Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Действие Azure HDInsight в Фабрике данных для Microsoft Fabric позволяет управлять следующими типами заданий Azure HDInsight:
- Выполнение запросов Hive
- Вызов программы MapReduce
- Выполнение запросов Pig
- Выполнение программы Spark
- Выполните программу Hadoop Stream
В этой статье содержится пошаговое руководство по созданию действия Azure HDInsight с помощью интерфейса фабрики данных.
Предварительные условия
Чтобы приступить к работе, необходимо выполнить следующие предварительные требования:
- У вас должен быть доступ к клиенту Microsoft Fabric с подготовленной вычислительной мощностью. Вы можете попробовать Fabric с бесплатной пробной версией.
- Рабочая область Fabric, назначенная этой емкости.
Добавить активность Azure HDInsight (HDI) в конвейер с помощью интерфейса пользователя
Создайте конвейер в рабочей области.
Выберите карточку действия конвейера или перейдите на вкладку "Действия " и выберите Azure HDInsight.
Создание действия на карточке главного экрана:
Создание действия на панели действий:
Выберите новое действие Azure HDInsight на холсте редактора конвейера, если оно еще не выбрано.
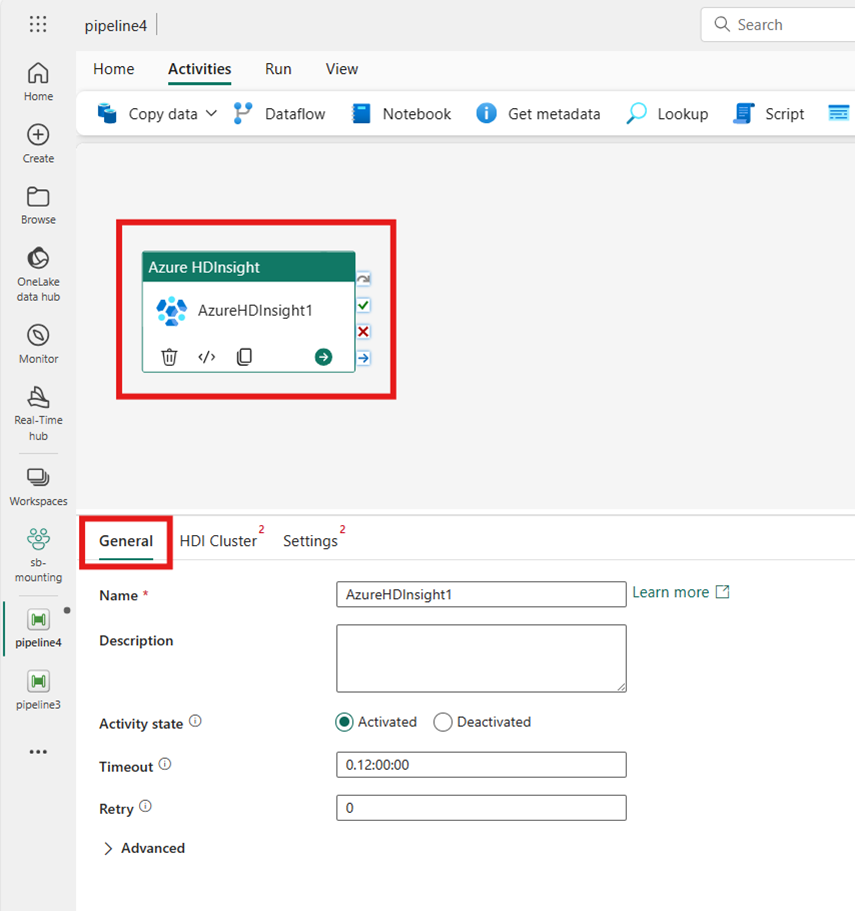
Ознакомьтесь с руководством по общим параметрам , чтобы настроить параметры, найденные на вкладке "Общие параметры ".

