Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Действие Azure Databricks в Фабрике данных для Microsoft Fabric позволяет управлять следующими заданиями Azure Databricks:
- Записная книжка
- Банка
- Питон
- Job
В этой статье приведены пошаговые инструкции по созданию действия Azure Databricks с помощью интерфейса фабрики данных.
Предпосылки
Чтобы приступить к работе, необходимо выполнить следующие предварительные требования:
- У вас должен быть доступ к клиенту Microsoft Fabric с подготовленной вычислительной мощностью. Вы можете попробовать Fabric с бесплатной пробной версией.
- Рабочая область Fabric, назначенная этой емкости.
Настройка активности в Azure Databricks
Чтобы использовать действие Azure Databricks в конвейере, выполните следующие действия.
Настройка подключения
Создайте конвейер в рабочей области.
Выберите Добавить активность конвейера и найдите Azure Databricks.
Кроме того, вы можете найти Azure Databricks в панели действий конвейера и выбрать его, чтобы добавить на полотно конвейера.
Выберите новое действие Azure Databricks на холсте, если оно еще не выбрано.
Ознакомьтесь с руководством по общим параметрам , чтобы настроить вкладку "Общие параметры".
Настройка кластеров
Перейдите на вкладку "Кластер ". Затем можно выбрать существующее или создать подключение Azure Databricks, а затем выбрать новый кластер заданий, существующий интерактивный кластер или существующий пул экземпляров.
В зависимости от того, что вы выбрали для кластера, заполните соответствующие поля, как показано.
- В новом кластере заданий и существующем пуле экземпляров также есть возможность настроить количество рабочих узлов и включить спотовые экземпляры.
Кроме того, можно указать другие параметры кластера, такие как политика кластера, конфигурация Spark, переменные среды Spark и настраиваемые теги, необходимые для подключаемого кластера. Скрипты databricks init и путь назначения журнала кластера также можно добавить в дополнительные параметры кластера.
Замечание
Все расширенные свойства кластера и динамические выражения, поддерживаемые в связанной службе Фабрики данных Azure Databricks, теперь также поддерживаются в действии Azure Databricks в Microsoft Fabric в разделе "Дополнительная конфигурация кластера" в пользовательском интерфейсе. Так как эти свойства теперь включены в пользовательский интерфейс действия, их можно использовать с выражением (динамическим содержимым) без необходимости в расширенной спецификации JSON.
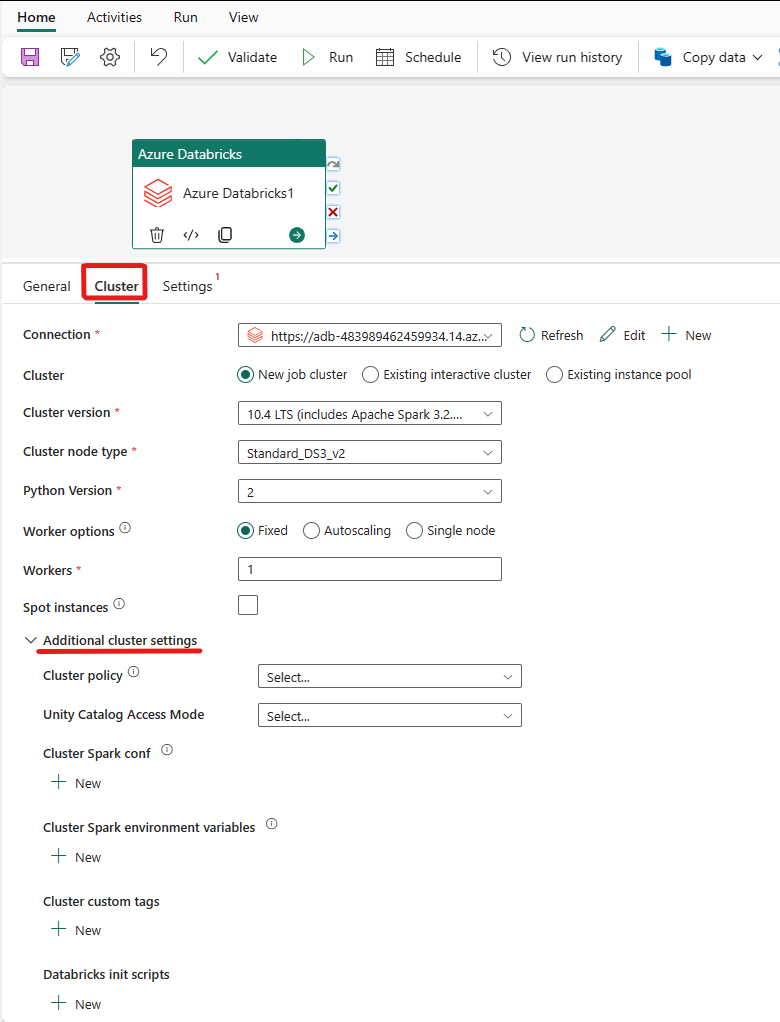
Действие Azure Databricks теперь также поддерживает поддержку политики кластера и каталога Unity.
