Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Полнотекстовый поиск — это подход к получению информации, которая соответствует обычному тексту, хранящемуся в индексе. Например, учитывая строку запроса "отели в Сан-Диего на пляже", поисковая система ищет токенизованные строки на основе этих терминов. Чтобы сделать сканирование более эффективным, строки запроса проходят лексический анализ: перевод всех терминов в нижний регистр, удаление стоп-слов, таких как "the", и приведение терминов к их базовым корневым формам. При обнаружении соответствующих терминов поисковая система извлекает документы, ранжирует их по порядку релевантности и возвращает первые результаты.
Выполнение запроса может быть сложным. Эта статья предназначена для разработчиков, которые нуждаются в более глубоком понимании того, как работает полнотекстовый поиск в службе "Поиск ИИ Azure". Для текстовых запросов поиск Azure AI без труда выдает ожидаемые результаты в большинстве сценариев, но иногда вы можете получить результат, который кажется "неправильным" каким-то образом. В таких ситуациях, иметь знания о четырех этапах выполнения запроса в Lucene (синтаксический анализ, лексический анализ, сопоставление документов и оценка результатов) может помочь вам определить конкретные изменения параметров запроса или конфигурации индекса, которые приводят к желаемому результату.
Примечание.
Поиск ИИ Azure использует Apache Lucene для полнотекстового поиска, но интеграция Lucene не является исчерпывающей. Мы выборочно предоставляем и расширяем функциональные возможности Lucene, чтобы обеспечить сценарии, важные для поиска ИИ Azure.
Схема архитектуры и ее обзор
Выполнение запроса состоит из четырех этапов:
- синтаксический анализ запроса;
- Лексический анализ
- извлечение документа;
- Очки
Запрос полнотекстового поиска начинается с анализа текста запроса для извлечения терминов и операторов поиска. Существует два средства синтаксического анализа, чтобы выбрать между скоростью и сложностью. Этап анализа будет следующим, где отдельные термины запросов иногда разбиваются и переосмысливаются в новых формах. Этот шаг помогает охватить более широкий круг того, что можно рассматривать как потенциальное совпадение. Затем поисковая система сканирует индекс, чтобы найти документы с соответствующими терминами и оценивает каждое совпадение. Выборка результатов затем сортируется по оценке релевантности, назначенной каждому совпадающему документу. Элементы в верхней части ранжированного списка возвращаются вызывающему приложению.
На следующей схеме показаны компоненты, используемые для обработки запроса поиска:
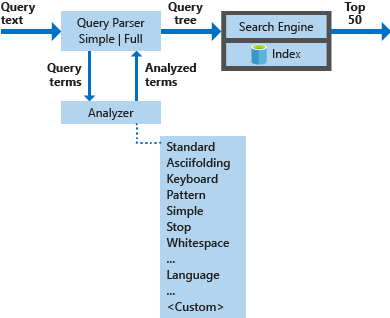
| Ключевые компоненты | Описание функций |
|---|---|
| Средства синтаксического анализа запроса | Отделяют термины запроса от операторов и создают структуру запроса (дерево запроса), которая отправляется в поисковую систему. |
| Анализаторы | Выполняют лексический анализ терминов запроса, Этот процесс может включать преобразование, удаление или расширение терминов запроса. |
| Указатель | Эффективная структура данных, используемая для хранения и упорядочивания доступных для поиска терминов, извлеченных из индексированных документов. |
| Поисковая система | Извлекает и оценивает совпадающие документы на основе содержимого обращенного индекса. |
Схема поискового запроса
Поисковый запрос представляет собой полную спецификацию содержимого, возвращаемого в результирующем наборе. В самой простой форме это пустой запрос без критериев любого вида. В более реалистичном примере он включает в себя параметры, несколько терминов запроса, вероятно, ограниченных определенными полями, выражение фильтра и правила упорядочения.
