Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
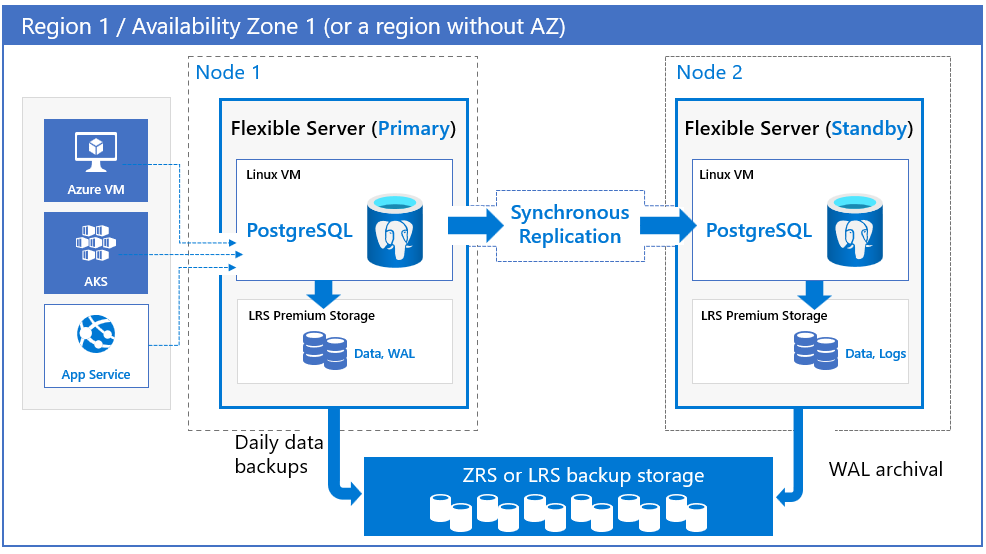
База данных Azure для PostgreSQL поддерживает высокий уровень доступности путем подготовки физически разделенных первичных и резервных реплик. Эта модель высокой доступности предназначена для обеспечения того, чтобы зафиксированные данные никогда не терялись во время сбоев. При установке высокого уровня доступности данные синхронно фиксируются как на первичных, так и на резервных серверах. Модель разработана таким образом, чтобы база данных не стала единственной точкой сбоя в архитектуре программного обеспечения.
По умолчанию в большинстве регионов резервная реплика развертывается в другой зоне доступности относительно основной реплики (с зональной избыточностью). Вы также можете развернуть основные и резервные реплики в одной зоне доступности (зональные).
Возможности обеспечения высокой доступности
Резервная реплика развертывается в той же конфигурации виртуальной машины, что и основной сервер, включая виртуальные ядра, хранилище и параметры сети.
Вы можете добавить поддержку зоны доступности для существующего сервера базы данных.
Наряду с резервным сервером мы также развертываем сервер реплики WAL для поддержания фиксации кворума. В сценариях, когда резервный сервер временно недоступен, транзакции фиксируются на основном сервере и сервере реплики WAL для обеспечения устойчивости. Когда резервный сервер снова становится доступным, он автоматически синхронизируется с основным сервером. Эта архитектура помогает гарантировать, что зафиксированные записи надежно сохраняются.
Если выполняется переключение при отказе, только резервный сервер назначается новым основным сервером. Сервер-реплика WAL не переводится в основной сервер и используется только для поддержания кворума коммитов.
Вы можете отключить высокий уровень доступности, который удаляет резервную реплику.
Вы можете выбрать зоны доступности для основных и резервных серверов базы данных с резервированием по зонам для обеспечения высокой доступности.
Некоторые операции, например остановку, запуск и перезапуск, выполняют одновременно и на главном, и на резервном серверах базы данных.
Сервер базы данных-источник периодически выполняет автоматическое резервное копирование. В то же время резервная реплика постоянно архивирует журналы транзакций в хранилище резервных копий. Для зонально избыточных серверов данные резервного копирования хранятся в зонально избыточном хранилище (ZRS). Данные резервного копирования хранятся в локально избыточном хранилище (LRS) для серверов, настроенных без избыточности зоны, зональных (однозонных) серверов и в регионах, которые не поддерживают зоны доступности.
