Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Из этого краткого руководства вы узнаете, как использовать Apache Zeppelin для выполнения запросов Apache Hive в Azure HDInsight. Кластеры интерактивных запросов HDInsight включают записные книжки Apache Zeppelin , которые можно использовать для выполнения интерактивных запросов Hive.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Предпосылки
Кластер интерактивных запросов HDInsight. См. статью "Создание кластера " для создания кластера HDInsight. Обязательно выберите тип кластера интерактивных запросов .
Создайте заметку в Apache Zeppelin
Замените
CLUSTERNAMEименем кластера в следующем URL-адресеhttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Затем введите URL-адрес в веб-браузере.Введите имя пользователя и пароль для входа в кластер. На странице Zeppelin можно создать новую заметку или открыть существующие заметки. HiveSample содержит некоторые примеры запросов Hive.

Выберите "Создать заметку".
В диалоговом окне "Создание заметки" введите или выберите следующие значения:
- Имя заметки. Введите имя заметки.
- Интерпретатор по умолчанию: выберите jdbc из раскрывающегося списка.
Выберите "Создать заметку".
Введите следующий запрос Hive в разделе кода и нажмите клавиши Shift + Enter:
%jdbc(hive) show tables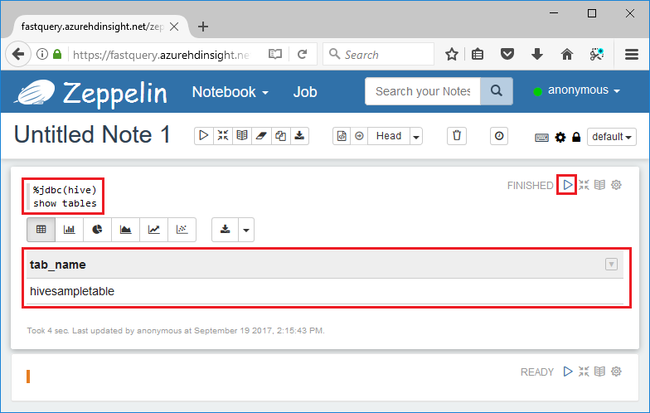
Инструкция
%jdbc(hive)в первой строке сообщает записной книжке использовать интерпретатор Hive JDBC.Запрос должен возвращать одну таблицу Hive с именем hivesampletable.
Ниже приведены два дополнительных запроса Hive, которые можно выполнить в hivesampletable:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}По сравнению с традиционным Hive результаты запроса возвращаются гораздо быстрее.
Дополнительные примеры
Создайте таблицу. Выполните код в записной книжке Zeppelin:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Загрузите данные в новую таблицу. Выполните код в записной книжке Zeppelin:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Вставьте одну запись. Выполните код в записной книжке Zeppelin:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Дополнительные сведения см. в руководстве по языку Hive .
Очистка ресурсов
После завершения быстрого запуска вы можете захотеть удалить кластер. В случае с HDInsight ваши данные хранятся в службе хранилища Azure, что позволяет безопасно удалить неиспользуемый кластер. Плата за кластеры HDInsight взимается, даже когда они не используются. Так как затраты на кластер во много раз превышают затраты на хранилище, экономически целесообразно удалять неиспользуемые кластеры.
Инструкции по удалению кластера см. в статье Delete an HDInsight cluster using your browser, PowerShell, or the Azure CLI (Удаление кластера HDInsight с помощью браузера, PowerShell или Azure CLI).
Дальнейшие действия
Из этого краткого руководства вы узнали, как использовать Apache Zeppelin для выполнения запросов Apache Hive в Azure HDInsight. Чтобы узнать больше о запросах Hive, в следующей статье показано, как выполнять запросы с помощью Visual Studio.