Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Пакет SDK для Python azure-ai-ml версии 2 (current)
Узнайте, как специалист по обработке и анализу данных использует Машинное обучение Azure для обучения модели. В этом примере используется набор данных кредитной карты, чтобы понять, как использовать Машинное обучение Azure для проблемы классификации. Цель заключается в том, чтобы предсказать, имеет ли клиент высокую вероятность по умолчанию на оплату кредитной карты. Скрипт обучения обрабатывает подготовку данных. Затем скрипт обучает и регистрирует модель.
В этом руководстве описано, как отправить облачное задание обучения (задание команды).
- Получение дескриптора в рабочую область Машинное обучение Azure
- Создание вычислительного ресурса и среды задания
- создать сценарий обучения;
- Создание и запуск задания команды для запуска скрипта обучения на вычислительном ресурсе
- Просмотр выходных данных скрипта обучения
- развертывание новой обученной модели в качестве конечной точки;
- Вызов конечной точки Машинное обучение Azure для вывода
Если вы хотите узнать больше о загрузке данных в Azure, см. руководство по отправке, доступу и просмотру данных в Машинное обучение Azure.
В этом видео показано, как приступить к работе в Студия машинного обучения Azure, чтобы выполнить действия, описанные в руководстве. В видео показано, как создать записную книжку, создать вычислительный экземпляр и клонировать записную книжку. Действия также описаны в следующих разделах.
Необходимые компоненты
-
Чтобы использовать Машинное обучение Azure, вам нужна рабочая область. Если у вас нет ресурсов, выполните инструкции по созданию рабочей области и узнайте больше об использовании.
Внимание
Если в рабочей области Машинное обучение Azure настроена управляемая виртуальная сеть, может потребоваться добавить правила для исходящего трафика, чтобы разрешить доступ к общедоступным репозиториям пакетов Python. Дополнительные сведения см. в статье "Сценарий: доступ к общедоступным пакетам машинного обучения".
-
Войдите в студию и выберите рабочую область, если она еще не открыта.
-
Откройте или создайте записную книжку в рабочей области:
- Если вы хотите скопировать и вставить код в ячейки, создайте новую записную книжку.
- Кроме того, откройте учебники/get-started-notebooks/train-model.ipynb из раздела "Примеры " студии. Затем выберите "Клонировать", чтобы добавить записную книжку в файлы. Чтобы найти примеры записных книжек, ознакомьтесь с примерами записных книжек.
Установка ядра и открытие в Visual Studio Code (VS Code)
На верхней панели над открытой записной книжкой создайте вычислительный экземпляр, если у вас еще нет.

Если вычислительный экземпляр остановлен, нажмите кнопку "Пуск вычислений " и дождитесь, пока он не будет запущен.

Подождите, пока вычислительный экземпляр не будет запущен. Затем убедитесь, что ядро, найденное в правом верхнем углу, имеется
Python 3.10 - SDK v2. В противном случае используйте раскрывающийся список для выбора этого ядра.
Если вы не видите это ядро, убедитесь, что вычислительный экземпляр запущен. Если это так, нажмите кнопку "Обновить " в правом верхнем углу записной книжки.
Если вы видите баннер, который говорит, что необходимо пройти проверку подлинности, выберите "Проверка подлинности".
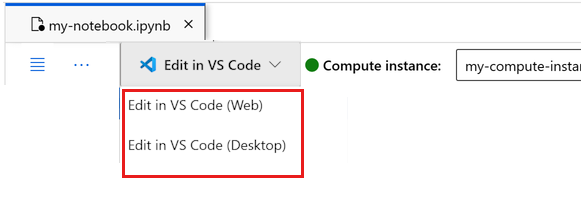
Вы можете запустить записную книжку здесь или открыть ее в VS Code для полной интегрированной среды разработки (IDE) с помощью Машинное обучение Azure ресурсов. Выберите "Открыть" в VS Code, а затем выберите вариант веб-приложения или рабочего стола. При запуске таким образом VS Code присоединяется к вычислительному экземпляру, ядру и файловой системе рабочей области.




Внимание
Остальная часть этого руководства содержит ячейки записной книжки учебника. Скопируйте и вставьте их в новую записную книжку или переключитесь на записную книжку, если она клонирована.
Использование задания команды для обучения модели в Машинное обучение Azure
Чтобы обучить модель, необходимо отправить задание. Машинное обучение Azure предлагает несколько различных типов заданий для обучения моделей. Пользователи могут выбрать свой метод обучения на основе сложности модели, размера данных и требований к скорости обучения. В этом руководстве описано, как отправить задание команды для запуска скрипта обучения.
