Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В Azure надежность означает устойчивость и доступность при сбое или ухудшении работы службы. В службе "Поиск ИИ Azure" надежность может быть достигнута в одной службе или нескольких службах поиска в отдельных регионах.
Разверните одну службу поиска и масштабируйте масштаб для обеспечения высокой доступности. Можно добавить несколько реплик для обработки более высоких индексов и рабочих нагрузок запросов. Если служба поиска поддерживает зоны доступности, реплики автоматически подготавливаются в разных физических центрах обработки данных для дополнительной устойчивости.
Разверните несколько служб поиска в разных географических регионах. Все рабочие нагрузки поиска полностью содержатся в одной службе, которая выполняется в одном географическом регионе, но в сценарии с несколькими службами можно синхронизировать содержимое таким образом, чтобы он был одинаковым во всех службах. Вы также можете настроить решение балансировки нагрузки для перераспределения запросов или отработки отказа в случае сбоя службы.
Для обеспечения непрерывности бизнес-процессов и восстановления от аварий на региональном уровне планируйте межрегиональная топологию, состоящую из нескольких служб поиска, имеющих одинаковую конфигурацию и содержимое. Пользовательский скрипт или код предоставляет механизм резервного переключения к альтернативной поисковой службе, если она внезапно становится недоступной.
Высокая доступность
В службе поиска AI Azure реплики представляют собой копии индекса. Служба поиска запускается, имея по крайней мере одну копию и может иметь до 12 экземпляров. Добавление реплик позволяет службе "Поиск ИИ Azure" выполнять перезагрузку компьютера и обслуживание для одной реплики, а выполнение запросов продолжается на других репликах.
Для каждой отдельной службы поиска корпорация Майкрософт гарантирует доступность не менее 99,9% для конфигураций, удовлетворяющих перечисленным ниже критериям.
Две реплики для обеспечения высокой доступности рабочих нагрузок только для чтения (запросы)
Три или более реплики для обеспечения высокой доступности рабочих нагрузок чтения и записи (запросы и индексирование)
Система имеет внутренние механизмы для мониторинга работоспособности реплики и целостности секций. Если вы подготавливаете определенную комбинацию реплик и разделов, система гарантирует такой уровень емкости для вашего сервиса.
Соглашение об уровне обслуживания (SLA) не предоставляется для уровня "Бесплатный". Дополнительные сведения см. в документе SLA для сервиса поиска Azure ИИ.
Поддержка зоны доступности
Зоны доступности — это возможность платформы Azure, которая разделяет центры обработки данных региона на отдельные группы физических расположений для обеспечения высокой доступности в одном регионе. В Azure AI Search отдельные реплики — это единицы распределения по зонам. Служба поиска выполняется в одном регионе; ее реплики выполняются в разных физических центрах обработки данных (или зонах) в этом регионе.
Зоны доступности используются при добавлении двух или более реплик в службу поиска. Каждая реплика помещается в другую зону доступности в пределах региона. Если у вас есть больше реплик, чем доступные зоны в регионе службы поиска, реплики распределяются по зонам равномерно. От вас не требуется никаких конкретных действий, кроме как создать службу поиска в регионе с зонами доступности и настроить службу на использование нескольких реплик.
Предварительные условия
- Уровень служб должен быть стандартным или более высоким.
- Регион службы должен находиться в регионе с доступными зонами (перечислены в следующем разделе).
