Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Конечные точки пакетной службы позволяют развертывать модели, которые выполняют вывод по большим объемам данных. Эти конечные точки упрощают размещение моделей для пакетной оценки, поэтому вы можете сосредоточиться на машинном обучении вместо инфраструктуры.
Используйте пакетные конечные точки для развертывания моделей при:
- Вы используете дорогие модели, которые требуют больше времени для вывода.
- Вы выполняете вывод данных над большими объемами данных, распределённых в нескольких файлах.
- Не требуется низкая задержка.
- Вы используете преимущества параллелизации.
В этой статье показано, как использовать пакетную конечную точку для развертывания модели машинного обучения, которая решает классическую проблему распознавания цифр MNIST (Измененный Национальный институт стандартов и технологий). Развернутая модель выполняет пакетное прогнозирование больших объемов данных, таких как файлы изображений. Процесс начинается с создания пакетного развертывания модели, созданной с помощью Torch. Это развертывание становится стандартным в точке доступа. Позже создайте второе развертывание модели, созданной с помощью TensorFlow (Keras), протестируйте второе развертывание и задайте его в качестве развертывания по умолчанию конечной точки.
Необходимые компоненты
Прежде чем выполнить действия, описанные в этой статье, убедитесь, что у вас есть следующие предварительные требования:
Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу. Попробуйте бесплатную или платную версию Машинного обучения Azure.
Рабочая область Машинного обучения Azure. Если у вас нет одного, выполните действия, описанные в статье "Управление рабочими областями ", чтобы создать ее.
Чтобы выполнить следующие задачи, убедитесь, что в рабочей области есть следующие разрешения:
Для создания и управления конечными точками и развертываниями пакетной службы: используйте роль владельца, роль участника или пользовательскую роль, разрешающую
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.Чтобы создать развертывания ARM в группе ресурсов рабочей области: используйте роль владельца, роль участника или пользовательскую роль, разрешающую
Microsoft.Resources/deployments/writeв группе ресурсов, в которой развернута рабочая область.
Для работы с Машинное обучение Azure необходимо установить следующее программное обеспечение:
ОБЛАСТЬ ПРИМЕНЕНИЯ:
расширение машинного обучения Azure CLI версии 2 (текущее)Azure CLI и
mlрасширение для Машинное обучение Azure.az extension add -n ml
Клонирование репозитория примеров
Пример в этой статье основан на примерах кода, содержащихся в репозитории azureml-examples . Чтобы выполнить команды локально без необходимости копирования и вставки YAML и других файлов, сначала клонируйте репозиторий, а затем измените каталоги в папку:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Подготовка системы
Подключение к рабочей области
Сначала подключитесь к рабочей области Машинного обучения Azure, в которой вы работаете.
Если вы еще не задали параметры по умолчанию для Azure CLI, сохраните их. Чтобы избежать ввода значений для подписки, рабочей области, группы ресурсов и расположения несколько раз, выполните следующий код:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Создание вычислений
Конечные точки пакетной службы выполняются в вычислительных кластерах и поддерживают как Машинное обучение Azure вычислительные кластеры (AmlCompute), так и кластеры Kubernetes. Кластеры являются общим ресурсом, поэтому один кластер может размещать один или несколько пакетных развертываний (а также другие рабочие нагрузки, если это необходимо).
Создайте вычисление с именем batch-cluster, как показано в следующем коде. Настройте по мере необходимости и используйте свои вычислительные ресурсы с помощью azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Примечание.
Плата за вычислительные ресурсы не взимается на этом этапе, так как кластер остается равным 0 узлам до тех пор, пока не будет вызвана конечная точка для пакетной обработки и не отправлено задание на пакетную оценку. Дополнительные сведения о затратах на вычислительные ресурсы см. в разделе "Управление и оптимизация затрат для AmlCompute".
Создание пакетной конечной точки
Конечная точка пакетной службы — это конечная точка HTTPS, вызываемая клиентами для активации задания оценки пакетной службы. Пакетное задание оценки оценивает несколько входных данных. Пакетное развертывание — это набор вычислительных ресурсов, размещающих модель, выполняющую пакетное инференсирование. У одной пакетной конечной точки может быть несколько развертываний пакетной службы. Дополнительные сведения о конечных точках пакетной службы см. в разделе "Что такое конечные точки пакетной службы?".
Совет
Одно из пакетных развертываний служит развертыванием по умолчанию для конечной точки. При вызове конечной точки развертывание по умолчанию выполняет пакетную оценку. Дополнительные сведения о конечных точках пакетной службы и развертываниях см. в разделе "Конечные точки пакетной службы" и "Пакетное развертывание".
Назовите конечную точку. Имя конечной точки должно быть уникальным в пределах региона Azure, так как имя входит в универсальный код ресурса (URI) конечной точки. Например, в ней может быть только одна конечная точка пакетной службы с именем
mybatchendpointwestus2.Настройка конечной точки пакетной службы
Следующий ФАЙЛ YAML определяет конечную точку пакетной службы. Используйте этот файл с командой CLI для создания пакетной конечной точки.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningВ следующей таблице описываются ключевые свойства конечной точки. Полная схема YAML пакетной конечной точки см. в YAML схеме пакетной конечной точки CLI (версии 2).
