Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Внимание
В этой статье содержатся сведения об использовании пакета SDK Машинное обучение Azure версии 1. Пакет SDK версии 1 устарел с 31 марта 2025 г. Поддержка будет завершена 30 июня 2026 г. Вы можете установить и использовать пакет SDK версии 1 до этой даты. Существующие рабочие процессы, использующие пакет SDK версии 1, будут продолжать работать после даты окончания поддержки. Однако они могут быть подвержены рискам безопасности или критическим изменениям в случае изменений архитектуры в продукте.
Рекомендуется перейти на пакет SDK версии 2 до 30 июня 2026 г. Дополнительные сведения о SDK версии 2 см. в разделе Что такое Машинное обучение Azure CLI и Python SDK v2? и справочнике по SDK версии 2.
Внимание
В этой статье объясняется, как использовать интерфейс командной строки Машинное обучение Azure (версии 1) и пакет SDK Машинное обучение Azure для Python (версии 1) для развертывания модели. Рекомендуемый подход для версии 2 см. в статье Развертывание и оценка модели машинного обучения с помощью сетевой конечной точки.
Узнайте, как использовать Машинное обучение Azure для развертывания модели в качестве веб-службы на Azure Kubernetes Service (AKS). AKS хорошо подходит для развертываний в крупномасштабных производственных средах. Используйте AKS, если вам нужна одна или несколько следующих возможностей:
- быстрое время отклика;
- автомасштабирование развернутого сервиса;
- Логирование
- Сбор данных модели
- Аутентификация
- завершение сеанса TLS;
- такие параметры аппаратного ускорения, как GPU и программируемые логические матрицы (ППВМ).
При развертывании в AKS используется кластер AKS, подключенный к рабочей области. Сведения о подключении кластера AKS к рабочей области см. в статье Создание и присоединение кластера Служба Azure Kubernetes.
Внимание
Рекомендуется выполнить отладку локально перед развертыванием в веб-службе. Дополнительные сведения см. в разделе "Устранение неполадок с развертыванием локальной модели".
Примечание.
Машинное обучение Azure конечные точки (версия 2) обеспечивают улучшенный и упрощенный процесс развертывания. Эндпоинты поддерживают сценарии как для инференции в режиме реального времени, так и для пакетной инференции. Конечные точки служат единым интерфейсом для вызова развертывания моделей и управления ими в вычислительных ресурсах разных типов. См. раздел Что такое конечные точки Машинное обучение Azure?.
Предварительные условия
Рабочая область Машинное обучение Azure. Дополнительные сведения см. в разделе Создание рабочей области Машинное обучение Azure.
Модель машинного обучения, зарегистрированная в вашей рабочей области. Если у вас нет зарегистрированной модели, ознакомьтесь с разделом Развертывание моделей машинного обучения в Azure.
Расширение Azure CLI (версия 1) для службы Машинное обучение, пакет SDK Машинное обучение Azure Python или Машинное обучение Azure Visual Studio Code extension.
Внимание
В некоторых командах Azure CLI в этой статье используется расширение
azure-cli-mlили v1 для Машинное обучение Azure. Поддержка CLI версии 1 закончилась 30 сентября 2025 г. Корпорация Майкрософт больше не будет предоставлять техническую поддержку или обновления для этой службы. Существующие рабочие процессы, использующие CLI версии 1, будут продолжать работать после даты окончания поддержки. Однако они могут быть подвержены рискам безопасности или критическим изменениям в случае изменений архитектуры в продукте.Рекомендуется как можно скорее перейти к расширению
mlили версии 2. Дополнительные сведения о расширении версии 2 см. в разделе Машинное обучение Azure расширение CLI и пакет SDK Python версии 2.Фрагменты кода Python в этой статье предполагают, что заданы следующие переменные:
-
ws— Установлено в вашей рабочей области; -
model— устанавливается для вашей зарегистрированной модели; -
inference_config— установить конфигурацию вывода для модели.
Дополнительные сведения об установке этих переменных см. в разделе Как и где развертываются модели.
-
Фрагменты интерфейса командной строки в этой статье предполагают, что вы уже создали документ inferenceconfig.json . Дополнительные сведения о создании этого документа см. в статье Развертывание моделей машинного обучения в Azure.