- Конфигурация должна включать несколько реплик: две для рабочих нагрузок запросов только для чтения, три для рабочих нагрузок чтения и записи, которые включают индексирование
Поддерживаемые регионы
Поддержка зон доступности зависит от инфраструктуры и хранилища. В настоящее время в следующей зоне недостаточно хранилища и не предоставляется зона доступности для поиска ИИ Azure:
- Западная Япония
В противном случае зоны доступности для поиска ИИ Azure поддерживаются в следующих регионах:
| Область/регион | Дата развертывания |
|---|---|
| Восточная Австралия | 30 января 2021 г. или позже |
| Южная Бразилия | 2 мая 2021 г. или позже |
| Центральная Канада | 30 января 2021 года или позже |
| Центральная Индия | 20 января 2022 года или позже |
| Центральная часть США | 4 декабря 2020 года или позже |
| Северный Китай 3 | 7 сентября 2022 г. или позже |
| Восточная Азия | 13 января 2022 г. или позднее |
| Восточная часть США | 27 января 2021 г. или позже |
| Восточная часть США 2 | 30 января 2021 г. или позднее |
| Центральная Франция | 23 октября 2020 г. или позже |
| Центрально-Западная Германия | 3 мая 2021 г. или позже |
| Центральная Израиль | 1 апреля 2024 г. или более поздней версии |
| Италия Север | 1 апреля 2024 г. или более поздней версии |
| Восточная Япония | 30 января 2021 г. или позже |
| Республика Корея, центральный регион | 20 января 2022 г. или позже |
| Северная Европа | 28 января 2021 г. или позже |
| Восточная Норвегия; | 20 января 2022 года или позже |
| Центральный Катар | 25 августа 2022 г. или позже |
| Северная часть ЮАР | 7 сентября 2022 г. или позже |
| Центрально-южная часть США | 30 апреля 2021 г. или позже |
| Юго-Восточная Азия | 31 января 2021 г. или позже |
| Центральная Швеция | 21 января 2022 г. или позже |
| Северная Швейцария | 7 сентября 2022 г. или позднее |
| Северная часть ОАЭ; | 9 сентября 2022 г. или позже |
| Южная Часть Великобритании | 30 января 2021 года или позже |
| Правительство США (Вирджиния) | 30 апреля 2021 г. или позже |
| Западная Европа | 29 января 2021 года или позже |
| Западная часть США 2 | 30 января 2021 г. или позже |
| Западная часть США 3 | 2 июня 2021 г. или позже |
Примечание.
Зоны доступности не изменяют условия соглашения об уровне обслуживания. Для обеспечения высокой доступности запросов по-прежнему требуется наличие трёх или более реплик.
Несколько служб в разных географических регионах
Избыточность служб необходима, если к вашим операционным требованиям относятся:
Требования к непрерывности бизнес-процессов и аварийному восстановлению. Поиск Azure AI не обеспечивает мгновенного резервного переключения в случае сбоя.
Быстрая производительность для глобально распределенного приложения. Если запросы и индексирование приходят из всего мира, пользователи, находящиеся ближе всего к центру обработки данных, получают более высокую производительность. Создание дополнительных служб в регионах с непосредственной близостью к этим пользователям может уравнять производительность для всех пользователей.
Если вам нужны две или несколько служб поиска, создание их в разных регионах может соответствовать требованиям приложения к непрерывности и восстановлению, а также ускорить время отклика для глобальной базы пользователей.
Поиск по искусственному интеллекту Azure не предоставляет автоматизированный метод репликации индексов поиска в географических регионах, но есть некоторые методы, которые могут упростить этот процесс для реализации и управления ими. Эти методы описаны в следующих нескольких разделах.
Цель геораспределяемого набора служб поиска — иметь два или более индексов, доступных в двух или более регионах, где пользователь направляется в службу Azure AI, которая обеспечивает наименьшую задержку.

Эту архитектуру можно реализовать, создав несколько служб и разрабатывая стратегию синхронизации данных. При необходимости можно включить ресурс, например Диспетчер трафика Azure, для маршрутизации запросов.
Совет
Для помощи в развертывании нескольких служб поиска в различных регионах, см. этот пример Bicep на GitHub, чтобы развернуть полностью настроенное решение для поиска в нескольких регионах. В этом примере приведены два варианта синхронизации индексов и перенаправление запросов с помощью Диспетчер трафика.
Синхронизация данных между несколькими службами
Существует два варианта хранения двух или нескольких разных служб поиска в синхронизации:
- Извлечение обновлений содержимого в индекс поиска с помощью индексатора.
- Отправка содержимого в индекс с помощью API добавления или обновления документов (REST) или эквивалентного API пакета SDK Azure.
Чтобы настроить любой вариант, мы рекомендуем использовать пример скрипта Bicep из репозитория azure-search-multiple-region, модифицированный в соответствии с вашими регионами и стратегиями индексирования.
Вариант 1. Использование индексаторов для обновления содержимого в нескольких службах
Если индексатор уже используется в одной службе, можно настроить второй индексатор во второй службе, чтобы использовать тот же объект источника данных, извлекая данные из того же расположения. Каждая служба в каждом регионе имеет собственный индексатор и целевой индекс (индекс поиска не является общим, что означает, что каждый индекс имеет собственную копию данных), но каждый индексатор ссылается на один источник данных.
