Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве описано, как обучить модель классификации без кода автоматизированного машинного обучения (AutoML) с помощью Машинное обучение Azure в Студия машинного обучения Azure. Эта модель классификации прогнозирует, подписывается ли клиент на фиксированный срок депозита с финансовым учреждением.
С помощью автоматизированного машинного обучения можно автоматизировать задачи с интенсивным временем. Автоматическое машинное обучение позволяет быстро выполнить итерацию множества сочетаний алгоритмов и гиперпараметров, пока не будет найдена лучшая модель на основе выбранных удачных метрик.
Вы не пишете код в этом руководстве. Для обучения используется интерфейс студии. Вы узнаете, как выполнить следующие задачи:
- Создание рабочей области машинного обучения Azure
- Выполнение эксперимента автоматизированного машинного обучения
- Изучение сведений о модели
- Развертывание рекомендуемой модели
Необходимые компоненты
Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись.
Скачайте файл данных bank+marketing.zip. Мы будем использовать файлbank-full.csv . Столбец y в нем указывает, подписан ли клиент на депозит с фиксированным сроком. Впоследствии он будет выбран в этом учебнике как целевой столбец для прогнозов.
Примечание.
Этот набор данных для маркетинга банка доступен в соответствии с международной лицензией Creative Commons Attribution 4.0. Этот набор данных доступен в составе базы данных машинного обучения UCI.
Моро, С., Рита и Кортес. 2014. Банковский маркетинг. Репозиторий машинного обучения UCI. https://doi.org/10.24432/C5K306.
Создание рабочей области
Рабочая область машинного обучения Azure — это основной ресурс в облаке для экспериментов, обучения и развертывания моделей машинного обучения. Она связывает подписку и группу ресурсов Azure с легко используемым объектом в службе.
Выполните следующие действия, чтобы создать рабочую область и продолжить учебник.
Войдите в Студию машинного обучения Azure.
Выберите "Создать рабочую область".
Укажите следующие сведения для настройки новой рабочей области:
Поле Описание имя рабочей области. Введите уникальное имя для идентификации рабочей области. Имена должны быть уникальными в группе ресурсов. Используйте имя, которое позволит легко запомнить рабочую область и отличить ее от областей, созданных другими пользователями. В имени рабочей области не учитывается регистр. Отток подписок Выберите подписку Azure, которую нужно использовать. Группа ресурсов Используйте группу ресурсов, которая есть в подписке, или введите имя, чтобы создать группу ресурсов. Группа ресурсов содержит связанные ресурсы для решения Azure. Для использования существующей группы ресурсов требуется роль участника или владельца. Дополнительные сведения см. в статье Управление доступом к рабочей области Машинного обучения Azure. Область/регион Для создания рабочей области выберите ближайший к пользователям и ресурсам данных регион Azure. Щелкните Создать, чтобы создать рабочую область.
Дополнительные сведения о ресурсах Azure см. в статье "Создание рабочей области".
Чтобы создать рабочую область в Azure, управляйте Машинное обучение Azure рабочими областями на портале или с помощью пакета SDK для Python версии 2.
Создание задания автоматизированного Машинное обучение
Выполните следующие действия по настройке и выполнению эксперимента с помощью Студия машинного обучения Azure по адресуhttps://ml.azure.com. Машинное обучение Studio — это объединенный веб-интерфейс, включающий средства машинного обучения для выполнения сценариев обработки и анализа данных для специалистов по обработке и анализу данных всех уровней навыков. Студия не поддерживается в браузерах Internet Explorer.
Выберите свою подписку и рабочую область, которую создали.
В области навигации выберите "Разработка>автоматизированного машинного обучения".
Так как это первый автоматизированный эксперимент машинного обучения, вы увидите пустой список и ссылки на документацию.
Выберите новое задание автоматизированного машинного обучения.
В методе обучения выберите "Обучение автоматически", а затем нажмите кнопку "Начать настройку задания".
В базовых параметрах выберите "Создать", а затем в поле "Имя эксперимента" введите my-1st-automl-experiment.
Нажмите кнопку "Рядом", чтобы загрузить набор данных.