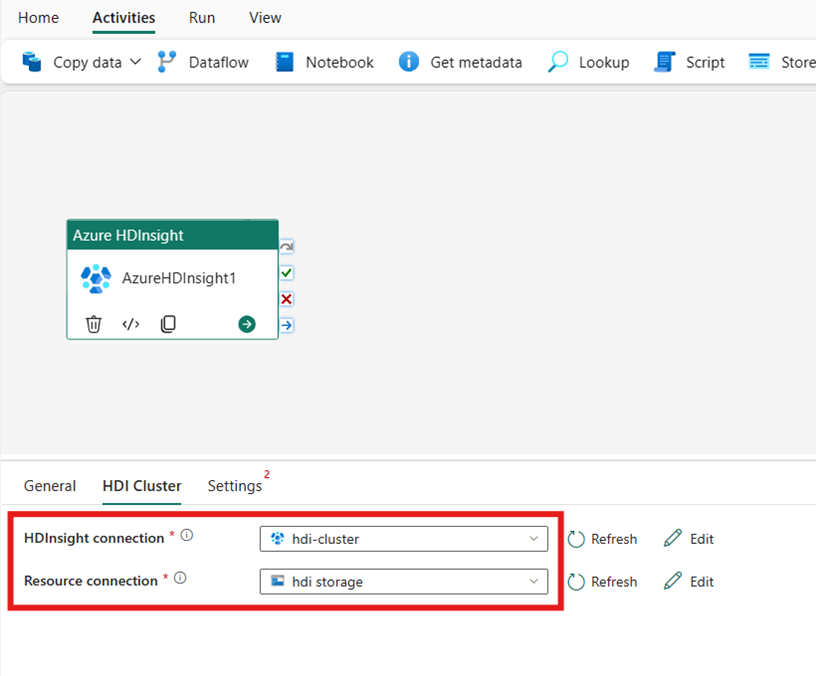
Настройка кластера HDI
Перейдите на вкладку кластера HDI. Затем можно выбрать существующее или создать новое подключение HDInsight.
Для подключения к ресурсу выберите Хранилище BLOB-объектов Azure, ссылающееся на кластер Azure HDInsight. Вы можете выбрать существующее хранилище BLOB-объектов или создать новый.
Настройка параметров
Перейдите на вкладку "Параметры" , чтобы просмотреть дополнительные параметры для действия.
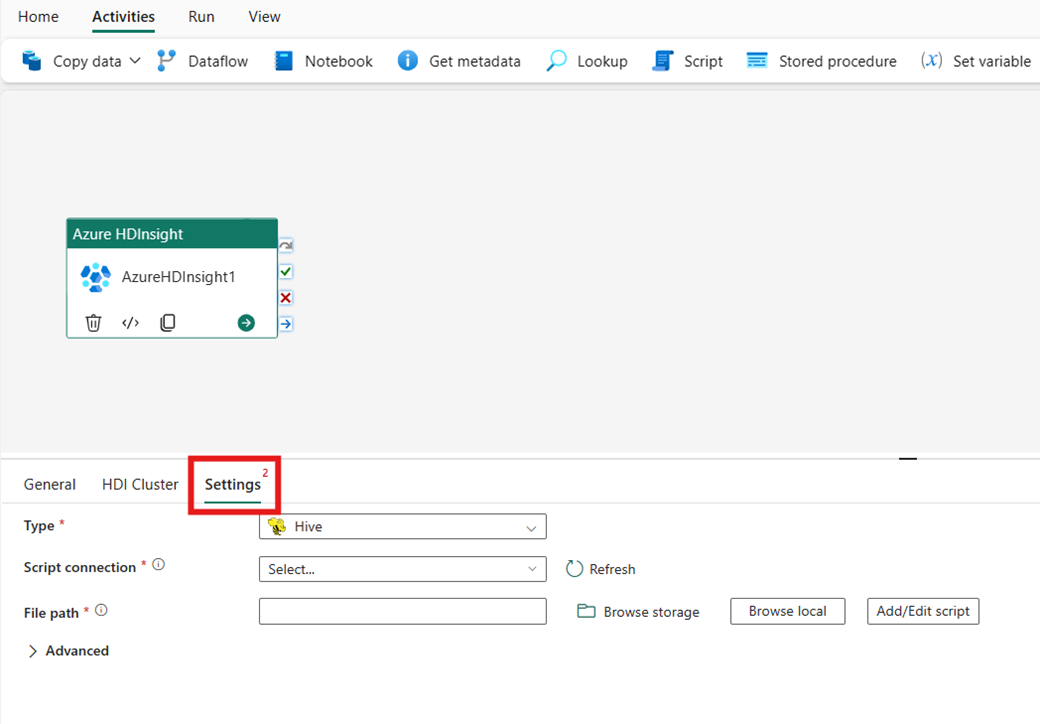
Все расширенные свойства кластера и динамические выражения, поддерживаемые в связанной службе Фабрика данных Azure и Synapse Analytics HDInsight, теперь также поддерживаются в действии Azure HDInsight для фабрики данных в Microsoft Fabric в разделе "Дополнительно" в пользовательском интерфейсе. Все эти свойства поддерживают настраиваемые параметризованные выражения с динамическим содержимым.
Тип кластера
Чтобы настроить параметры для кластера HDInsight, сначала выберите его тип из доступных параметров, включая Hive, Map Reduce, Pig, Spark и Streaming.