Ключ. Описание nameИмя учетной записи пакетной конечной точки. Должно быть уникальным на уровне региона Azure. descriptionОписание конечной точки пакетной службы. Это необязательное свойство. tagsТеги для включения в конечную точку. Это необязательное свойство. Создание конечной точки:
Создание развертывания пакетной службы
Развертывание модели — это набор ресурсов, необходимых для размещения модели, которая выполняет фактическое вывод. Чтобы создать развертывание пакетной модели, вам потребуется следующее:
- Зарегистрированная модель в рабочей области
- Код для оценки модели
- Среда с установленными зависимостями модели
- Предварительно созданные параметры вычислений и ресурсов
Начните с регистрации модели для развертывания — модель Факела для проблемы с распознаванием популярных цифр (MNIST). Пакетные развертывания могут развертывать только модели, зарегистрированные в рабочей области. Этот шаг можно пропустить, если модель, которую вы хотите развернуть, уже зарегистрирована.
Совет
Модели связаны с развертыванием, а не с конечной точкой. Это означает, что одна конечная точка может обслуживать разные модели (или версии модели) в той же конечной точке, если разные модели (или версии модели) развертываются в разных развертываниях.
Теперь пришло время создать скрипт оценки. Для пакетных развертываний требуется скрипт оценки, указывающий, как должна выполняться данная модель и как должны обрабатываться входные данные. Конечные точки пакетной службы поддерживают скрипты, созданные в Python. В этом случае вы развертываете модель, которая считывает файлы изображений, представляющие цифры и выводит соответствующую цифру. Скрипт оценки выглядит следующим образом:
Примечание.
Для моделей MLflow Машинное обучение Azure автоматически создает скрипт оценки, поэтому его не требуется. Если модель является моделью MLflow, можно пропустить этот шаг. Дополнительные сведения о работе конечных точек пакетной службы с моделями MLflow см. в статье об использовании моделей MLflow в пакетных развертываниях.
Предупреждение
Если вы развертываете модель автоматического машинного обучения (AutoML) в пакетной конечной точке, обратите внимание, что скрипт оценки, который AutoML предоставляет только для сетевых конечных точек и не предназначен для пакетного выполнения. Сведения о создании скрипта оценки для пакетного развертывания см. в статье "Создание скриптов оценки для пакетных развертываний".
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Создайте среду, в которой выполняется пакетное развертывание. Среда должна включать пакеты
azureml-coreиazureml-dataset-runtime[fuse], которые требуются конечными точками пакетной службы, а также любые зависимости, необходимые для выполнения кода. В этом случае зависимости были записаны вconda.yamlфайле:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Внимание
Пакеты
azureml-coreиazureml-dataset-runtime[fuse]необходимы для пакетных развертываний и должны быть включены в зависимости среды.Укажите среду следующим образом:
Перейдите на вкладку "Среды" в боковом меню.
Выберите Пользовательские среды>Создать.
Введите имя среды в данном случае
torch-batch-env.В качестве источника среды выберите "Использовать существующий образ Docker" с необязательным файлом conda.
Введите образу реестра контейнеров.
Нажмите кнопку "Далее ", чтобы перейти к разделу "Настройка".
Скопируйте содержимое файла deployment-torch/environment/conda.yaml из репозитория GitHub на портал.
Нажмите кнопку "Далее", пока не достигнете страницы "Рецензирование".
Выберите "Создать " и подождите, пока среда будет готова.
Предупреждение
Курируемые среды не поддерживаются в пакетных развертываниях. Необходимо указать собственную среду. Для упрощения процесса всегда можно использовать базовый образ курированной среды.
Создание определения развертывания
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoВ следующей таблице описываются ключевые свойства пакетного развертывания. Полная схема YAML для развертывания пакетной службы приведена в разделе Схема YAML для развертывания пакетной службы CLI (версия 2).
