Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
В этой статье содержатся сведения об использовании пакета SDK машинного обучения Azure версии 1. Пакет SDK версии 1 устарел с 31 марта 2025 г. Поддержка будет завершена 30 июня 2026 г. Вы можете установить и использовать пакет SDK версии 1 до этой даты.
Рекомендуется перейти на пакет SDK версии 2 до 30 июня 2026 г. Дополнительные сведения о пакете SDK версии 2 см. в статье "Что такое ИНТЕРФЕЙС командной строки Машинного обучения Azure" и пакет SDK для Python версии 2 исправочник по пакету SDK версии 2.
Если вы интересуетесь, какой алгоритм машинного обучения следует использовать, ответ зависит в первую очередь от двух аспектов сценария обработки и анализа данных:
Что вы хотите сделать с данными? В частности, какой бизнес-вопрос вы хотите ответить, изучая прошлые данные?
Каковы требования к сценарию обработки и анализа данных? Каковы функции, точность, время обучения, линейность и параметры, поддерживаемые решением?
Примечание.
Конструктор Машинное обучение Azure поддерживает два типа компонентов: классические предварительно созданные компоненты (версии 1) и пользовательские компоненты (версия 2). Эти два типа компонентов несовместимы.
Классические предварительно созданные компоненты предназначены в основном для обработки данных и традиционных задач машинного обучения, таких как регрессия и классификация. Этот тип компонента по-прежнему поддерживается, но новые компоненты добавляться не будут.
Пользовательские компоненты позволяют упаковывать собственный код в качестве компонента. Они поддерживают совместное использование компонентов между рабочими областями и простой разработки в интерфейсах Studio, CLI версии 2 и ПАКЕТА SDK версии 2.
Для новых проектов настоятельно рекомендуется использовать пользовательские компоненты, совместимые с AzureML версии 2 и сохраняющие новые обновления.
Эта статья относится к классическим предварительно созданным компонентам и несовместима с CLI версии 2 и пакетом SDK версии 2.
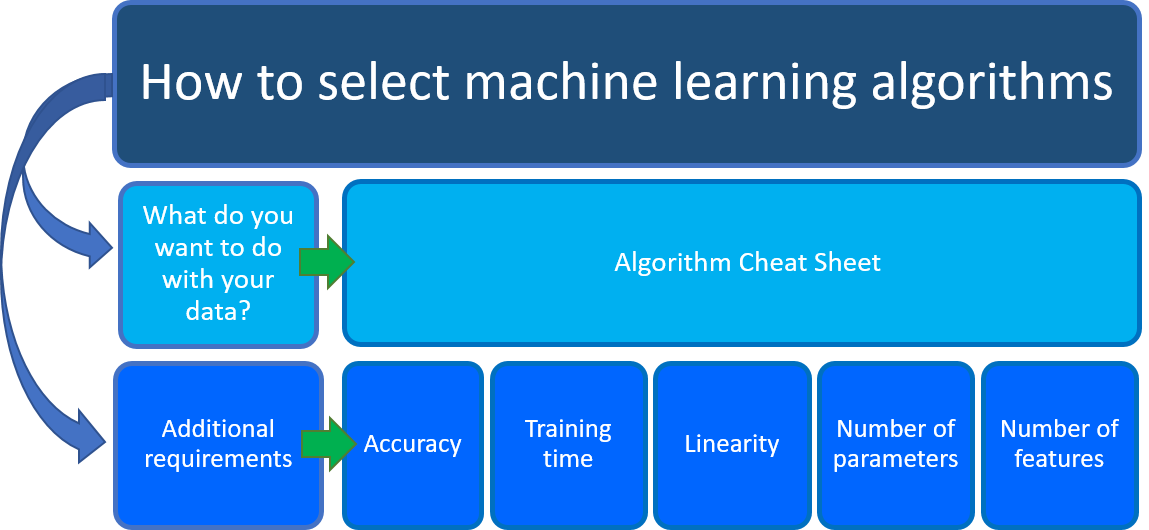
Памятка по алгоритмам Машинного обучения Azure
Памятка по алгоритму Машинное обучение Azure поможет вам в первую очередь: что вы хотите сделать с данными? На памятках найдите задачу, которую вы хотите выполнить, а затем найдите алгоритм конструктора Машинное обучение Azure для решения прогнозной аналитики.