Куст
При выборе Hive для типа действие выполняет запрос Hive. При необходимости можно указать подключение скрипта, ссылающееся на учетную запись хранения, содержащую тип Hive. По умолчанию используется подключение к хранилищу, указанное на вкладке HDI Cluster. Необходимо указать путь к файлу, чтобы выполнить его в Azure HDInsight. При необходимости можно указать дополнительные конфигурации в разделе "Дополнительно", "Сведения об отладке", "Время ожидания запроса", "Аргументы", "Параметры" и "Переменные".
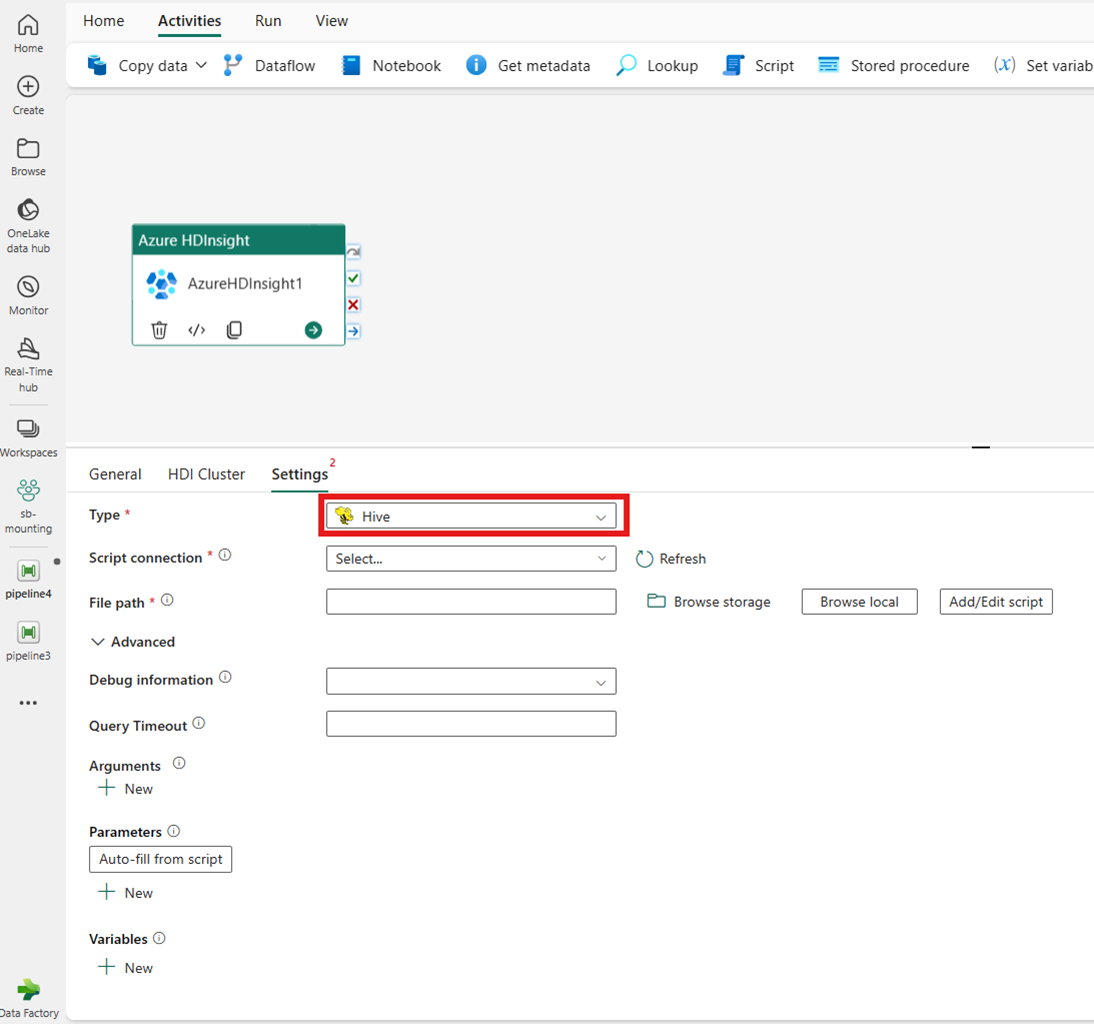
MapReduce
Если выбрать map Reduce для типа, действие вызывает программу Map Reduce. При необходимости можно указать в jar-подключении, ссылающемся на учетную запись хранения, содержащую тип Map Reduce. По умолчанию используется подключение к хранилищу, указанное на вкладке кластера HDI. Необходимо указать имя класса и путь к файлу для выполнения в Azure HDInsight. При необходимости можно указать дополнительные сведения о конфигурации, такие как импорт библиотек Jar, сведения об отладке, аргументы и параметры в разделе "Дополнительно ".