Ключ. Описание nameИмя развертывания. endpoint_nameИмя конечной точки для создания развертывания. modelМодель, используемая для пакетной оценки. В примере определяется встроенная модель с использованием path. Это определение позволяет автоматически отправлять и регистрировать файлы модели с автоматически созданным именем и версией. Дополнительные параметры см. в схеме модели. В сценариях для рабочей среды рекомендуется создавать модель отдельно и ссылаться на нее здесь. Чтобы сослаться на существующую модель, используйте синтаксисazureml:<model-name>:<model-version>.code_configuration.codeЛокальный каталог, содержащий весь исходный код Python для оценки модели. code_configuration.scoring_scriptФайл Python в каталоге code_configuration.code. В этом файле должны быть функцииinit()иrun(). Используйте функциюinit()для любой дорогостоящей или обычной подготовки (например, для загрузки модели в памяти).init()вызывается только один раз в начале процесса. Методrun(mini_batch)позволяет оценить каждую запись; значениеmini_batchпредставляет собой список путей к файлам. Функцияrun()должна возвращать объект DataFrame Pandas или массив. Каждый возвращаемый элемент обозначает один успешный запуск входного элемента вmini_batch. Дополнительные сведения о создании скрипта оценки см. в разделе "Общие сведения о скрипте оценки".environmentСреда для оценки модели. В примере определяется встроенная среда с использованием conda_fileиimage. Зависимостиconda_fileустанавливаются на вершинеimage. Среда автоматически регистрируется с автоматически созданным именем и версией. Дополнительные параметры см. в схеме среды. В сценариях для рабочей среды рекомендуется создавать среду отдельно и ссылаться на нее здесь. Чтобы сослаться на существующую среду, используйте синтаксисazureml:<environment-name>:<environment-version>.computeВычисление для выполнения оценки пакетной службы. В примере используется batch-clusterсозданный в начале и ссылается на него с помощью синтаксисаazureml:<compute-name>.resources.instance_countКоличество экземпляров, используемых для каждого задания оценки пакетной службы. settings.max_concurrency_per_instanceМаксимальное количество параллельных запусков scoring_scriptна экземпляр.settings.mini_batch_sizeЧисло файлов, которые scoring_scriptможет обрабатывать в одном вызовеrun().settings.output_actionПорядок организации выходных данных в выходном файле. append_rowобъединяет всеrun()возвращенные выходные результаты в один файл с именемoutput_file_name.summary_onlyне будет объединять выходные результаты и будет вычислятьerror_thresholdтолько.settings.output_file_nameИмя выходного файла пакетной оценки для append_rowoutput_action.settings.retry_settings.max_retriesМаксимальное количество попыток для неудачного. scoring_scriptrun()settings.retry_settings.timeoutВремя ожидания в секундах для scoring_scriptrun()оценки мини-пакета.settings.error_thresholdКоличество сбоев оценки входных файлов, которые следует игнорировать. Если количество ошибок для всего входного значения превышает это значение, задание пакетной оценки завершается. В примере используется -1, что означает, что любое количество ошибок разрешено без завершения задания пакетной оценки.settings.logging_levelДетализация журнала. Значения уровня детализации в порядке увеличения: WARNING, INFO и DEBUG. settings.environment_variablesСловарь пар "имя-значение" переменной среды, устанавливаемых для каждого задания пакетной оценки. Перейдите на вкладку "Конечные точки" в боковом меню.
Выберите вкладку "Создать конечные>точки пакетной службы".
Присвойте конечной точке имя, в данном случае
mnist-batch. Вы можете настроить остальные поля или оставить их пустыми.Нажмите кнопку "Далее ", чтобы перейти к разделу "Модель".
Выберите модель mnist-classifier-torch.
Нажмите кнопку "Далее ", чтобы перейти на страницу "Развертывание".
Присвойте развертыванию имя.
Для действия вывода убедитесь, что выбрано "Добавить строку".
Для имени выходного файла убедитесь, что выходной файл пакетной оценки является нужным. По умолчанию —
predictions.csv.Для размера мини-пакета настройте размер файлов, которые будут включены в каждый мини-пакет. Этот размер определяет объем данных, получаемых скриптом оценки для каждого пакета.
Для времени ожидания оценки (секунды) убедитесь, что вы предоставляете достаточно времени для развертывания для оценки определенного пакета файлов. При увеличении количества файлов обычно необходимо увеличить значение времени ожидания. Более дорогие модели (например, на основе глубокого обучения) могут требовать высоких значений в этом поле.
Для максимального параллелизма для каждого экземпляра настройте количество исполнителей, которые требуется использовать для каждого вычислительного экземпляра, который вы получаете в развертывании. Более высокое число здесь гарантирует более высокую степень параллелизации, но также увеличивает нагрузку на память на вычислительный экземпляр. Настройте это значение полностью с размером пакета Mini.
После завершения нажмите кнопку "Далее ", чтобы перейти на страницу "Код + среда".
В разделе "Выбор скрипта оценки для вывода" найдите и выберите файл скрипта оценки deployment-torch/code/batch_driver.py.
В разделе "Выбор среды" выберите среду, созданную ранее факел-batch-env.
Нажмите кнопку "Далее ", чтобы перейти на страницу "Вычисления".
Выберите вычислительный кластер, созданный на предыдущем шаге.
Предупреждение
Кластеры Azure Kubernetes поддерживаются в пакетных развертываниях, но только при создании с помощью интерфейса командной строки машинного обучения Azure или пакета SDK для Python.
Для числа экземпляров введите количество вычислительных экземпляров, которые требуется выполнить для развертывания. В этом случае используйте 2.
Выберите Далее.
Создание развертывания:
Выполните следующий код, чтобы создать пакетное развертывание в конечной точке пакетной службы и задать его как развертывание по умолчанию.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultСовет
Параметр
--set-defaultзадает вновь созданное развертывание в качестве развертывания конечной точки по умолчанию. Это удобный способ создания нового развертывания конечной точки по умолчанию, особенно для первого создания развертывания. Для рабочих сценариев рекомендуется создать новое развертывание, не задав его в качестве значения по умолчанию. Убедитесь, что развертывание работает должным образом, а затем обновите развертывание по умолчанию позже. Дополнительные сведения о реализации этого процесса см. в разделе "Развертывание новой модели ".Проверьте сведения о конечной точке пакетной службы и развертывании.
Перейдите на вкладку Конечные точки пакета.
Выберите конечную точку пакетной службы, которую вы хотите просмотреть.
На странице сведений конечной точки отображаются сведения о конечной точке вместе со всеми развертываниями, доступными в конечной точке.
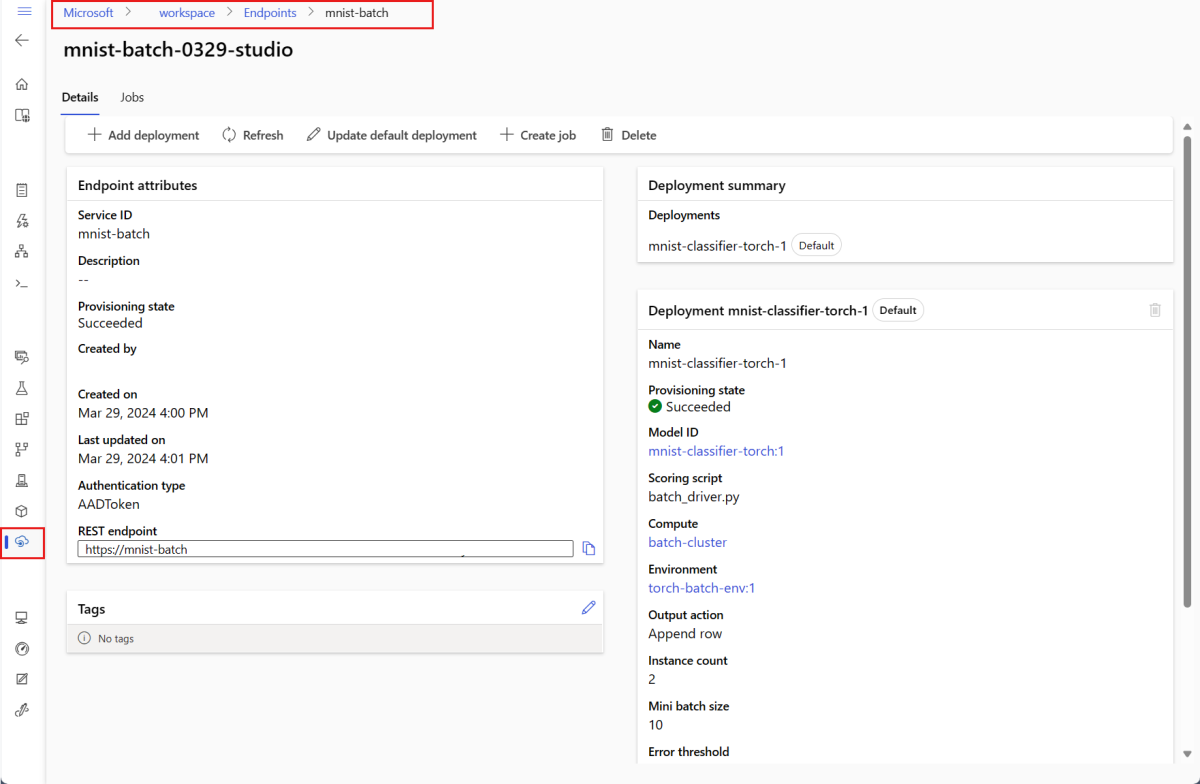

Запуск конечных точек пакетной службы и результатов доступа
Общие сведения о потоке данных
Прежде чем запускать пакетную конечную точку, поймите, как данные передаются через систему:
Входные данные: данные для обработки (оценка). Сюда входит следующее:
- Файлы, хранящиеся в службе хранилища Azure (хранилище BLOB-объектов, озеро данных)
- Папки с несколькими файлами
- Зарегистрированные наборы данных в Машинном обучении Azure
Обработка: развернутая модель обрабатывает входные данные в пакетах (мини-пакетах) и создает прогнозы.
Выходные данные: результаты модели, хранящиеся в качестве файлов в службе хранилища Azure. Выходные данные по умолчанию сохраняются в резервное хранилище BLOB рабочей области, но можно указать другое расположение.
Вызвать пакетную конечную точку
При вызове пакетной конечной точки запускается задание пакетной оценки. Задание name возвращается в ответе вызова и отслеживает прогресс пакетного расчета. Укажите путь входных данных, чтобы конечные точки могли найти данные для оценки. В следующем примере показано, как запустить новое задание по образцу данных набора данных MNIST, хранящегося в учетной записи служба хранилища Azure.
Вы можете запускать и вызывать пакетную конечную точку с помощью Azure CLI, Машинное обучение Azure sdk или конечных точек REST. Дополнительные сведения об этих параметрах см. в разделе Создание заданий и входных данных для пакетных конечных точек.
Примечание.
Как работает параллелизация?
Пакетные развертывания распределяют работу на уровне файла. Например, папка с 100 файлами и мини-пакетами из 10 файлов создает 10 пакетов из 10 файлов. Это происходит независимо от размера файла. Если файлы слишком большие для обработки в мини-пакетах, разделите их на небольшие файлы, чтобы увеличить параллелизм или уменьшить количество файлов на мини-пакет. В настоящее время пакетные развертывания не учитывают перекос в распределении размеров файлов.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $SAMPLE_INPUT_URI --input-type uri_folder --query name -o tsv)



Конечные точки пакетной службы поддерживают чтение файлов или папок, расположенных в разных расположениях. Дополнительные сведения о поддерживаемых типах и их указании см. в статье "Доступ к данным из заданий пакетных конечных точек".
Мониторинг хода выполнения пакетного задания
Задания пакетной оценки занимают время для обработки всех входных данных.
Следующий код проверяет состояние задания и выводит ссылку на Студия машинного обучения Azure для получения дополнительных сведений.
