Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
HDInsight обеспечивает эластичность с параметрами для увеличения и уменьшения числа рабочих узлов в ваших кластерах. Эта эластичность позволяет уменьшать кластер после рабочей смены или в выходные дни. И расширить его в периоды максимальной бизнес-нагрузки.
Масштабируйте кластер до периодической пакетной обработки, чтобы кластер получил достаточные ресурсы. После завершения обработки и уменьшения использования масштабируйте кластер HDInsight до меньше рабочих узлов.
Вы можете масштабировать кластер вручную с помощью одного из следующих методов. Вы также можете использовать параметры автомасштабирования для автоматического увеличения и уменьшения масштаба в ответ на определенные метрики.
Примечание.
Поддерживаются только кластеры HDInsight версии 3.1.3 или более поздней. Если вы не уверены в версии кластера, можно проверить страницу "Свойства".
Служебные программы для масштабирования кластеров
Корпорация Майкрософт предоставляет следующие служебные программы для масштабирования кластеров:
| Полезность | Описание |
|---|---|
| PowerShell Az |
Set-AzHDInsightClusterSize
-ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE
|
| Azure CLI |
az hdinsight resize
--resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE
|
| Классический интерфейс командной строки Azure | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Портал Azure | Откройте панель кластера HDInsight, выберите размер кластера в меню слева, а затем в области размера кластера введите количество рабочих узлов и нажмите кнопку "Сохранить". |
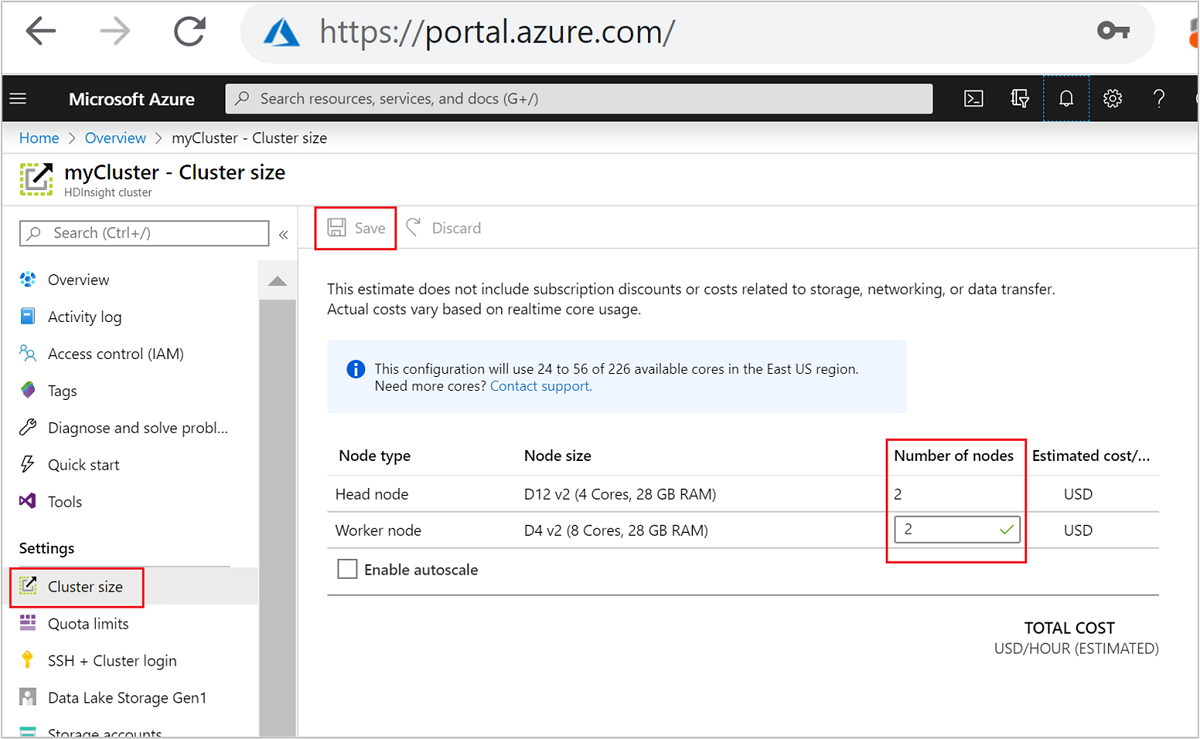
Используя любой из этих методов, вы можете масштабировать кластер HDInsight вверх или вниз в течение нескольких минут.
Это важно
Влияние операций масштабирования
При добавлении узлов в запущенный кластер HDInsight (увеличение масштаба) задания остаются без изменений. Новые задания можно безопасно отправить во время выполнения процесса масштабирования. Если операция масштабирования завершается сбоем, кластер остается в функциональном состоянии.