Задание команды — это функция, которая позволяет отправлять настраиваемый скрипт обучения для обучения модели. Это задание также можно определить как настраиваемое задание обучения. Задание команды в Машинное обучение Azure — это тип задания, выполняющего скрипт или команду в указанной среде. Вы можете использовать задания команд для обучения моделей, обработки данных или любого другого пользовательского кода, который вы хотите выполнить в облаке.
В этом руководстве основное внимание уделяется использованию задания команды для создания настраиваемого задания обучения, используемого для обучения модели. Для любого настраиваемого задания обучения требуются следующие элементы:
- окружающая среда
- .
- задание команды
- обучающий скрипт
В этом руководстве приведены следующие элементы: создание классификатора для прогнозирования клиентов, которые имеют высокую вероятность по умолчанию для оплаты кредитной карты.
Создание дескриптора в рабочей области
Прежде чем изучить код, вам потребуется способ ссылаться на рабочую область. Создайте ml_client дескриптор рабочей области. Затем используйте ml_client для управления ресурсами и заданиями.
В следующей ячейке введите идентификатор подписки, имя группы ресурсов и имя рабочей области. Вот как найти эти значения:
- На панели инструментов в правом верхнем углу Студии машинного обучения Azure выберите имя рабочей области.
- Скопируйте значение рабочей области, группы ресурсов и идентификатор подписки в код. Необходимо скопировать одно значение, закрыть область и вставить, а затем вернуться к следующей.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Примечание.
Создание MLClient не подключается к рабочей области. Инициализация клиента отложена. Он ожидает первого вызова, который происходит в следующей ячейке кода.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Создание среды задания
Чтобы запустить задание Машинное обучение Azure в вычислительном ресурсе, вам потребуется среда. Среда содержит список среды выполнения программного обеспечения и библиотек, которые необходимо установить на вычислительных ресурсах, где выполняется обучение. Это похоже на среду Python на локальном компьютере. Дополнительные сведения см. в статье о Машинное обучение Azure средах?
Машинное обучение Azure предоставляет множество готовых или готовых сред, которые полезны для распространенных сценариев обучения и вывода.
В этом примере создается настраиваемая среда conda для заданий с помощью файла conda yaml.
Сначала создайте каталог для хранения файла.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Следующая ячейка использует магию IPython для записи файла conda в созданный каталог.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
Спецификация содержит некоторые обычные пакеты, используемые в задании, такие как numpy и pip.
Обратитесь к этому yaml-файлу , чтобы создать и зарегистрировать эту настраиваемую среду в рабочей области:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
Настройка задания обучения с помощью функции команды
Вы создаете задание команды Машинное обучение Azure для обучения модели для прогнозирования по умолчанию кредита. Задание команды запускает скрипт обучения в указанной среде для указанного вычислительного ресурса. Вы уже создали среду и вычислительный кластер. Затем создайте скрипт обучения. В этом случае вы обучаете набор данных для создания классификатора с помощью GradientBoostingClassifier модели.
Скрипт обучения обрабатывает подготовку данных, обучение и регистрацию обученной модели. Метод train_test_split разбивает набор данных на тестовые и обучающие данные. В этом руководстве описано, как создать скрипт обучения Python.
Задания команд можно запускать из интерфейса командной строки, пакета SDK для Python или интерфейса студии. В этом руководстве используйте пакет SDK python для Машинное обучение Azure версии 2 для создания и запуска задания команды.
Создание скрипта обучения
Начните с создания скрипта обучения: main.py файла Python. Сначала создайте исходную папку для скрипта:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Этот скрипт предварительно обрабатывает данные, разделяя их на тестовые и обучающие данные. Затем он использует данные для обучения модели на основе дерева и возврата выходной модели.
MLFlow используется для регистрации параметров и метрик во время этого задания. Пакет MLFlow позволяет отслеживать метрики и результаты для каждой модели azure. Используйте MLFlow, чтобы получить лучшую модель для данных. Затем просмотрите метрики модели в Студии Azure. Дополнительные сведения см. в разделе MLflow и Машинное обучение Azure.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
В этом скрипте после обучения модели файл модели сохраняется и регистрируется в рабочей области. Регистрация модели позволяет хранить и версии моделей в облаке Azure в рабочей области. После регистрации модели можно найти все остальные зарегистрированные модели в одном месте в Azure Studio, называемом реестром моделей. Реестр моделей позволяет организовывать и отслеживать обученные модели.
Настройка команды
Теперь, когда у вас есть скрипт, который может выполнять задачу классификации, используйте команду общего назначения, которая может выполнять действия командной строки. Это действие командной строки может быть непосредственно вызовом системных команд или выполнением скрипта.
Создайте входные переменные для указания входных данных, разделения соотношения, скорости обучения и имени зарегистрированной модели. Сценарий команды:
- Использует среду, созданную ранее. Используйте
@latestнотацию, чтобы указать последнюю версию среды при выполнении команды. - Настраивает само действие командной строки в
python main.pyданном случае. Доступ к входным и выходным данным в команде можно получить с помощью${{ ... }}нотации. - Так как вычислительный ресурс не указан, скрипт выполняется в бессерверном вычислительном кластере , который создается автоматически.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
отправить задание.
