Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Автомасштабирование Lakebase — это последняя версия Lakebase с автомасштабированием вычислений, масштабированием до нуля, ветвлением и мгновенным восстановлением. Сведения о поддерживаемых регионах см. в разделе "Доступность регионов". Если вы являетесь пользователем Lakebase Provisioned, см. Lakebase Provisioned.
В этом руководстве описывается включение высокой доступности конечных точек Lakebase и управление ими. Общие сведения о том, как работает высокий уровень доступности и как вторичные вычислительные экземпляры отличаются от автономных реплик чтения, см. в разделе "Высокий уровень доступности".
Включение высокой доступности
Чтобы включить высокий уровень доступности, задайте тип вычислений и конфигурацию высокого уровня доступности в пользовательском интерфейсе или настройте конечную точку EndpointGroupSpec через API.
Необходимые условия
- Масштабирование до нуля должно быть отключено. В пользовательском интерфейсе установите Масштаб в значение "Отключено" в разделе редактирования вычислений. С помощью API задайте
no_suspension: trueв спецификации конечной точки (используйтеspec.suspensionв качестве маски обновления).
Пользовательский интерфейс
После создания проекта щелкните основную ссылку на вычислительные ресурсы на панели мониторинга проекта, чтобы открыть средство редактирования вычислительных ресурсов.
панель управления проекта, показывающая производственную ветвь с основной вычислительной связью
Задайте для типа вычисленийвысокий уровень доступности, а затем выберите конфигурацию в разделе "Высокий уровень доступности".
- 2 (1 первичная, 1 вторичная),
- 3 (1 основной, 2 второстепенных)
- или 4 (1 первичный, 3 вторичных) общего числа вычислительных экземпляров.

Lakebase обеспечивает развертывание вторичных вычислительных экземпляров в различных зонах доступности. После активации всех вычислительных экземпляров конечная точка имеет автоматический переход на резервный ресурс.
пакет SDK Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
result = w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(
min=2,
max=2,
enable_readable_secondaries=True
)
)
),
update_mask=FieldMask(field_mask=["spec.group"])
).wait()
print(f"Group size: {result.status.group.max}")
print(f"Host: {result.status.hosts.host}")
print(f"Read-only host: {result.status.hosts.read_only_host}")
CLI
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group" \
--json '{
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}'
завиток
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}' | jq
Настройка доступа только для чтения к вторичным вычислительным экземплярам
Разрешить доступ к вычислительным экземплярам только для чтения определяет, обслуживают ли вторичные вычислительные экземпляры трафик для чтения через -ro строку подключения.
Пользовательский интерфейс
- На вкладке "Вычисления" нажмите кнопку "Изменить " для основного вычисления.
- В разделе "Высокий уровень доступности" установите или снимите флажок Разрешить доступ к вычислительным экземплярам только для чтения.
- Нажмите кнопку Сохранить.
пакет SDK Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
# Get current group size first
current = w.postgres.get_endpoint(name=endpoint_name)
current_size = current.status.group.max
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(
min=current_size,
max=current_size,
enable_readable_secondaries=True # set False to disable
)
)
),
update_mask=FieldMask(field_mask=["spec.group.enable_readable_secondaries"])
).wait()
CLI
# Replace 2 with your current group size
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group.enable_readable_secondaries" \
--json '{
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}'
завиток
# Replace 2 with your current group size
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group.enable_readable_secondaries" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}' | jq
Предупреждение
Только один дополнительный вычислительный экземпляр и включён доступ на чтение, весь трафик чтения по строке подключения прерывается во время переключения при сбое, пока не будет добавлена замена. Для устойчивого доступа на чтение настройте два или более вторичных вычислительных экземпляров с включенным доступом на чтение.
Изменение количества вторичных вычислительных экземпляров
Пользовательский интерфейс
- На вкладке "Вычисления" нажмите кнопку "Изменить " для основного вычисления.
- В разделе "Высокий уровень доступности" выберите новую конфигурацию вычислений в раскрывающемся списке (2, 3 или 4 общих вычислительных экземпляров).
- Нажмите кнопку Сохранить.
Замечание
Чтобы отключить высокий уровень доступности, измените тип вычислений обратно на Одиночное вычисление. При этом удаляются все вторичные вычислительные экземпляры, а конечная точка возвращается в конфигурацию с одним вычислением.
пакет SDK Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
# Scale to 3 compute instances (1 primary + 2 secondaries)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(min=3, max=3)
)
),
update_mask=FieldMask(field_mask=["spec.group.min", "spec.group.max"])
).wait()
CLI
# Scale to 3 compute instances (1 primary + 2 secondaries)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group.min,spec.group.max" \
--json '{
"spec": {
"group": { "min": 3, "max": 3 }
}
}'
завиток
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group.min,spec.group.max" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": { "min": 3, "max": 3 }
}
}' | jq
Просмотр состояния и ролей высокого уровня доступности
На вкладке "Вычисления" показан каждый вычислительный экземпляр в конфигурации высокой доступности с текущей ролью, состоянием и уровнем доступа.
