Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Таблица потоковой передачи — это таблица Delta с дополнительной поддержкой потоковой или добавочной обработки данных. Таблица потоковой передачи может быть нацелена на один или несколько потоков в конвейере.
Потоковые таблицы являются хорошим выбором для загрузки данных по следующим причинам:
- Каждая входная строка обрабатывается только один раз, что моделирует подавляющее большинство рабочих нагрузок по приему данных, а именно добавление или обновление строк в таблице.
- Они могут обрабатывать большие объемы данных, доступных только для добавления.
Таблицы потоковой передачи также являются хорошим выбором для низкой задержки потоковых преобразований, так как они могут работать с строками и временными окнами, обрабатывать большие объемы данных и обеспечивать обработку с низкой задержкой.
На следующей схеме показано, как потоки считываются из источников потоковой передачи и постепенно записываются в таблицу потоковой передачи в конвейере.
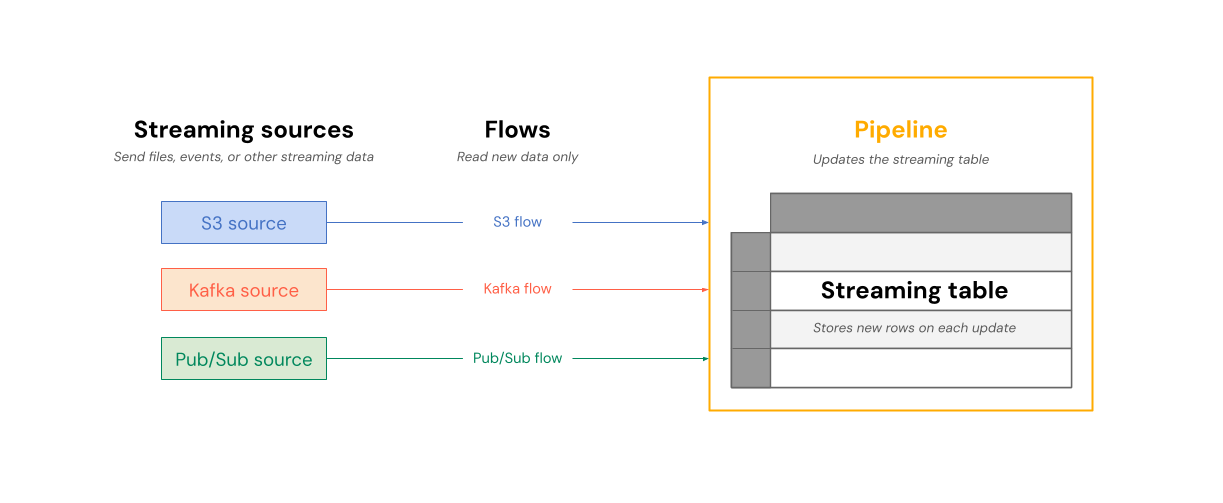
В каждом обновлении потоки, связанные с таблицей потоковой передачи, считывают измененные сведения в источнике потоковой передачи и добавляют новые сведения в эту таблицу.
Потоковые таблицы принадлежат и обновляются одним конвейером. Вы явно определяете таблицы потоковой передачи в исходном коде конвейера. Таблицы, определенные конвейером, не могут быть изменены или обновлены любым другим конвейером. Можно определить несколько потоков для добавления к одной таблице потоковой передачи.
Azure Databricks создает внутренние таблицы для поддержки обработки потоковых таблиц. Эти таблицы появляются в system.information_schema.tables, но не видны в обозревателе каталогов или на других страницах пользовательского интерфейса рабочей области.
Замечание
При создании потоковой таблицы за пределами конвейера с помощью Databricks SQL Azure Databricks создает конвейер, используемый для обновления таблицы. Можно увидеть конвейер, выбрав в рабочей области пункт ETL. Потоковые таблицы, созданные в Databricks SQL, имеют тип MV/ST.