Создание и загрузка набора данных в качестве ресурса данных
Перед настройкой эксперимента отправьте файл данных в рабочую область в виде Машинное обучение Azure ресурса данных. В этом руководстве вы можете подумать о ресурсе данных в качестве набора данных для задания автоматизированного машинного обучения. Это позволяет убедиться, что данные форматируются соответствующим образом для эксперимента.
В поле "Тип задачи" и "Данные" для типа задачи выберите "Классификация".
В разделе "Выбор данных" нажмите кнопку "Создать".
В форме типа данных укажите имя ресурса данных и укажите необязательное описание.
Для типа выберите табличный элемент. В настоящее время автоматический интерфейс машинного обучения поддерживает только табличные наборы Данных.
Выберите Далее.
В форме источника данных выберите "Из локальных файлов". Выберите Далее.
В целевом типе хранилища выберите хранилище данных по умолчанию, которое было автоматически настроено во время создания рабочей области: workspaceblobstore. Вы отправляете файл данных в это расположение, чтобы сделать его доступным для рабочей области.
Выберите Далее.
В разделе "Файл" или "Папка" выберите "Отправить файлы" или "Отправить файлы".>
Выберите файл bankmarketing_train.csv на локальном компьютере. Вы скачали этот файл в качестве обязательного условия.
Выберите Далее.
После завершения отправки область предварительного просмотра данных заполняется на основе типа файла.
В форме "Параметры" просмотрите значения данных. Затем выберите Далее.
Поле Описание Значение для руководства Формат файла Свойство определяет структуру и тип данных, хранящихся в файле. с разделением Разделитель Один или несколько символов для указания границы между отдельными, независимыми регионами в виде простого текста или других потоков данных. Точка с запятой Кодировка Определяет, какой бит следует использовать в таблице схемы символов, чтобы считать набор данных. UTF-8 Заголовки столбцов Указывает, как обрабатываются заголовки набора данных, если таковые имеются. Все файлы имеют одинаковые заголовки Пропустить строки Указывает, сколько строк, если таковые имеются, пропускается в наборе данных. нет Форма Схема позволяет выполнять дальнейшую настройку данных для этого эксперимента. В этом примере выберите переключатель для функции day_of_week, чтобы не включать его. Выберите Далее.
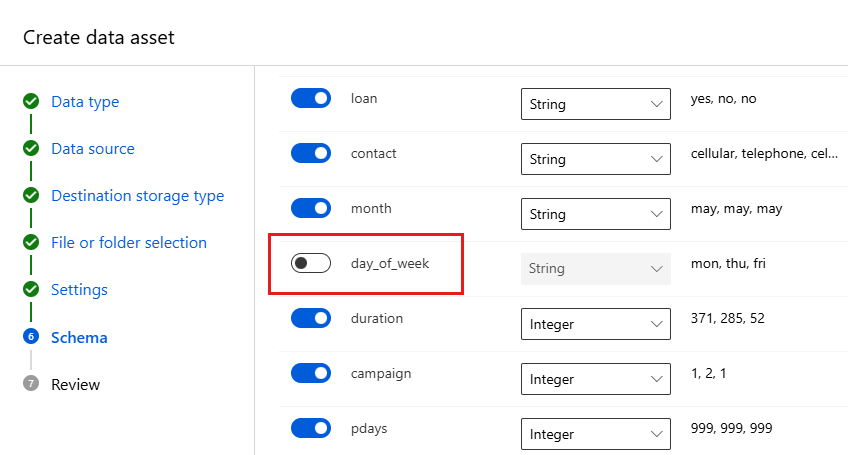
В форме проверки проверьте сведения и нажмите кнопку "Создать".
Выберите в списке набор данных.
Просмотрите данные, выбрав ресурс данных и просмотрев вкладку предварительного просмотра . Убедитесь, что он не включает day_of_week и нажмите кнопку "Закрыть".
Нажмите кнопку "Далее ", чтобы перейти к параметрам задач.
Настроить задание
После загрузки и настройки данных можно настроить эксперимент. Эта настройка включает в себя такие задачи разработки эксперимента, как выбор размера вычислительной среды и указание столбца, который необходимо спрогнозировать.
Заполните форму параметров задачи следующим образом:
Выберите y (Строка) в качестве целевого столбца, который является тем, что вы хотите прогнозировать. Этот столбец содержит сведения о том, подписан ли клиент на срочный депозит или нет.
Выберите View additional configuration settings (Просмотреть дополнительные параметры конфигурации) и заполните поля следующим образом. Эти настройки предназначены для лучшего управления заданием для обучения. В противном случае применяются значения по умолчанию, основанные на выборе эксперимента и данных.
Дополнительные конфигурации Описание Значение для руководства Основная метрика Метрика оценки, используемая для измерения алгоритма машинного обучения. Взвешенная AUC Пояснения для наилучшей модели Автоматическое отображение пояснений для лучшей модели, созданной с помощью автоматизированного машинного обучения. Включить Заблокированные модели Алгоритмы, которые вы хотите исключить из задания обучения. нет Выберите Сохранить.
В разделе " Проверка и проверка":
- Для типа проверки выберите перекрестную проверку k-свертывания.
- Для количества перекрестных проверок выберите 2.
Выберите Далее.
Выберите в качестве типа вычислений вычислительный кластер.
Целевым объектом вычислений называется локальная или облачная среда, в которой будет запущен сценарий обучения или размещена развернутая служба. Для этого эксперимента можно попробовать облачные бессерверные вычисления (предварительная версия) или создать собственные облачные вычислительные ресурсы.
Примечание.
Чтобы использовать бессерверные вычисления, включите предварительную версию функции, выберите бессерверные и пропустите эту процедуру.
Чтобы создать собственный целевой объект вычислений, в разделе "Выбор типа вычислений" выберите кластер вычислений, чтобы настроить целевой объект вычислений.
Заполните форму Виртуальная машина, чтобы настроить вычислительную среду. Выберите Создать.
Поле Описание Значение для руководства Расположение Регион, из которого вы хотите запустить компьютер западная часть США 2 Уровень виртуальных машин Выберите приоритет, который должен иметь ваш эксперимент. Выделенные Тип виртуальной машины Выберите тип виртуальной машины для вычислительной среды. ЦП (центральный процессор) размер виртуальной машины; Выберите размер виртуальной машины для вычислительной среды. Список рекомендуемых размеров выводится с учетом ваших данных и типа эксперимента. Standard_DS12_V2 Нажмите кнопку "Далее ", чтобы перейти к форме "Дополнительные параметры ".
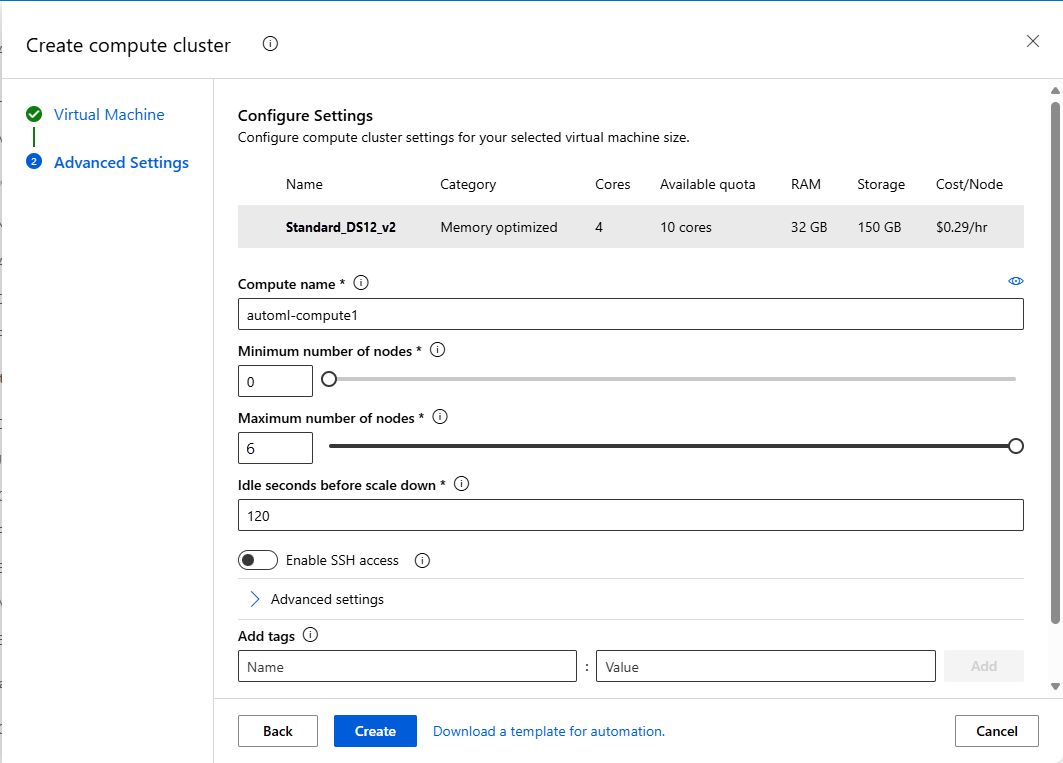
Поле Описание Значение для руководства Имя вычислительной среды Уникальное имя для идентификации контекста вычислительной среды. automl-compute Min/Max nodes (Минимальное и максимальное количество узлов) Для профилирования данных необходимо указать один или больше узлов. Минимальные узлы: 1