Клиенты всегда подключаются к конечному имени узла сервера базы данных-источника.
Любые изменения параметров также применяются к резервной реплике.
Вы можете перезапустить сервер, чтобы получить любые изменения статических параметров.
Периодические действия обслуживания, такие как незначительные обновления версий, выполняются в резервном режиме. Чтобы сократить время простоя, резервный режим повышен до основного, чтобы рабочие нагрузки могли продолжаться, пока задачи обслуживания применяются на оставшемся узле.
Замечание
Чтобы функции высокой доступности работали правильно, настройте значения параметров max_replication_slots и max_wal_senders. Для обеспечения высокой доступности требуется четыре из них для обработки сбоев и бесшовных обновлений. Для настройки высокой доступности с 5 репликами чтения и 12 слотами логической репликации установите значения параметров max_replication_slots и max_wal_senders на 21. Эта конфигурация необходима, так как для каждой реплики чтения и каждого слота логической репликации требуется по одному из них, плюс четыре, которые необходимы для правильной функциональности высокой доступности. Дополнительные сведения о параметрах max_replication_slotsmax_wal_senders см. в их документации.
Типы поддержки зоны доступности
База данных Azure для PostgreSQL поддерживает зонизбыточные и зональные модели для конфигураций высокой доступности. Обе конфигурации высокой доступности обеспечивают автоматическое переключение на резерв без потери данных во время как запланированных, так и незапланированных событий.
Зонально-избыточный. Высокая доступность с зональной избыточностью развертывает резервную реплику в другой зоне с возможностью автоматического переключения в случае сбоя. Избыточность зоны обеспечивает высокий уровень доступности, но необходимо настроить избыточность приложений в разных зонах. По этой причине выберите избыточность зоны, если требуется защита от сбоев уровня зоны доступности и когда задержка между зонами доступности допустима. Хотя задержка может повлиять на операции записи и фиксации из-за синхронной репликации, она не влияет на запросы на чтение. Это влияние зависит от рабочих нагрузок, выбранного типа SKU и региона.
Вы можете выбрать регион и зоны доступности для основных и резервных серверов. Резервный сервер реплики подготавливается в выбранной зоне доступности в том же регионе с аналогичной конфигурацией вычислений, хранилища и сети в качестве основного сервера. Файлы данных и файлы журналов транзакций (журналы перед записью, также известные как WAL) хранятся в локально избыточном хранилище (LRS) в каждой зоне доступности, автоматически сохраняя три копии данных. Зонально-избыточная конфигурация обеспечивает физическую изоляцию всего стека между основными и резервными серверами.

Параметр с зональной избыточностью доступен только в регионах с поддержкой зон доступности.
Зональная избыточность не поддерживается для:
- Ресурсоемкие вычислительные уровни
- Регионы с наличием одной зоны
Та же зона (зональная). Выберите зональное развертывание, если вы хотите достичь самого высокого уровня доступности в пределах одной зоны доступности, но с наименьшей задержкой сети. Вы можете выбрать регион и зону доступности, чтобы развернуть оба сервера базы данных-источника. Резервный сервер реплики автоматически подготавливается и управляется в той же зоне доступности с аналогичной вычислительной мощностью, хранилищем и конфигурацией сети, как у основного сервера. Зональная конфигурация защищает базы данных от сбоев на уровне узла, а также помогает сократить время простоя приложения во время запланированных и незапланированных событий простоя. Данные с первичного сервера реплицируются на резервную реплику в синхронном режиме. При сбое основного сервера сервер автоматически переключается на резервную реплику.
Вариант развертывания зональный доступен во всех регионах Azure, где можно развернуть Flexible Server.


Замечание
Модели развертывания, как зональные, так и с избыточностью между зонами, архитектурно ведут себя одинаково. Различные обсуждения в следующих разделах применяются к обоим, если не указано иное.
Восстановление после сбоев зоны
Зонально-избыточный: База данных Azure для PostgreSQL автоматически выполняет отработку отказа на резервный сервер в течение 60–120 секунд с нулевой потерей данных.