Вот визуальное представление в общих чертах данной архитектуры.

Вариант 2. Использование REST API для отправки обновлений содержимого в несколько служб
Если вы используете REST API поиска Azure для отправки содержимого в ваш поисковый индекс, вы можете поддерживать синхронизацию различных служб поиска, отправляя изменения во все службы поиска при необходимости обновления. Убедитесь, что в коде обрабатываются ситуации, когда обновление одной службы поиска завершается сбоем, но для других служб оно выполняется успешно.
Запросы запросов на отработку отказа или перенаправление
Если требуется избыточность на уровне запроса, Azure предоставляет несколько вариантов балансировки нагрузки:
- Диспетчер трафика Azure, используемый для маршрутизации запросов на несколько географически расположенных веб-сайтов, которые затем поддерживаются несколькими службами поиска.
- Шлюз приложений, используемый для балансировки нагрузки между серверами в регионе на уровне приложения.
- Azure Front Door используется для оптимизации глобальной маршрутизации веб-трафика и обеспечения глобальной отработки отказа.
- Azure Load Balancer, используемый для балансировки нагрузки между службами в серверном пуле.
Некоторые моменты следует учитывать при оценке параметров балансировки нагрузки:
Поиск — это серверная служба, которая принимает поисковые и индексирующие запросы от клиента.
Запросы от клиента к службе поиска должны проходить проверку подлинности. Для доступа к операциям поиска вызывающая сторона должна иметь разрешения на основе ролей или предоставить ключ API в запросе.
Конечные точки службы по умолчанию достигаются через общедоступное подключение к Интернету. Если вы настроили частную конечную точку для клиентских подключений, исходящих из виртуальной сети, используйте Шлюз приложений.
Поиск ИИ Azure принимает запросы, адресованные конечной точке
<your-search-service-name>.search.windows.net. Если вы достигнете той же конечной точки, используя другое DNS-имя в заголовке узла, например CNAME, запрос отклоняется.
Поиск ИИ Azure предоставляет пример развертывания с несколькими регионами, который использует Диспетчер трафика Azure для перенаправления запросов, если основная конечная точка завершается ошибкой. Это решение полезно при маршрутизации к клиенту, поддерживающему поиск, который вызывает только службу поиска в том же регионе.
Диспетчер трафика Azure в основном используется для маршрутизации сетевого трафика между разными конечными точками на основе определенных методов маршрутизации (таких как приоритет, производительность или географическое расположение). Он действует на уровне DNS для направления входящих запросов в соответствующую конечную точку. Если конечная точка, которую обслуживает Диспетчер трафика, начинает отказывать в обработке запросов, трафик перенаправляется на другую конечную точку.
Диспетчер трафика не предоставляет конечную точку для прямого подключения к поиску ИИ Azure, что означает, что вы не можете поместить службу поиска непосредственно за Диспетчер трафика. Вместо этого предполагается, что поток запросов направляется к Диспетчеру трафика, затем к веб-клиенту с поддержкой поиска и в конечном итоге к службе поиска на серверной части. Клиент и служба находятся в одном регионе. Если одна служба поиска выходит из строя, клиент поиска начинает давать сбои, и Диспетчер трафика перенаправляет запросы на оставшийся клиент.
Примечание.
Если вы используете пробы работоспособности Azure Load Balancer в службе поиска, необходимо использовать пробу HTTPS по адресу /ping.
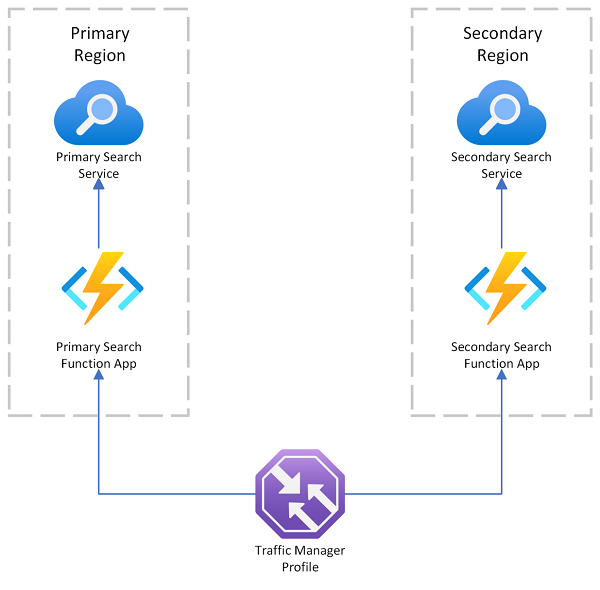
Многорегиональное размещение данных
При развертывании нескольких служб поиска в различных географических регионах содержимое хранится в регионе, выбранном для каждой службы поиска.