az ml job show -n $JOB_NAME --web

Проверка результатов пакетной оценки
Выходные данные задания хранятся в облачном хранилище либо в хранилище BLOB-объектов рабочей области по умолчанию, либо в указанном хранилище. Сведения об изменении значений по умолчанию см. в разделе "Настройка расположения выходных данных". Следующие шаги позволяют просматривать результаты оценки в обозревателе служба хранилища Azure при завершении задания:
Выполните следующий код, чтобы открыть задание оценки пакетной службы в Студия машинного обучения Azure. Ссылка на студию содержится в ответе
invokeв виде значенияinteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webНа графике задания выберите шаг
batchscoring.Перейдите на вкладку Выходные данные + журналы и выберите Показать выходные данные.
Из выходных данных выберите значок, чтобы открыть Обозреватель службы хранилища.
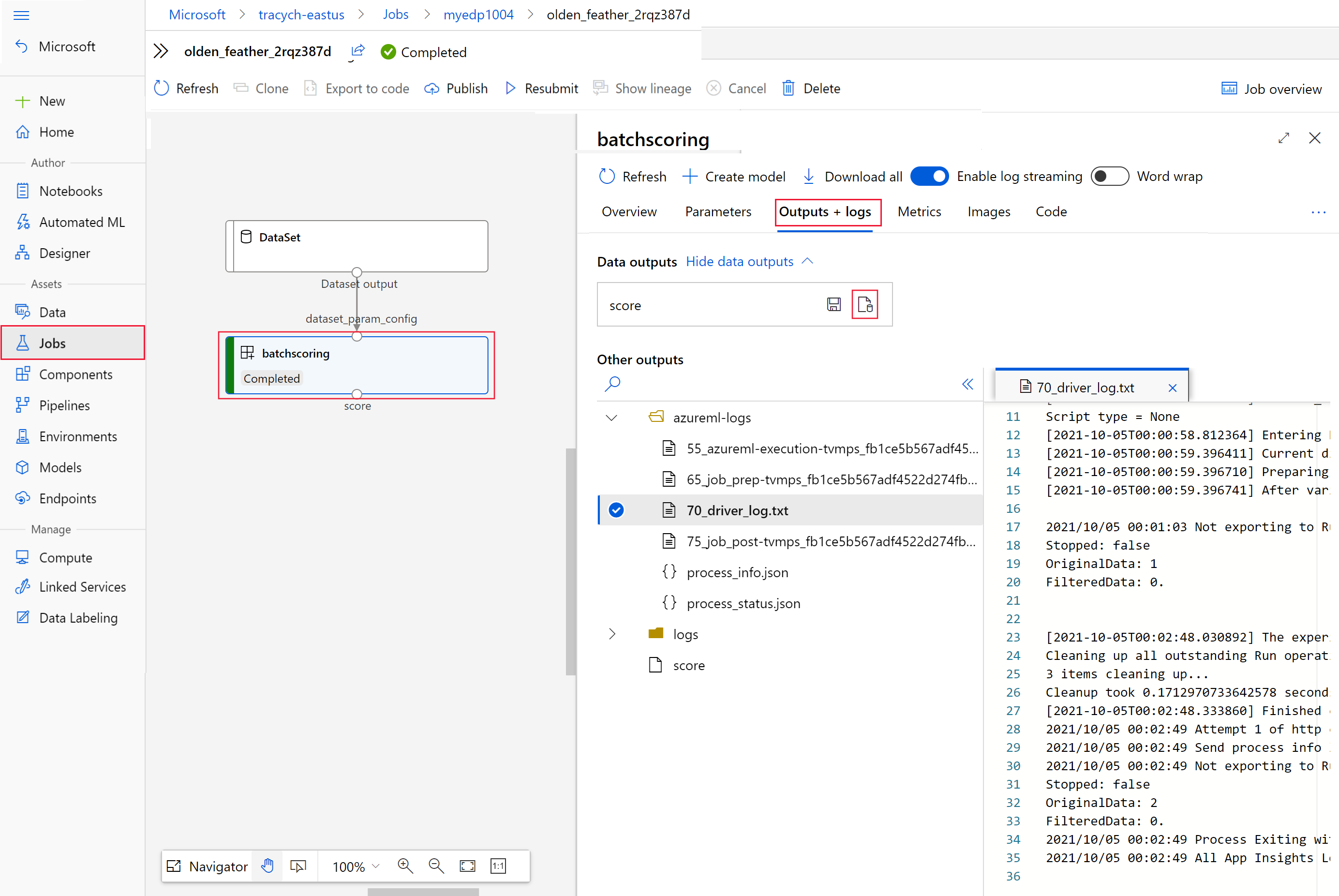
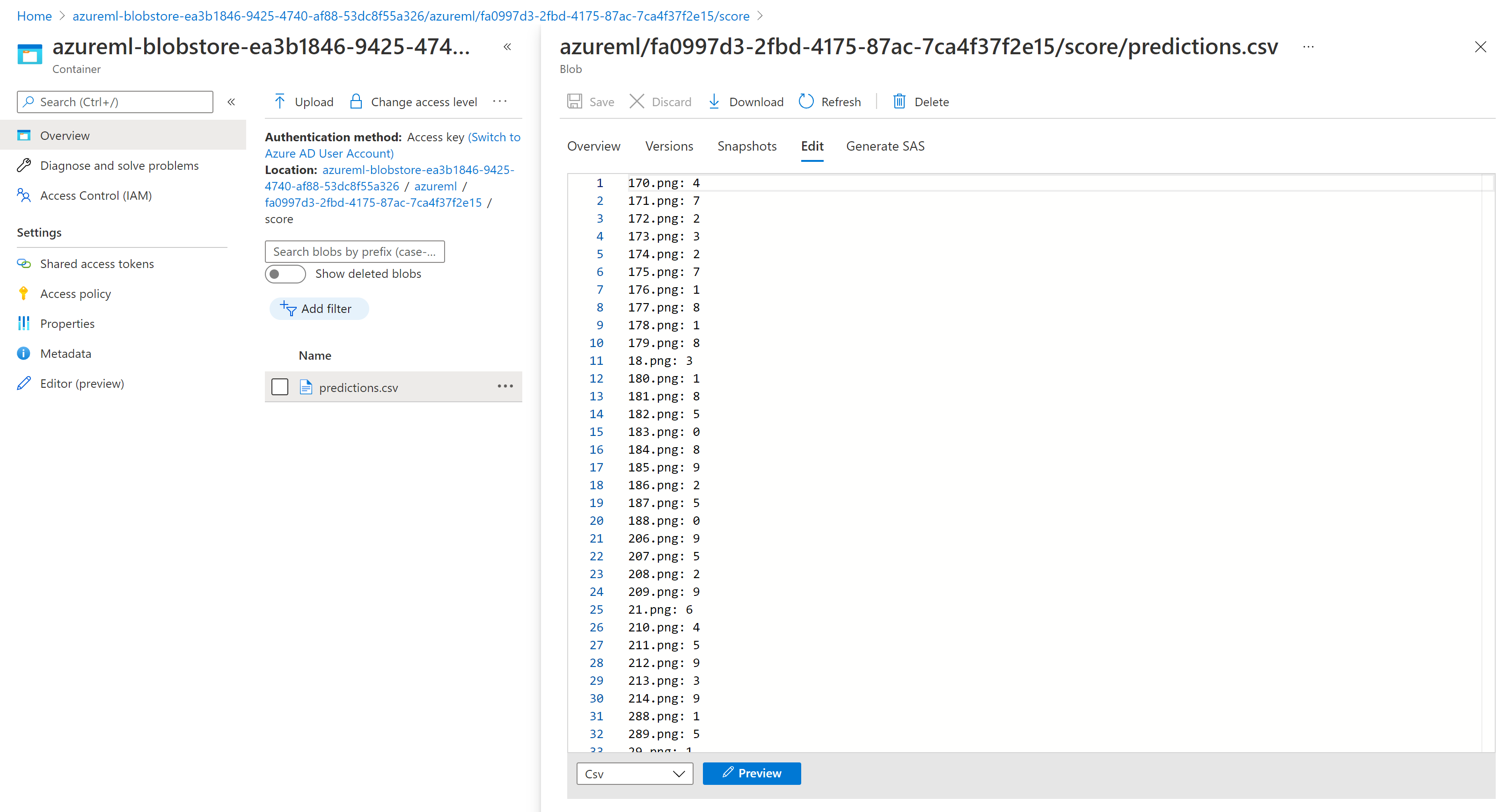
Результаты оценки в обозревателе службы хранилища похожи на следующий образец страницы:


Настройка расположения вывода
По умолчанию результаты пакетной оценки хранятся в стандартном объектном хранилище рабочей области в папке с именем задания (автоматически сгенерированный системой GUID). Настройте место сохранения выходных данных при вызове пакетной конечной точки.