Зональный: если зона испытала сбой, первичный и резервный серверы недоступны. Чтобы восстановиться после сбоя на уровне зоны, можно выполнить восстановление на определенный момент времени с помощью резервной копии. Можно выбрать пользовательскую точку восстановления с последним временем для восстановления последних данных. Новый гибкий сервер развернут в другой незатронутой зоне. Время, необходимое для восстановления, зависит от предыдущей резервной копии и объема восстанавливаемых журналов транзакций.
Дополнительные сведения о восстановлении данных на определённую точку во времени см. в разделе Резервное копирование и восстановление в База данных Azure для PostgreSQL-сервере с гибкой настройкой.
Соглашение об уровне обслуживания
Модель избыточности между зонами обеспечивает коэффициент доступности SLA около 99,99%. Зональная модель предлагает время безотказной работы для SLA на уровне 99,95%.
База данных Azure для PostgreSQL без высокой доступности
Хотя это не рекомендуется, можно настроить гибкий сервер без включения высокой доступности. Для гибких серверов, настроенных без высокой доступности, служба предоставляет локально избыточное хранилище с тремя копиями данных и встроенную устойчивость сервера для автоматического перезапуска аварийного сервера и перемещения сервера на другой физический узел. Эта конфигурация обеспечивает более низкую гарантию времени бесперебойной работы, чем серверы с высокой доступностью. Во время запланированных или незапланированных событий отработки отказа, если сервер выходит из строя, служба обеспечивает сохранение доступности серверов с помощью следующей автоматической процедуры:
- Подготовлена новая вычислительная виртуальная машина Linux.
- Хранилище с файлами данных сопоставляется с новой виртуальной машиной.
- Ядро СУБД PostgreSQL подключено к сети на новой виртуальной машине.
На следующем рисунке показан переход между виртуальной машиной и сбоем хранилища.

Настройка бизнес-критических (высокая доступность) параметров
Высокую доступность (HA) можно настроить двумя способами: межзонное резервирование высокой доступности, которое размещает резервный сервер в другой зоне доступности для обеспечения максимальной устойчивости зоны, или резервирование высокой доступности в той же зоне, которое развертывает резервный сервер в той же зоне, что и основной сервер, чтобы свести к минимуму задержку.
В разделе 'Критически важный для бизнеса (высокая доступность)' предоставляется возможность создания резервного сервера высокой доступности с зонально-резервной конфигурацией. Чтобы упростить настройку и обеспечить устойчивость зоны, портал предоставляет параметр зональной устойчивости с двумя переключателями: включено и отключено. Выбор параметра Включено означает попытку создать резервный сервер в другой зоне доступности (зонально-избыточный режим высокой доступности). Если в регионе не поддерживается высокая доступность с избыточностью между зонами, вы можете выбрать параметр "Резервный" для включения высокой доступности в пределах одной зоны (зональный режим).

При выборе резервного флажка система создает резервный сервер в той же зоне. Если впоследствии зональная ёмкость станет доступна, Azure автоматически переносит ваши рабочие нагрузки из режима высокой доступности в одной зоне в режим высокой доступности с резервированием между зонами. Если вы не выбрали флажок, а зональная мощность недоступна, включение функции высокой доступности не удается. Эта конструкция устанавливает зональное резервирование высокой доступности (HA) в качестве стандартного, обеспечивая контролируемый откат на высокую доступность в пределах одной зоны и гарантируя, что рабочие нагрузки в конечном итоге достигнут полной устойчивости по зонам.
Создание База данных Azure для PostgreSQL с включенной зоной доступности
Сведения о создании База данных Azure для PostgreSQL для обеспечения высокой доступности с зонами доступности см. в статье Quickstart: создание База данных Azure для PostgreSQL на портале Azure.
Перераспределение и миграция зон доступности
Чтобы узнать, как включить или отключить конфигурацию высокой доступности на гибком сервере в моделях развёртывания с избыточностью по зонам и в пределах зоны, см. статью "Управление высокой доступностью на гибком сервере".
Отслеживание состояния системы высокой доступности
Мониторинг состояния высокой доступности в База данных Azure для PostgreSQL предоставляет непрерывный обзор здоровья и готовности экземпляров, поддерживающих высокую доступность. Эта функция мониторинга применяет платформу Azure Работоспособность ресурсов check (RHC) для обнаружения и оповещения о любых проблемах, которые могут повлиять на готовность к отработке отказа базы данных или общую доступность. Оценивая ключевые метрики, такие как состояние подключения, состояние отработки отказа и работоспособность репликации данных, мониторинг состояния работоспособности высокой доступности обеспечивает упреждающее устранение неполадок и помогает поддерживать безотказное время работы и производительность базы данных.
Мониторинг состояния работоспособности высокого уровня доступности используется для:
- Получите аналитические сведения о работоспособности основной и резервной реплики в режиме реального времени с индикаторами состояния, которые показывают потенциальные проблемы, такие как снижение производительности или блокировка сети.
- Настройте оповещения для своевременного уведомления о любых изменениях в состоянии высокой доступности, чтобы вы могли немедленно принять меры по устранению потенциальных сбоев.
- Оптимизируйте готовность к восстановлению после сбоев, выявляя и устраняя проблемы до того, как они повлияют на операции базы данных.
Подробное руководство по настройке и интерпретации состояний работоспособности высокого уровня доступности см. в разделе Мониторинг состояния работоспособности высокого уровня доступности (HA) для База данных Azure для PostgreSQL.
Ограничения высокого уровня доступности
Репликация между основным и резервным сервером синхронна.
Сервер высокой доступности (HA) нельзя использовать для выполнения запросов на чтение данных.
В зависимости от рабочей нагрузки и активности на основном сервере процесс переключения может занять более 120 секунд, так как резервная реплика должна восстановиться, прежде чем ее можно будет повысить.
Резервный сервер обычно восстанавливает ФАЙЛЫ WAL в 40 МБ/с. Для более крупных версий эта скорость может увеличиться до 200 МБ/с. Если ваша рабочая нагрузка превышает это ограничение, вы можете столкнуться с тем, что восстановление может занять больше времени, как во время переключения на резерв, так и после установки нового резервного сервера.
Перезапуск сервера базы данных-источника также перезапускает резервную реплику.
Вы не можете настроить дополнительный резервный режим.
Вы не можете запланировать задачи управления, инициированные клиентом, во время управляемого периода обслуживания.
Запланированные события, такие как вычислительные и хранилищные масштабирования, происходят на резервном сервере, а затем на основном сервере. В настоящее время сервер не выполняет автоматическое переключение при отказе для этих запланированных операций.
Настройка зон доступности между частной (виртуальной сетью) и общедоступным доступом с частными конечными точками не поддерживается. Необходимо настроить зоны доступности в виртуальной сети (распределенной между зонами доступности в пределах региона) или публичный доступ с частными конечными точками.
Вы можете настроить только зоны доступности в одном регионе. Невозможно настроить зоны доступности в разных регионах.
Компоненты и рабочие процессы высокого уровня доступности
Выполнение транзакций
Транзакция приложения инициирует запись и подтверждение, которые сначала регистрируются в WAL на основном сервере. Сервер-источник передает эти журналы на резервный сервер с помощью протокола потоковой передачи Postgres. Когда резервное хранилище сервера сохраняет журналы, основной сервер признает завершение записи. Приложение фиксирует транзакцию только после подтверждения. Эта дополнительная круговая поездка добавляет задержку в приложение. Процент влияния зависит от приложения. Этот процесс подтверждения не ожидает применения журналов к резервному серверу. Резервный сервер остается в режиме восстановления, пока не будет активирован.
Проверка состояния здоровья
Гибкий мониторинг работоспособности сервера периодически проверяет работоспособность основных и резервных серверов. После нескольких пингов, если мониторинг работоспособности обнаруживает, что первичный сервер недоступен, служба инициирует автоматическую отработку отказа на резервный сервер. Алгоритм мониторинга работоспособности использует несколько точек данных, чтобы избежать ложных положительных ситуаций.
Режимы отработки отказа
Гибкий сервер поддерживает два режима отработки отказа, плановую отработку отказа и неплановую отработку отказа. В обоих режимах после нарушения репликации резервный сервер запускает восстановление перед повышением до основного сервера и открывается для чтения и записи. При автоматическом обновлении записей DNS с помощью новой конечной точки сервера-источника приложения могут подключаться к серверу с помощью той же конечной точки. Новый резервный сервер устанавливается в фоновом режиме, чтобы приложение может поддерживать подключение.
Статус высокой доступности
Система постоянно отслеживает работоспособность первичных и резервных серверов. Для устранения проблем необходимо выполнить соответствующие действия, включая переключение на резервный сервер. В следующей таблице перечислены возможные состояния высокой доступности:
| Статус | Описание |
|---|---|
| Инициализация | В процессе создания нового резервного сервера |
| Репликация данных | После создания резервного узла он синхронизируется с основным. |
| Здоровый | Репликация находится в стабильном и хорошем состоянии. |
| Переключение при отказе | Сервер базы данных находится в процессе переключения на резервный сервер. |
| Удаление резервного режима | В процессе удаления резервного сервера. |
| Не включено | Высокий уровень доступности не включен. |
Замечание
Вы можете включить высокий уровень доступности во время создания сервера или позже. Если вы включите или отключите высокий уровень доступности на этапе после создания, сделайте это, если активность сервера-источника низка.
Операции в устойчивом состоянии
Клиентские приложения PostgreSQL подключаются к основному серверу с помощью имени сервера базы данных. Сервер-источник непосредственно обслуживает операции чтения приложений. В то же время приложение получает подтверждение фиксаций и выполняет запись только после сохранения данных журнала на основном сервере и резервном экземпляре. Из-за этого дополнительного обмена данными приложения могут ожидать повышенную задержку для операций записи и фиксации изменений. Состояние высокого уровня доступности можно отслеживать на портале.
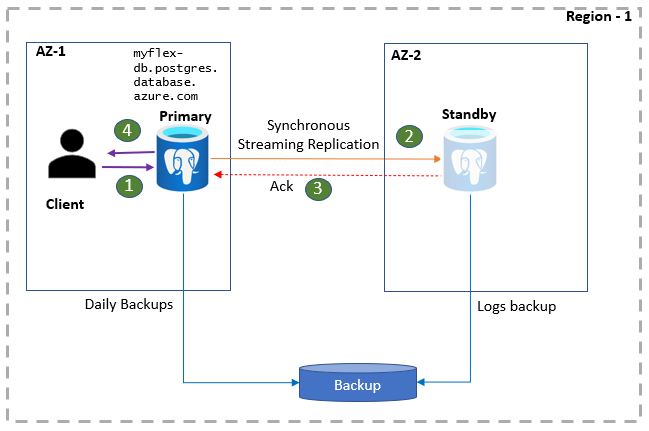
- Клиенты подключаются к гибкому серверу и выполняют операции записи.
- Изменения реплицируются на резервный сайт.
- Первичный получает подтверждение.
- Признаются записи и фиксации.
Восстановление серверов высокой доступности на конкретный момент времени
Для гибких серверов, настроенных с высокой доступностью, система реплицирует данные журнала в режиме реального времени на резервный сервер. Все ошибки пользователя на основном сервере, например случайное удаление таблицы или неправильные обновления данных, реплицируются в резервную реплику. Таким образом, вы не можете использовать резервный режим для восстановления после таких логических ошибок. Чтобы восстановиться после таких ошибок, необходимо выполнить восстановление на определенный момент времени из резервной копии. Используя возможность гибкого сервера для восстановления на определенный момент времени, можно восстановить систему до момента времени до возникновения ошибки. Новый сервер базы данных восстанавливается как зональный (однозонный) гибкий сервер с новым именем сервера, предоставленным пользователем, для баз данных, настроенных с высоким уровнем доступности. Восстановленный сервер можно использовать для нескольких вариантов использования:
Используйте восстановленный сервер для рабочей среды и при необходимости включите высокий уровень доступности с резервной репликой в той же зоне или другой зоне в том же регионе.
Если вы хотите восстановить объект, экспортируйте его с восстановленного сервера базы данных и импортируйте его на рабочий сервер базы данных.
Если вы хотите клонировать сервер базы данных для тестирования и разработки или восстановления для любых других целей, можно выполнить восстановление на определенный момент времени.
Сведения о восстановлении гибкого сервера на определенный момент времени см. в статье "Восстановление гибкого сервера на определенный момент времени".