Максимальное число узлов: 6Время до уменьшения масштаба (сек) Время простоя перед автоматическим уменьшением масштаба кластера до минимального количества узлов. 120 (по умолчанию) Расширенные настройки Параметры для настройки и авторизации виртуальной сети для эксперимента. нет Нажмите кнопку создания.
Создание вычислительных ресурсов может занять несколько минут.
После создания выберите новый целевой объект вычислений из списка. Выберите Далее.
Выберите " Отправить обучающее задание ", чтобы запустить эксперимент. Откроется экран "Обзор " с состоянием в верхней части, когда начинается подготовка эксперимента. Это состояние обновляется по мере выполнения эксперимента. Уведомления также отображаются в студии, чтобы сообщить о состоянии эксперимента.

Внимание
Подготовка к запуску эксперимента занимает 10-15 минут. С начала эксперимента на каждую итерацию уходит 2-3 минуты.
В рабочей среде у вас будет время заняться другими делами. Но для этого руководства вы можете начать изучение проверенных алгоритмов на вкладке "Модели " по мере их завершения, пока другие продолжают работать.
Изучение моделей
Перейдите на вкладку "Модели и дочерние задания ", чтобы просмотреть проверенные алгоритмы (модели). По умолчанию задание упорядочивает модели по оценке метрик по завершении. В этом руководстве модель, которая оценивает наибольшее значение на основе выбранной метрики AUCWeighted , находится в верхней части списка.
В ожидании завершения всех моделей эксперимента вы можете щелкнуть Algorithm name (Имя алгоритма) для любой завершенной модели, чтобы просмотреть сведения о ее эффективности. Выберите вкладки "Обзор " и "Метрики" для получения сведений о задании.
В следующей анимации отображаются свойства, метрики и диаграммы производительности выбранной модели.

Просмотр объяснений модели
Пока вы ожидаете завершения моделей, вы также можете взглянуть на пояснения к модели и узнать, какие функции данных (необработанные или спроектированные) влияют на прогнозы конкретной модели.
Эти объяснения модели можно создавать по требованию. На панели мониторинга модели, которая входит в вкладку "Пояснения ( предварительная версия) сводные сведения об этих объяснениях.
Чтобы создать объяснения модели, выполните указанные действия.
В верхней части страницы в ссылках навигации выберите имя задания, чтобы вернуться на экран "Модели ".
Перейдите на вкладку "Модели и дочерние задания ".
Для этого руководства выберите первую модель MaxAbsScaler, LightGBM.
Выберите "Объяснить модель". Справа появится панель Пояснение к модели.
Выберите тип вычислений и выберите экземпляр или кластер: automl-compute , созданный ранее. Это вычисление запускает дочернее задание для создания объяснений модели.