Примечание.
Вы можете скачать памятку по алгоритму Машинное обучение.
Конструктор предоставляет комплексный портфель алгоритмов, таких как лес многоклассовых решений, системы рекомендаций, регрессия нейронной сети, многоклассовая нейронная сеть и кластеризация K-Средних. Каждый алгоритм предназначен для решения определенного типа проблем, связанных с машинным обучением. Ознакомьтесь со ссылкой на алгоритм и компонент для полного списка вместе с документацией о том, как работает каждый алгоритм и как настроить параметры для оптимизации алгоритма.
Наряду с этим руководством при выборе алгоритма машинного обучения следует учитывать другие требования. Ниже приведены дополнительные факторы, которые следует учитывать, такие как точность, время обучения, линейность, количество параметров и функций.
Сравнение алгоритмов машинного обучения
Некоторые алгоритмы делают определенные предположения о структуре данных или требуемых результатах. Если вы сможете найти тот алгоритм, который соответствует вашим потребностям, с ним вы сможете получить более точные результаты, более точные прогнозы и сократить время обучения.
В следующей таблице перечислены некоторые из наиболее важных характеристик алгоритмов из семейств классификации, регрессии и кластеризации.
| Алгоритм | Точность | Время обучения | Линейность | Параметры | Примечания |
|---|---|---|---|---|---|
| Семейство классификации | |||||
| Двухклассовая логистическая регрессия | Специалист | Быстро | Да | 4 | |
| Двухклассовый лес принятия решений | Отлично | Умеренно | нет | 5 | Показывает меньшее время оценки. Мы рекомендуем не работать с one-vs-All Multiclass, из-за более медленной оценки времени, вызванного блокировкой потока в накапливающихся прогнозированиях дерева |
| Двухклассовое увеличивающееся дерево принятия решений | Отлично | Умеренно | нет | 6 | Большой объем памяти |
| Двухклассовая нейронная сеть | Специалист | Умеренно | нет | 8 | |
| Двухклассовое усредненное восприятие | Специалист | Умеренно | Да | 4 | |
| Двухклассовый метод опорных векторов | Специалист | Быстро | Да | 5 | Подходит для больших наборов функций |
| Многоклассовая логистическая регрессия | Специалист | Быстро | Да | 4 | |
| Многоклассовый лес принятия решений | Отлично | Умеренно | нет | 5 | Показывает меньшее время оценки |
| Мультиклассовое увеличивающееся дерево принятия решений | Отлично | Умеренно | нет | 6 | Имеет тенденцию к повышению точности с небольшим риском меньшего объема |
| Многоклассовая нейронная сеть | Специалист | Умеренно | нет | 8 | |
| Многоклассовый классификатор "один — все" | - | - | - | - | Просмотрите свойства выбранного двухклассового метода |
| Семейство регрессии | |||||
| Линейная регрессия | Специалист | Быстро | Да | 4 | |
| Регрессия леса принятия решений | Отлично | Умеренно | нет | 5 | |
| Регрессия увеличивающегося дерева принятия решений | Отлично | Умеренно | нет | 6 | Большой объем памяти |
| Регрессия нейронной сети | Специалист | Умеренно | нет | 8 | |
| Семейство кластеризации | |||||
| Кластеризация методом k-средних | Отлично | Умеренно | Да | 8 | Алгоритм кластеризации |
Требования к сценарию обработки и анализа данных
После того как вы узнаете, что нужно сделать с данными, необходимо определить другие требования к сценарию обработки и анализа данных.