Поддержка отработки отказа
Плановое переключение на резервную систему
Запланированные события простоя включают запланированные периодические обновления программного обеспечения и незначительные обновления версий для Azure. Вы также можете использовать плановое переключение для возврата первичного сервера в предпочтительную зону доступности. При настройке высокой доступности эти операции сначала применяются к резервной реплике, пока приложения продолжают получать доступ к основному серверу. После обновления процесса резервной реплики, он отключает подключения с основного сервера и запускает переключение, которое активирует резервную реплику в качестве основного сервера с тем же именем сервера базы данных. Клиентские приложения повторно подключаются с тем же именем сервера базы данных к новому основному серверу и могут возобновить свои операции. Процесс устанавливает новый резервный сервер в той же зоне, что и старый первичный.
Подсказка
При наличии гибкого сервера с отказоустойчивостью по зонам, можно также использовать плановое переключение, чтобы вернуть основной сервер в предпочтительную область доступности, минимизировав время простоя. Например, основной сервер может находиться в другой зоне доступности, чем приложение, после незапланированного переключения на резервный. Запланированный процесс переключения на резервный возвращает первичный сервер обратно в исходную зону и устанавливает новый резервный сервер в той же зоне, где был старый первичный.
Для других операций, инициированных пользователем, таких как масштабирование вычислений или масштабирование хранилища, процесс сначала применяет изменения в резервном режиме, а затем основной. В настоящее время служба не переключается на резервный режим. Таким образом, в то время как операция масштабирования выполняется на основном сервере, приложения сталкиваются с коротким временем простоя.
Эту функцию можно также использовать для переключения на резервный сервер с меньшим временем простоя. Например, основной сервер может находиться в другой зоне доступности, чем приложение, после незапланированного переключения на резервный. Вы хотите вернуть основной сервер в предыдущую зону, чтобы разместить его вместе с приложением.
При выполнении этой функции процесс сначала подготавливает резервный сервер, чтобы убедиться, что он перехватывает последние транзакции, позволяя приложению продолжать выполнять операции чтения и записи. Процесс переводит систему в резервный режим и разрывает соединения с основной системой. Приложение может продолжать запись в основной, пока процесс устанавливает новый резервный сервер в фоновом режиме. В следующей таблице описаны шаги, связанные с плановым переключением на резерв.
| Step | Описание | Ожидается ли простой приложения? |
|---|---|---|
| 1 | Подождите, пока резервный сервер догонит основной сервер. | Нет |
| 2 | Внутренняя система мониторинга инициирует процесс переключения. | Нет |
| 3 | Записи приложений блокируются, когда резервный сервер близок к основному номеру последовательности журналов (LSN). | Да |
| 4 | Резервный сервер повышен до статуса независимого сервера. | Да |
| 5 | Запись DNS обновлена, и в ней указан IP-адрес нового резервного сервера. | Да |
| 6 | Приложение повторно подключается и возобновляет чтение и запись с новым главным сервером. | Нет |
| 7 | Устанавливается новый резервный сервер. Для серверов с зональной избыточностью новый сервер находится в другой зоне. | Нет |
| 8 | Резервный сервер начинает восстанавливать журналы (из Azure BLOB-объектов), которые он пропустил во время настройки. | Нет |
| 9 | Устанавливается устойчивое состояние между основным и резервным сервером. | Нет |
| 10 | Процесс запланированного переключения на резерв завершен. | Нет |
Время простоя приложения начинается на шаге 3 и может возобновить работу после шага 5. Остальные действия выполняются в фоновом режиме, не затрагивая записи данных и фиксации транзакций приложения.
Подсказка
С гибким сервером вы можете при необходимости запланировать действия обслуживания, инициированные Azure, выбрав 60-минутное окно в день вашего предпочтения, когда действия в базах данных, как ожидается, будут низкими. Задачи обслуживания Azure, такие как установка исправлений или обновление незначительных версий, происходят в это окно. Если вы не выбираете настраиваемое окно, система выделяет одночасовое окно между 11 вечера и 7 часов локального времени сервера. Эти действия обслуживания, инициированные Azure, также выполняются на резервной реплике для гибких серверов, настроенных с зонами доступности.
Список возможных запланированных событий простоя см. в разделе "Запланированные события простоя".
Внеплановое переключение
Незапланированные простои могут возникать в результате непредвиденных сбоев, таких как базовые ошибки оборудования, проблемы сети и ошибки программного обеспечения. Если сервер базы данных, настроенный с высоким уровнем доступности, неожиданно исчезнет, процесс активирует резервную реплику и клиенты могут возобновить свои операции. Если вы не настраиваете высокий уровень доступности (HA), а попытка перезапуска завершается сбоем, процесс автоматически подготавливает новый сервер базы данных. Хотя незапланированное время простоя невозможно избежать, гибкий сервер помогает снизить время простоя, автоматически выполняя операции восстановления, не требуя вмешательства человека.
Сведения о внеплановых сбоях и простоях, включая возможные сценарии, см. в разделе "Снижение внепланового простоя".
принудительное переключение
Вы можете использовать принудительное переключение на резерв для тестирования отработки отказа, чтобы имитировать непредвиденный отказ при выполнении производственной нагрузки и наблюдать за временем простоя приложения. Вы также можете использовать принудительное переключение, когда основной сервер не отвечает.
Принудительное переключение отказа приводит к отключению первичного сервера и запускает рабочий процесс отказоустойчивости, в котором выполняется операция повышения уровня резервного сервера. После того как резервный сервер завершит процесс восстановления до последнего зафиксированного состояния данных, он будет повышен до первичного сервера. Записи DNS обновляются, и приложение может подключаться к продвинутому основному серверу. Приложение может продолжать записывать данные в основной сервер, пока новый резервный сервер установлен в фоновом режиме, что не влияет на время простоя.
В следующей таблице описаны этапы процесса принудительного переключения при отказе.
| Step | Описание | Ожидается ли простой приложения? |
|---|---|---|
| 1 | Основной сервер останавливается вскоре после получения запроса переключения на резервный. | Да |
| 2 | Так как главный сервер не работает, приложение простаивает. | Да |
| 3 | Внутренняя система мониторинга обнаруживает сбой и инициирует переключение на резервный сервер. | Да |
| 4 | Резервный сервер переходит в режим восстановления до того момента, пока его уровень не будет повышен до независимого сервера. | Да |
| 5 | Процесс отработки отказа ожидает завершения восстановления резервного режима. | Да |
| 6 | После запуска сервера процесс обновляет запись DNS с тем же именем узла, но использует IP-адрес резервного сервера. | Да |
| 7 | Приложение может повторно подключиться к новому главному серверу и возобновить свою работу. | Нет |
| 8 | Создан резервный сервер в предпочтительной зоне. | Нет |
| 9 | Резервный сервер начинает восстанавливать журналы (из Azure BLOB-объектов), которые он пропустил во время настройки. | Нет |
| 10 | Устанавливается устойчивое состояние между основным и резервным сервером. | Нет |
| 11 | Процесс принудительного переключения завершен. | Нет |
Время простоя приложения начинается после шага 1 и продолжается до завершения шага 6. Оставшиеся шаги выполняются в фоновом режиме, не влияя на операции записи и фиксации в приложении.
Это важно
Сквозной процесс переключения при отказе включает (a) переключение на резервный сервер после отказа основного сервера и (b) создание нового резервного сервера в готовом для работы состоянии. Пока ваше приложение бездействует до завершения переключения на резервный режим, измеряйте время простоя с перспективы приложения или клиента, а не весь процесс отключения и переключения.
Рекомендации при выполнении принудительного переключения
Общее время выполнения операции может быть дольше фактического времени простоя приложения.
Это важно
Всегда следите за временем простоя с точки зрения приложения!
Не выполняйте немедленные переключения подряд. Подождите по крайней мере 15–20 минут между переключениями на резервный сервер, чтобы новый вторичный сервер мог полностью запуститься.
Выполните принудительное переключение, чтобы сократить время простоя во время периода низкой активности.
Рекомендации по статистике PostgreSQL после переключения после сбоя
После переключения PostgreSQL, для обеспечения оптимальной производительности базы данных необходимо понимание различных ролей pg_statistic и представлений pg_stat_*. В таблице хранятся статистические pg_statistic данные оптимизатора, которые важны для планировщика запросов. Эти статистические данные включают распределение данных в таблицах и остаются неизменными после переключения на резервный узел, гарантируя, что планировщик запросов сможет эффективно оптимизировать выполнение запросов на основе точной исторической информации о распределении данных.
