Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Автомасштабирование Lakebase — это последняя версия Lakebase с автомасштабированием вычислений, масштабированием до нуля, ветвлением и мгновенным восстановлением. Сведения о поддерживаемых регионах см. в разделе "Доступность регионов". Если вы являетесь пользователем Lakebase Provisioned, см. Lakebase Provisioned.
Автомасштабируемая база данных Postgres Lakebase — это полностью управляемая база данных Postgres, созданная для любого приложения, требующего обработки транзакций в сети (OLTP) и предоставления данных с низкой задержкой. Он интегрирован в платформу Databricks, что позволяет создавать приложения транзакций в режиме реального времени вместе с рабочими нагрузками аналитики.
Автомасштабирование в Lakebase Postgres сочетает надежность и привычность Postgres с современными возможностями базы данных, такими как автоматическое масштабирование, уменьшение масштабирования до нуля, разветвление и мгновенное восстановление. Эти функции обеспечивают гибкие рабочие процессы разработки, экономичные операции и быструю итерацию.
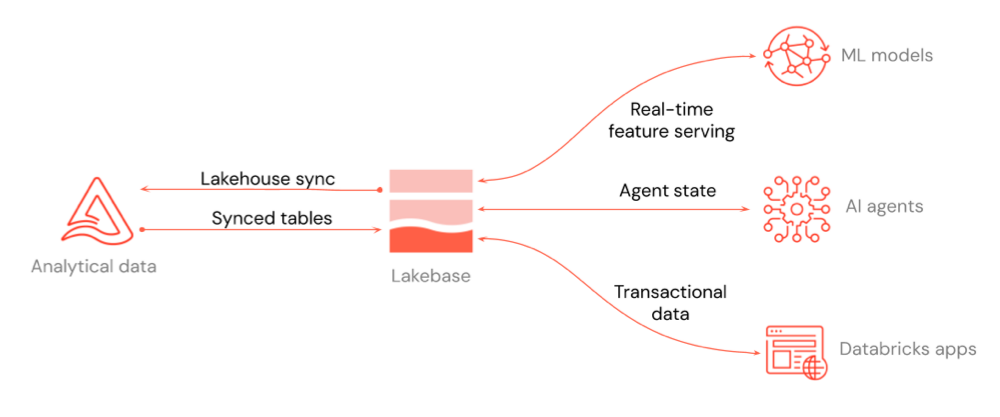
На схеме показано, как Lakebase интегрируется с остальной частью платформы: функция реального времени, обслуживающая модели машинного обучения и хранилище компонентов, состояние агента для агентов ИИ и транзакционные данные для Приложений Databricks или любое приложение, к которому вы подключаетесь.
Данные можно перемещать в любом направлении между вашим озёрным домом (lakehouse) и Lakebase. Синхронизированные таблицы перемещают данные из lakehouse в Lakebase, чтобы приложения могли запрашивать их при низкой задержке.
Примеры вариантов использования и типов рабочих нагрузок
Ниже приведены лишь несколько примеров множества способов использования базы данных OLTP Postgres, таких как Lakebase в различных отраслях: персонализированные рекомендации и предложения, предназначенные для электронной коммерции и розничной торговли, клинических испытаний и систем рекомендаций в области здравоохранения, автоматизированной аналитики торговли и потоковой передачи в финансовых службах, а также телеметрии машин и рабочих процессов обслуживания в производстве.
Распространенные типы рабочих нагрузок для баз данных OLTP могут включать следующие:
- Обслуживание данных: Предоставление аналитических сведений от эталонных таблиц приложениям с низкой задержкой и высокой частотой запросов (QPS).
- Хранение состояния приложения: Управление состоянием рабочего процесса и агента в хранилище транзакционных данных.
- Подавать признаки: Подача данных с признаками с низкой задержкой для моделей машинного обучения.
Интеграция Databricks
На схеме выше выделены три основных варианта использования интеграции:
- Обслуживание функций в режиме реального времени: Используйте проекты Lakebase в качестве интернет-магазина для моделей машинного обучения и хранилища компонентов, чтобы вы могли обслуживать данные с небольшими задержками. Ознакомьтесь с интернет-магазином функций (Lakebase) и обслуживанием компонентов.
- Состояние агента для агентов ИИ: Храните и управляйте состоянием агентов ИИ в транзакционной базе данных, чтобы беседы и контекст рабочего процесса сохранялись между запросами.