Для получения дополнительной информации о потоках см. раздел Загрузка и обработка данных поэтапно с помощью потоков декларативных конвейеров Spark Lakeflow.
Потоковая передача таблиц для загрузки
Потоковые таблицы предназначены для источников данных, к которым можно только добавлять, и обрабатывают входные данные единожды. Это делает их хорошо подходящими для нагрузок на прием данных, когда данные поступают непрерывно и должны надежно фиксироваться без повторной обработки существующих записей. Azure Databricks поддерживает прием данных из облачного хранилища и потоковой передачи сообщений.
Прием файлов из облачного хранилища
Вы можете использовать потоковую таблицу для ингерирования новых файлов из облачного хранилища. В этих примерах используется автозагрузчик для добавочного обработки новых файлов по мере их поступления.
Питон
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
Чтобы создать таблицу потоковой передачи, определение набора данных должно быть типом потока. При использовании spark.readStream функции в определении набора данных он возвращает потоковый набор данных.
SQL
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
Для таблиц для потоковой обработки данных требуются наборы данных для потоковой передачи. Ключевое слово STREAM перед read_files указывает запросу обрабатывать набор данных в виде потока.
Прием потоковых сообщений
Стриминговые таблицы также можно использовать для приема данных из шин сообщений. В следующем примере показано, как создать потоковую таблицу, которая читает данные из темы Pub/Sub.
Питон
@dp.table
def pubsub_raw():
auth_options = {
"clientId": client_id,
"clientEmail": client_email,
"privateKey": private_key,
"privateKeyId": private_key_id
}
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.options(auth_options)
.load()
)
SQL
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
clientEmail => secret('pubsub-scope', 'clientEmail'),
clientId => secret('pubsub-scope', 'clientId'),
privateKeyId => secret('pubsub-scope', 'privateKeyId'),
privateKey => secret('pubsub-scope', 'privateKey')
);
Databricks рекомендует использовать секреты при предоставлении параметров авторизации. См. настройку доступа к Pub/Sub для всех параметров аутентификации.
Дополнительные сведения о загрузке данных в потоковую таблицу см. в разделе "Загрузка данных в конвейерах".
Следующая диаграмма иллюстрирует, как работают потоковые таблицы в режиме только добавления.
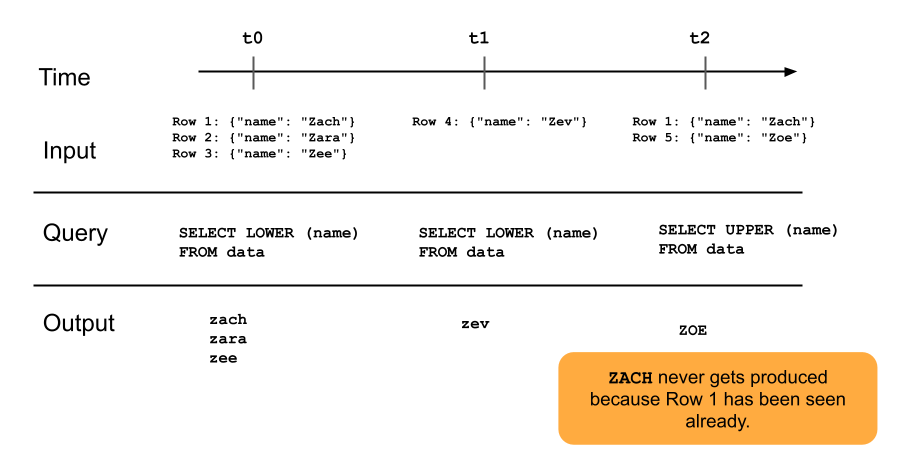
Строка, которая уже добавлена в таблицу потоковой передачи, не будет повторно запрашиваться при последующих обновлениях конвейера. Если изменить запрос (например, из SELECT LOWER (name)SELECT UPPER (name)), существующие строки не будут обновляться в верхнем регистре, но новые строки будут прописными. Вы можете активировать полное обновление для повторного запроса всех предыдущих данных из исходной таблицы, чтобы обновить все строки в таблице потоковой передачи.
