Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Если у вас есть индекс vector в Поиск с использованием ИИ Azure, в этой статье объясняется, как:
В этой статье используется REST для иллюстрации. После понимания базового рабочего процесса перейдите к примерам кода Azure SDK в репозитории azure-search-vector-samples, которое предоставляет комплексные решения, включающие векторные запросы.
Вы также можете использовать Search Explorer на портале Azure.
Необходимые условия
Служба Поиск с использованием ИИ Azure в любом регионе и на любом уровне.
Векторный индекс. Проверьте наличие раздела в индексе
vectorSearch, чтобы подтвердить его присутствие.При необходимости добавьте векторизатор в индекс для встроенного преобразования текста в вектор или преобразования изображений в вектор во время запросов.
Visual Studio Code с клиентом REST и примерами данных, если вы хотите выполнить эти примеры самостоятельно. Сведения о начале работы с клиентом REST см. в кратком руководстве: полнотекстовый поиск с помощью REST.
Преобразование входных данных строки запроса в вектор
Для запроса поля вектора сам запрос должен быть вектором.
Одним из способов преобразования строки текстового запроса пользователя в векторное представление является вызов библиотеки внедрения или API в коде приложения. Рекомендуется всегда использовать те же модели внедрения, используемые для создания внедрения в исходные документы. Примеры кода, показывающие как создавать векторные представления, находятся в репозитории azure-search-vector-samples.
Второй подход — использовать встроенную векторизацию, чтобы Поиск с использованием ИИ Azure мог обрабатывать входные и выходные данные векторизации запросов.
Ниже приведен пример строки параметров запроса REST API-интерфейса, отправленной при развертывании модели внедрения эмбеддингов Azure OpenAI.
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
Ожидаемый ответ — 202 при успешном вызове развернутой модели.
Поле embedding в тексте ответа — векторное представление строки inputзапроса. В целях тестирования необходимо скопировать значение массива embeddingvectorQueries.vector в запрос, используя синтаксис, показанный в следующих нескольких разделах.
Фактический ответ на этот вызов POST к развернутой модели включает 1536 эмбеддингов. Для удобства чтения в этом примере показаны только первые несколько векторов.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
В этом подходе код приложения отвечает за подключение к модели, создание внедрения и обработку ответа.
Запрос векторного поиска
В этом разделе показана базовая структура векторного запроса. С помощью портала Azure, REST API или Azure SDKs можно сформулировать векторный запрос.
Если вы мигрируете из 2023-07-01-Preview, будут нарушающие изменения. Дополнительные сведения см. в статье об обновлении до последней версии REST API.
Стабильная версия поддерживает следующее:
-
vectorQueries— это конструкция для векторного поиска. -
vectorQueries.kindустановитеvectorдля массива векторов илиtext, если входные данные являются строкой и если у вас есть векторизатор. -
vectorQueries.vector— это запрос (векторное представление текста или изображения). -
vectorQueries.exhaustive(необязательно) вызывает исчерпывающий KNN во время запроса, даже если поле индексируется для HNSW. -
vectorQueries.fields(необязательно) предназначены для выполнения запросов по определённым полям (до 10 на запрос). -
vectorQueries.weight(необязательно) указывает относительный вес каждого векторного запроса, включенного в операции поиска. Дополнительные сведения см. в разделе "Векторный вес". -
vectorQueries.k— это число совпадений, которые необходимо вернуть.
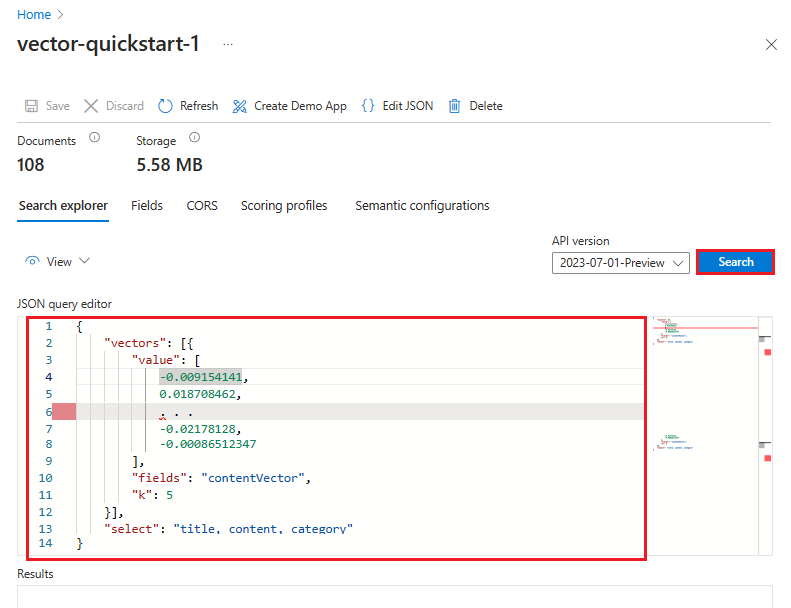
В следующем примере вектор представляет эту строку: "what Azure services support full text search". Запрос предназначен для contentVector поля и возвращает k результаты. Исходный вектор имеет 1536 векторов вложений, которые обрезаются в этом примере для наглядности.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2025-09-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
Ответ векторного запроса
В Поиск с использованием ИИ Azure ответы запросов состоят из всех полей retrievable по умолчанию. Однако обычно результаты поиска ограничиваются подмножеством retrievable полей, перечисляя их в инструкции select .