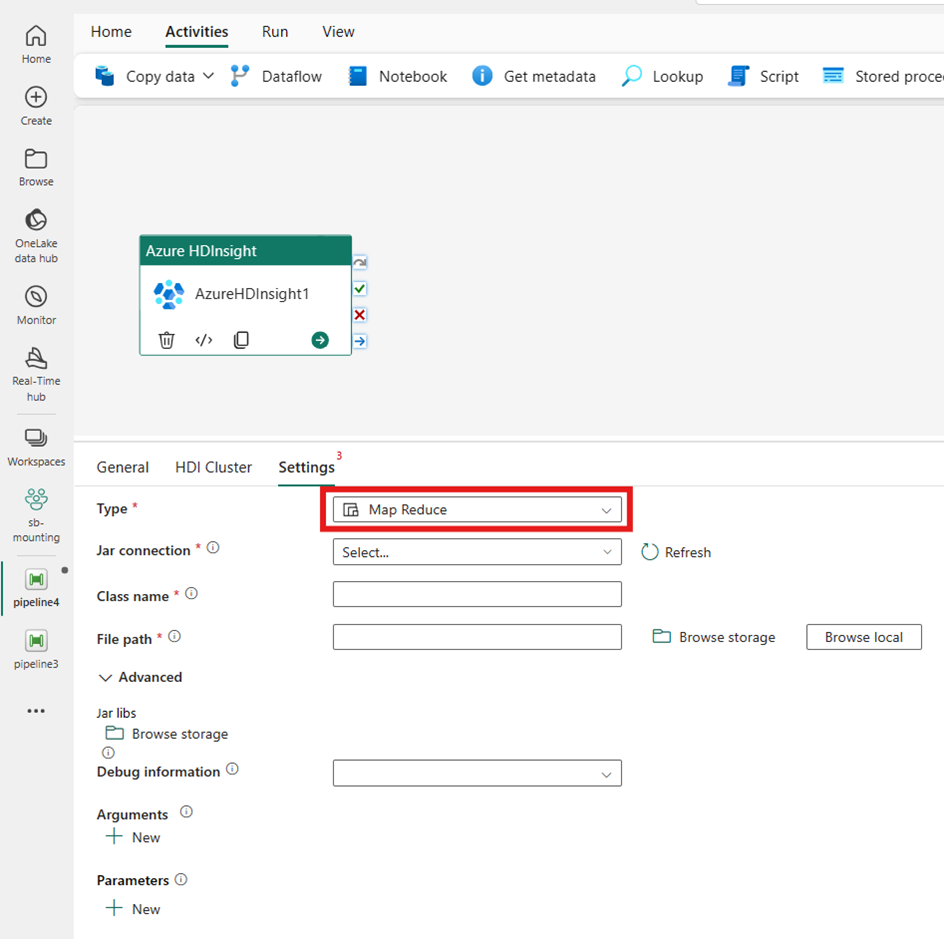
Свинья
Если выбрать Pig для типа, действие вызовет запрос Pig. При необходимости можно указать параметр подключения скрипта, который ссылается на учетную запись хранения, содержащую тип Pig. По умолчанию используется подключение к хранилищу, указанное на вкладке кластера HDI. Необходимо указать путь к файлу, чтобы выполнить его в Azure HDInsight. При необходимости можно указать дополнительные конфигурации, такие как сведения об отладке, аргументы, параметры и переменные в разделе "Дополнительно ".
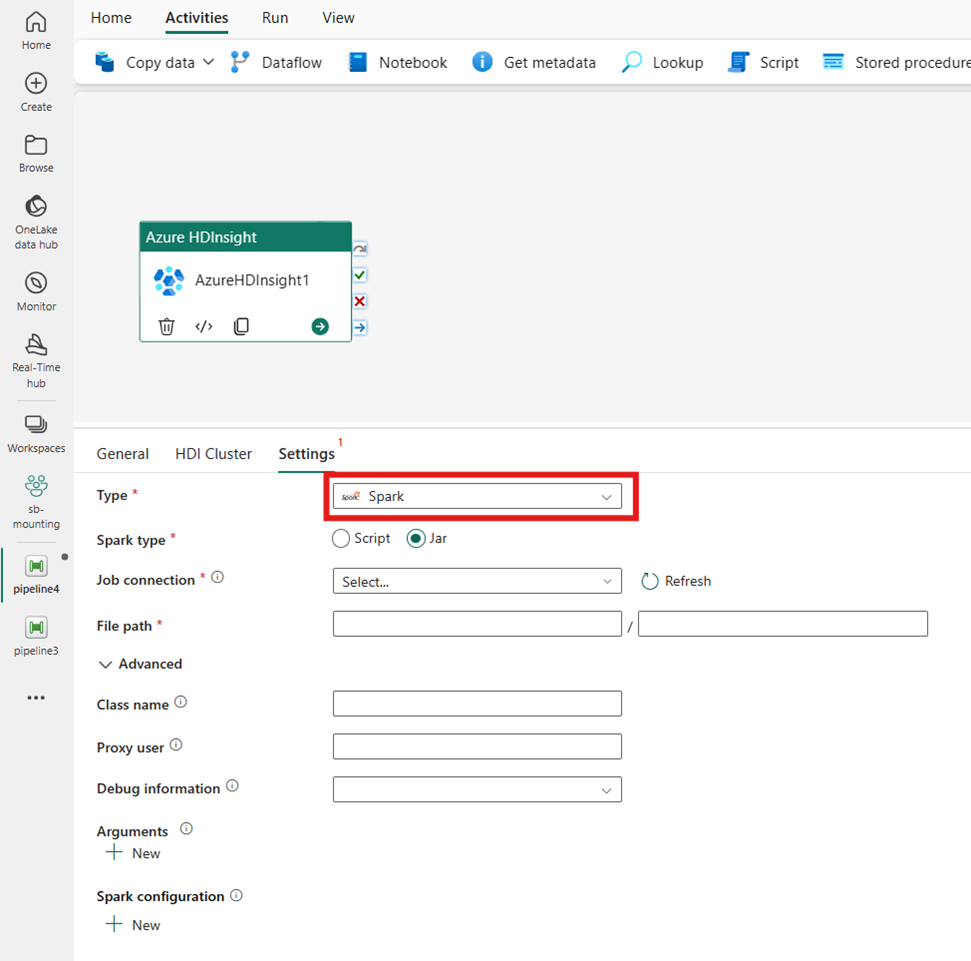
Спарк
При выборе Spark для типа действие вызывает программу Spark. Выберите Скрипт или Jar для типа Spark. При необходимости можно указать соединение задания, ссылающееся на учетную запись хранения, содержащую тип Spark. По умолчанию используется подключение к хранилищу, указанное на вкладке