Нажмите кнопку создания. Появится зеленое сообщение об успешном выполнении.
Примечание.
Задание создания пояснений занимает от 2 до 5 минут.
Выберите "Объяснения" (предварительная версия). Эта вкладка заполняется после завершения выполнения объясняемости.
Слева разверните область. В разделе "Компоненты" выберите строку, которая говорит необработанные.
Перейдите на вкладку "Агрегатная важность функции". На этой диаграмме показаны функции данных, влияющие на прогнозы выбранной модели.
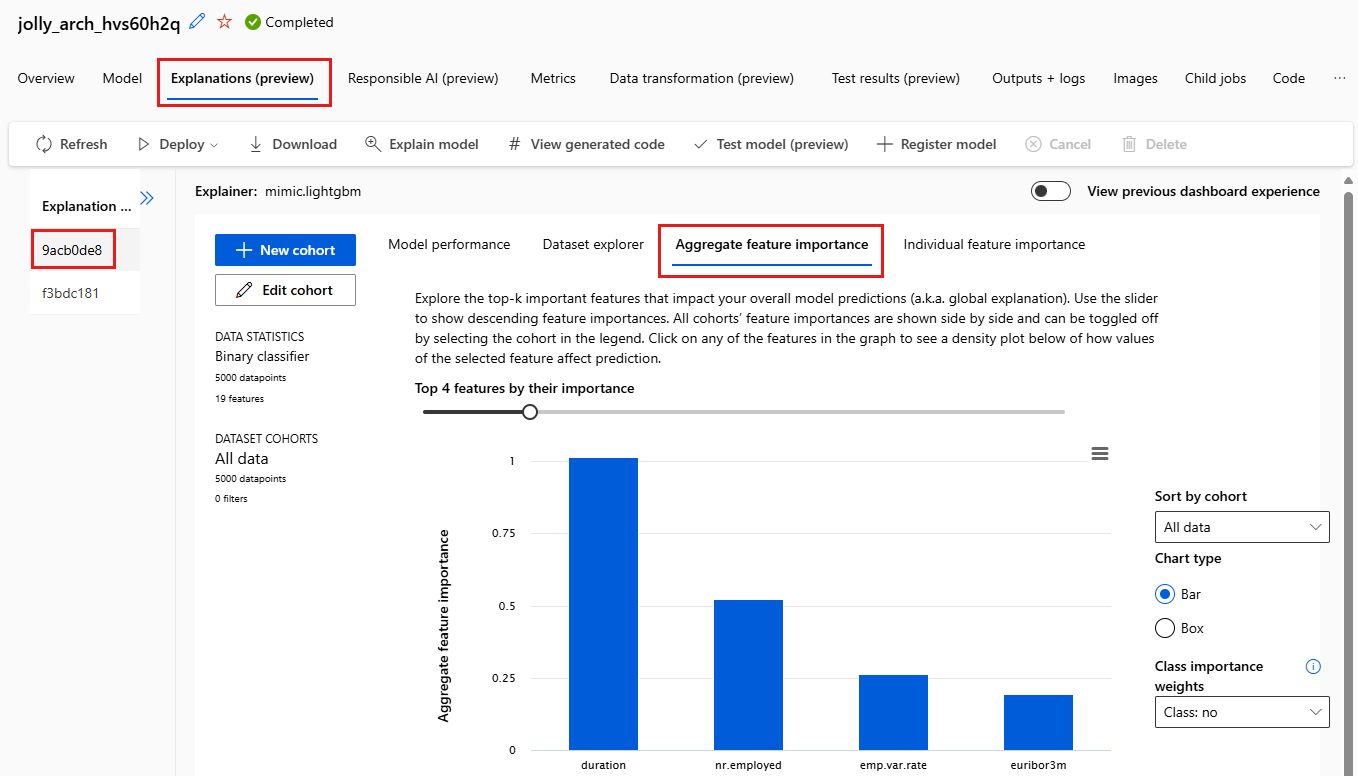
В этом примере Длительность имеет наибольшее влияние на прогнозы этой модели.