В векторном запросе тщательно рассмотрите необходимость векторных полей в ответе. Поля векторов не доступны для чтения, поэтому если вы отправляете ответ на веб-страницу, следует выбрать невекторные поля, представляющие результат. Например, если запрос выполняется против contentVector, вы можете вернуть content вместо этого.
Если вы хотите векторные поля в результате, вот пример структуры отклика.
contentVector представляет собой массив строк эмбеддингов, который усечен в этом примере для читаемости. Оценка поиска указывает релевантность. Другие невекторные поля включаются в контекст.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Ключевые моменты:
kопределяет, сколько ближайших результатов возвращаются, в данном случае три. Векторные запросы всегда возвращаютkрезультаты, если существуют хотя быkдокументы, даже если некоторые документы имеют плохое сходство. Это связано с тем, что алгоритм находит ближайшихkсоседей с вектором запроса.Алгоритм векторного поиска определяет
@search.score.Поля в результатах поиска — это либо все
retrievableполя, либо поля в условииselect. Во время выполнения векторного запроса сопоставление выполняется только для векторных данных. Однако ответ может включать любоеretrievableполе в индекс. Так как нет возможности декодировать результат векторного поля, включение невекторных текстовых полей полезно для их удобочитаемых значений.
Несколько векторных полей
Вы можете задать свойство vectorQueries.fields для нескольких векторных полей. Векторный запрос выполняется для каждого поля вектора, указанного в списке fields . Можно указать до 10 полей.
При запросе нескольких векторных полей убедитесь, что каждая из них содержит внедрения из одной модели внедрения. Запрос также должен быть создан из той же модели внедрения.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2025-09-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Несколько векторных запросов
Поиск с несколькими запросами по векторам отправляет несколько запросов по нескольким векторам в индексе поиска. Этот тип запроса обычно используется с моделями, такими как CLIP для многомодального поиска, где одна и та же модель может векторизировать как текст, так и изображения.
В приведенном ниже примере запрос ищет сходство как в myImageVector, так и в myTextVector, отправляя два соответствующих векторных представления запроса, каждый из которых выполняется параллельно. Результат этого запроса оценивается с помощью reciprocal rank fusion (RRF).
-
vectorQueriesпредоставляет массив векторных запросов. -
vectorсодержит векторы изображения и текстовые векторы в индексе поиска. Каждый экземпляр является отдельным запросом. -
fieldsуказывает, какое поле вектора выбрать. -
k— это число ближайших совпадений соседей, включаемых в результаты.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Индексы поиска не могут хранить изображения. Если индекс содержит поле для файла изображения, результаты поиска будут включать сочетание текста и изображений.
Запрос с интегрированной векторизацией
В этом разделе показан векторный запрос, вызывающий встроенную векторизацию для преобразования текстового или изображения в вектор. Мы рекомендуем стабильный 2025-09-01 REST API, обозреватель поиска или более новые пакеты Azure SDK для этой функции.
Предварительные требования — это индекс поиска с настроенным векторизатором и назначенным векторным полем. Векторизатор предоставляет сведения о подключении к модели внедрения, используемой во время запроса.
Обозреватель поиска поддерживает встроенную векторизацию во время запроса. Если индекс содержит векторные поля и имеет векторизатор, можно использовать встроенное преобразование текста в вектор.
Перейдите в службу поиска на портале Azure.
В меню слева выберите управление поиском>индексы, и выберите индекс.
Перейдите на вкладку "Векторные профили" , чтобы убедиться, что у вас есть векторизатор.
Перейдите на вкладку обозревателя поиска . С помощью представления запроса по умолчанию можно ввести текстовую строку в строку поиска. Встроенный векторизатор преобразует строку в вектор, выполняет поиск и возвращает результаты.
Кроме того, можно выбрать>представление JSON для просмотра или изменения запроса. Если векторы присутствуют, обозреватель поиска автоматически настраивает векторный запрос. Представление JSON можно использовать для выбора полей для использования в поиске и ответе, добавления фильтров и создания более сложных запросов, таких как гибридные запросы. Чтобы просмотреть пример JSON, перейдите на вкладку REST API в этом разделе.
Число ранжированных результатов в ответе на векторный запрос
Векторный запрос указывает параметр k, который определяет количество совпадений, возвращаемых в результатах. Поисковая система всегда возвращает k количество совпадений. Если k больше количества документов в индексе, количество документов определяет верхний предел возвращаемого значения.
Если вы знакомы с полнотекстовый поиск, вы знаете, что вы ожидаете нулевого результата, если индекс не содержит термин или фразу. Однако в векторном поиске операция поиска определяет ближайших соседей и всегда возвращает k результаты, даже если ближайшие соседи не похожи. Вы можете получить результаты для бессмысленных или не по теме запросов, особенно если вы не используете подсказки для установления границ. Менее релевантные результаты имеют худший показатель сходства, но они по-прежнему "ближайшие" векторы, если нет ничего ближе. Таким образом, ответ без значимых результатов по-прежнему может возвращать k результаты, но оценка сходства каждого результата будет низкой.
Гибридный подход, включающий полнотекстовый поиск, может устранить эту проблему. Другое решение — задать минимальное пороговое значение для оценки поиска, но только если запрос является чистым одним векторным запросом. Гибридные запросы не способствуют минимальным пороговым значениям, так как диапазоны RRF гораздо меньше и более изменчивы.
Параметры запроса, влияющие на число результатов, включают:
-
"k": nрезультаты запросов только для векторных данных. -
"top": nрезультаты гибридных запросов с параметромsearch.
Оба k и top являются необязательными. Если не указано, число результатов по умолчанию равно 50. Вы можете задать top и skip для перехода по дополнительным результатам или изменить значение по умолчанию.
Алгоритмы ранжирования, используемые в векторном запросе
Ранжирование результатов вычисляется одним из следующих способов:
- Метрика сходства.
- RRF, если есть несколько наборов результатов поиска.
Метрика сходства
Метрика сходства, указанная в разделе индекса vectorSearch, для запроса, работающего только с векторами. Допустимые значения: cosine, euclideanи dotProduct.
Azure встраиваемые модели OpenAI используют косинусное сходство, поэтому, если вы используете Azure OpenAI эмбеддинги, cosine является рекомендуемой метрикой. Другие поддерживаемые метрики ранжирования включают euclidean и dotProduct.
RRF
Несколько наборов создаются, если запрос предназначен для нескольких векторных полей, выполняет несколько векторных запросов параллельно или является гибридом векторного и полнотекстового поиска с семантической ранжированием или без нее.
Во время выполнения запроса векторный запрос может использовать только один внутренний векторный индекс. Для нескольких векторных полей и нескольких векторных запросов поисковая система создает несколько запросов, предназначенных для соответствующих индексов векторов каждого поля. Выходной результат — это набор ранжированных ответов для каждого запроса, которые объединяются с использованием RRF. Дополнительные сведения см. в разделе Оценка релевантности с использованием Reciprocal Rank Fusion.
Векторный вес
Добавьте параметр запроса, чтобы указать относительный weight вес каждого векторного запроса, включенного в операции поиска. Это значение используется при объединении результатов нескольких списков ранжирования, созданных двумя или более векторными запросами в одном запросе, или из векторной части гибридного запроса.
Значение по умолчанию равно 1.0, а значение должно быть положительным числом, превышающим нулю.
Весовые значения используются при вычислении показателей RRF каждого документа. Вычисление представляет собой умножение значения weight на оценку ранжирования документа в соответствующем наборе результатов.
В следующем примере используется гибридный запрос с двумя строками векторных запросов и одной текстовой строкой. Весы назначаются векторным запросам. Первый запрос составляет 0,5 или половину веса, что снижает его значение в общем запросе. Второй векторный запрос является дважды важным.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2025-09-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
Вес вектора применяется только к векторам. Текстовый запрос в этом примере "hello world"имеет неявный нейтральный вес 1,0. Однако в гибридном запросе можно увеличить или уменьшить важность текстовых полей, задав maxTextRecallSize.
Задайте пороговые значения, чтобы исключить результаты низкой оценки (предварительная версия)
Так как ближайший поиск соседей всегда возвращает запрошенных k соседей, можно получить несколько совпадений с низкой оценкой в рамках выполнения k требования количества результатов поиска. Чтобы исключить результаты поиска с низкой threshold оценкой, можно добавить параметр запроса, который фильтрует результаты на основе минимальной оценки. Фильтрация возникает перед объединением результатов из разных наборов отзывов.
Этот параметр находится в предварительной версии. Мы рекомендуем последнюю предварительную версию Documents - Search Post (REST API).
В этом примере все совпадения, которые оцениваются ниже 0,8, исключаются из результатов векторного поиска, даже если число результатов падает ниже k.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2025-11-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
Дальнейшие действия
На следующем шаге просмотрите примеры кода векторного запроса в Python, C# или JavaScript.