Сделайте выбор и, возможно, найдите приемлемое решение для удовлетворения следующих требований.
- Правильность
- Время обучения
- Линейность
- Количество параметров
- Количество функций
Правильность
Точность машинного обучения позволяет измерить эффективность модели как пропорцию истинных результатов к общему числу вариантов. В конструкторе компонент "Оценка модели" вычисляет набор метрик оценки отраслевых стандартов. Вы можете использовать этот компонент для измерения точности обученной модели.
Получение наиболее точного ответа возможно не всегда. Иногда достаточно приближенного ответа в зависимости от того, для чего он используется. Если это так, возможно, вы сможете резко сократить время обработки, придерживаясь более приблизительных методов. Кроме того, приблизительные методы, как правило, позволяют избежать лжевзаимосвязи.
Существует три способа использования компонента "Оценка модели":
- Создайте оценки по данным обучения, чтобы оценить модель.
- Создайте оценки в модели, но сравните эти оценки с оценками в зарезервированном наборе тестирования.
- Сравните оценки для двух разных моделей, но связанных с ними, используя один набор данных.
Полный список метрик и подходов, которые можно использовать для оценки точности моделей машинного обучения, см. в компоненте "Оценка модели".
Время обучения
Контролируемое обучение обозначает использование исторических данных для построения модели машинного обучения, которая позволяет снизить ошибки до минимума. Количество минут или часов, необходимых для обучения модели, сильно отличается для различных алгоритмов. Время обучения часто тесно связано с точностью — одно обычно сопутствует другому.
Кроме того, некоторые алгоритмы более чувствительны к количеству точек данных, чем другие. Можно выбрать конкретный алгоритм, так как имеется ограничение по времени, особенно если набор данных большой.
В конструкторе создание и использование модели машинного обучения обычно представляет собой трехэтапный процесс:
Необходимо настроить модель, выбрав определенный тип алгоритма и определив ее параметры или гиперпараметры.
Укажите набор данных, помеченный и совместимый с алгоритмом. Подключите данные и модель к компоненту Train Model.
После завершения обучения используйте обученную модель с одним из компонентов оценки, чтобы создать прогнозы на основе новых данных.
Линейность
Линейность в статистике и машинном обучении означает, что в наборе данных есть линейная связь между переменной и константой. Например, алгоритмы линейной классификации предполагают, что классы могут быть разделены прямой линией (или ее аналогом для большего числа измерений).
Линейность используется во многих алгоритмах машинного обучения. В конструкторе "Машинное обучение" Azure они включают:
- Многоклассовая логистическая регрессия
- Двухклассовая логистическая регрессия
- Поддержка векторных компьютеров
Алгоритмы линейной регрессии предполагают, что тренды данных следуют прямой линии. Это предположение полезно для решения некоторых проблем, но для других снижает точность. Несмотря на недостатки, линейные алгоритмы распространены в качестве первой стратегии. Обычно они алгоритмически просты и быстро осваиваются.
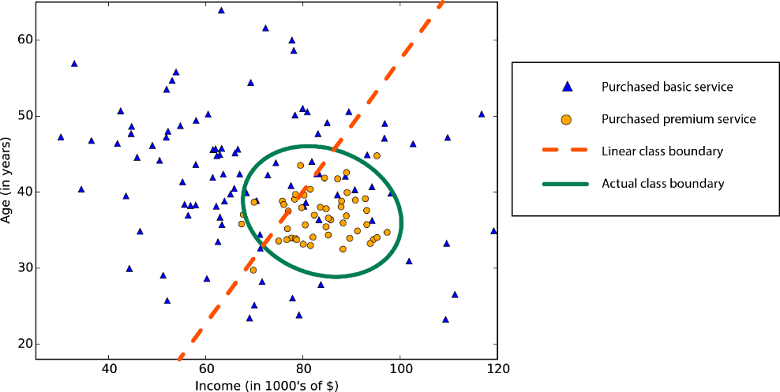
Граница нелинейного класса — использование алгоритма линейной классификации приведет к снижению точности.
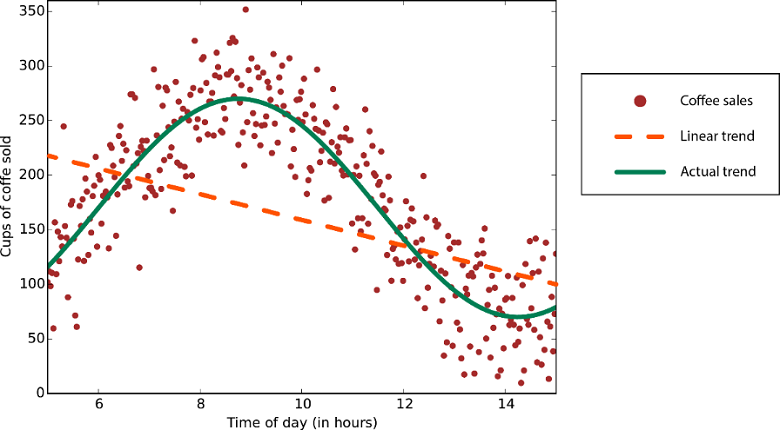
Данные с нелинейным трендом — использование метода линейной регрессии приведет к появлению гораздо большего количества ошибок, чем необходимо.
Количество параметров
Параметры — это ручки, которые получает специалист по обработке и анализу данных при настройке алгоритма. Это числа, влияющие на поведение алгоритма, такие как погрешность или количество итерации, или параметры между вариантами поведения алгоритма. Время обучения и точность алгоритма иногда могут быть чувствительными к точности задания параметров. Как правило, алгоритмы с большим числом параметров требуют большого количества проб и ошибок, чтобы определить удачное сочетание параметров.
Кроме того, в конструкторе есть компонент Hyperparameters для модели настройки. Цель этого компонента — определить оптимальные гиперпараметры для модели машинного обучения. Модуль создает и тестирует несколько компонентов, используя различные сочетания параметров. Он сравнивает метрики по всем моделям, чтобы получить сочетания параметров.
Хотя это отличный способ убедиться, что вы охватывали пространство параметров, время, необходимое для обучения модели, увеличивается экспоненциально с числом параметров. Плюсом является то, что наличие большого количества параметров обычно означает, что алгоритм имеет большую гибкость. Часто это позволяет достичь очень хорошей точности при условии, что вы можете найти правильное сочетание настроек параметров.
Количество функций
В машинном обучении функция является квалифициируемой переменной явления, который вы пытаетесь проанализировать. Для некоторых типов данных количество функций может быть очень большим по сравнению с количеством точек данных. Это часто происходит с генетическими или текстовыми данными.
Большое количество функций для некоторых алгоритмов обучения может привести к тому, что они увязнут и время обучения станет недопустимо большим. Векторные машины поддержки хорошо подходят для сценариев с большим количеством функций. По этой причине они использовались во многих областях применения: от извлечения информации до классификации текста и изображения. Методы опорных векторов можно использовать как для задач классификации, так и регрессии.
Как правило, выбор признаков обозначает процесс применения статистических тестов к входным данным с учетом конкретных выходных данных. Цель состоит в том, чтобы определить столбцы, которые лучше других позволяют прогнозировать эти выходные данные. Компонент выбора компонентов на основе фильтров в конструкторе предоставляет несколько алгоритмов выбора компонентов. Данный компонент включает такие методы корреляции, как корреляция Пирсона и значения хи-квадрат.
Кроме того, можно воспользоваться компонентом "Важность признака перестановки", чтобы вычислить набор оценок важности признаков для вашего набора данных. Затем вы можете использовать эти оценки, чтобы определить лучшие функции для использования в модели.