Если удалить узлы (уменьшить масштаб), ожидающие или выполняющиеся задания потерпят неудачу при завершении операции масштабирования. Этот сбой обусловлен перезапуском некоторых служб во время масштабирования. Кластер может застрять в безопасном режиме во время операции масштабирования вручную.
Влияние изменения количества узлов данных зависит от каждого типа кластера, поддерживаемого HDInsight:
Apache Hadoop
Вы можете легко увеличить количество рабочих узлов в работающем кластере Hadoop, не влияя на какие-либо задания. Новые задания можно также отправить во время выполнения операции. Сбои в операции масштабирования обрабатываются элегантно. Кластер всегда остается в функциональном состоянии.
Если кластер Hadoop масштабируется с меньшим количеством узлов данных, некоторые службы перезапускаются. Это поведение приводит к сбою всех выполняемых и ожидающих заданий при завершении операции масштабирования. Однако вы можете повторно отправить задания после завершения операции.
Apache HBase
Вы можете легко добавлять или удалять узлы в кластер HBase во время его работы. Региональные серверы автоматически балансируются в течение нескольких минут после завершения операции масштабирования. Однако вы можете сбалансировать региональные серверы вручную. Войдите в головной узел кластера и выполните следующие команды:
pushd %HBASE_HOME%\bin hbase shell balancerДополнительные сведения об использовании оболочки HBase см. в статье "Начало работы с примером Apache HBase в HDInsight".
Примечание.
Недоступно для кластеров Kafka.
Apache Hive LLAP
После масштабирования до
Nрабочих узлов HDInsight автоматически настраивает следующие конфигурации и перезапускает Hive.- Максимальное количество одновременных запросов:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Количество узлов, используемых LLAP системы Hive:
num_llap_nodes = N - Количество узлов для запуска управляющей программы Hive LLAP:
num_llap_nodes_for_llap_daemons = N
- Максимальное количество одновременных запросов:
Как безопасно уменьшить масштаб кластера
Уменьшите размер кластера с запущенными заданиями
Чтобы избежать сбоя выполняемых заданий во время операции уменьшения масштаба, можно попробовать три действия.
- Дождитесь завершения заданий перед масштабированием кластера.
- Вручную завершите задания.
- Повторно отправьте задания после завершения операции масштабирования.
Чтобы просмотреть список ожидающих и выполняющихся заданий, можно использовать пользовательский интерфейс YARN Resource Manager, выполнив следующие действия.
На портале Azure выберите свой кластер. Кластер откроется на новой странице портала.
В главном представлении перейдите к панелям инструментов кластера>на домашнюю страницу Ambari. Введите учетные данные кластера.
В пользовательском интерфейсе Ambari выберите YARN в списке служб в меню слева.
На странице YARN выберите быстрые ссылки и наведите указатель мыши на активный головной узел, а затем выберите пользовательский интерфейс Resource Manager.
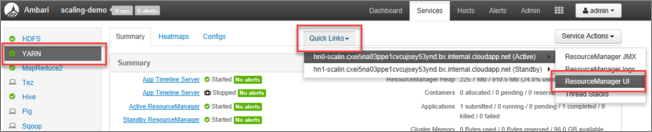
Вы можете получить доступ к пользовательскому интерфейсу Resource Manager напрямую с помощью https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
Вы видите список заданий вместе с их текущим состоянием. На снимке экрана в данный момент выполняется одно задание.
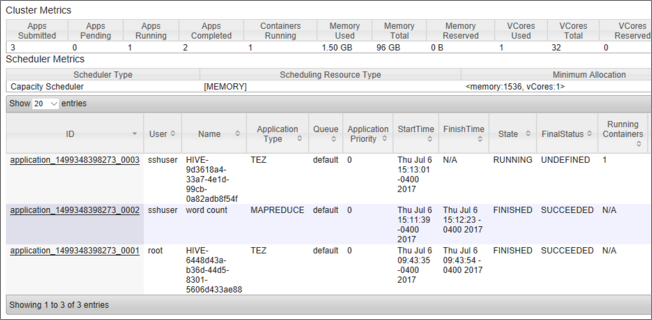
Чтобы вручную убить запущенное приложение, выполните следующую команду из оболочки SSH:
yarn application -kill <application_id>
Рассмотрим пример.
yarn application -kill "application_1499348398273_0003"
Застревание в безопасном режиме
При уменьшении масштаба кластера HDInsight использует интерфейсы управления Apache Ambari для первого вывода из эксплуатации дополнительных рабочих узлов. Узлы реплицируют блоки HDFS на другие рабочие узлы в сети. После этого HDInsight безопасно уменьшает масштаб кластера. HDFS переходит в безопасный режим во время операции масштабирования. HDFS должен выйти после завершения масштабирования. Однако в некоторых случаях HDFS зависает в безопасном режиме во время операции масштабирования из-за нерепликации блока файлов.