кластера HDI. Необходимо указать путь к файлу, чтобы выполнить его в Azure HDInsight. При необходимости можно указать дополнительные конфигурации, например имя класса, прокси-пользователя, сведения об отладке, аргументы и конфигурацию Spark в разделе "Дополнительно".
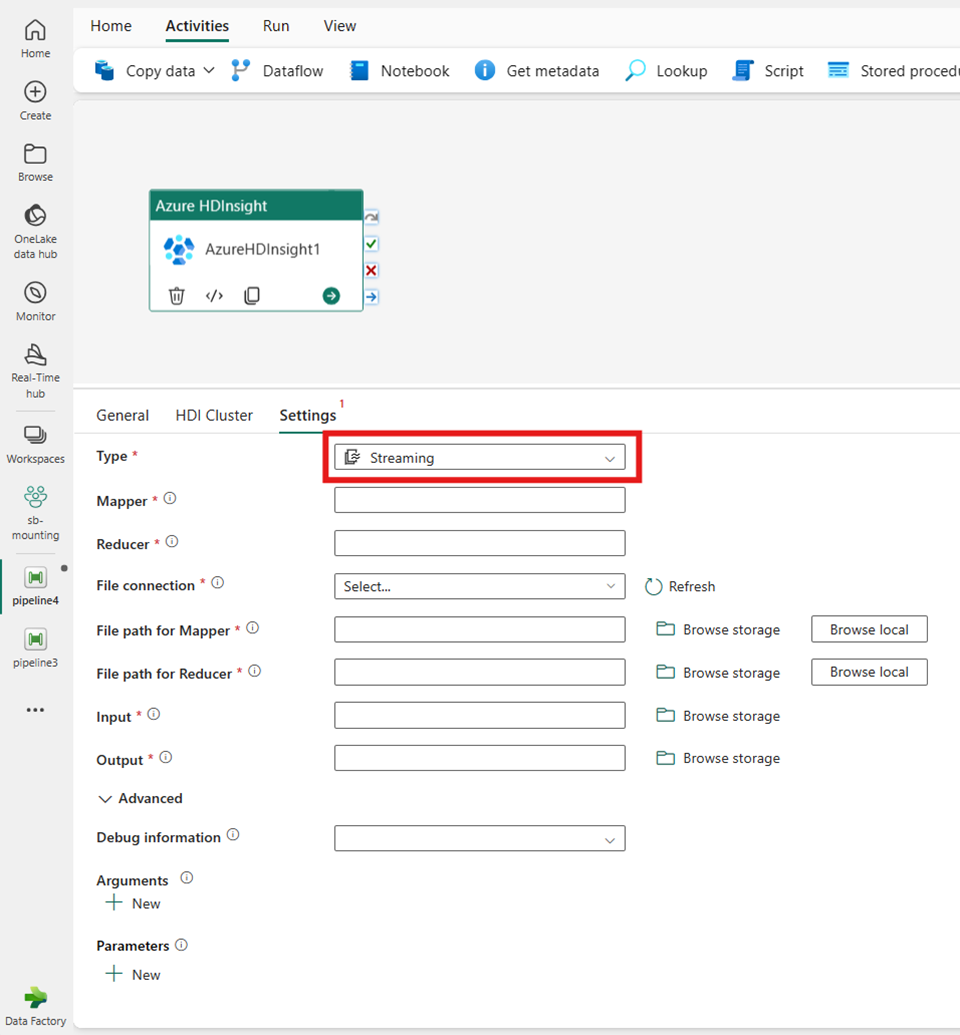
Стриминг
Если выбрать потоковую передачу для типа, действие вызывает программу потоковой передачи. Укажите имена Mapper и Reducer, и при необходимости можно указать подключение к файлу, ссылающееся на учетную запись хранения, содержащую тип потоковой передачи. По умолчанию используется подключение к хранилищу, указанное на вкладке кластера HDI. Необходимо указать путь к файлу для Mapper и путь к файлу для Reducer для выполнения в Azure HDInsight. Добавьте параметры ввода и вывода, а также для пути WASB. При необходимости можно указать дополнительные конфигурации, такие как сведения об отладке, аргументы и параметры в разделе "Дополнительно".
Справочник по свойствам