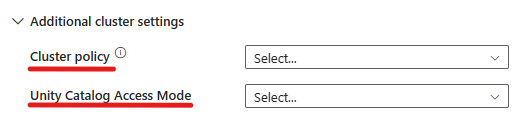
- В разделе "Дополнительные параметры" можно выбрать политику кластера , чтобы указать, какие конфигурации кластера разрешены.
- Кроме того, в разделе "Дополнительные параметры" можно настроить режим доступа к каталогу Unity для дополнительной безопасности. Доступные типы режима доступа :
- Режим доступа к одному пользователю Этот режим предназначен для сценариев, в которых каждый кластер используется одним пользователем. Это гарантирует, что доступ к данным в кластере ограничен только этим пользователем. Этот режим полезен для задач, требующих изоляции и обработки отдельных данных.
- Режим общего доступа В этом режиме несколько пользователей могут получить доступ к одному кластеру. Он объединяет управление данными каталога Unity с устаревшими списками управления доступом к таблицам (ACL). Этот режим обеспечивает совместный доступ к данным при сохранении протоколов управления и безопасности. Однако он имеет определенные ограничения, такие как отсутствие поддержки Databricks Runtime ML, задания Spark-submit и определенных API Spark и определяемых пользователем функций.
- Нет режима доступа Этот режим отключает взаимодействие с каталогом Unity, то есть кластеры не имеют доступа к данным, управляемым каталогом Unity. Этот режим полезен для рабочих нагрузок, которые не требуют функций управления каталогом Unity.
Настройка параметров
Выбрав вкладку Параметры, вы можете выбрать один из 4 вариантов того, какой тип Azure Databricks вы хотите оркестрировать.
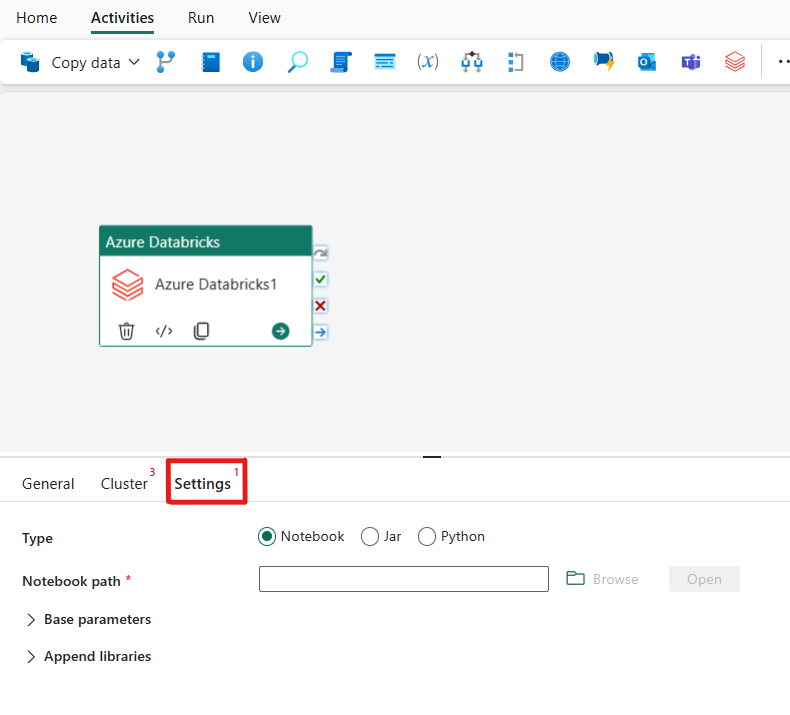
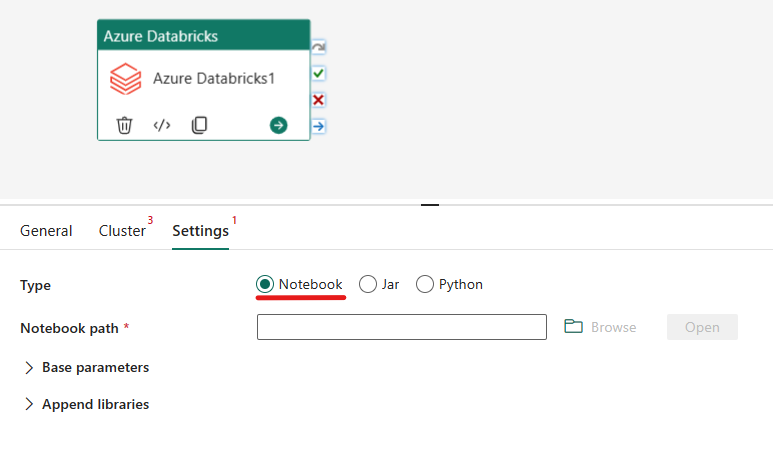
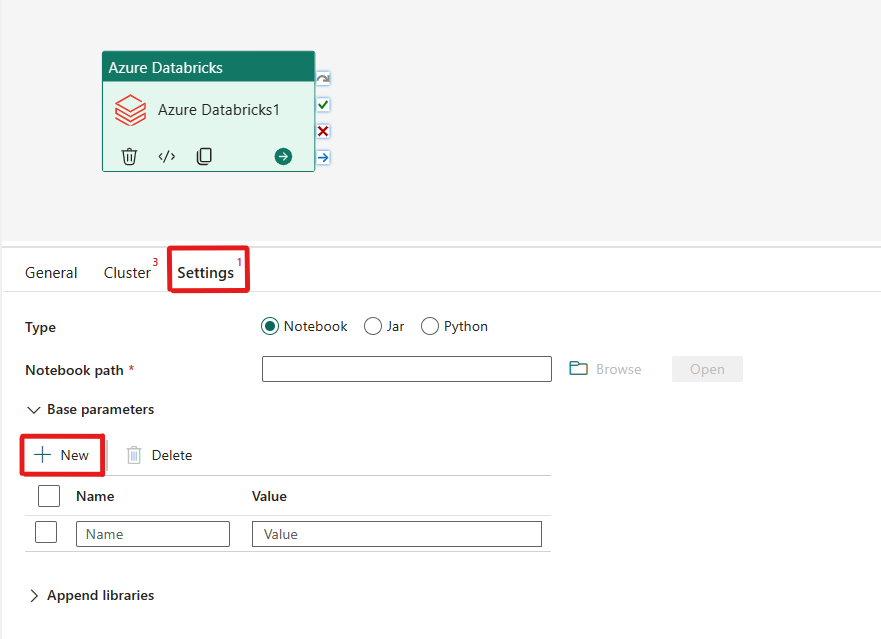
Организация работы с типом Notebook в активности Azure Databricks.
На вкладке "Параметры" можно выбрать переключатель "Записная книжка" , чтобы запустить записную книжку. Для выполнения задания необходимо указать путь к записной книжке для выполнения в Azure Databricks, необязательные базовые параметры для передачи в записную книжку, а также любые дополнительные библиотеки для установки в кластере.
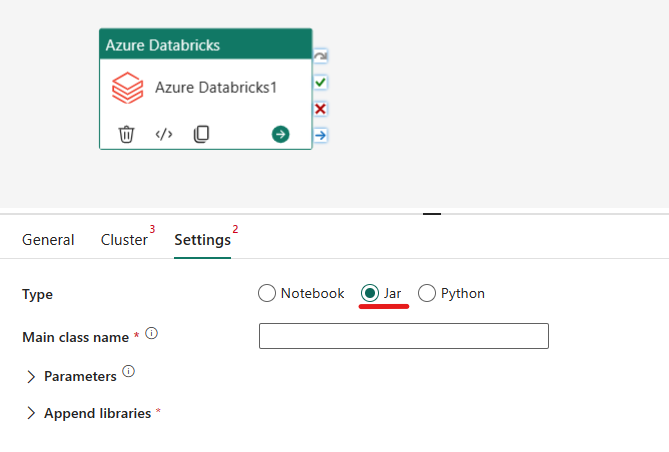
Оркестрация активности типа Jar в Azure Databricks.
На вкладке "Параметры" можно выбрать переключатель Jar для запуска jar-файла. Необходимо указать имя класса, выполняемого в Azure Databricks, необязательные базовые параметры, передаваемые jar-файлу, и все дополнительные библиотеки, которые должны быть установлены в кластере для выполнения задания.
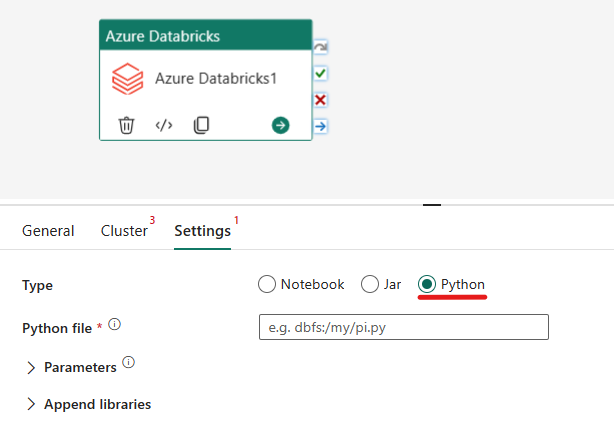
Организация задач Python в активности Azure Databricks:
На вкладке "Параметры" можно выбрать переключатель Python для запуска файла Python. Необходимо указать путь в Azure Databricks к исполняемому файлу Python, необязательным базовым параметрам, передаваемым и любым дополнительным библиотекам, установленным в кластере для выполнения задания.
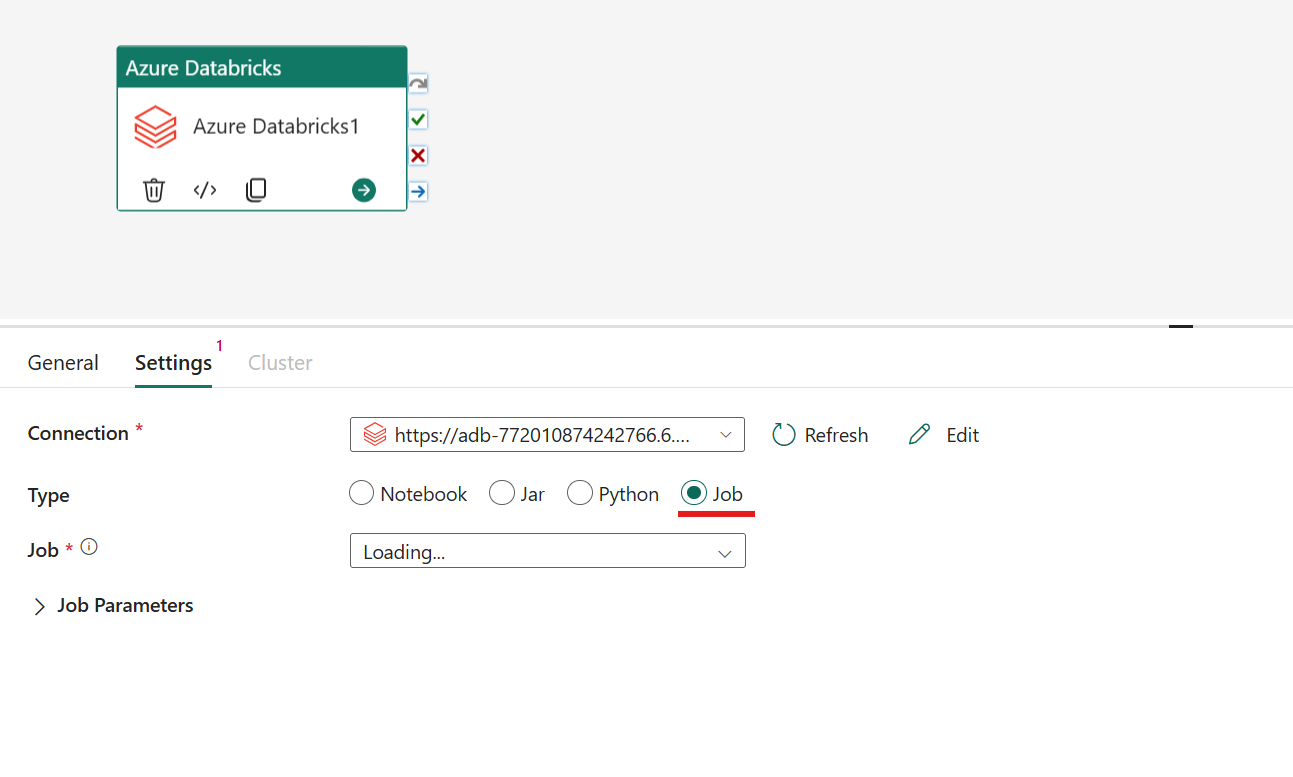
Организация типа задания в задаче Azure Databricks:
На вкладке "Параметры" можно выбрать переключатель Job, чтобы запустить задание Databricks. В раскрывающемся списке необходимо указать задание, которое будет выполняться в Azure Databricks, и любые необязательные параметры задания, которые нужно передать. С помощью этого параметра можно выполнять бессерверные задания.
Поддерживаемые библиотеки для задачи Azure Databricks
В приведенном выше определении действия Databricks можно указать следующие типы библиотек: jar, яйцо, whl, maven, pypi, cran.
Дополнительные сведения см. в документации по Databricks для типов библиотек.
Обмен параметрами между активностью Azure Databricks и конвейерами
Параметры можно передать в записные книжки с помощью свойства baseParameters в действии Databricks.
Иногда может потребоваться возвращать значения из записной книжки в службу для управления потоком выполнения или использовать в дальнейших действиях (с ограничением размера 2 МБ).
Например, в вашей записной книжке можно вызвать dbutils.notebook.exit("returnValue"), и соответствующий "returnValue" будет возвращён в службу.
Выходные данные в службе можно использовать с помощью таких выражений, как
@{activity('databricks activity name').output.runOutput}.
Сохраните и запустите конвейер или запланируйте его
Перейдите на вкладку "Главная " в верхней части редактора конвейера и нажмите кнопку "Сохранить", чтобы сохранить конвейер. Выберите "Выполнить" , чтобы запустить его напрямую или запланировать выполнение в определенный момент времени или интервалы. Дополнительные сведения о запусках конвейера см. в статье "Планирование запусков конвейера".

После выполнения можно отслеживать выполнение конвейера и просматривать журнал выполнения с вкладки "Выходные данные " под холстом.