Следующий пример — это запрос поиска, который можно отправить в службу "Поиск ИИ Azure" с помощью REST API:
POST /indexes/hotels/docs/search?api-version=2025-09-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Для этого запроса поисковая система выполняет следующие операции:
Находит документы, где цена составляет не менее $60 и менее $ 300.
Выполняет запрос. В этом примере поисковый запрос состоит из фраз и терминов:
"Spacious, air-condition* +\"Ocean view\""(Обычно пользователи не вводят пунктуацию, но в том числе в примере, мы можем объяснить, как анализаторы обрабатывают его.)Для этого запроса поисковая система сканирует поля описания и заголовка, указанные в "searchFields", для документов, содержащих
"Ocean view", а также на термин"spacious", или на термины, начинающиеся с префикса"air-condition". Параметр searchMode используется для сопоставления с любым термином (по умолчанию) или всеми из них, в тех случаях, когда термин не является явным образом обязательным (+).Сортирует полученный набор отелей по близости к заданной географической точке и затем возвращает результаты в вызывающее приложение.
Большая часть этой статьи заключается в обработке поискового запроса: "Spacious, air-condition* +\"Ocean view\"" Фильтрация и упорядочение не относятся к сфере данного рассмотрения. Дополнительные сведения см. в статье о поиске документов с помощью интерфейса REST API службы поиска Azure.
Этап 1. Синтаксический анализ запроса
Как было отмечено, строка запроса является первой строкой запроса.
"search": "Spacious, air-condition* +\"Ocean view\"",
Средство синтаксического анализа запросов отделяет операторы (например * , и + в примере) от условий поиска и деконструирует поисковый запрос в вложенные запросы поддерживаемого типа:
- запрос термина — для автономных терминов (например, spacious);
- запрос фразы — для терминов, заключенных в кавычки (например, «вид на океан» [ocean view]);
-
запрос префикса — для терминов, за которыми следует оператор префикса
*(например, air-condition).
Полный список поддерживаемых типов запросов см. в синтаксисе запросов Lucene.
Операторы, связанные с вложенными запросами, определяют, обязательно ли должен быть удовлетворен запрос, чтобы документ рассматривался в качестве подходящего. Например, +"Ocean view" - это "обязательно" вследствие оператора +.
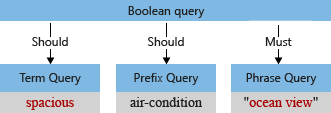
Средство синтаксического анализа запросов реструктурирует вложенные запросы в дерево запросов (внутренняя структура, представляющая запрос), который передается поисковой системе. На первом этапе синтаксического анализа запроса дерево запросов выглядит следующим образом:

Поддерживаемые парсеры: Упрощенный и Полный парсеры Lucene
Поиск по искусственному интеллекту Azure предоставляет два разных языка запросов: simple (по умолчанию) и full. Задавая параметр queryType для поискового запроса, вы сообщаете средству синтаксического анализа запросов выбранный язык запросов для верной интерпретации операторов и синтаксиса.
Язык простых запросов является интуитивно понятным и надежным, часто подходит для интерпретации пользовательских входных as-is без обработки на стороне клиента. Он поддерживает те же операторы запросов,что и поисковые системы в Интернете.
Полный язык запросов Lucene, который доступен при установке параметра
queryType=full, расширяет язык запросов Simple, добавляя поддержку для большего числа операторов и типов запросов, таких как подстановочные знаки, нечеткие запросы, регулярные выражения и запросы по полям. Например, регулярное выражение, отправленное в простой синтаксис запросов, будет интерпретироваться как строка запроса, а не как выражение. В нашем примере запроса используется язык расширенных запросов Lucene.
Влияние параметра searchMode на средство синтаксического анализа
Другим параметром запроса поиска, влияющим на синтаксический анализ, является параметр searchMode. Он управляет оператором по умолчанию для логических запросов: любой (по умолчанию) или все.