- Транзакционные данные для приложений: Сохраняйте данные для Приложений Databricks или любого приложения, подключаемого к Lakebase. Для Databricks Apps добавьте проект Lakebase в качестве ресурса приложения. См. статью "Добавление ресурса Lakebase" в приложение Databricks.
Подготовлено Lakebase
Lakebase Provisioned — это исходное предложение Lakebase, которое использует подготовленные вычислительные ресурсы, масштабируемые вручную. Существующие подготовленные экземпляры продолжают поддерживаться. Разработка New Lakebase ориентирована на самомасштабирование. Если у вас есть подготовленные экземпляры или оцениваете оба варианта, см. раздел «Что такое Lakebase подготовленные экземпляры?» и Автомасштабирование по умолчанию.
Что такое проект?
Ресурсы автомасштабирования Lakebase организованы в структуру проекта . Проект — это контейнер верхнего уровня для ресурсов базы данных. При создании базы данных Автомасштабирования Lakebase создается проект. Проект содержит среды баз данных (ветви), вычислительные компоненты, роли и базы данных. Думайте о проекте как единице организации для одного приложения или рабочей нагрузки. У вас может быть несколько проектов в рабочей области, каждая из которых содержит собственные ветви и данные.
Порядок организации проектов
Понимание иерархии объектов в проекте помогает упорядочивать ресурсы и управлять ими:
Databricks Workspace
└── Project(s)
└── Branch(es)
├── Compute (primary R/W)
├── Read replica(s) (optional)
├── Role(s)
└── Database(s)
└── Schema(s)
Каждый уровень в иерархии служит определенной целью:
| Object | Description |
|---|---|
| Project | Контейнер верхнего уровня для ресурсов базы данных. Проект содержит ветви, базы данных, роли и вычислительные ресурсы. См. статью "Управление проектами". |
| Филиал | Изолированная среда базы данных, которая предоставляет общий доступ к хранилищу с родительской ветвью. Каждый проект может содержать несколько ветвей. См. раздел "Управление ветвями". |
| Вычисление | Сервер Postgres, который управляет ветвью. Каждая ветвь имеет собственные вычислительные ресурсы, которые предоставляют вычислительные мощности и память для операций с базами данных. См. раздел "Управление вычислениями". |
| База данных | Стандартная база данных Postgres в ветви. Каждая ветвь может содержать несколько баз данных с собственными таблицами, схемами и данными. См. раздел "Управление базами данных". |
Общие сведения о ветвях
Одним из самых мощных функций Lakebase Postgres является ветвление. Как и ветви Git для кода, ветви позволяют создавать изолированные среды базы данных для разработки и тестирования, не влияя на рабочую среду.
Почему это важно: Для традиционных рабочих процессов базы данных требуются отдельные серверы разработки и промежуточные серверы, обновления данных вручную и тщательная координация. С помощью ветвей можно:
- Мгновенное создание среды разработки с рабочими данными
- Безопасно тестируйте изменения схемы перед применением их к промышленной среде.
- Восстановление от ошибок путем создания ветвей с любого момента времени
- Оплата только за измененные данные, а не полные повторяющиеся базы данных
| Тема | Description |
|---|---|
| Филиалы | Узнайте, как работают ветви, распространенные рабочие процессы и рекомендации для вашей команды. |
| Управление ветвями | Создавайте, сбрасывайте и удаляйте ветки для разработки и тестирования. |
| Защищенные ветви | Защита продуктивных ветвей от случайных изменений и удалений. |
Основные понятия
Lakebase основан на нескольких ключевых инновациях, которые отличают его от традиционных систем баз данных:
- Разделенные вычислительные ресурсы и хранилище: Масштабируйте вычислительные ресурсы независимо от хранилища для повышения эффективности затрат и гибкости.
- Автомасштабирование: Вычислительные ресурсы автоматически настраиваются на основе спроса на рабочую нагрузку, с поддержкой масштабирования до нуля во время простаивания.
- Копирование при записи: Позволяет мгновенное ветвление, где вы оплачиваете только изменения данных, а не полное копирование.
- Мгновенные операции на момент времени: Создание ветвей или восстановление в любой момент в течение настроенного периода восстановления (2–30 дней)
Эти понятия работают вместе, чтобы обеспечить гибкие рабочие процессы разработки, эффективные операции и быстрое восстановление после ошибок.
Подробное описание каждой основной концепции см. в разделе "Основные понятия".