Поиск по искусственному интеллекту Azure не сохраняет данные за пределами указанного региона без авторизации. Авторизация неявна при использовании функций, которые записываются в ресурс служба хранилища Azure: кэш обогащения, сеанс отладки, хранилище знаний. Во всех случаях учетная запись хранения — это учетная запись хранения, которую вы предоставляете в выбранном регионе.
Примечание.
Если учетная запись хранения и служба поиска находятся в одном регионе, сетевой трафик между поиском и хранилищем использует частный IP-адрес и происходит через магистральную сеть Майкрософт. Так как используются частные IP-адреса, нельзя настроить брандмауэры IP-адресов или частную конечную точку для безопасности сети. Вместо этого используйте исключение доверенной службы в качестве альтернативы, если обе службы находятся в одном регионе.
Сведения о сбоях служб и катастрофических событиях
Как указано в Соглашении об уровне обслуживания, корпорация Майкрософт гарантирует высокий уровень доступности для запросов на индекс, если экземпляр службы Azure AI настроен с двумя или более репликами, и обновления индекса, когда экземпляр службы Azure AI настроен с тремя или более репликами. Однако встроенный механизм аварийного восстановления отсутствует. Если непрерывная служба требуется в случае катастрофического сбоя за пределами контроля Майкрософт, рекомендуется подготовить вторую службу в другом регионе и реализовать стратегию георепликации, чтобы обеспечить полное избыточность индексов во всех службах.
Клиенты, использующие индексаторы для заполнения и обновления индексов, могут обрабатывать аварийное восстановление с помощью гео-специфичных индексаторов, которые извлекают данные из одного и того же источника данных. Две службы в разных регионах, в каждой из которых работает индексатор, могут индексировать один и тот же источник данных для обеспечения географической избыточности. Если вы индексируете из источников данных, которые также являются геоизбыточными, помните, что индексаторы поиска Azure AI могут выполнять только добавочное индексирование (слияние обновлений из новых, измененных или удаленных документов) из первичных реплик. При возникновении отказа обязательно перенаправьте индексатор на новую основную реплику.
Если индексаторы не используются, вы будете использовать код приложения для отправки объектов и данных в разные службы поиска параллельно. Дополнительные сведения см. в разделе "Синхронизация данных в нескольких службах".
Альтернативные варианты резервного копирования и восстановления
Стратегия непрерывности бизнес-процессов для уровня данных обычно включает шаг восстановления из резервного копирования. Так как поиск по искусственному интеллекту Azure не является основным решением для хранения данных, корпорация Майкрософт не предоставляет формальный механизм для самостоятельного резервного копирования и восстановления. Однако вы можете использовать пример кода для резервного копирования индекса в этом репозитории службы поиска ИИ Azure или в этом примере репозитория Python для резервного копирования определения индекса и моментального снимка в ряд JSON-файлов, а затем использовать эти файлы для восстановления индекса при необходимости. Это средство также может перемещать индексы между уровнями служб.
Код приложения, используемый для создания и заполнения индекса, фактически предоставляет возможность восстановления на случай, если индекс будет удален по ошибке. Чтобы перестроить индекс, необходимо удалить его (если он существует), заново создать индекс в службе и перезагрузить, получив данные из основного хранилища данных.
Связанный контент
- Ознакомьтесь с ограничениями служб, чтобы узнать больше о ценовых категориях и ограничениях служб.
- Ознакомьтесь с Планированием емкости, чтобы узнать больше о сочетаниях секций и реплик.
- Рассмотрите исследование: использование когнитивного поиска для поддержки сложных сценариев ИИ для получения дополнительных рекомендаций по настройке.