Если "searchMode=any", который является значением по умолчанию, разделитель пространства между просторным и кондиционером имеет значение OR (||), что эквивалентно тексту примера запроса:
Spacious,||air-condition*+"Ocean view"
Явные операторы, например + в +"Ocean view", являются однозначными в конструкции бульевого запроса (это обязательное соответствие). Менее очевидно, как интерпретировать оставшиеся термины: просторный и кондиционирование воздуха. Должна ли поисковая система искать совпадения по запросу вид на океан и просторный и кондиционер? Или же нужно найти вид на океан и один из оставшихся терминов?
По умолчанию ("searchMode=any"), поисковая система предполагает более широкую интерпретацию. Любое поле должно совпадать, отражая семантику оператора "or". Исходное дерево запроса, показанное ранее, с двумя операциями "рекомендуется", соответствует режиму по умолчанию.
Предположим, что теперь задано значение searchMode=all. В этом случае пробел интерпретируется как операция "и". Оба остальных термина должны присутствовать в документе, чтобы квалифицироваться как совпадение. Результирующий пример запроса будет интерпретирован следующим образом:
+Spacious,+air-condition*+"Ocean view"
Измененное дерево запросов для этого запроса, где соответствующий документ представляет собой пересечение всех трех подзапросов, выглядит так:

Примечание.
Выбор "searchMode=any" на "searchMode=all" — это решение, лучше всего принятое путем выполнения репрезентативных запросов. Пользователи, которые, скорее всего, используют операторы (обычно при поиске в хранилищах документов), могут находить результаты более интуитивно понятными, если "searchMode=all" информирует булевым конструкциям запросов. Дополнительные сведения о взаимодействии между searchMode и операторами см. в разделе "Простой синтаксис запроса".
Этап 2. Лексический анализ
Лексические анализаторы обрабатывают запросы терминов и запросы фраз после формирования дерева запроса. Анализатор принимает текстовые входные данные, предоставленные ему синтаксическим анализатором, обрабатывает их, а затем отправляет обратно термины, снабженные маркером, для их последующего включения в дерево запроса.
Наиболее распространенной формой лексического анализа является лингвистический анализ, который преобразует термины запросов на основе правил, относящихся к заданному языку. Это включает в себя:
- Сокращение термина запроса к корневой форме слова.
- Удаление стоп-слов (stopwords, например "the" или "and" в английском языке).
- Разбиение составного слова на составные части.
- Преобразование прописного слова в нижний регистр.
Цель всех этих операций — стереть различия между текстовыми входными данными, предоставленными пользователем, и терминами, сохраненными в индексе. Эти операции выходят за рамки обработки текста и требуют глубоких знаний самого языка. Чтобы добавить этот уровень лингвистической осведомленности, поиск ИИ Azure поддерживает длинный список анализаторов языка как Lucene, так и Майкрософт.
Примечание.
В зависимости от вашего сценария требования к анализу могут варьироваться от минимального до сложного. Вы можете управлять сложностью лексического анализа, выбрав один из предопределенных анализаторов или создав собственный пользовательский анализатор. Анализаторы привязаны к полям, поддерживающим поиск, и задаются как часть определения поля. Таким образом, вы можете изменять лексический анализ на основе поля. Если не указано, используется стандартный анализатор Lucene.
В нашем примере перед анализом исходное дерево запросов имеет термин "Просторный", с верхним регистром "S" и запятой, которую средство синтаксического анализа запросов интерпретирует как часть термина запроса (запятая не считается оператором языка запросов).
Когда анализатор по умолчанию обрабатывает термин, он преобразует в строчные буквы "ocean view" и "spacious" и удаляет символ запятой. Измененное дерево запросов выглядит следующим образом:
Проверка поведения анализатора
Поведение анализатора можно проверить с помощью API анализа. Укажите текст, который нужно проанализировать, чтобы узнать, какие термины генерирует данный анализатор. Например, чтобы увидеть, каким образом стандартный анализатор будет обрабатывать текст "air-condition", вы можете использовать запрос ниже.
{
"text": "air-condition",
"analyzer": "standard"
}
Стандартный анализатор разбивает входной текст на следующие два маркера, аннотируя их такими атрибутами, как «startOffset» и «endOffset» (используемые для подсветки совпадений), а также их «положением» (используемым для сопоставления фраз).
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Исключения лексического анализа
Лексический анализ применяется только к типам запросов, которым требуются полные термины, запрос терминов или запрос фразы. Он не применяется к типам запросов с неполными терминами — поиск по префиксу, поиск с подстановочными знаками, поиск по регулярному выражению — или к нечеткому поиску. Эти типы запросов, включая запрос префикса с термином air-condition* в нашем примере, добавляются непосредственно в дерево запросов, обходя этап анализа. Единственное преобразование для терминов запроса такого типа — преобразование в нижний регистр.
Этап 3. Извлечение документа
Извлечение документа относится к поиску документов с совпадающими терминами в индексе. Этот этап лучше всего понятен с помощью примера. Начнем с индекса отелей, имеющего следующую простую схему:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Предположим, что этот индекс содержит следующие четыре документа:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Индексирование терминов
Чтобы понять процесс извлечения, необходимо знать основные сведения об индексировании. Единицей хранения является обращенный индекс, по одному для каждого поля, доступного для поиска. Обращенный индекс содержит отсортированный список со всеми терминами из всех документов. Каждый термин сопоставляется со списком документов, в которых он встречается, что очевидно из примера ниже.
Чтобы создать термины в обращенном индексе, система поиска выполняет лексический анализ содержимого документов, схожий с процессом обработки запросов:
- Входные данные текста передаются анализатору, преобразуются в нижний регистр, очищаются от знаков препинания и т. д. в зависимости от конфигурации анализатора.
- Токены являются выходными данными текстового анализа.
- Термины добавляются в индекс.
Обычно, но не обязательно, использовать одинаковые анализаторы для операций поиска и индексирования, чтобы термины запроса больше походили на термины внутри индекса.
Примечание.
Поисковая система Azure AI позволяет указывать различные анализаторы для индексации и поиска через дополнительные параметры поля indexAnalyzer и searchAnalyzer. Если их не указать, анализатор с заданным свойством analyzer будет использоваться для двух операций — индексирования и поиска.
Инвертированные индексы для примеров документов
Возвращаясь к нашему примеру, для поля заголовка обращенный индекс будет выглядеть следующим образом:
| Термин | Список документов |
|---|---|
| atman | 1 |
| пляж | 2 |
| отель | 1, 3 |
| океан | 4 |
| плайя | 3 |
| курорт | 2 |
| отступление | 4 |
В поле заголовка отображается только отель в двух документах: 1 и 3.
Для поля описания индекс выглядит следующим образом:
| Термин | Список документов |
|---|---|
| воздух | 3 |
| и | 4 |
| пляж | 1 |
| обусловленный | 3 |
| удобный | 3 |
| расстояние | 1 |
| остров | 2 |
| kauaʻi | 2 |
| расположен | 2 |
| север | 2 |
| океан | 1, 2, 3 |
| из | 2 |
| на | 2 |
| тихий | 4 |
| комнаты | 1, 3 |
| уединенный | 4 |
| берег | 2 |
| просторный | 1 |
| мыши | 1, 2 |
| до | 1 |
| вид | 1, 2, 3 |
| ходьба | 1 |
| на | 3 |
Сопоставление терминов запроса с индексированных терминов
Учитывая инвертированные индексы выше, давайте вернемся к образцу запроса и посмотрим, как найдены соответствующие документы для нашего примера запроса. Вспомним, что конечное дерево запроса выглядит следующим образом:
Во время выполнения запроса каждое отдельное обращение выполняется к поисковым полям независимо друг от друга.
Запрос TermQuery "spacious" соответствует документу 1 (Hotel Atman).
Префиксный запрос "air-condition*" не находит совпадений ни в одном документе.
Это поведение иногда путает разработчиков. Несмотря на то, что термин кондиционированный воздух существует в документе, он разделен на два термина анализатором по умолчанию. Помните, что запросы префикса, содержащие частичные термины, не анализируются. Поэтому термины с префиксом "кондиционирование воздуха" ищутся в инвертированном индексе и не находятся.
Запрос фраз "ocean view" выполняет поиск по терминам "ocean" и "view" и проверяет их близость в исходном документе. Документы 1, 2 и 3 соответствуют этому запросу в поле описания. Обратите внимание, что документ 4 имеет термин "океан" в названии, но не считается совпадением, так как мы ищем фразу "вид океана", а не отдельные слова.
Примечание.
Поисковый запрос выполняется независимо от всех полей, доступных для поиска в индексе поиска ИИ Azure, если вы не ограничиваете поля, заданные параметром searchFields , как показано в примере поискового запроса. Возвращаются документы, содержащие совпадение в любом из выбранных полей.
В целом для рассматриваемого запроса документы, которые соответствуют, - это 1, 2 и 3.
Этап 4. Оценка
Каждому документу в результирующем наборе поиска присваивается оценка релевантности. Функция оценки релевантности — задать более высокий приоритет документам, которые лучше соответствуют вопросам пользователей, выраженным в поисковом запросе. Оценка вычисляется на основе статистических свойств терминов, для которых найдены соответствия. В основе формулы оценки используется частотность терма–обратная частотность документа (TF/IDF). В запросах, содержащих редкие и распространенные термины, TF-IDF придает большую важность результатам для терминов, которые встречаются нечасто. Например, в гипотетическом индексе со всеми статьями Wikipedia среди документов, содержащих поисковой термин the president, документы, содержащие president, будут более релевантными по сравнению с теми, которые содержат the.
Пример оценки
Вспомните три документа, которые соответствовали примеру запроса:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Документ 1 лучше всего соответствовал запросу, так как в его поле описания содержится и термин spacious, и обязательная фраза ocean view. Следующие два документа содержат только фразу ocean view. Вы можете быть удивлены тем, что оценки релевантности для документов 2 и 3 отличаются, даже если они совпадают с запросом. Это связано с тем, что формула оценки имеет больше компонентов, чем просто TF/IDF. В этом случае документу 3 была присвоена оценка выше, так как его описание короче. Ознакомьтесь с практической формулой оценки Lucene, чтобы узнать, как длина поля и другие факторы влияют на оценку релевантности.
Некоторые типы запросов (подстановочные знаки, префикс и regex) всегда вносят постоянную оценку в общую оценку документа. Это позволяет совпадениям, найденным путем расширения запросов, включаться в результаты, не влияя на рейтинг.
В примере объясняется, почему это важно. Поиск с подстановочными знаками, включая поиск префикса, неоднозначны по определению, так как входная строка является частичной строкой с потенциальными совпадениями на очень большом количестве разрозненных терминов. Рассмотрим входные данные "tour*", с совпадениями, найденными на "турах", "туретты", и "турмалин". Учитывая характер этих результатов, нет способа разумно определить, какие термины являются более ценными, чем другие. По этой причине мы игнорируем частотность терминов при оценке результатов в запросах типов подстановочных знаков, префиксов и регулярных выражений. Во множественном поисковом запросе, который включает частичные и полные термины, результаты из неполных входных данных объединяются с постоянной оценкой, чтобы избежать смещения по отношению к потенциально неожиданным соответствиям.
Настройка релевантности
Существует два способа настройки показателей релевантности в службе "Поиск ИИ Azure":
Профили оценки повышают позицию документов в ранжированном списке результатов на основе набора правил. В нашем примере мы можем рассмотреть документы, для которых найдены совпадения в заголовке поля, как более релевантные, чем те, которые содержат совпадения в поле описания. Кроме того, если наш индекс имел поле цены для каждого отеля, мы могли бы выделить документы с более низкими ценами. Дополнительные сведения о добавлении профилей оценки в индекс поиска.
Повышение приоритета слов (доступно только в синтаксисе расширенных запросов Lucene) достигается с помощью оператора
^, который можно применить к любой части дерева запроса. В нашем примере вместо поиска по префиксу air-condition* можно выполнить поиск по точному термину air-condition или префиксу, но документы с соответствием точному термину будут ранжированы выше, так как для запроса применен оператор повышения приоритета — air-condition^2||air-condition*. Узнайте больше о усилении весов терминов в запросе.
Оценка в распределенном индексе
Все индексы в поиске ИИ Azure автоматически разделяются на несколько сегментов, что позволяет быстро распределять индекс между несколькими узлами во время увеличения или уменьшения масштаба службы. При выдаче поискового запроса он выдается независимо от каждого сегмента. Затем результаты из каждого сегмента объединяются и упорядочиваются по оценке (если не определен другой порядок). Важно знать, что функция оценки взвешивает частоту термина запроса в сравнении с его обратной частотой в документе только внутри одного шарда, а не во всех шардов!
Это значит, что оценка релевантности может отличаться для идентичных документов, если они находятся в разных сегментах. К счастью, подобные различия обычно исчезают по мере увеличения документов в индексе, что происходит благодаря более равномерному распределению термина. Невозможно предположить, на какой сегмент будет помещен любой указанный документ. Но так как, вероятнее всего, ключ документа не меняется, он всегда будет присвоен одному сегменту.
Как правило, оценочная цифра документа не является лучшим атрибутом для упорядочивания документов, если важна стабильность порядка. Например, при наличии двух документов с одинаковыми показателями нет никакой гарантии, что один из них отобразится первым в последующих запусках того же запроса. Оценка документов должна представлять только общее представление релевантности документа относительно других документов в результирующем наборе.
Заключение
Успех коммерческих поисковых систем вызвал ожидания полнотекстового поиска по частным данным. Теперь мы ожидаем, что независимо от типа поиска система будет распознавать наши намерения, даже если используются термины с ошибками или же неполные термины. Мы даже можем ожидать совпадений на основе почти эквивалентных терминов или синонимов, которые мы никогда не указали.
С технической точки зрения полнотекстовый поиск является чрезвычайно сложным и требует тщательного лингвистического анализа и систематического подхода к обработке, которая включает извлечение, расширение и преобразование терминов запроса, для обеспечения релевантного результата. Учитывая присущие сложности, существует множество факторов, которые могут повлиять на результат запроса. По этой причине, разобравшись с механизмами полнотекстового поиска, мы можем получить ощутимые преимущества при работе с неожиданными результатами.
В этой статье рассматриваются полнотекстовый поиск в контексте поиска ИИ Azure. Мы надеемся, это даст вам достаточные знания, чтобы распознать потенциальные причины и решения для устранения распространенных проблем с запросами.
Следующие шаги
Создайте пример индекса, попробуйте выполнить различные запросы и просмотреть результаты. Инструкции см. в разделе "Сборка и запрос индекса" в портал Azure.
Попробуйте использовать другой синтаксис запроса из раздела «Документы поиска» или из раздела «Простой синтаксис запросов» в обозревателе поиска в портале Azure.
Если вы хотите настроить ранжирование в поисковом приложении, ознакомьтесь с профилями оценки.
Применение лексических анализаторов для конкретного языка.
Настройте пользовательские анализаторы для минимальной или специализированной обработки определенных полей.
Связанный контент
Search Documents (Azure Search Service REST API) (Поиск по документам (REST API службы поиска Azure))
Lucene query syntax in Azure Search (Синтаксис запросов Lucene в службе поиска Azure)