В отличие от этого, pg_stat_* представления предоставляют статистику активности среды выполнения, например количество сканирований, чтения кортежей и обновлений, хранятся в памяти и сбрасываются при переключении на резервный узел. Примером является отслеживание действий с помощью pg_stat_user_tables, которое применяется для таблиц, определяемых пользователем. Этот сброс точно отражает рабочее состояние нового главного сервера, но также означает потерю исторических данных о деятельности, которые могли бы информировать процесс автоматического удаления мусора и другие операционные эффективности.
Учитывая это различие, следует рассмотреть возможность запуска ANALYZE после отработки отказа PostgreSQL. Это действие обновляет pg_stat_* данные (например, pg_stat_user_tablesс новой статистикой активности вакуума), помогая процессу автовакуума, что, в свою очередь, гарантирует, что производительность базы данных остается оптимальной в новой роли. Этот упреждающий шаг связывает разрыв между сохранением важной статистики оптимизатора и обновлением метрик действий для выравнивания текущего состояния базы данных.
Поддержка логической репликации с функцией высокой доступности
При использовании логической репликации или логического декодирования с высокой доступностью (HA) в База данных Azure для PostgreSQL на гибком сервере важно понимать, как работают слоты репликации в случае отказа и как обеспечить непрерывность репликации.
PostgreSQL 16 и более ранних версий
В PostgreSQL 16 и более ранних версиях слоты логической репликации на резервном сервере не сохраняются автоматически после переключения на ведущий сервер. Чтобы поддерживать логическую репликацию при отказе, необходимо:
- Включить расширение
pg_failover_slots - Настройте необходимые параметры, например:
hot_standby_feedback = on
Без этих конфигураций логическая репликация может перестать работать после переключения на резервный узел, так как слоты репликации недоступны на новом первичном узле.
PostgreSQL 17 и более поздних версий
Начиная с PostgreSQL 17 синхронизация слотов логической репликации поддерживается изначально. При правильной настройке слоты репликации автоматически синхронизируются с резервным сервером.
Чтобы включить это поведение, выполните указанные ниже действия.
- Задайте значение
sync_replication_slots = on. - Задайте значение
hot_standby_feedback = on.
При этих настройках слоты логической репликации сохраняются во время перехода на резервный сервер, и репликация может продолжаться без необходимости использования расширений. Дополнительные сведения см. в документации расширения PG_Failover_Slots.
Важные замечания
- Логические слоты репликации управляются на первичном сервере, но также должны существовать на резервном сервере, чтобы обеспечить продолжение логической репликации после отказоустойчивости.
- Системные представления (например, запросы
pg_replication_slots) показывают только статус на ведущем сервере и не подтверждают, синхронизированы ли слоты с резервным сервером. Система может казаться работоспособной на первичном сервере, но по-прежнему не быть готовой к переключению на резервный режим, чтобы сохранить логические слоты репликации на резервном сервере.
Контроль готовности логической репликации к отказоустойчивости
Чтобы проверить готовность отработки отказа, можно использовать метрику Azure Monitor logical_replication_slot_sync_status (предварительная версия).
Это важно
Чтобы выпустить эту метрику, убедитесь, что параметр metrics.collector_database_activity имеет значение on.
Эта метрика указывает, синхронизированы ли логические слоты репликации между основным и резервным сервером.
-
1указывает, что слоты синхронизируются между основными и резервными. -
0указывает, что слоты не синхронизируются в резервном режиме.
Если значение метрики равно 0, логическая репликация может продолжать функционировать в текущем основном узле, но она может не продолжаться после переключения на резервный узел. Полный список метрик логической репликации см. в разделе "Мониторинг логической репликации".
Замечание
Состояние синхронизации отражает статус на всех узлах высокой доступности и не может быть проверено только с помощью системных представлений на основном узле. Рассмотрите возможность использования этой метрики с оповещениями, чтобы определить, когда логическая репликация не готова к отработку отказа, особенно перед запланированным обслуживанием или событиями отработки отказа. Рассмотрите возможность настройки оповещений, когда эта метрика остается 0 в течение устойчивого периода.