Отправьте задание для выполнения в Студия машинного обучения Azure. На этот раз используйте create_or_updateml_client.
ml_client— это клиентский класс, позволяющий подключаться к подписке Azure с помощью Python и взаимодействовать со службами Машинное обучение Azure.
ml_client позволяет отправлять задания с помощью Python.
ml_client.create_or_update(job)
Просмотр выходных данных задания и ожидание завершения задания
Чтобы просмотреть задание в Студия машинного обучения Azure, выберите ссылку в выходных данных предыдущей ячейки. Выходные данные этого задания выглядят следующим образом в Студия машинного обучения Azure. Ознакомьтесь с вкладками для различных сведений, таких как метрики, выходные данные и т. д. После завершения задания она регистрирует модель в рабочей области в результате обучения.
Внимание
Дождитесь завершения состояния задания, прежде чем вернуться к этой записной книжке. Выполнение задания занимает от 2 до 3 минут. Это может занять до 10 минут, если вычислительный кластер был масштабирован до нуля узлов и настраиваемая среда по-прежнему строится.
При запуске ячейки выходные данные записной книжки отображают ссылку на страницу сведений о задании в Машинное обучение студии. Кроме того, можно выбрать задания на левой панели.
Задание представляет собой совокупность нескольких запусков указанного скрипта или фрагмента кода. Сведения о запуске хранятся в соответствующем задании. На странице сведений представлен обзор задания, времени его выполнения, времени его создания и других сведений. На странице также есть вкладки для других сведений о задании, таких как метрики, выходные данные + журналы и код. Ниже приведены вкладки, доступные на странице сведений о задании:
- Обзор. Основные сведения о задании, включая его состояние, время начала и окончания, а также тип выполняемого задания
- Входные данные: данные и код, используемые в качестве входных данных для задания. Этот раздел может включать наборы данных, скрипты, конфигурации среды и другие ресурсы, которые использовались во время обучения.
- Выходные данные + журналы: журналы, созданные во время выполнения задания. Эта вкладка помогает устранять неполадки при возникновении ошибок при создании скрипта обучения или модели.
- Метрики: ключевые метрики производительности из модели, такие как оценка обучения, оценка f1 и оценка точности.
Очистка ресурсов
Если вы планируете продолжить работу с другими руководствами, перейдите к связанному содержимому.
Остановка вычислительного экземпляра
Если вы сейчас не планируете использовать вычислительный экземпляр, остановите его, выполнив следующие действия:
- В студии в левой области выберите "Вычисления".
- На верхних вкладках выберите экземпляры вычислений.
- Выберите вычислительный экземпляр из списка.
- В верхней панели инструментов выберите Остановить.
Удаление всех ресурсов
Внимание
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
В портал Azure в поле поиска введите группы ресурсов и выберите его из результатов.
Выберите созданную группу ресурсов из списка.
На странице "Обзор" выберите "Удалить группу ресурсов".
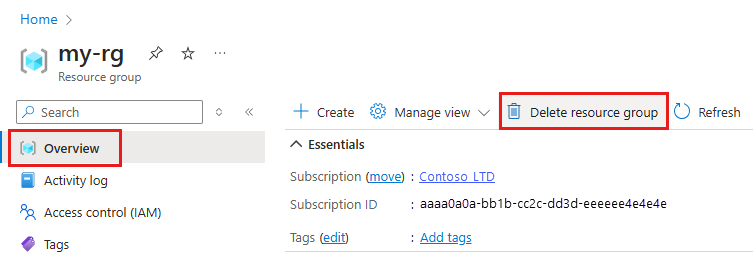
Введите имя группы ресурсов. Затем выберите Удалить.
Связанный контент
Сведения о развертывании модели:
В этом руководстве используется файл данных в Интернете. Дополнительные сведения о других способах доступа к данным см. в руководстве по отправке, доступу и изучению данных в Машинное обучение Azure.
Автоматизированное машинное обучение — это дополнительное средство, позволяющее сократить время, которое специалист по обработке и анализу данных тратит на поиск модели, которая лучше всего работает с данными. Дополнительные сведения см. в статье "Что такое автоматизированное машинное обучение".
Если вы хотите больше примеров, аналогичных этому руководству, ознакомьтесь с примерами записных книжек. Эти примеры доступны на странице примеров GitHub. Примеры включают полные записные книжки Python, которые можно запустить код и научиться обучать модель. Можно изменить и запустить существующие скрипты из примеров, содержащих сценарии, включая классификацию, обработку естественного языка и обнаружение аномалий.