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для потоковой передачи Hadoop тип действия — HDInsightStreaming. | Да |
| картограф | Указывает имя исполняемого файла маппера. | Да |
| редуктор | Указывает имя исполняемого файла редуктора. | Да |
| комбайн | Указывает имя исполняемого файла программы-комбайнера. | Нет |
| Подключение к файлу | Ссылка на связанную службу хранилища Azure, используемую для хранения программ сопоставителя, комбайнера и редуктора, которые должны быть выполнены. | Нет |
| Здесь поддерживаются только подключения к Azure Blob-хранилищу и ADLS Gen2. Если это подключение не указано, используется подключение к хранилищу, определенное в подключении HDInsight. | ||
| путь к файлу | Предоставьте список путей к программам Mapper, Combiner и Reducer, хранящимся в службе хранилища Azure, на которые указывает соединение с файлом. | Да |
| ввод | Указывает путь WASB к входному файлу для маппера. | Да |
| вывод | Указывает WASB путь к выходному файлу для редьюсера. | Да |
| getDebugInfo | Указывает, когда файлы журнала копируются в службу хранилища Azure, используемую кластером HDInsight или определенную scriptLinkedService. | Нет |
| Допустимые значения: Нет, Всегда или Ошибка. Значение по умолчанию: None. | ||
| аргументы | Указывает массив аргументов для задания Hadoop. Аргументы передаются в качестве аргументов командной строки в каждую задачу. | Нет |
| определяет | Укажите параметры в виде пар "ключ/значение" для их последующего использования в скрипте Hive. | Нет |
Сохраните и запустите или запланируйте выполнение конвейера.
Перейдите на вкладку "Главная " в верхней части редактора конвейера и нажмите кнопку "Сохранить", чтобы сохранить конвейер. Выберите "Выполнить" , чтобы запустить его напрямую или запланировать выполнение в определенный момент времени или интервалы. Дополнительные сведения о запусках конвейера см. в статье "Планирование запусков конвейера".

После выполнения можно отслеживать выполнение конвейера и просматривать журнал выполнения с вкладки "Выходные данные " под холстом.