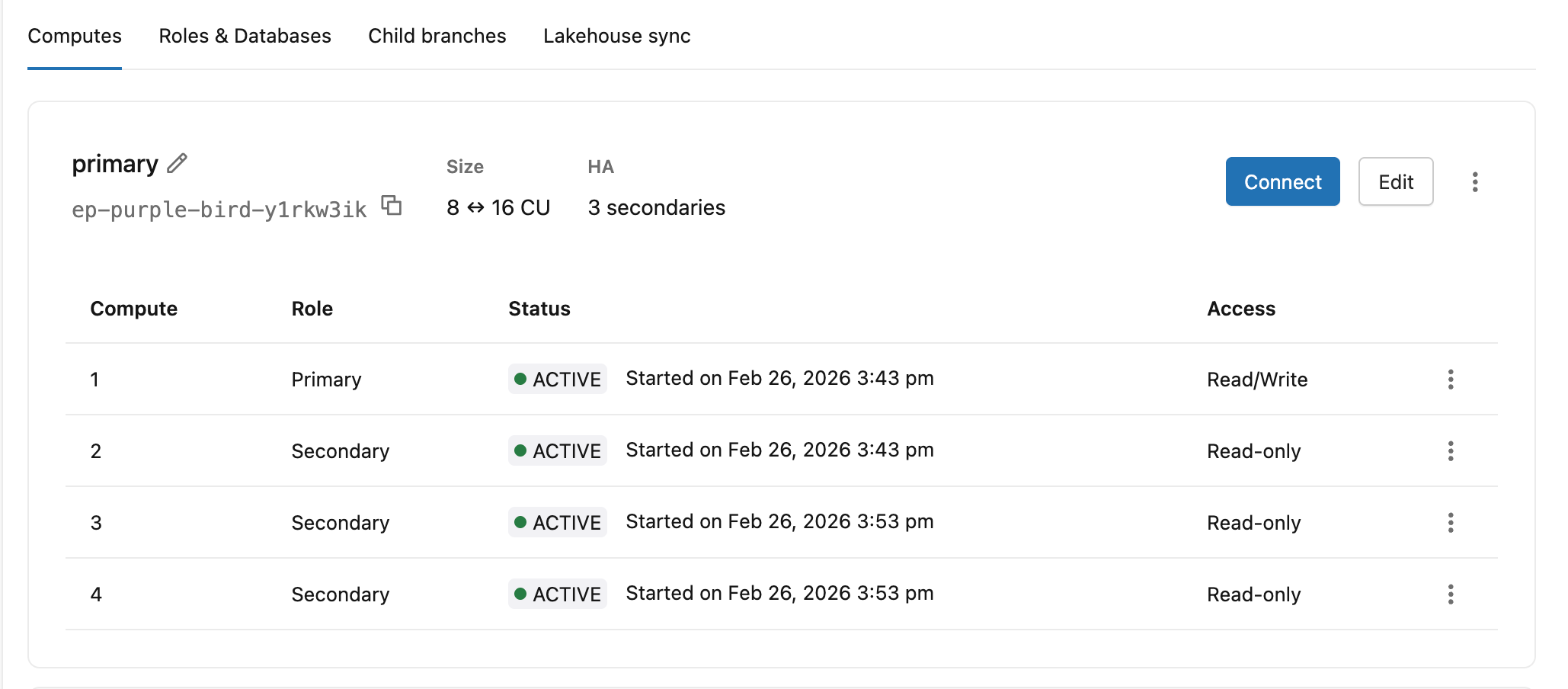
| колонна | Ценности |
|---|---|
| Роль | Основной, вторичный |
| Статус | Запуск, активный |
| Открыть | Чтение и запись (основной), только для чтения (вторичный вычислительный экземпляр с включенным доступом), отключен (вторичный вычислительный экземпляр без доступа на чтение) |
Основной заголовок вычислений также отображает идентификатор конечной точки, диапазон автомасштабирования и дополнительное число (например, 8 ↔ 16 CU · 3 secondaries).
Получение строк подключения
Пользовательский интерфейс
Нажмите "Подключиться" на основном вычислительном узле, чтобы открыть диалоговое окно сведений о подключении. В раскрывающемся списке вычислений перечислены оба варианта подключения для конечной точки высокой доступности.

| Параметр вычислений | Строка соединения | Используется для |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
Все соединения для записи и чтения/записи |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
Перенос операций чтения на вторичные вычислительные узлы |
Строка подключения
пакет SDK Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
endpoint = w.postgres.get_endpoint(
name="projects/my-project/branches/production/endpoints/my-endpoint"
)
print(f"Read/write host: {endpoint.status.hosts.host}")
print(f"Read-only host: {endpoint.status.hosts.read_only_host}")
CLI
databricks postgres get-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
-o json | jq '{rw_host: .status.hosts.host, ro_host: .status.hosts.read_only_host}'
завиток
curl -X GET "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
| jq '{rw_host: .status.hosts.host, ro_host: .status.hosts.read_only_host}'
Для получения полной информации о строках подключения см. раздел Строки подключения.
Дальнейшие действия
- Высокая доступность — основные понятия, поведение переключения при отказе и передовые методы.
- Реплики чтения — автономные реплики чтения для увеличения емкости чтения без обеспечения высокой доступности
- строки подключения