существующую таблицу с уже имеющимися секциями столбцы секций автоматически извлекаются из существующей таблицы. Поддерживаемые типы данных — строка, целое число, логическое значение и datetime. Формат учитывает параметры преобразования типов на вкладке "Сопоставление ".
-
Включение секции. Этот выбор позволяет создавать секции в структуре папок на основе одного или нескольких столбцов. Каждое отдельное значение столбца (пара) — это новая секция. Например, "год=2000/месяц=01/файл".
Перезапись: перезаписать существующие данные и схему в таблице с помощью новых значений. В параметрах "Дополнительно" можно включить партиционирование в целевой таблице.
-
Включение секции. Этот выбор позволяет создавать секции в структуре папок на основе одного или нескольких столбцов. Каждое отдельное значение столбца (пара) — это новая секция. Например, "год=2000/месяц=01/файл".
- Название столбца раздела: выберите из целевых столбцов в карте схем. Поддерживаемые типы данных — строка, целое число, логическое значение и datetime. Формат учитывает параметры преобразования типов на вкладке "Сопоставление ".
Он поддерживает функцию перемещения Delta Lake во времени. Переписанная таблица содержит дельта-журналы для предыдущих версий, к которым можно получить доступ в Lakehouse. Вы также можете скопировать предыдущую таблицу версий из Lakehouse, указав версию в источнике действия копирования.
-
Включение секции. Этот выбор позволяет создавать секции в структуре папок на основе одного или нескольких столбцов. Каждое отдельное значение столбца (пара) — это новая секция. Например, "год=2000/месяц=01/файл".
Upsert: вставьте новые значения в существующую таблицу и обновите существующие значения.
- ключевые столбцы: выберите, какой столбец используется для определения того, соответствует ли строка из источника строке из назначения. Раскрывающийся список всех столбцов назначения. При записи в таблицу Lakehouse можно выбрать один или несколько столбцов, которые будут рассматриваться как ключевые столбцы.
В параметрах "Дополнительно" можно включить партиционирование в целевой таблице.
Включение секции. Этот выбор позволяет создавать секции в структуре папок на основе одного или нескольких столбцов. Каждое отдельное значение столбца (пара) — это новая секция. Например, "год=2000/месяц=01/файл".
Имя столбца секции: выберите из целевых столбцов в сопоставлении схем при обновлении или вставке данных в новой таблице. При включении данных в существующую таблицу с уже имеющимися секциями столбцы секций автоматически извлекаются из существующей таблицы. Поддерживаемые типы данных — строка, целое число, логическое значение и datetime. Формат учитывает параметры преобразования типов на вкладке "Сопоставление ".
Note
Столбцы секционирования не могут перекрываться с ключевыми столбцами.
В разделе "Дополнительно" можно указать следующие поля:
- Применение V-Order: укажите, чтобы применить V-Order с помощью копирования. Отключение сохраняет исходные файлы parquet без применения дополнительной оптимизации V-Order. Дополнительные сведения см. в разделе "Оптимизация таблицы Delta Lake" и "V-Order".
Если выбрать "Файлы":
Путь к файлу: нажмите кнопку "Обзор" , чтобы выбрать файл, который требуется скопировать, или указать путь вручную.

Формат файла: выберите формат файла из раскрывающегося списка. Выберите "Параметры", чтобы настроить формат файла. Сведения о параметрах различных форматов файлов см. в статьях в поддерживаемом формате .
В разделе "Дополнительно" можно указать следующие поля:
Поведение копирования: определяет поведение копирования, если источник является файлами из файлового хранилища данных. Вы можете выбрать Сгладить иерархию, Объединить файлы, Сохранить иерархию или Добавить динамическое содержимое в качестве поведения копирования. Конфигурация каждого параметра:
Уплощение иерархии: все файлы из исходной папки находятся на первом уровне в целевой папке. У целевых файлов есть автоматически созданные имена.
Объединить файлы: объединяет все файлы из исходной папки в один файл. Если указано имя файла, присвоенное объединенному файлу имя будет точно таким же. В противном случае это автоматически созданное имя файла.
Сохранение иерархии: сохраняет иерархию файлов в целевой папке. Относительный путь исходного файла к исходной папке идентичен относительному пути целевого файла к целевой папке.
Добавление динамического содержимого. Чтобы указать выражение для значения свойства, выберите " Добавить динамическое содержимое". Это поле открывает построитель выражений, где можно создавать выражения из поддерживаемых системных переменных, выходных данных действий, функций и пользовательских переменных или параметров. Дополнительные сведения о языке выражений см. в описании выражений и функций.

Максимальное число одновременных подключений: верхний предел одновременных подключений, установленных в хранилище данных во время выполнения действия. Указывайте значение только при необходимости ограничить количество одновременных подключений.
Размер блока (МБ): укажите размер блока в МБ при записи данных в Lakehouse. Допустимое значение — от 4 до 100 МБ.
Метаданные. Задайте пользовательские метаданные при копировании в целевое хранилище данных. Каждый объект в массиве
metadataпредставляет дополнительный столбец.nameопределяет имя ключа метаданных, аvalueуказывает значение данных этого ключа. Если используется функция сохранения атрибутов, указанные метаданные будут объединены с метаданными исходного файла или перезаписаны ими. Допустимые значения данных:$$LASTMODIFIED: зарезервированная переменная указывает на сохранение времени последнего изменения исходных файлов. Применяется только к источнику на основе файлов с двоичным форматом.Expression
Статическое значение




Mapping
Для конфигурации вкладки Сопоставление, если вы не применяете таблицу Lakehouse в качестве целевого хранилища данных, перейдите к Сопоставлению.
Если вы используете таблицу Lakehouse в качестве целевого хранилища данных, помимо настройки в сопоставлении, вы можете изменить тип данных для целевых столбцов. После выбора схемы импорта можно указать тип столбца в назначении.
Например, тип столбца PersonID в источнике является int, и его можно изменить на тип строки при сопоставлении с целевым столбцом.

Note
Изменение типа назначения в настоящее время не поддерживается, если исходный тип имеет десятичный тип.
Если в качестве формата файла выбран двоичный файл, сопоставление не поддерживается.
Settings
Для настройки вкладки "Параметры" перейдите в раздел "Параметры".
Сопоставление типов данных для таблиц Lakehouse
В следующих разделах описаны сопоставления типов данных при копировании данных из таблиц Lakehouse. Дополнительные сведения см. в подразделе, соответствующем исходному режиму.
Таблица
При копировании данных из таблиц Lakehouse в режиме таблицы используются следующие сопоставления типов данных таблиц Lakehouse с промежуточными типами данных, применяемыми службой.
| Тип данных таблицы Lakehouse | Тип данных временной услуги |
|---|---|
| string | String |
| long | Int64 |
| integer | Int32 |
| short | Int16 |
| byte | SByte |
| float | Single |
| double | Double |
| decimal | Decimal |
| boolean | Boolean |
| binary | Массив байтов |
| date | Date |
| timestamp | DateTime |
При копировании данных в таблицы Lakehouse в режиме таблиц используются следующие сопоставления промежуточных типов данных, используемых службой, к поддерживаемым производным целевым типам данных.
| Тип данных временной услуги | Поддерживаемый тип назначения delta |
|---|---|
| Boolean | boolean |
| SByte | byte |
| Byte | short |
| Int16 | short |
| UInt16 | integer |
| Int32 | integer |
| UInt32 | long |
| Int64 | long |
| UInt64 | десятичная (20,0) |
| Single | float |
| Double | double |
| GUID | string |
| Date | date |
| TimeSpan | Не поддерживается |
| DateTime | timestamp |
| DateTimeOffset | timestamp |
| String | string |
| Массив байтов | binary |
| Decimal | decimal |
Запрос T-SQL (предварительная версия)
При копировании данных из таблиц Lakehouse в режиме запроса T-SQL (предварительная версия) следующие сопоставления используются из типов данных таблицы Lakehouse с промежуточными типами данных, используемыми службой внутри службы.
| Тип данных таблицы Lakehouse в режиме T-SQL Query (предварительная версия) | Тип данных временной услуги |
|---|---|
| инт | Int32 |
| varchar | String |
| Бигинт | Int64 |
| smallint | Int16 |
| real | Single |
| float | Double |
| decimal | Decimal |
| кусочек | Boolean |
| varbinary | Byte[] |
| date | Date |
| datetime2 | DateTime |
Параллельная копия из таблиц Lakehouse с помощью запроса T-SQL (предварительная версия)
Соединитель таблиц Lakehouse с помощью запроса T-SQL (предварительная версия) в действии копирования обеспечивает встроенное секционирование данных для параллельного копирования данных. Параметры секционирования данных можно найти на вкладке Источник в действии копирования.
При включении секционированного копирования действие копирования выполняет параллельные запросы к таблицам Lakehouse с помощью источника T-SQL Query (предварительная версия) для загрузки данных по секциям. Параллельная степень управляется степенью параллелизма копирования на вкладке параметров действия копирования. Например, если задать степень параллелизма копирования четырем, служба одновременно создает и выполняет четыре запроса на основе указанного параметра секции и параметров, а каждый запрос извлекает часть данных из таблиц Lakehouse с помощью T-SQL-запроса (предварительная версия).
Рекомендуется включить параллельную копию с секционированием данных, особенно при загрузке большого объема данных из таблиц Lakehouse с помощью T-SQL-запроса (предварительная версия). Ниже приведены рекомендуемые конфигурации для разных сценариев. Если данные копируются в файловое хранилище данных, то рекомендуется сохранять данные в папку несколькими файлами (указывая только имя папки), так как производительность в таком случае будет выше, чем при записи в один файл.
| Scenario | Рекомендуемые параметры |
|---|---|
| Полная загрузка из большой таблицы без физических разделов, но с использованием целочисленного или datetime столбца для секционирования данных. |
Параметры разделения: Динамическое разделение диапазона. Столбец секционирования (необязательно): Укажите столбец, используемый для секционирования данных. Если он не указан, используется индекс или столбец первичного ключа. верхняя граница раздела и нижняя граница раздела (необязательно): укажите, нужно ли определить шаг раздела. Это не для фильтрации строк в таблице, все строки в таблице будут секционированы и скопированы. Если не указано, действие копирования автоматически обнаруживает значения и может занять много времени в зависимости от значений MIN и MAX. Рекомендуется указать верхнюю и нижнюю границу. Например, если столбец раздела "ID" имеет значения от 1 до 100, а нижняя граница установлена на 20, а верхняя граница на 80, с количеством параллельных копий 4, служба получает данные по 4 разделам — идентификаторы в диапазоне <=20, [21, 50], [51, 80], и >=81 соответственно. |
| Загрузка большого объема данных с помощью пользовательского запроса, без физических разделов, при этом используя столбец с целыми числами или датой/временем для секционирования данных. |
Параметры разделения: Динамическое разделение диапазона. Запрос: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Столбец секционирования: укажите столбец, используемый для секционирования данных. верхняя граница раздела и нижняя граница раздела (необязательно): укажите, нужно ли определить шаг раздела. Это не для фильтрации строк в таблице, все строки в результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. Например, если ваш столбец секционирования "ID" имеет значения в диапазоне от 1 до 100, а нижняя граница установлена на 20, верхняя граница на 80, и параллельное копирование настроено на 4, служба извлекает данные по 4 разделам— идентификаторы в диапазоне <=20, [21, 50], [51, 80], и >=81 соответственно. Ниже приведены дополнительные примеры запросов для различных сценариев: • Запросите всю таблицу: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Запрос из таблицы с выбором столбцов и дополнительными фильтрами по условию where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Запрос с вложенными запросами: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Запрос с разделом в подзапросе: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Поддержка таблиц Delta Lake
В следующих разделах вы найдете подробные сведения о поддержке атрибутов таблиц Delta Lake как со стороны источника, так и со стороны назначения.
Source
сопоставление столбцов Delta поддерживается при применении читателя версии 2 или читателя версии 3 с columnMapping в readerFeatures в таблице Lakehouse.
Возможность сопоставления столбцов разностной таблицы позволяет более гибко изменять схему, что гарантирует, что изменения в структуре таблицы не нарушают рабочие процессы данных. С помощью сопоставления столбцов можно считывать данные из существующей таблицы Дельта Лэйк с delta.columnMapping.mode, установленным на name или id.
Векторы удаления поддерживаются при использовании ридера версии 3 с deletionVectors в readerFeatures в таблице Lakehouse. Строки, которые мягко удалены, помечены в векторных файлах удаления и пропускаются при чтении таблицы Delta Lake.
Канал данных изменений поддерживается.
Destination
сопоставление столбцов Delta поддерживается. Эта возможность позволяет более гибкой эволюции схемы, обеспечивая, чтобы изменения в структуре таблиц не нарушали рабочие процессы данных. Сопоставление столбцов позволяет:
- Запись данных в существующую таблицу разностного озера с
delta.columnMapping.modeзаданным значениемname. - Автоматически создайте таблицу с
delta.columnMapping.modeдляname, если целевая таблица не существует, а исходные столбцы включают специальные символы и пробелы. - Автоматическое создание таблицы с
delta.columnMapping.mode, заданной дляnameпри перезаписи действия таблицы, а столбцы исходного набора данных включают специальные символы и пробелы.
Поддерживаются векторы удаления.
Канал данных изменений поддерживается.
Поддерживается кластеризация жидкости.
Сводка таблицы
В следующих таблицах содержатся дополнительные сведения об операции копирования в системе Lakehouse.
Исходная информация
| Name | Description | Value | Required | Свойство скрипта JSON |
|---|---|---|---|---|
| Connection | Раздел для выбора подключения. | < ваше подключение к Lakehouse> | Yes | workspaceId идентификатор_элемента |
| Корневая папка | Тип корневой папки. | • Таблицы • Файлы |
No | rootFolder: Таблицы или файлы |
| Использовать запрос | Способ чтения данных из Lakehouse. Примените таблицу для чтения данных из указанной таблицы или применения запроса T-SQL (предварительная версия) для чтения данных с помощью запроса. | • таблицы • Запрос T-SQL (предварительная версия) |
Yes | / |
| Table | Имя таблицы, данные из которой вы хотите читать, или имя таблицы со схемой, данные из которой вы хотите читать при применении Lakehouse с использованием схем в качестве подключения. | <имя таблицы> | Да при выборе таблиц в корневой папке | table |
| Имя схемы | Имя схемы. | < имя вашей схемы > | No | schema |
| имя таблицы | Название таблицы. | < имя вашей таблицы > | No | table |
| Запрос T-SQL (предварительная версия) | Используйте пользовательский запрос для чтения данных. Примером является SELECT * FROM MyTable. |
< запрос > | No | sqlReaderQuery |
| Timestamp | Метка времени, используемая для запроса старого моментального снимка. | <метка времени> | No | timestampAsOf |
| Version | Версия для выполнения запроса к старому снимку состояния. | <версия> | No | versionAsOf |
| время ожидания запроса (минуты) | Время ожидания выполнения команды запроса по умолчанию — 120 минут. | временной промежуток | No | время ожидания запроса |
| Опция разбиения | Параметры секционирования данных, используемые для загрузки данных из режима запроса таблицы Lakehouse. | • Нет •Динамический диапазон |
No | partitionOption |
| имя столбца раздела | Имя исходного столбца в целочисленном типе, который будет использоваться разбиением диапазона для параллельного копирования. Если это не указано, первичный ключ таблицы обнаруживается автоматически и используется в качестве столбца секционирования. | <Имя столбца раздела> | No | имя столбца раздела |
| верхняя граница раздела | Максимальное значение столбца разделения для разбиения диапазона. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. | <верхняя граница раздела> | No | верхняя граница раздела |
| нижняя граница раздела | Минимальное значение столбца секционирования для разделения диапазона секционирования. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. | <нижняя граница раздела> | No | partitionLowerBound |
| Дополнительные столбцы | Дополнительные столбцы данных для хранения относительного пути или статического значения исходных файлов. Выражение поддерживается для последнего. | •Имя •Ценность |
No | additionalColumns: •имя •ценность |
| Тип пути к файлу | Тип используемого пути к файлу. | • Путь к файлу • Путь к файлу с подстановочными знаками • Список файлов |
Да при выборе файлов в корневой папке | / |
| Путь к файлу | Скопируйте путь к папке или файлу в исходном хранилище данных. | <Путь к файлу> | Да при выборе пути к файлу | • путь к папке •имя файла |
| Пути с подстановочными знаками | Путь к папке с подстановочными знаками в исходном хранилище данных, настроенный для фильтрации исходных папок. | <Пути с подстановочными знаками> | Да, при выборе пути к файлу с маской | • WildcardFolderPath • подстановочный знакFileName |
| Путь к папке | Указывает на папку, содержащую файлы, которые нужно скопировать. | <Путь к папке> | No | folderPath |
| Путь к списку файлов | Указывает, что нужно скопировать заданный набор файлов. Укажите путь к текстовому файлу, содержащему список файлов, которые вы хотите скопировать. Каждый файл должен быть указан на отдельной строке и представлять собой относительный путь к настроенному пути. | <путь к списку файлов> | No | fileListPath |
| Recursively | Обработайте все файлы во входной папке и ее вложенных папках рекурсивно или просто те, которые в выбранной папке. Этот параметр отключен при выборе одного файла. | Выбор или отмена выбора | No | recursive: истина или ложь |
| Формат файлов | Формат файла для исходных данных. Сведения о различных форматах файлов см. в статьях в поддерживаемом формате для получения подробных сведений. | / | Да при выборе файлов в корневой папке | / |
| Фильтрация по последней дате изменения | Файлы с последним измененным временем в диапазоне [время начала, время окончания) будут отфильтрованы для дальнейшей обработки. Время применяется к часовой поясу UTC в формате yyyy-mm-ddThh:mm:ss.fffZ.Это свойство можно пропустить, что означает, что фильтр атрибутов файла не применяется. Это свойство не применяется при настройке типа пути к файлу в качестве списка файлов. |
• Время начала • Время окончания |
No | modifiedDatetimeStart modifiedDatetimeEnd |
| Включение обнаружения разделов | Следует ли анализировать секции из пути к файлу и добавлять их в качестве дополнительных исходных столбцов. | Выбрано или не выбрано | No | enablePartitionDiscovery: true или false (по умолчанию) |
| Корневой путь раздела | Абсолютный корневой путь секционирования для чтения секционированных папок в виде столбцов данных. | <корневой путь вашего раздела> | No | partitionRootPath |
| Максимальное число одновременных подключений | Верхний предел одновременных подключений, установленных для хранилища данных при выполнении действия. Значение необходимо только в том случае, если требуется ограничить одновременные подключения. | <максимальное число одновременных подключений> | No | maxConcurrentConnections |
Сведения о назначении
| Name | Description | Value | Required | Свойство скрипта JSON |
|---|---|---|---|---|
| Connection | Раздел для выбора подключения. | < ваше подключение к Lakehouse> | Yes | workspaceId идентификатор_элемента |
| Корневая папка | Тип корневой папки. | • Таблицы • Файлы |
Yes | rootFolder: Таблица или файлы |
| Table | Имя таблицы, в которую требуется записать данные. Или имя таблицы со схемой, в которую необходимо записать данные при применении Lakehouse с схемами в качестве соединения. | <имя таблицы> | Да при выборе таблиц в корневой папке | table |
| Имя схемы | Имя схемы. |
<имя вашей схемы> (значение по умолчанию — dbo) |
No | schema |
| имя таблицы | Название таблицы. | <имя таблицы> | Yes | table |
| Действие таблицы | Добавьте новые значения в существующую таблицу, перезаписать существующие данные и схему в таблице с помощью новых значений или вставить новые значения в существующую таблицу и обновить существующие значения. | • Добавление • Перезапись • Upsert |
No | tableActionOption: •Прибавлять • ПерезаписатьСхему • обновление или добавление записи |
| Применить V-Order | Примените V-Order через копирование. Отключение сохраняет исходные файлы parquet без применения дополнительной оптимизации V-Order. Дополнительные сведения см. в разделе "Оптимизация таблицы Delta Lake" и "V-Order". | Выбрано (по умолчанию) или не выбрано | No | applyVOrder |
| Включение секций | Этот выбор позволяет создавать секции в структуре папок на основе одного или нескольких столбцов. Каждое отдельное значение столбца (пара) — это новая секция. Например, "год=2000/месяц=01/файл". | Выбрано или не выбрано | No | partitionOption: PartitionByKey или Отсутствует |
| Колонки партиционирования | Целевые столбцы в сопоставлении схем. | <столбцы разделов> | No | partitionNameList |
| Ключевые столбцы | Выберите столбец, используемый для определения того, соответствует ли строка из источника строке из назначения. | <ключевые столбцы> | Yes | keyColumns |
| Путь к файлу | Запись данных в путь к папке или файлу в целевом хранилище данных. | <Путь к файлу> | No | • путь к папке •имя файла |
| Формат файлов | Формат файла для целевых данных. Сведения о различных форматах файлов см. в статьях в поддерживаемом формате для получения подробных сведений. | / | Да при выборе файлов в корневой папке | / |
| Поведение копирования | Поведение копирования, определенное для случаев, когда источником являются файлы из файлового хранилища. | • Плоская иерархия • Слияние файлов • Сохранение иерархии • Добавление динамического содержимого |
No | copyBehavior: • УпрощениеИерархии • MergeFiles • Сохранить Иерархию |
| Максимальное число одновременных подключений | Верхний предел одновременных подключений, установленных для хранилища данных при выполнении действия. Указывайте значение только при необходимости ограничить количество одновременных подключений. | <максимальное число одновременных подключений> | No | maxConcurrentConnections |
| Размер блока (МБ) | Размер блока в МБ, используемый для записи данных в Lakehouse. Допустимое значение — от 4 до 100 МБ. | <Размер блока> | No | blockSizeInMB |
| Metadata | Настраиваемый набор метаданных при копировании в место назначения. | • $$LASTMODIFIED•Выражение • Статическое значение |
No | metadata |