Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве описано, как читать и записывать данные в Azure Lakehouse с помощью записной книжки. Fabric поддерживает API Spark и API Pandas для достижения этой цели.
Загрузка данных с помощью API Apache Spark
В ячейке кода записной книжки используйте следующий пример кода, чтобы считывать данные из источника и загружать их в файлы, таблицы или оба раздела озера.
Чтобы указать расположение для чтения, можно использовать относительный путь, если данные находятся из озера по умолчанию текущей записной книжки. Или, если данные из другого озера, можно использовать абсолютный путь к файловой системе BLOB-объектов Azure (ABFS). Скопируйте этот путь из контекстного меню данных.
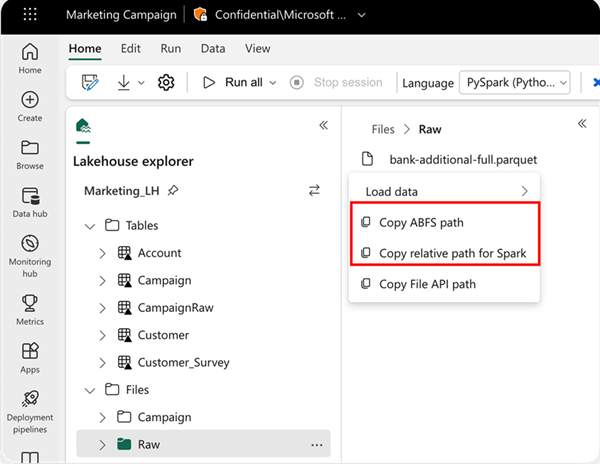
Скопируйте путь ABFS: этот параметр возвращает абсолютный путь к файлу.
Скопируйте относительный путь для Spark: этот параметр возвращает относительный путь к файлу в вашем озерном доме по умолчанию.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Загрузка данных с помощью API Pandas
Для поддержки API Pandas хранилище озера по умолчанию автоматически подключается к записной книжке. Точка подключения — "/lakehouse/default/". Эту точку подключения можно использовать для чтения и записи данных из или в озеро по умолчанию. Параметр "Копировать путь к API файла" из контекстного меню возвращает путь к API файлов из этой точки подключения. Путь, возвращаемый из параметра Copy ABFS, также работает для API Pandas.
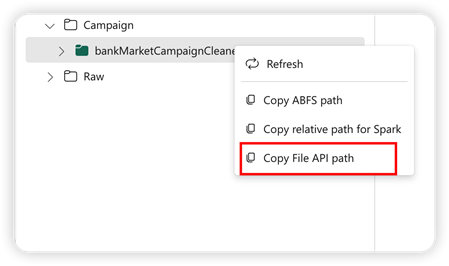
Путь к API копирования: этот параметр возвращает путь под точкой подключения озера по умолчанию.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://[email protected]/Marketing_LH.Lakehouse/Files/sample.parquet")
Совет
Для API Spark используйте параметр "Копировать путь ABFS" или "Копировать относительный путь" для Spark , чтобы получить путь к файлу. Для API Pandas используйте параметр "Копировать путь ABFS" или путь к API копирования файлов, чтобы получить путь к файлу.
Самый быстрый способ работы кода с API Spark или API Pandas — использовать параметр загрузки данных и выбрать API, который требуется использовать. Код автоматически создается в новой ячейке кода записной книжки.
