Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Из этой статьи вы узнаете, как отслеживать и отлаживать задания Apache Spark, выполняемые в кластерах HDInsight. Отладка с помощью пользовательского интерфейса Apache Hadoop YARN, пользовательского интерфейса Spark и сервера журнала Spark. Вы запускаете задание Spark с помощью записной книжки, доступной в Spark-кластере, Машинное обучение: прогнозный анализ на данных проверки продуктов питания с помощью MLLib. Выполните следующие действия, чтобы отслеживать приложение, отправленное с помощью любого другого подхода, например spark-submit.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Предпосылки
Кластер Apache Spark в HDInsight. Для получения инструкций см. Создание кластеров Apache Spark в Azure HDInsight.
Вам следует запустить блокнот, машинное обучение: прогнозный анализ данных проверки продуктов питания с помощью MLLib. Инструкции по запуску этой записной книжки см. по ссылке.
Отслеживание приложения в пользовательском интерфейсе YARN
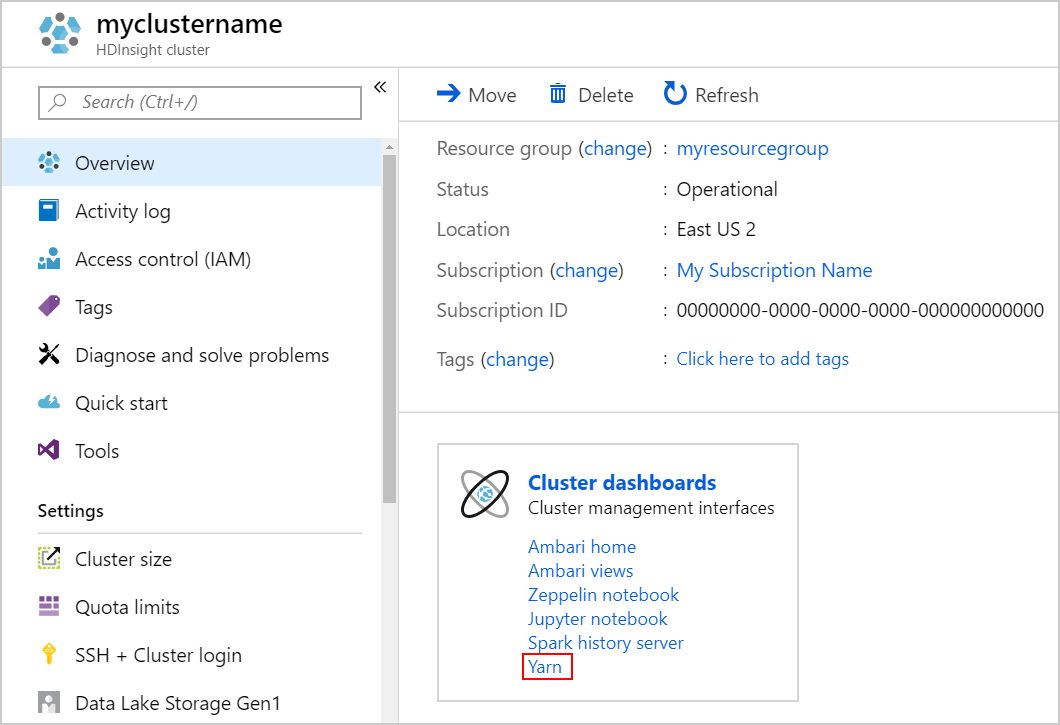
Запустите пользовательский интерфейс YARN. Выберите Yarn в панели мониторинга кластера.
Подсказка
Также пользовательский интерфейс YARN можно открыть из пользовательского интерфейса Ambari. Чтобы запустить пользовательский интерфейс Ambari, выберите дом Ambari в разделе "Панели мониторинга кластера". В пользовательском интерфейсе Ambari перейдите к YARN>Quick Links> активному интерфейсу >.
Так как вы запустили задание Spark с помощью Записных книжек Jupyter, приложение имеет имя remotesparkmagics (имя для всех приложений, запущенных из записных книжек). Выберите идентификатор приложения по имени приложения, чтобы получить дополнительные сведения о работе. Это действие запускает представление приложения.
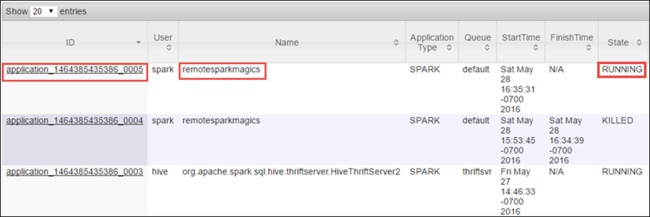
Для таких приложений, запускаемых из ноутбуков Jupyter, состояние всегда выполняется, пока вы не выйдете из ноутбука.
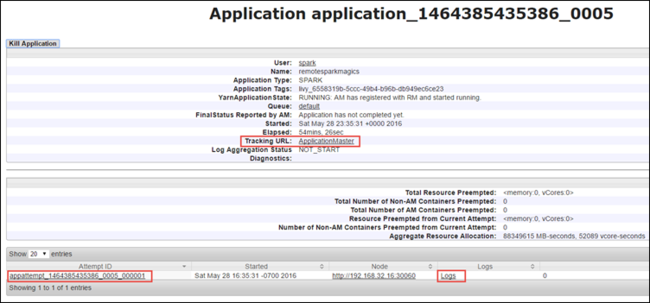
В представлении приложения можно подробнее узнать контейнеры, связанные с приложением, и журналы (stdout/stderr). Вы также можете запустить пользовательский интерфейс Spark, щелкнув ссылку, соответствующую URL-адресу отслеживания, как показано ниже.
Отслеживание приложения в пользовательском интерфейсе Spark
В пользовательском интерфейсе Spark можно углубиться в детали заданий Spark, которые создаются приложением, запущенным ранее.
Чтобы запустить пользовательский интерфейс Spark, в представлении приложения выберите ссылку на URL-адрес отслеживания, как показано в приведенном выше снимке экрана. Вы можете видеть все задания Spark, которые запускаются приложением, работающим в Jupyter Notebook.

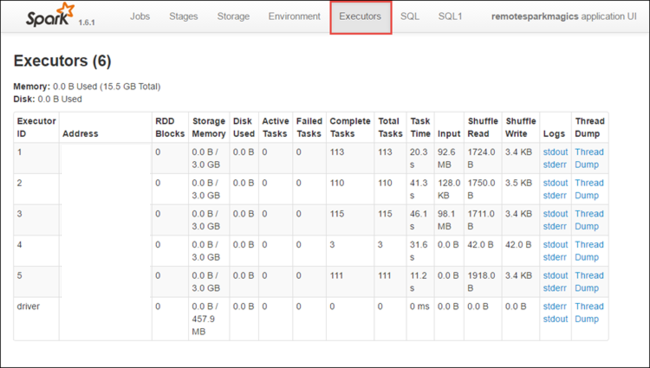
Перейдите на вкладку "Исполнители" , чтобы просмотреть сведения об обработке и хранении для каждого исполнителя. Вы также можете получить стек вызовов, выбрав ссылку "Дамп потока ".
Перейдите на вкладку "Этапы ", чтобы просмотреть этапы, связанные с приложением.
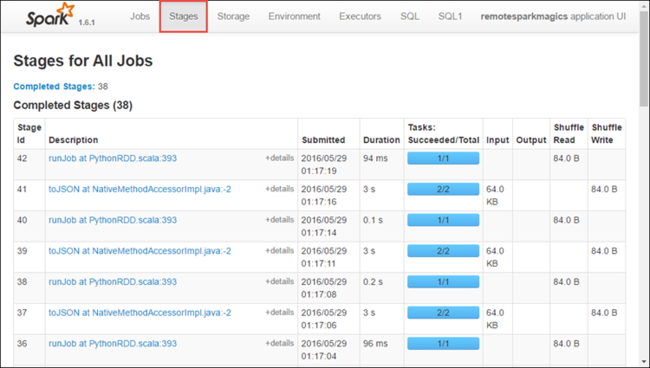
Каждый этап может иметь несколько задач, для которых можно просмотреть статистику выполнения, как показано ниже.

На странице сведений о стадии можно запустить визуализацию DAG. Разверните ссылку на визуализацию DAG в верхней части страницы, как показано ниже.

DAG или Direct Aclyic Graph представляет различные этапы приложения. Каждое синее поле в графе представляет операцию Spark, вызванную приложением.
На странице сведений о стадии можно также запустить представление временной шкалы приложения. Разверните ссылку " Временная шкала событий " в верхней части страницы, как показано ниже.

На этом изображении отображаются события Spark в виде временной шкалы. Представление временной шкалы доступно на трех уровнях, между заданиями, в задании и на этапе. На приведенном выше изображении показано представление временной шкалы для заданного этапа.
Подсказка
Если установлен флажок "Включить масштабирование ", можно прокрутить экран влево и вправо по временной шкале.
Другие вкладки в пользовательском интерфейсе Spark предоставляют полезные сведения о экземпляре Spark.
- Вкладка хранилища. Если приложение создает RDD, вы можете найти сведения на вкладке хранилища.
- Вкладка "Среда" - Эта вкладка содержит полезные сведения о вашем экземпляре Spark, например:
- Версия Scala
- Каталог журнала событий, связанный с кластером
- Количество ядер исполнителя для приложения
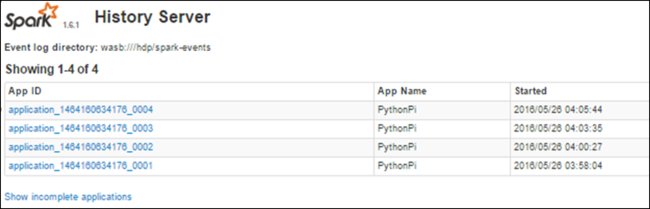
Найдите информацию о завершённых заданиях с помощью сервера истории Spark
После завершения задания сведения о задании сохраняются на сервере журнала Spark.
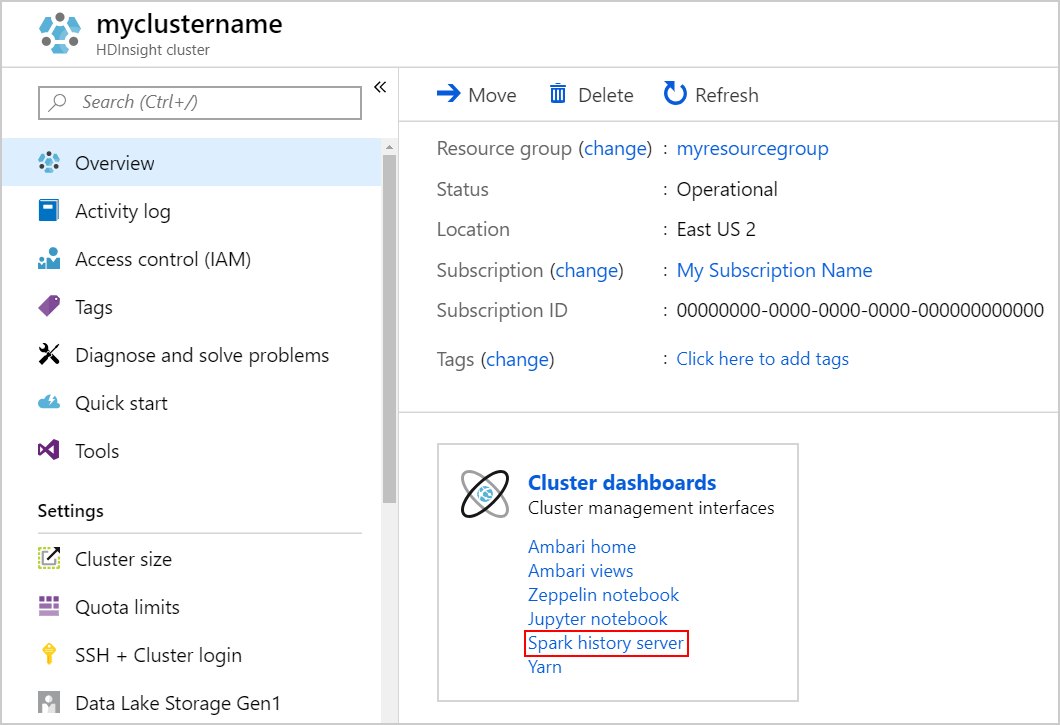
Чтобы запустить сервер журнала Spark, на странице "Обзор " выберите сервер журнала Spark на панели мониторинга кластера.
Подсказка
Кроме того, можно запустить пользовательский интерфейс сервера журнала Spark из пользовательского интерфейса Ambari. Чтобы открыть интерфейс Ambari, в разделе "Обзор" выберите Ambari home в подразделе Панели управления кластером. В пользовательском интерфейсе Ambari перейдите к Spark2, затем >, и откройте интерфейс обозревателя истории Spark2.
Вы увидите все завершенные приложения, перечисленные в списке. Выберите идентификатор приложения, чтобы перейти к приложению и получить больше информации.