Кластер AKS, подключенный к рабочей области. Дополнительные сведения см. в разделе Создание и подключение кластера Служба Azure Kubernetes.
- Если вы хотите развернуть модели на узлах GPU или узлах FPGA (или любом конкретном продукте), необходимо создать кластер с определенным продуктом. Создание пула вторичных узлов в существующем кластере и развертывание моделей в пуле вторичных узлов не поддерживаются.
Общие сведения о процессах развертывания
Слово deployment используется как в Kubernetes, так и в Машинное обучение Azure.
Развертывание имеет разные значения в этих двух контекстах. В Kubernetes развертывание является конкретной сущностью, определяемой посредством декларативного файла YAML. Развертывание Kubernetes имеет определенный жизненный цикл и конкретные связи с другими сущностями Kubernetes, такими как Pods и ReplicaSets. Вы можете узнать о Kubernetes из документации и видеороликов по ссылке Что такое Kubernetes?.
В Машинное обучение Azure развертывание используется в более общем смысле для предоставления доступа к ресурсам проекта и их очистки. Ниже приведены действия, которые Машинное обучение Azure рассматривает как часть развертывания:
- Архивирование файлов в папке проекта, за исключением тех, которые указаны в .amlignore или .gitignore.
- Масштабирование вычислительного кластера (относится к Kubernetes)
- Создание или скачивание dockerfile на вычислительный узел (относится к Kubernetes)
- Система вычисляет хэш:
- базовый образ
- пользовательских шагов Docker (см. раздел Развертывание модели с помощью пользовательского базового образа Docker);
- Определение conda YAML (см. Создание и использование программных сред в Машинное обучение Azure)
- Система использует этот хэш в качестве ключа в поиске рабочей области Реестр контейнеров Azure (ACR)
- Если объект не найден, осуществляется поиск совпадения в глобальном ACR.
- Если он не найден, система создает новый образ, кэшированный и отправленный в рабочую область ACR
- Система вычисляет хэш:
- Загрузка упакованного файла проекта во временное хранилище в вычислительном узле.
- Распаковка файла проекта.
- Вычислительный узел, выполняющий
python <entry script> <arguments>. - Сохранение журналов, файлов модели и других файлов, записанных в ./outputs в учетную запись хранения, связанную с рабочей областью
- Масштабирование вычислительных ресурсов, включая удаление временного хранилища (относится к Kubernetes)
маршрутизатор Машинное обучение Azure
Интерфейсный компонент (azureml-fe), который направляет входящие запросы вывода в развернутые службы, автоматически масштабируется по мере необходимости. Масштабирование azureml-fe зависит от назначения и размера кластера AKS (числа узлов). Назначение и узлы кластера настраиваются при создании или подключении кластера AKS. Существует одна служба azureml-fe на кластер, и она может работать на нескольких подах.
Внимание
- При использовании кластера, настроенного как
dev-test, самомасштабирование отключено. Даже для кластеров FastProd/DenseProd Self-Scaler включается только тогда, когда телеметрия показывает, что это необходимо. - Машинное обучение Azure не автоматически отправляет журналы или сохраняет журналы из каких-либо контейнеров, включая системные контейнеры. Для комплексной отладки рекомендуется включить Аналитику контейнеров для кластера AKS. Это позволяет сохранять журналы контейнеров, управлять ими вместе с командой Машинное обучение Azure при необходимости. Без этого Машинное обучение Azure не может гарантировать поддержку проблем, связанных с azureml-fe.
- Максимальная нагрузка запроса составляет 100 МБ.
Azureml-fe масштабируется как вертикально, чтобы использовать больше ядер, так и горизонтально, чтобы использовать больше подов. При принятии решения о масштабировании используется время, необходимое для маршрутизации входящих запросов на вывод результатов. Если это время превышает пороговое значение, происходит увеличение масштаба. Если время маршрутизации входящих запросов все еще превышает пороговое значение, происходит горизонтальное масштабирование.
При уменьшении масштаба используется потребление ресурсов ЦП. Если порог использования ЦП достигнут, фронтенд сначала масштабируется вниз. Если загрузка ЦП падает до порогового значения внутреннего масштабирования, выполняется операция внутреннего масштабирования. Масштабирование вверх и в стороны происходит только в том случае, если доступно достаточное количество ресурсов кластера.
При масштабировании или уменьшении масштаба модули pod azureml-fe перезагружаются, чтобы применить изменения ЦП или памяти. Перезапуски не влияют на процесс выполнения запросов на вывод.
Понимание требований к подключению для инференсного кластера AKS
При создании или подключении кластера AKS с помощью Машинное обучение Azure кластер AKS развертывается с использованием одной из следующих двух сетевых моделей:
- Сеть Kubenet: сетевые ресурсы обычно создаются и настраиваются в процессе развертывания кластера AKS.
- сеть Azure Container Networking Interface (CNI): кластер AKS подключен к существующему виртуальному сетевому ресурсу и конфигурациям.
Для сети Kubenet сеть создается и настроена правильно для службы Машинное обучение Azure. При использовании сетей CNI необходимо понимать требования к подключаемости, а также обеспечить разрешение DNS и исходящее сетевое подключение для инференсинга AKS. Например, можно использовать брандмауэр для блокировки сетевого трафика.
На следующей диаграмме показаны требования к подключению для инференса AKS. Черные стрелки представляют фактический обмен данными, а синие — доменные имена. Возможно, потребуется добавить записи для этих узлов в брандмауэр или на пользовательский DNS-сервер.
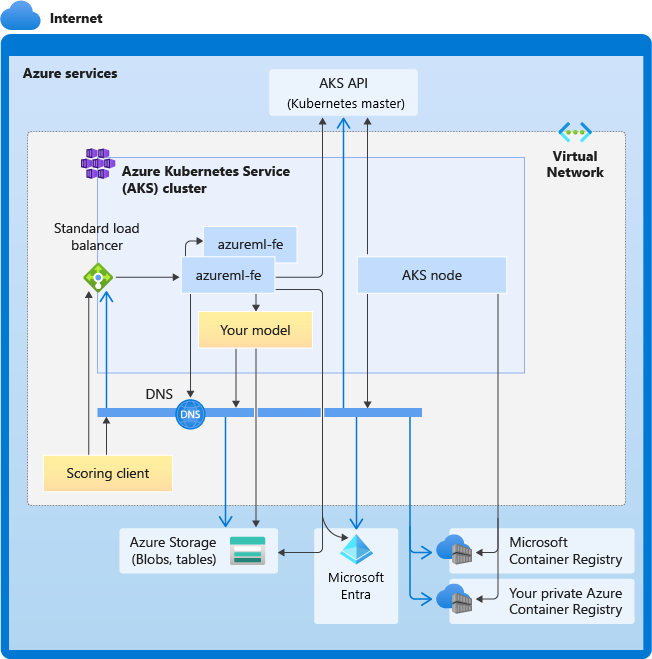
Общие требования к подключению AKS см. в разделе Ограничение сетевого трафика с помощью Брандмауэр Azure в AKS.
Сведения о доступе к службам Машинное обучение Azure за брандмауэром см. в разделе Настройка входящего и исходящего сетевого трафика.
Общие требования к разрешению DNS
Разрешение DNS в существующей виртуальной сети находится под вашим контролем. Пример: брандмауэр или пользовательский DNS-сервер. Должны быть доступны указанные ниже узлы.
| Имя узла | Используется кем |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Сервер API AKS |
mcr.microsoft.com |
Реестр контейнеров Майкрософт (MCR) |
<ACR name>.azurecr.io |
Ваш Реестр контейнеров Azure (ACR) |
<account>.table.core.windows.net |
учетная запись служба хранилища Azure (хранилище таблиц) |
<account>.blob.core.windows.net |
учетная запись служба хранилища Azure (хранилище BLOB-объектов) |
api.azureml.ms |
проверка подлинности Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Конечная точка Kusto для отправки данных телеметрии |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Доменное имя конечной точки, если оно было автоматически сгенерировано с помощью Машинное обучение Azure. Если вы использовали имя личного домена, эта запись не требуется. |
Требования к подключению в хронологическом порядке
В процессе создания или подключения AKS в кластер AKS развертывается маршрутизатор Машинное обучение Azure (azureml-fe). Чтобы развернуть маршрутизатор Машинное обучение Azure, узел AKS должен иметь возможность:
- разрешить DNS для сервера API AKS;
- Настройка DNS для MCR для загрузки образов Docker для маршрутизатора Машинное обучение Azure
- Загрузите образы из MCR, где требуется исходящее подключение.
Сразу после развертывания azureml-fe он пытается запуститься, и это требует:
- разрешить DNS для сервера API AKS;
- запросить сервер API AKS для обнаружения других своих экземпляров (это служба с несколькими pod);
- подключиться к другим экземплярам себя.
После запуска azureml-fe для его правильной работы требуются следующие подключения:
- Подключение к служба хранилища Azure для скачивания динамической конфигурации
- Разрешить DNS для сервера проверки подлинности Microsoft Entra api.azureml.ms и обмениваться данными с ним, когда развернутая служба использует проверку подлинности Microsoft Entra.
- Отправьте запрос к серверу API AKS для обнаружения развернутых моделей.
- Связь с развернутыми Pod модели.
Во время развертывания модели для успешного развертывания модели узел AKS должен иметь следующие возможности:
- разрешить DNS для ACR заказчика;
- загружать образы из ACR заказчика;
- Разрешите DNS для BLOB-хранилищ Azure, где хранится модель
- Загрузка моделей из хранилищ BLOB Azure
После развертывания модели и запуска службы azureml-fe автоматически обнаруживает ее с помощью API AKS и готова к перенаправлению запроса к ней. Он должен иметь возможность взаимодействовать с модельными POD.
Примечание.
Если развернутой модели требуется любое подключение (например, запрос внешней базы данных или другой службы REST или скачивание BLOB-объекта), необходимо включить разрешение DNS и исходящее взаимодействие для этих служб.
Развертывание в AKS
Чтобы развернуть модель в AKS, создайте конфигурацию развертывания, описывающую необходимые вычислительные ресурсы. Например, количество ядер и памяти. Вам также потребуется конфигурация вывода, описывающая среду, необходимую для размещения модели и веб-службы. Дополнительные сведения о создании конфигурации вывода см. в разделе Как и где развертываются модели.
Примечание.
Число развертываемых моделей должно быть не более 1000 на развертывание (для каждого контейнера).
- пакет SDK Python
- Azure CLI
- Visual Studio Code
ПРИМЕНИМО К: Машинное обучение Azure SDK версии 1 для Python
Машинное обучение Azure SDK версии 1 для Python
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and Azure Machine Learning components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Дополнительные сведения о классах, методах и параметрах, используемых в этом примере, см. в следующих справочных документах.
- Класс AksCompute
- Класс конфигурации AksWebservice.deployment
- Model.deploy
- Webservice.wait_for_deployment # ожидание развертывания
Автомасштабирование
ПРИМЕНИМО К:Машинное обучение Azure SDK версии 1 для Python
Компонент, который обрабатывает автомасштабирование для развертываний модели Машинное обучение Azure, — azureml-fe, который является маршрутизатором интеллектуального запроса. Так как все запросы вывода проходят через него, у него есть необходимые данные для автоматического масштабирования развернутых моделей.
Внимание
Не включите горизонтальное автомасштабирование pod Kubernetes (HPA) для развертываний моделей. Это приводит к тому, что два компонента автоматического масштабирования будут конкурировать друг с другом. Azureml-fe предназначен для автоматического масштабирования моделей, развернутых с помощью Машинное обучение Azure, где HPA придется угадать или приблизить использование модели из универсальной метрики, например использования центрального процессора или настраиваемой конфигурации метрик.
Azureml-fe не масштабирует количество узлов в кластере AKS, так как это может привести к непредвиденному росту затрат. Вместо этого он масштабирует количество реплик для модели в границах физического кластера. Если необходимо масштабировать количество узлов в кластере, вы можете масштабировать кластер вручную или настроить автомасштабирование кластера AKS.
Чтобы управлять автомасштабированием, можно настроить autoscale_target_utilization, autoscale_min_replicas и autoscale_max_replicas для веб-службы AKS. В следующем примере показано, как включить автомасштабирование.
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
Решения для увеличения или уменьшения масштаба основаны на использовании текущих реплик контейнеров. Количество занятых (обрабатывающих запросы) реплик, деленное на общее число текущих реплик, и является показателем текущего использования. Если это число превышает autoscale_target_utilization, то создаются дополнительные реплики. Если оно меньше, то число реплик уменьшается. По умолчанию целевой показатель использования составляет 70 %.
Решения по добавлению реплик принимаются решительно и быстро (около 1 секунды). Решения по удалению реплик более консервативны и принимаются около 1 минуты.
Вы можете рассчитать необходимые реплики, используя следующий код:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Дополнительные сведения о настройке autoscale_target_utilization, autoscale_max_replicas и autoscale_min_replicas см. в справочнике модуля AksWebservice.
Проверка подлинности веб-службы
При развертывании в Служба Azure Kubernetes key-based аутентификация включена по умолчанию. Вы также можете включить проверку подлинности на основе токенов. Аутентификация на основе токенов требует от клиентов использования учетной записи Microsoft Entra для запроса токена аутентификации, который используется для выполнения запросов к развернутой службе.
Чтобы отключить проверку подлинности, задайте параметр auth_enabled=False при создании конфигурации развертывания. В следующем примере пакет SDK используется для отключения проверки подлинности:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Для получения информации о проверке подлинности из клиентского приложения см. раздел Использование модели Машинное обучение Azure, развернутой в виде веб-службы.
Проверка подлинности на основе ключей
Если включена проверка подлинности на основе ключей, можно использовать метод get_keys для извлечения первичного и вторичного ключей проверки подлинности:
primary, secondary = service.get_keys()
print(primary)
Внимание
Если вам нужно повторно создать ключ, используйте service.regen_key.
Проверка подлинности на основе маркеров
Чтобы включить аутентификацию по токену, используйте параметр token_auth_enabled=True при создании или обновлении развертывания. В следующем примере включена проверка подлинности на основе токенов с использованием SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Если проверка подлинности маркера включена, можно использовать get_token метод для получения JWT и времени истечения срока действия этого маркера:
token, refresh_by = service.get_token()
print(token)
Внимание
Вам нужно запросить новый токен после истечения времени токена refresh_by.
Корпорация Майкрософт настоятельно рекомендует создать рабочую область Машинное обучение Azure в том же регионе, что и кластер AKS. Для аутентификации с помощью токена веб-служба обращается к региону, в котором была создана рабочая область Машинное обучение Azure. Если регион рабочей области недоступен, вы не можете получить маркер для веб-службы, даже если кластер находится в другом регионе, отличном от рабочей области. Это фактически приводит к недоступности проверки подлинности на основе токенов до тех пор, пока регион вашей рабочей области снова не станет доступен. Кроме того, чем больше расстояние между регионом кластера и регионом рабочей области, тем больше времени требуется для получения токена.
Чтобы получить маркер, необходимо использовать пакет SDK Машинное обучение Azure или команду az ml service get-access-token.
Сканер уязвимостей
Microsoft Defender для облака обеспечивает унифицированное управление безопасностью и расширенную защиту от угроз в гибридных облачных рабочих нагрузках. Вы должны разрешить Microsoft Defender для облака сканировать ресурсы и следовать его рекомендациям. Дополнительные сведения см. в разделе Безопасность контейнеров в Microsoft Defender для контейнеров.
Связанный контент
- Используйте роль-базированный контроль доступа Azure для авторизации Kubernetes
- Защитите среду развертывания Машинное обучение Azure с помощью виртуальных сетей
- Использование пользовательского контейнера для развертывания модели в сетевой конечной точке
- Устранение неполадок при развертывании удаленной модели
- Обновление развернутой веб-службы
- Использовать TLS для защиты веб-службы с помощью Машинное обучение Azure
- Использование модели Машинное обучение Azure, развернутой как веб-служба
- Мониторинг и сбор данных из конечных точек веб-службы Машинного обучения