Развертывание лучшей модели
Интерфейс автоматизированного машинного обучения позволяет развертывать лучшую модель как веб-службу. Развертывание — это интеграция модели, поэтому она может прогнозировать новые данные и определять потенциальные области возможностей. Для этого эксперимента развертывание в веб-службе предоставит финансовому учреждению итеративное и масштабируемое решение для определения потенциальных клиентов по депозитам с фиксированным сроком.
Проверьте, завершено ли выполнение эксперимента. Для этого вернитесь на страницу родительского задания, выбрав имя задания в верхней части экрана. Состояние Завершено отображается в левом верхнем углу экрана.
После завершения выполнения эксперимента страница сведений заполняется разделом "Лучшая сводка модели". В этом контексте эксперимента VotingEnsemble считается лучшей моделью на основе метрики AUCWeighted .
Разверните эту модель. Развертывание занимает около 20 минут. Процесс развертывания выполняется за несколько шагов, включая регистрацию модели, создание ресурсов и их настройку для веб-службы.
Выберите VotingEnsemble, чтобы открыть страницу для конкретной модели.
Выберите "Развернуть>веб-службу".
Заполните панель Deploy a model (Развертывание модели), как показано ниже.
Поле Значение Имя. my-automl-deploy Описание My first automated machine learning experiment deployment (Первое развертывание эксперимента автоматического машинного обучения) Тип вычисления Выбор экземпляра контейнера Azure Включение проверки подлинности Отключить. Использовать настраиваемые ресурсы развертывания Отключить. Это позволяет автоматически создавать файл драйвера (скрипт оценки) и файл среды по умолчанию. В этом примере используйте значения по умолчанию, указанные в меню "Дополнительно ".
Выберите Развернуть.
В верхней части экрана задания появится зеленое сообщение об успешном выполнении. В области сводки модели в разделе "Состояние развертывания" появится сообщение о состоянии "Развертывание". Периодически щелкайте Обновить, чтобы проверять состояние развертывания.
У вас есть операционная веб-служба для создания прогнозов.
Перейдите к связанному содержимому, чтобы узнать больше о том, как использовать новую веб-службу, и протестируйте прогнозы с помощью Power BI, встроенной в Машинное обучение Azure поддержки.
Очистка ресурсов
Файлы развертывания имеют больший размер, чем файлы данных и экспериментов, поэтому их хранение обходится дороже. Если вы хотите сохранить рабочие области и файлы экспериментов, удалите только файлы развертывания, чтобы свести к минимуму затраты на учетную запись. Если вы не планируете использовать файлы, удалите всю группу ресурсов.
Удаление промежуточного развертывания
Удаление только экземпляра развертывания из Машинное обучение Azurehttps://ml.azure.com/.
Перейдите в Машинное обучение Azure. Перейдите в рабочую область и в области "Активы" выберите "Конечные точки".
Выберите развертывание для удаления и щелкните Удалить.
Выберите Продолжить.
Удаление группы ресурсов
Внимание
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
В портал Azure в поле поиска введите группы ресурсов и выберите его из результатов.
Выберите созданную группу ресурсов из списка.
На странице "Обзор" выберите "Удалить группу ресурсов".
Введите имя группы ресурсов. Затем выберите Удалить.
Связанный контент
В ходе работы с этим руководством по автоматизированному машинному обучению вы создали и развернули модель классификации с помощью интерфейса автоматизированного машинного обучения в службе "Машинное обучение Azure". Дополнительные сведения и дальнейшие действия см. в следующих ресурсах:
- Дополнительные сведения об автоматическом машинном обучении.
- Узнайте о метриках классификации и диаграммах: оценка результатов эксперимента автоматизированного машинного обучения.
- Узнайте больше о настройке AutoML для NLP.
Также опробуйте автоматизированное машинное обучение для таких типов моделей:
- Пример прогнозирования без кода см. в разделе "Руководство. Прогнозирование спроса без кода автоматизированного машинного обучения в Студия машинного обучения Azure".
- Первый пример кода модели обнаружения объектов см. в руководстве по обучению модели обнаружения объектов с помощью AutoML и Python.