Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Обозреватель данных Azure Synapse Analytics (предварительная версия) будет прекращен 7 октября 2025 г. После этой даты рабочие нагрузки, работающие в Synapse Data Explorer, будут удалены, а связанные данные приложения будут потеряны. Мы настоятельно рекомендуем мигрировать в Eventhouse на платформе Microsoft Fabric.
Программа Microsoft Cloud Migration Factory (CMF) предназначена для поддержки клиентов при миграции в Fabric. Программа предлагает практические ресурсы клавиатуры без затрат для клиента. Эти ресурсы назначаются в течение 6–8 недель с предопределенной и согласованной областью. Номинации клиентов принимаются от команды учетных записей Microsoft или непосредственно путем отправки запроса на помощь команде CMF.
Прием данных — это процесс, используемый для загрузки записей данных из одного или нескольких источников для импорта данных в таблицу в пуле Azure Synapse Data Explorer. После принятия данные становятся доступными для запроса.
Служба управления данными Azure Synapse Data Explorer, которая отвечает за прием данных, реализует следующий процесс:
- Извлекает данные из пакетов или потоковой передачи из внешнего источника и считывает запросы из ожидающей очереди Azure.
- Пакетные данные, поступающие в ту же базу данных и таблицу, оптимизированы для эффективной загрузки данных.
- Исходные данные проверяются и формат преобразуется при необходимости.
- Дополнительные манипуляции с данными, включая сопоставление схемы, упорядочение, индексирование, кодировку и сжатие данных.
- Данные сохраняются в хранилище в соответствии с заданной политикой хранения.
- Прием данных фиксируется в подсистеме, где она доступна для запроса.
Поддерживаемые форматы данных, свойства и разрешения
Свойства приема: свойства, влияющие на прием данных (например, тег, сопоставление, время создания).
Разрешения. Для приема данных процессу требуются разрешения уровня базы данных ingestor. Для других действий, таких как запрос, могут потребоваться разрешения администратора базы данных, пользователя базы данных или администратора таблицы.
Пакетная загрузка и потоковая загрузка
Пакетная загрузка выполняет пакетную обработку данных и оптимизирована для обеспечения высокой пропускной способности при загрузке. Этот метод является предпочтительным и наиболее производительным типом приема. Данные собираются в пакеты в соответствии со свойствами загрузки. Небольшие пакеты данных объединяются и оптимизированы для быстрого выполнения запросов. Политику пакетной обработки данных можно задать в базах данных или таблицах. По умолчанию максимальное значение пакетной обработки составляет 5 минут, 1000 элементов или общий размер 1 ГБ. Ограничение размера данных для команды пакетного добавления данных составляет 4 ГБ.
Потоковый ввод — это непрерывная загрузка данных из потокового источника. Потоковая загрузка обеспечивает почти в реальном времени обработку небольших наборов данных по каждой таблице. Данные изначально загружаются в хранилище строк, а затем перемещаются в экстенты хранилища столбцов.
Методы приема и средства
Azure Synapse Data Explorer поддерживает несколько методов приема, каждый из которых имеет собственные целевые сценарии. Эти методы включают ингестионные инструменты, соединители и подключаемые модули для различных служб, управляемые конвейеры, программное принятие с использованием пакетов SDK и прямой доступ к ингэстионному процессу.
Прием с помощью управляемых конвейеров
Для организаций, которые хотят, чтобы управление (ограничением скорости, повторными попытками, мониторами, уведомлениями и т. д.) выполнялось внешней службой, использование коннектора, скорее всего, является наиболее подходящим решением. Прием в очереди подходит для больших томов данных. Azure Synapse Data Explorer поддерживает следующие Azure Pipelines:
- Концентратор событий: конвейер, который передает события из служб в Azure Synapse Data Explorer. Дополнительные сведения см. в разделе "Прием данных из Концентратора событий" в Azure Synapse Data Explorer.
- Конвейеры Synapse: полностью управляемая служба интеграции данных для аналитических рабочих нагрузок в конвейерах Synapse подключается к более чем 90 поддерживаемым источникам для обеспечения эффективной и устойчивой передачи данных. Конвейеры Synapse подготавливают, трансформируют и обогащают данные для получения аналитических сведений, которые можно отслеживать в различных форматах. Эта служба может использоваться в качестве одноразового решения на периодической временной шкале или активироваться определенными событиями.
Программная загрузка с использованием SDK
Azure Synapse Data Explorer предоставляет пакеты SDK, которые можно использовать для приема запросов и данных. Программный прием оптимизирован для снижения издержек на поглощение (COGs), минимизируя транзакции хранения во время и после процесса поглощения.
Перед началом работы выполните следующие действия, чтобы получить конечные точки пула Data Explorer для настройки программной загрузки.
В Synapse Studio в области навигации слева выберите Управление>пулы Data Explorer.
Выберите пул обозревателя данных, который вы хотите использовать для просмотра сведений.
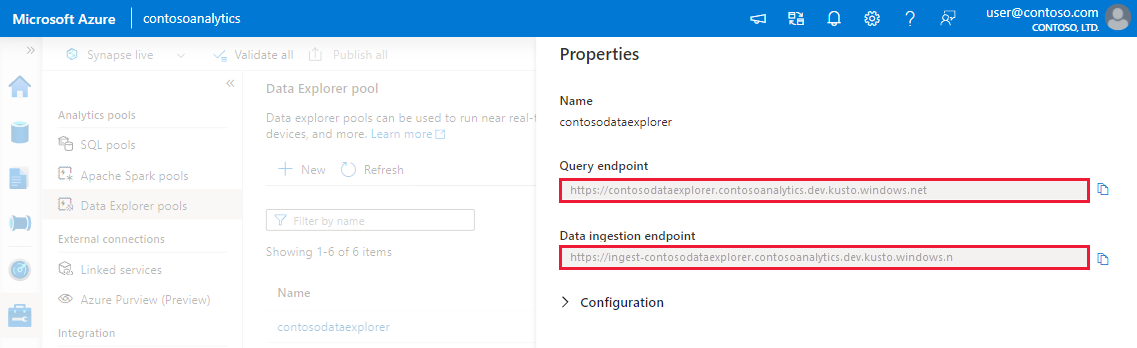
Запишите конечные точки приема запросов и данных. Используйте конечную точку запроса в качестве кластера при настройке подключений к пулу Обозревателя данных. При настройке пакетов SDK для приема данных используйте конечную точку приема данных.
Доступные пакеты SDK и проекты с открытым кодом
Tools
- Прием по одному щелчку: позволяет быстро получать данные путем создания и настройки таблиц из широкого диапазона типов источников. Однократное нажатие для загрузки автоматически предлагает таблицы и структуры сопоставления на основе источника данных в Azure Synapse Data Explorer. Одним щелчком загрузки можно использовать для однократной загрузки данных или для определения непрерывной загрузки через Event Grid в контейнер, в который были загружены данные.
Команды управления приемом данных в языке запросов Kusto
Существует ряд методов, с помощью которых данные могут быть загружены непосредственно в систему командами Языка запросов Kusto (KQL). Поскольку этот метод обходит службы управления данными, он подходит только для изучения и прототипирования. Не используйте этот метод в рабочих или высоконагруженных сценариях.
Встраиваемое поглощение: Команда .ingest inline отправляется в подсистему, с данными для поглощения, являющимися частью текста команды. Этот метод предназначен для импровизированного тестирования.
Прием из запроса: команда управления .set, .append, .set-or-append или .set-or-replace отправляется в движок с данными, определенными косвенно, в качестве результатов запроса или команды.
Прием из хранилища (вытягивание): управляющая команда .ingest into отправляется в движок, с данными, хранящимися во внешнем хранилище (например, в хранилище BLOB-объектов Azure), которое доступно для движка и на которое указывает команда.
Пример использования команд управления приемом см. в разделе "Анализ с помощью обозревателя данных".
Процесс приема
Выбрав наиболее подходящий метод приема для ваших потребностей, сделайте следующее:
Настройка политики хранения
Данные, загруженные в таблицу в Azure Synapse Data Explorer, подлежат действующей политике удержания таблицы. Если политика хранения явно не установлена для таблицы, то она определяется политикой хранения базы данных. Горячее хранение — это функция размера кластера и политики хранения. Прием большего объема данных, чем имеется доступное пространство, приведет первые данные к холодному хранению.
Убедитесь, что политика хранения базы данных подходит для ваших потребностей. Если нет, явно переопределите его на уровне таблицы. Дополнительные сведения см. в политике хранения.
Создание таблицы
Для приема данных необходимо создать таблицу заранее. Используйте один из следующих вариантов:
Создайте таблицу с помощью команды. Пример использования команды создания таблицы см. в разделе "Анализ с помощью обозревателя данных".
Создайте таблицу с помощью One-click Ingestion.
Замечание
Если запись является неполной или поле не может быть проанализировано как обязательный тип данных, соответствующие столбцы таблицы будут заполнены значениями NULL.
Создание сопоставления схем
Сопоставление схем помогает привязать поля исходных данных к столбцам целевой таблицы. Сопоставление позволяет интегрировать данные из разных источников в одну таблицу, с учётом определённых атрибутов. Поддерживаются различные типы сопоставлений, ориентированные на строки (CSV, JSON и AVRO), а также ориентированные на столбцы (Parquet). В большинстве методов сопоставления также могут быть предварительно созданы в таблице и ссылаться на них из параметра команды приема.
Установка политики обновления (необязательно)
Некоторые сопоставления форматов данных, таких как Parquet, JSON и Avro, поддерживают простые и полезные преобразования при поглощении данных. Если сценарий требует более сложной обработки во время приема, используйте политику обновления, которая позволяет упрощенной обработке с помощью команд языка запросов Kusto. Политика обновления автоматически выполняет извлечение и преобразование данных, загруженных из исходной таблицы, и передает преобразованные данные в одну или несколько целевых таблиц. Задайте политику обновления.