Транслирование таблиц и потоковая передача с низкой задержкой
Таблицы потоковой обработки предназначены для потоковой обработки с низкой задержкой при ограниченном состоянии. Потоковые таблицы используют управление контрольными точками, что делает их хорошо подходящими для обработки данных с низкой задержкой в потоковом режиме. Тем не менее, они ожидают потоки, которые естественным образом ограничены или ограничены водяным знаком.
Естественным образом ограниченный поток создается источником потоковых данных, который имеет четко определенное начало и конец. Пример естественно привязанного потока — чтение данных из каталога файлов, в которых новые файлы не добавляются после размещения первоначального пакета файлов. Поток считается ограничивающимся, так как число файлов является конечным, и поток заканчивается после обработки всех файлов.
Вы также можете использовать водяной знак для ограничения потока. Водяной знак в структурированной потоковой передаче — это механизм, который помогает обрабатывать поздние данные, указывая, сколько времени система должна ожидать отложенных событий, прежде чем считать временное окно завершённым. Неограниченный поток, который не имеет метки времени, может привести к сбою конвейера из-за давления на память.
Дополнительные сведения об обработке потоков с сохранением состояния см. в статье Оптимизация обработки с сохранением состояния с помощью водяных знаков.
Соединения потоков и снимков
Объединение потокового набора данных с таблицей измерений, которая фиксируется в момент начала потока. Так как таблица измерений обрабатывается как фиксированная в этот момент времени, любые изменения, внесенные в него после запуска потока, не отражаются в соединении. Это допустимо, если небольшие несоответствия не имеют значения, например, когда количество транзакций на порядки больше числа клиентов.
Следующий пример кода соединяет таблицу параметров с двумя строками, называемыми customers, с переменным набором данных transactions. Он осуществляет соединение между этими двумя наборами данных в таблице под названием sales_report. Если внешний процесс обновляет таблицу клиентов, добавляя новую строку (customer_id=3, name=Zoya), эта новая строка не будет присутствовать в соединении, так как статическая таблица измерений была зафиксирована как снимок состояния при запуске потоков.
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
Ограничения потоковой таблицы
Таблицы потоковой передачи имеют следующие ограничения:
-
Ограниченная эволюция: Запрос можно изменить без повторной компиляции всего набора данных. Без полного обновления таблица потоковой передачи видит только каждую строку один раз, поэтому различные запросы будут обрабатывать разные строки. Например, при добавлении
UPPER()в поле запроса только строки, обработанные после изменения, будут в верхнем регистре. Это означает, что необходимо знать обо всех предыдущих версиях запроса, выполняющихся в наборе данных. Для повторной обработки существующих строк, обработанных до изменения, требуется полное обновление. - Управление состоянием: Потоковые таблицы обеспечивают низкую задержку и требуют потоков, которые естественным образом ограничены или ограничены тайм-кодом. Дополнительные сведения см. в статье "Оптимизация обработки с сохранением состояния с помощью водяных знаков".
- Соединения не перекомпьютерируются: Соединения в таблицах потоковой передачи не перекомпьютерируются при изменении измерений. Эта характеристика может быть хорошей для сценариев "быстро, но неправильно". Если вы хотите, чтобы представление всегда было правильным, может потребоваться использовать материализованное представление. Материализованные представления всегда правильны, так как они автоматически перекомпьютерируют соединения при изменении измерений. Для получения дополнительной информации см. материализованные представления.
-
Нет
CLONEподдержки: таблицы потоковой передачи нельзя использовать в качестве источника или целевого объекта глубокого или мелкого клона. Другие неподдерживаемые команды см. в разделе "Ограничения".