Используйте output-path для настройки любой папки в зарегистрированном хранилище данных Машинного обучения Azure. Синтаксис для --output-path такой же, как --input при указании папки, т. е. azureml://datastores/<datastore-name>/paths/<path-on-datastore>/. С помощью --set output_file_name=<your-file-name> укажите новое имя выходного файла.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $SAMPLE_INPUT_URI --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Предупреждение
Используйте новое (уникальное) расположение выходных данных. Если выходной файл существует, задание пакетной оценки завершается сбоем.
Внимание
В отличие от входных данных, выходные данные могут храниться только в Машинное обучение Azure хранилищах данных, которые выполняются в учетных записях хранения BLOB-объектов.
Перезапись конфигурации развертывания для каждого задания
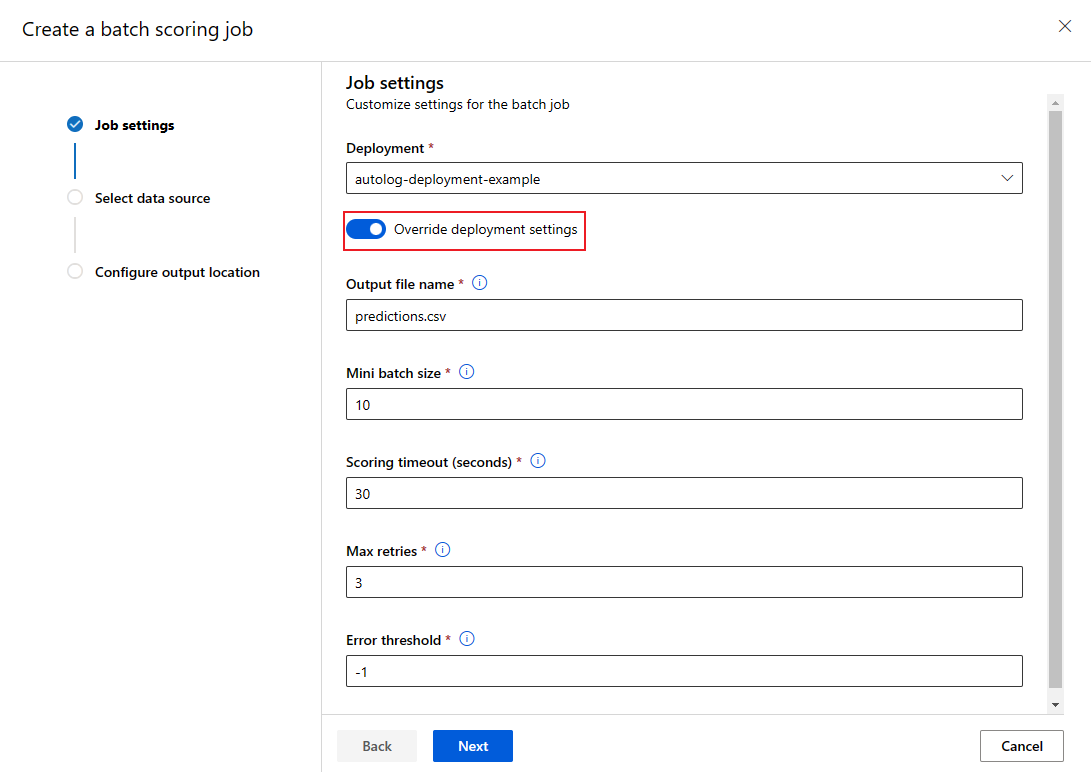
При вызове пакетной конечной точки можно перезаписать некоторые параметры, чтобы лучше использовать вычислительные ресурсы и повысить производительность. Эта функция полезна, если вам нужны разные параметры для разных заданий без постоянного изменения развертывания.
Какие параметры можно переопределить?
Вы можете настроить следующие параметры на основе каждого задания:
| Настройки | Когда следует использовать | Пример сценария |
|---|---|---|
| Число экземпляров | При наличии различных объемов данных | Используйте больше экземпляров для больших наборов данных (10 экземпляров для 1 миллиона файлов и 2 экземпляров для 100 000 файлов). |
| Размер мини-выборки | Когда необходимо сбалансировать пропускную способность и использование памяти | Используйте небольшие пакеты (10–50 файлов) для больших изображений и больших пакетов (100–500 файлов) для небольших текстовых файлов. |
| Максимальное количество повторных попыток | Если качество данных изменяется | Более высокие повторные попытки (5–10) для шумных данных; более низкие повторные попытки (1–3) для чистых данных |
| Тайм-аут | Если время обработки зависит от типа данных | Длительное время ожидания (300s) для сложных моделей; меньше времени ожидания (30-х) для простых моделей |
| Пороговое значение ошибки | Если вам нужны разные уровни отказоустойчивости | Строгое пороговое значение (-1) для критических заданий; минимальное пороговое значение (10%) для экспериментальных заданий |
Как переопределить параметры
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Добавление развертываний в конечную точку
После создания пакетной конечной точки с развертыванием можно продолжить уточнение модели и добавить новые развертывания. Конечные точки пакетной службы будут продолжать обслуживать развертывание по умолчанию при разработке и развертывании новых моделей в той же конечной точке. Развертывания не влияют друг на друга.
В этом примере вы добавите второе развертывание, которое использует модель, созданную с помощью Keras и TensorFlow , для решения той же проблемы MNIST.
Добавление второго развертывания
Создайте среду для пакетного развертывания. Включите все зависимости, необходимые для выполнения кода. Добавьте библиотеку
azureml-core, так как она необходима для пакетных развертываний. Следующее определение среды включает необходимые библиотеки для запуска модели с TensorFlow.Скопируйте содержимое файла deployment-keras/environment/conda.yaml из репозитория GitHub на портал.
Нажмите кнопку "Далее", пока не перейдите на страницу "Рецензирование".
Выберите "Создать " и подождите, пока среда будет готова к использованию.
Используемый файл conda выглядит следующим образом:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Создайте скрипт оценки для модели:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Создание определения развертывания
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvНажмите кнопку "Далее ", чтобы перейти на страницу "Код + среда".
Чтобы выбрать скрипт оценки для вывода, перейдите к выбору файла скрипта оценки deployment-keras/code/batch_driver.py.
Для выбора среды выберите среду, созданную на предыдущем шаге.
Выберите Далее.
На странице вычислений выберите вычислительный кластер, созданный на предыдущем шаге.
Для числа экземпляров введите количество вычислительных экземпляров, которые требуется выполнить для развертывания. В этом случае используйте 2.
Выберите Далее.
Создание развертывания:
Выполните следующий код, чтобы создать пакетное развертывание в конечной точке пакетной службы и задать его как развертывание по умолчанию.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMEСовет
В
--set-defaultэтом случае параметр отсутствует. Для рабочих сценариев рекомендуется создать новое развертывание, не задав его в качестве значения по умолчанию. Затем проверьте его и обновите развертывание по умолчанию позже.
Тестирование развертывания пакета, не используемое по умолчанию
Чтобы протестировать новое развертывание, отличное от по умолчанию, необходимо знать имя развертывания, которое требуется запустить.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input $SAMPLE_INPUT_URI --input-type uri_folder --query name -o tsv)
Уведомление --deployment-name используется для указания развертывания для выполнения. Этот параметр позволяет выполнять invoke развертывание, отличное от по умолчанию, без обновления развертывания пакетной конечной точки по умолчанию.
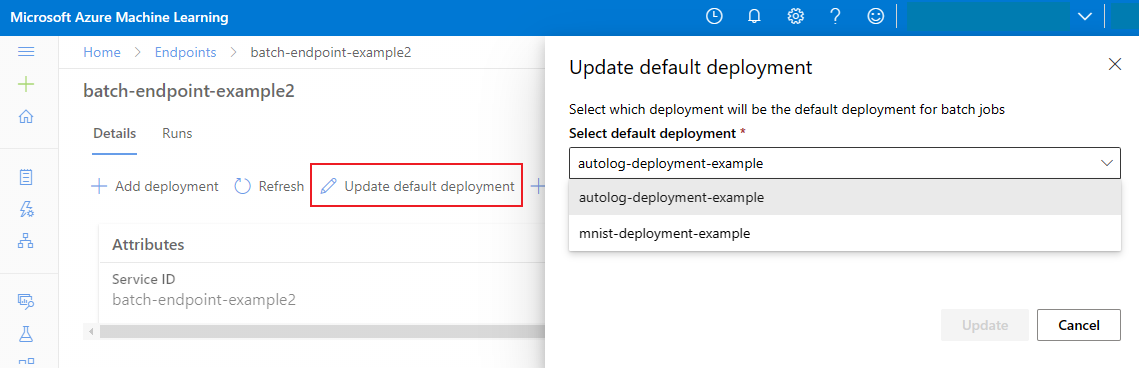
Обновление развертывания пакетной службы по умолчанию
Хотя вы можете вызвать определенное развертывание внутри конечной точки, обычно требуется вызвать саму конечную точку и разрешить конечной точке решить, какое развертывание следует использовать — развертывание по умолчанию. Вы можете изменить развертывание по умолчанию (и, следовательно, изменить модель, обслуживающую развертывание), не изменив контракт с пользователем, вызывающим конечную точку. Используйте следующий код для обновления развертывания по умолчанию:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
Удаление конечной точки пакетной службы и развертывания
Если вам не нужно старое пакетное развертывание, удалите его, выполнив следующий код. Флаг --yes подтверждает удаление.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Выполните следующий код, чтобы удалить конечную точку пакетной обработки и связанные с ней развертывания. Задания пакетной оценки не удаляются.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes