Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Местный механизм выполнения — это революционное усовершенствование выполнения заданий Apache Spark в Microsoft Fabric. Этот векторизованный механизм оптимизирует производительность и эффективность запросов Spark, выполняя их непосредственно в инфраструктуре Lakehouse. Бесшовная интеграция двигателя означает, что он не требует изменений кода и избегает привязки к поставщику. Он поддерживает API Apache Spark и совместим с средой выполнения 1.3 (Apache Spark 3.5) и средой выполнения 2.0 (Apache Spark 4.0) и работает с форматами Parquet, Delta и CSV. Независимо от расположения данных в OneLake или при доступе к данным через сочетания клавиш, собственный механизм выполнения повышает эффективность и производительность.
Собственный модуль выполнения значительно повышает производительность запросов при минимизации операционных затрат. Фактические результаты зависят от характеристик рабочей нагрузки и конфигурации. Движок справляется с широким спектром сценариев обработки данных, начиная от рутинного принятия данных, пакетных заданий и задач ETL (извлечение, преобразование, загрузка) до сложной аналитики данных и интерактивных реагирующих запросов. Пользователи получают преимущества от ускорения обработки, повышенной пропускной способности и оптимизированного использования ресурсов.
Нативный исполнительный механизм основан на двух ключевых компонентах OSS: Velox, библиотеке для ускорения баз данных на C++, представленной Meta, и Apache Gluten (находится в инкубации), промежуточном слое, который отвечает за разгрузку выполнения SQL-движков на основе JVM на нативные исполнительные механизмы, представленные Intel.
Поддерживаемые операторы перенаправляются из Spark на основе JVM на векторизированный путь выполнения C++, обеспечивая обработку с использованием columnar и ускоренное обработка с помощью SIMD, с собственной поддержкой форматов Parquet и Delta. Нативный механизм сохраняет ключевые оптимизации запросов Fabric Spark, включая адаптивное выполнение запросов (AQE), переписывание на основе затрат, обрезку столбцов и оптимизацию предиката, поэтому эти оптимизаторы остаются полностью активными при разгрузке операторов. Движок также поддерживает параллельную загрузку моментальных снимков Delta и ускоряет операции, которые получают преимущества от Z-упорядочения и кластеризации Liquid в таблицах Delta, что обеспечивает дополнительный прирост производительности для упорядоченных макетов данных.
Когда следует использовать собственный исполнительный механизм
Собственный механизм выполнения предлагает решение для выполнения запросов в крупномасштабных наборах данных; он оптимизирует производительность с помощью собственных возможностей базовых источников данных и минимизации затрат, связанных с перемещением данных и сериализацией в традиционных средах Spark. Подсистема поддерживает различные операторы и типы данных, включая хэш-агрегат свертки, присоединение к вложенным циклам широковещательной трансляции (BNLJ) и точные форматы меток времени. Тем не менее, чтобы полностью воспользоваться возможностями подсистемы, следует рассмотреть его оптимальные варианты использования:
- Механизм эффективен при работе с данными в форматах Parquet и Delta, которые он может обрабатывать нативно и эффективно.
- Запросы, включающие сложные преобразования и агрегации, значительно выигрывают от возможностей векторизации и обработки столбцов движка.
- Повышение производительности является наиболее заметным в сценариях, когда запросы не активируют резервный механизм, избегая неподдерживаемых функций или выражений.
- Движок хорошо подходит для запросов, которые требуют значительных вычислительных ресурсов, а не являются простыми или обусловленными операциями ввода-вывода.
Дополнительные сведения об операторах и функциях, поддерживаемых нативной системой исполнения, смотрите в документации Apache Gluten.
Включите собственный механизм выполнения
Чтобы использовать полные возможности собственной исполняющей среды на этапе предварительной версии, необходимы определенные конфигурации. В следующих процедурах показано, как активировать эту функцию для записных книжек, определений заданий Spark и всей среды.
Внимание
Собственный модуль выполнения поддерживает среду выполнения 1.3 (Apache Spark 3.5, Delta Lake 3.2) и Runtime 2.0 (Apache Spark 4.0, Delta Lake 4.0)). С выпуском собственного модуля выполнения в среде выполнения 1.3 поддержка предыдущей версии, среда выполнения 1.2 (Apache Spark 3.4, Delta Lake 2.4) прекращена. Мы рекомендуем всем клиентам обновиться до последней версии среды выполнения 1.3. Если вы используете модуль нативного исполнения в среде выполнения 1.2, то нативное ускорение будет отключено.
Включение на уровне среды
Чтобы обеспечить единообразное улучшение производительности, включите собственный модуль выполнения во всех заданиях и записных книжках, связанных с вашей средой:
Перейдите в рабочую область, содержащую среду, и выберите среду. Если у вас нет созданной среды, см. статью Создать, настроить и использовать среду в Fabric.
В разделе вычислений Spark выберите "Ускорение".
Установите флажок Включить нативный движок выполнения.
Сохраните и опубликуйте изменения.
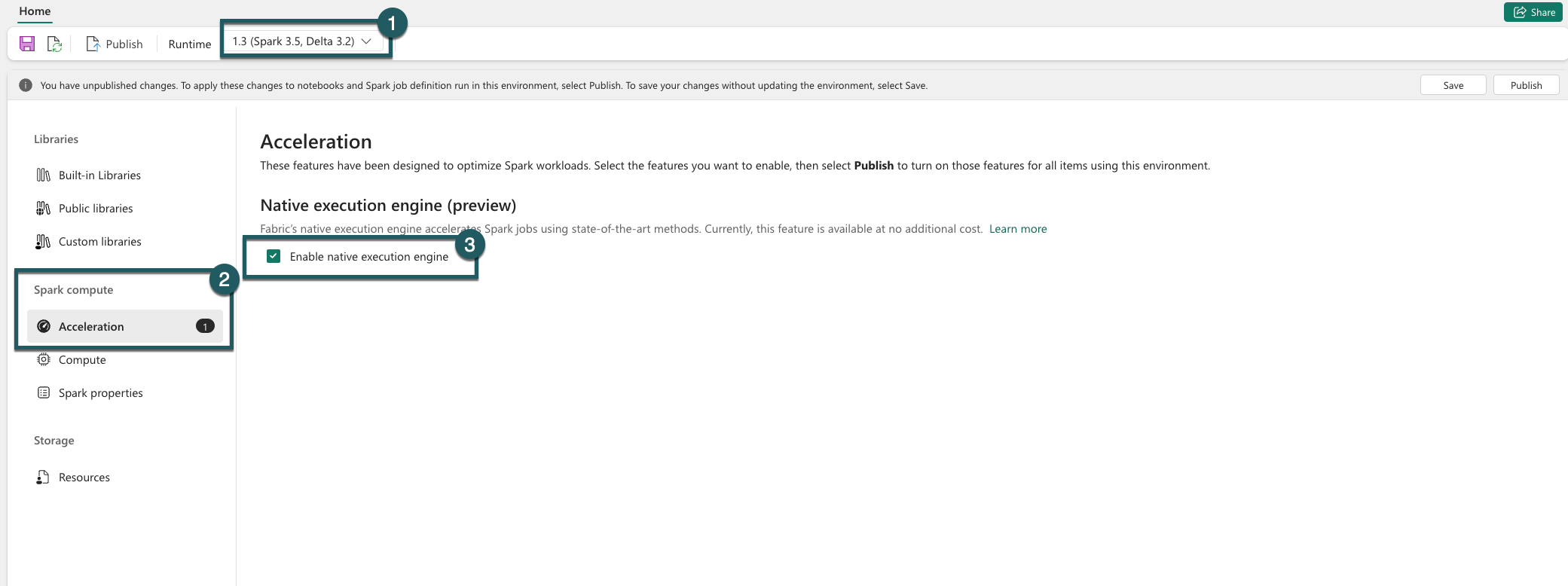

При включении на уровне среды все последующие задания и записные книжки наследуют этот параметр. Это наследование гарантирует, что любые новые сеансы или ресурсы, созданные в среде, автоматически получают преимущества от расширенных возможностей выполнения.
Внимание
Ранее собственный модуль выполнения был включен с помощью параметров Spark в конфигурации среды. Теперь родной механизм выполнения может быть включён более легко с помощью переключателя на вкладке «Ускорение» параметров среды. Чтобы продолжить использование, перейдите на вкладку "Ускорение " и включите переключатель. Вы также можете включить его с помощью свойств Spark, если они предпочтительнее.
Включение для блокнота или определения задания Spark
Вы также можете включить родной движок выполнения для отдельной записной книжки или определения задания Spark, необходимо добавить необходимые конфигурации в начале исполняемого сценария.
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Для записных книжек вставьте необходимые команды конфигурации в первую ячейку. Для определений заданий Spark включите конфигурации в передней строке определения задания Spark. Нативный исполнительный движок интегрирован с живыми пулами, поэтому после включения функции она начинает действовать немедленно, не требуя от вас запуска нового сеанса.
Управление уровнем запроса
Механизмы для включения Native Execution Engine на уровнях арендатора, рабочей области и среды, бесшовно интегрированные с пользовательским интерфейсом, находятся в активной разработке. В то же время можно отключить собственный обработчик выполнения для конкретных запросов, особенно если они включают операторы, которые в настоящее время не поддерживаются (см . ограничения). Чтобы отключить, задайте для конфигурации Spark spark.native.enabled значение false для конкретной ячейки, содержащей запрос.
%%sql
SET spark.native.enabled=FALSE;

После выполнения запроса, в котором отключен собственный обработчик выполнения, необходимо повторно включить его для последующих ячеек, задав spark.native.enabled значение true. Этот шаг необходим, так как Spark выполняет ячейки кода последовательно.
%%sql
SET spark.native.enabled=TRUE;
Определение операций, выполняемых подсистемой
Существует несколько методов, чтобы определить, был ли оператор в задании Apache Spark обработан с помощью собственного обработчика выполнения.
Пользовательский интерфейс Spark и сервер журнала Spark
Перейдите на пользовательский интерфейс Spark или сервер истории Spark, чтобы найти запрос, который вам нужно проверить. Чтобы получить доступ к веб-интерфейсу Spark, перейдите к определению задания Spark и запустите его. На вкладке Запуски выберите ... рядом с именем приложения и выберите Открыть веб-интерфейс Spark. Вы также можете получить доступ к пользовательскому интерфейсу Spark на вкладке монитора

В плане запроса, отображаемом в интерфейсе Spark, найдите все имена узлов, которые заканчиваются суффиксом Transformer, *NativeFileScan или VeloxColumnarToRowExec. Суффикс указывает, что системный исполнительный механизм выполнил операцию. Например, узлы могут быть помечены как RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinTransformer или BroadcastNestedLoopJoinExecTransformer. Для источников данных CSV собственные узлы сканирования данных могут отображаться как узлы сканирования файлов или преобразователей в пользовательском интерфейсе Spark, аналогично узлам сканирования Parquet и Delta.

Объяснение DataFrame
Кроме того, можно выполнить df.explain() команду в записной книжке, чтобы просмотреть план выполнения. В выходных данных найдите те же Transformer, *NativeFileScan или VeloxColumnarToRowExec суффиксы. Этот метод позволяет быстро подтвердить, обрабатываются ли определенные операции нативным движком выполнения.

Оповещения советника Fabric Spark
Помощник Fabric Spark обеспечивает видимость аварийного переключения в режиме реального времени во время выполнения ячеек блокнота. Когда оператор или сегмент плана возвращается к Spark, работающему на основе JVM, вместо использования собственного пути, Advisor показывает оповещение непосредственно в выходных данных ячейки записной книжки, что помогает быстро определять неподдерживаемые операторы или конфигурации, не покидая записную книжку. Эти оповещения можно использовать для диагностики ситуации, когда не применяется native offload, и принятия решения о корректировке запроса или конфигурации.
Резервный механизм
В некоторых случаях собственный обработчик выполнения может не выполнять запрос из-за таких причин, как неподдерживаемые функции. В таких случаях операция возвращается к традиционному движку Spark. Этот механизм автоматической резервной передачи гарантирует, что рабочий процесс не прерывается.


Мониторинг запросов и кадров данных, выполняемых подсистемой
Чтобы лучше понять, как подсистема машинного выполнения применяется к sql-запросам и операциям DataFrame, а также для детализации до уровней этапов и операторов, можно обратиться к пользовательскому интерфейсу Spark и серверу журнала Spark для получения более подробных сведений о выполнении собственного модуля.
Вкладка "Подсистема нативного выполнения"
Чтобы просмотреть сведения о сборке Gluten и выполнении запросов, перейдите на новую вкладку "Gluten SQL / DataFrame". Таблица "Запросы" содержит аналитические сведения о количестве узлов, работающих на собственном движке, и тех, которые переходят на JVM для каждого запроса.

Граф выполнения запросов
Вы также можете выбрать описание запроса для визуализации плана выполнения запросов Apache Spark. Граф выполнения предоставляет собственные сведения о выполнении на этапах и их соответствующих операциях. Цвета фона отличают обработчики выполнения: зеленый представляет собственный обработчик выполнения, а светло-синий цвет указывает, что операция выполняется на подсистеме JVM по умолчанию.

Ограничения
Хотя подсистема машинного выполнения (NEE) в Microsoft Fabric значительно повышает производительность заданий Apache Spark, в настоящее время она имеет следующие ограничения:
Существующие ограничения
Несовместимые функции Spark: встроенный двигатель выполнения в настоящее время не поддерживает определяемые пользователем функции (ОПФ),
array_containsфункцию или структурированную потоковую обработку. Если эти функции или неподдерживаемые функции используются напрямую или через импортированные библиотеки, Spark вернется к его обработчику по умолчанию.Неподдерживаемые форматы файлов: запросы к форматам
JSONиXMLне ускоряются встроенным движком выполнения. Они по умолчанию возвращаются в обычный модуль JVM Spark для выполнения. Теперь CSV поддерживается с помощью векторизованного средства синтаксического анализа CSV.Режим ANSI не поддерживается: подсистема машинного выполнения не поддерживает режим SQL ANSI. Если этот параметр включен, выполнение возвращается к подсистеме Vanilla Spark.
Несоответствия типов фильтра дат: Чтобы воспользоваться ускорением, которое обеспечивает собственный движок выполнения, убедитесь, что обе стороны сравнения дат совпадают по типу данных. Например, вместо сравнения столбца
DATETIMEсо строковым литералом явно приведите его тип, как показано:CAST(order_date AS DATE) = '2024-05-20'
Другие рекомендации и ограничения
Несоответствие приведения типов из десятичного в число с плавающей точкой: При приведении из
DECIMALвFLOATSpark сохраняет точность, преобразуя в строку и выполняя синтаксический анализ. NEE (через Velox) напрямую преобразует из внутреннегоint128_tпредставления, что может привести к погрешностям в округлении.Ошибки конфигурации часового пояса : установка нераспознанного часового пояса в Spark приводит к сбою задания в NEE, в то время как JVM Spark обрабатывает его корректно. Рассмотрим пример.
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEEНесогласованное округление: функция ведет себя по-разному в NEE из-за зависимости от , которая не соответствует логике округления, используемой в Spark. Это может привести к числовым несоответствиям в результатах округления.
Отсутствует проверка на дублирование ключей в функции
map(): когдаspark.sql.mapKeyDedupPolicyустановлено значение EXCEPTION, Spark выдает ошибку для дублирующихся ключей. В настоящее время NEE пропускает эту проверку и позволяет запросу ошибочно завершаться успешно.
Пример:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Изменение порядка при
collect_list()сортировке: при использованииDISTRIBUTE BYиSORT BYSpark сохраняет порядок элементов вcollect_list(). NEE может возвращать значения в другом порядке из-за различий в перемешивании, что может привести к несоответствию ожиданий для логики, чувствительной к порядку.Несоответствие промежуточного типа для
collect_list()/collect_set(): Spark используетBINARYв качестве промежуточного типа для этих агрегаций, в то время как NEE используетARRAY. Это несоответствие может привести к проблемам совместимости во время планирования запросов или выполнения.Управляемые частные конечные точки, необходимые для доступа к хранилищу: если включен механизм выполнения с использованием native (NEE), и задания Spark пытаются получить доступ к учетной записи хранилища с помощью управляемой частной конечной точки, пользователям необходимо настроить отдельные управляемые частные конечные точки как для конечных точек blob-объектов (blob.core.windows.net), так и для конечных точек файловой системы (dfs.core.windows.net), даже если они указывают на одну и ту же учетную запись хранилища. Для обеих конечных точек нельзя повторно использовать одну конечную точку. Это текущее ограничение, и может потребоваться дополнительная конфигурация сети при активации встроенного механизма выполнения в рабочей области с управляемыми частными конечными точками для учетных записей хранения.