По умолчанию HDFS настраивается с параметром dfs.replication 1, который определяет количество копий каждого блока файлов. Каждая копия блока файлов хранится на другом узле кластера.
Если ожидаемое количество копий блоков недоступно, HDFS вводит безопасный режим, а Ambari создает оповещения. HDFS может ввести безопасный режим для операции масштабирования. Кластер может застрять в безопасном режиме, если требуемое количество узлов не обнаружено для репликации.
Примеры ошибок при включении безопасного режима
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Можно просмотреть журналы NameNode в папке /var/log/hadoop/hdfs/ за время, близкое к моменту масштабирования кластера, чтобы узнать, когда он вошел в безопасный режим. Файлы журнала называются Hadoop-hdfs-namenode-<active-headnode-name>.*.
Основная причина заключалась в том, что Hive зависит от временных файлов в HDFS при выполнении запросов. Когда HDFS входит в безопасный режим, Hive не может выполнять запросы, так как он не может записывать в HDFS. Временные файлы в HDFS находятся на локальном диске, подключенном к отдельным виртуальным машинам рабочего узла. Файлы реплицируются среди других рабочих узлов, минимум на трёх репликах.
Как предотвратить зависание HDInsight в безопасном режиме
Существует несколько способов запретить hdInsight оставаться в безопасном режиме:
- Остановите все задания Hive перед масштабированием HDInsight. Кроме того, запланируйте процесс уменьшения масштаба, чтобы избежать конфликтов с выполнением заданий Hive.
- Перед масштабированием вручную очистите файлы каталогов Hive
tmpв HDFS. - Уменьшите масштабы HDInsight до трех рабочих узлов, минимум. Избегайте использования всего одного рабочего узла.
- При необходимости выполните команду, чтобы оставить безопасный режим.
В следующих разделах описаны эти параметры.
Остановить все задания Hive
Остановите все задания Hive перед масштабированием до одного рабочего узла. Если ваша рабочая нагрузка запланирована, выполните уменьшение масштабирования после завершения выполнения работы Hive.
Остановите задания Hive перед масштабированием, чтобы свести к минимуму количество временных файлов в папке tmp, если таковые есть.
Очистка царапин файлов Hive вручную
Если Hive оставил временные файлы, вы можете вручную очистить эти файлы перед масштабированием, чтобы избежать безопасного режима.
Узнайте, какое место расположения используется для временных файлов Hive, проверив
hive.exec.scratchdirсвойство конфигурации. Этот параметр задается в пределах/etc/hive/conf/hive-site.xml.<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Остановите службы Hive и убедитесь, что все запросы и задания завершены.
Просмотрите содержимое временного каталога, указанного выше,
hdfs://mycluster/tmp/hive/, чтобы узнать, содержит ли он файлы:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveНиже приведен пример выходных данных при наличии файлов:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoЕсли вы знаете, что Hive завершил работу с этими файлами, вы можете их удалить. Убедитесь, что в Hive не выполняются никакие запросы, проверив это в интерфейсе Yarn Resource Manager.
Пример командной строки для удаления файлов из HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Масштабирование HDInsight до трех или более рабочих узлов
Если ваши кластеры часто застревают в безопасном режиме при уменьшении до менее чем трех рабочих узлов, сохраняйте как минимум три рабочих узла.
Наличие трех рабочих узлов является более дорогостоящим, чем масштабирование до одного рабочего узла. Однако это действие предотвращает зависание кластера в безопасном режиме.
Уменьшите HDInsight до одного рабочего узла
Даже если кластер масштабируется до одного узла, рабочий узел 0 по-прежнему сохраняется. Рабочий узел 0 никогда не может быть выведен из эксплуатации.
Выполните команду, чтобы оставить безопасный режим
Последний вариант — выполнить команду выхода из безопасного режима. Если HDFS ввел безопасный режим из-за недорепликации файла Hive, выполните следующую команду, чтобы оставить безопасный режим:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Уменьшение масштаба кластера Apache HBase
Серверы регионов автоматически балансируются в течение нескольких минут после завершения операции масштабирования. Чтобы сбалансировать серверы регионов вручную, выполните следующие действия.
Подключитесь к кластеру HDInsight с помощью SSH. Дополнительные сведения см. в статье Подключение к HDInsight (Hadoop) с помощью SSH.
Запустите оболочку HBase:
hbase shellИспользуйте следующую команду, чтобы вручную сбалансировать серверы регионов:
balancer
Дальнейшие действия
Дополнительные сведения о масштабировании кластера HDInsight см. в статье: