Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как создать и выполнять запросы в векторном поисковом индексе с использованием мозаичного векторного поиска АИ .
Вы можете создавать и управлять компонентами векторного поиска, например конечной точкой векторного поиска и индексами векторного поиска, с помощью пользовательского интерфейса,пакета SDK для Python
Требования
- Рабочая область с включенной поддержкой каталога Unity.
- Бессерверные вычисления включены. Инструкции см. в разделе "Подключение к бессерверным вычислениям".
- Для стандартных конечных точек исходная таблица должна иметь включенный фид изменений данных. См. Использование канала изменений данных Delta Lake в Azure Databricks.
- Чтобы создать индекс векторного поиска, необходимо иметь CREATE TABLE привилегии в схеме каталога, в которой будет создан индекс.
- Чтобы запросить индекс, принадлежащий другому пользователю, необходимо иметь дополнительные привилегии. См. статью "Запрос конечной точки векторного поиска".
Разрешение на создание конечных точек поиска векторов и управление ими настраивается с помощью списков управления доступом. См. списки управления доступом для конечных точек векторного поиска.
Установка
Чтобы использовать пакет SDK для векторного поиска, необходимо установить его в записную книжку. Чтобы установить пакет, используйте следующий код:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Затем используйте следующую команду для импорта VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
Аутентификация
См. сведения о защите и проверке подлинности данных.
Создание конечной точки векторного поиска
Вы можете создать конечную точку векторного поиска с помощью пользовательского интерфейса Databricks, пакета SDK для Python или API.
Создание конечной точки векторного поиска с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать конечную точку векторного поиска с помощью пользовательского интерфейса.
На левой боковой панели щелкните "Вычисления".
Щелкните вкладку "Векторный поиск " и нажмите кнопку "Создать".

Откроется форма создания конечной точки . Введите имя этой конечной точки.
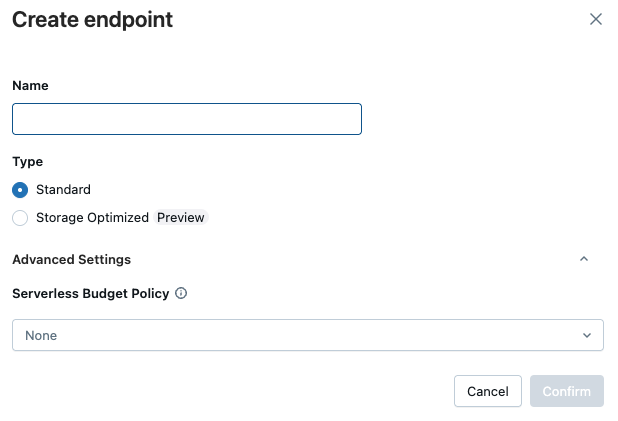
В поле "Тип" выберите "Стандартный " или "Оптимизированный для хранилища". См. параметры конечной точки.
(Необязательно) В разделе "Дополнительные параметры" выберите политику бюджета. См. векторный поиск Mosaic AI: бюджетная политика.
Нажмите кнопку "Подтвердить".
Создание конечной точки векторного поиска с помощью пакета SDK для Python
В следующем примере функция ПАКЕТА SDK create_endpoint() используется для создания конечной точки векторного поиска.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
Создание конечной точки векторного поиска с помощью REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/endpoints.
(Необязательно) Создание и настройка конечной точки для обслуживания модели внедрения
Если вы решили использовать Databricks для вычисления эмбеддингов, вы можете воспользоваться предварительно настроенным конечным узлом API модели Foundation или создать узел обслуживания модели для выбранной вами эмбеддинговой модели. Инструкции см. в API-интерфейсах базовой модели с оплатой за токен или создании конечных точек для обслуживания базовых моделей. Примеры ноутбуков см. в примерах вызова модели встраивания.
При настройке конечной точки внедрения Databricks рекомендует отключить опцию по умолчанию масштабирования до нуля. Активация конечных точек обслуживания может занять несколько минут, и начальный запрос в индексе с уменьшенной конечной точкой может завершиться тайм-аутом.
Заметка
Инициализация индекса векторного поиска может прерваться, если конечная точка встраивания не правильно настроена для набора данных. Для небольших наборов данных и тестов следует использовать только конечные точки ЦП. Для больших наборов данных используйте конечную точку GPU для оптимальной производительности.
Создание индекса векторного поиска
Индекс векторного поиска можно создать с помощью пользовательского интерфейса, пакета SDK Для Python или REST API. Пользовательский интерфейс — это самый простой подход.
Существует два типа индексов:
- Индекс разностной синхронизации автоматически синхронизируется с исходной таблицей Delta, автоматически и поэтапно обновляя индекс при изменении базовых данных в таблице Delta.
- Индекс прямого векторного доступа поддерживает прямое чтение и запись векторов и метаданных. Пользователь отвечает за обновление этой таблицы с помощью REST API или пакета SDK для Python. Этот тип индекса нельзя создать с помощью пользовательского интерфейса. Необходимо использовать REST API или пакет SDK.
Заметка
Имя столбца _id зарезервировано. Если в исходной таблице есть столбец с именем _id, переименуйте его перед созданием векторного индекса поиска.
Создание индекса с помощью пользовательского интерфейса
На левой боковой панели щелкните "Каталог ", чтобы открыть пользовательский интерфейс обозревателя каталогов.
Перейдите к таблице Delta, которую вы хотите использовать.
Нажмите кнопку "Создать " в правом верхнем углу и выберите индекс векторного поиска в раскрывающемся меню.

Используйте селекторы в диалоговом окне для настройки индекса.

Имя: имя, используемое для интерактивной таблицы в каталоге Unity. Для имени требуется трехуровневое пространство имен,
<catalog>.<schema>.<name>. Разрешены только буквенно-цифровые символы и символы подчеркивания.Первичный ключ: столбец для использования в качестве первичного ключа.
Конечная точка. Выберите конечную точку поиска векторов, которую вы хотите использовать.
Столбцы для синхронизации: (поддерживается только для стандартных конечных точек.) Выберите столбцы для синхронизации с векторным индексом. Если оставить это поле пустым, все столбцы из исходной таблицы синхронизируются с индексом. Столбец первичного ключа и столбец источника встраивания или столбец встраиваемого вектора всегда синхронизированы. Для конечных точек, оптимизированных для хранения, все столбцы из исходной таблицы всегда синхронизируются.
Встраивание источника: Укажите, хотите ли вы, чтобы Databricks вычислил встраивания для текстового столбца в таблице Delta (вычислить встраивания) или если ваша таблица Delta содержит предварительно вычисленные встраивания (использовать существующий столбец с встраиваниями).
- Если вы выбрали внедрение вычислений, выберите столбец, для которого вы хотите внедрить данные, и конечную точку, обслуживающую модель внедрения. Поддерживаются только текстовые столбцы. Для производственных приложений Databricks рекомендует использовать базовую модель
databricks-gte-large-enсо сконфигурированной конечной точкой обслуживания с высокой пропускной способностью. - При выборе "Использовать существующий столбец встраивания", выберите столбец, содержащий предварительно вычисленные встраивания и измерение встраивания. Формат предварительно вычисляемого столбца встраивания должен быть
array[float]. Для конечных точек, оптимизированных для хранения, измерение внедрения должно быть равномерно разделено на 16.
Синхронизация вычисляемых представлений: Включите или выключите этот параметр, чтобы сохранить созданные представления в таблицу каталога Unity. Дополнительные сведения см. в статье "Сохранить созданную таблицу внедрения".
Режим синхронизации: непрерывный режим сохраняет индекс в синхронизации с секундами задержки. Однако она имеет более высокую стоимость, так как вычислительный кластер подготавливается для запуска канала непрерывной передачи данных для синхронизации. Для стандартных конечных точек непрерывное и триггерное выполнение добавочных обновлений позволяет обрабатывать только данные, которые изменились с момента последней синхронизации. Для конечных точек, оптимизированных для хранения, каждая синхронизация полностью перестраивает индекс векторного поиска. Ознакомьтесь с ограничениями конечных точек, оптимизированных для хранения.
В режиме синхронизации с активацией вы используете пакет SDK для Python или REST API для запуска синхронизации. См . раздел "Обновление индекса разностной синхронизации".
Для конечных точек, оптимизированных для хранения, поддерживается только режим синхронизации с активацией .
- Если вы выбрали внедрение вычислений, выберите столбец, для которого вы хотите внедрить данные, и конечную точку, обслуживающую модель внедрения. Поддерживаются только текстовые столбцы. Для производственных приложений Databricks рекомендует использовать базовую модель
Завершив настройку индекса, нажмите кнопку "Создать".
Создание индекса с помощью пакета SDK для Python
В следующем примере создается индекс Delta-синхронизации с встраиваниями, вычисленными с помощью Databricks. Дополнительные сведения см. в справочнике по пакету SDK для Python.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
В следующем примере создается индекс Delta Sync с самоуправляемыми встраиваниями. В этом примере также показано использование необязательного параметра columns_to_sync для выбора только подмножества столбцов, используемых в индексе.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
По умолчанию все столбцы из исходной таблицы синхронизируются с индексом.
В стандартных конечных точках можно выбрать подмножество столбцов для синхронизации с помощью columns_to_sync. Первичный ключ и столбцы с эмбеддингами всегда включаются в индекс.
Чтобы синхронизировать только первичный ключ и столбец для встраивания, необходимо указать их в columns_to_sync как показано.
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Чтобы синхронизировать дополнительные столбцы, укажите их, как показано ниже. Не нужно включать первичный ключ и столбец встраивания, так как они всегда синхронизируются.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
В следующем примере создается индекс прямого векторного доступа.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Создание индекса с помощью REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/indexes.
Сохранить созданную таблицу внедрения
Если Databricks создает встраивания, можно сохранить созданные встраивания в таблице в каталоге Unity. Эта таблица создается в той же схеме, что и векторный индекс и связана с страницей векторного индекса.
Имя таблицы — это имя индекса векторного поиска с добавлением _writeback_table. Имя не редактируется.
Вы можете получить доступ и запросить таблицу, как и любую другую таблицу в каталоге Unity. Однако не следует удалять или изменять таблицу, так как она не предназначена для обновления вручную. Таблица удаляется автоматически, если индекс удаляется.
Обновление индекса векторного поиска
Обновление индекса разностной синхронизации
Индексы, созданные в режиме непрерывной синхронизации , автоматически обновляются при изменении исходной таблицы Delta. Если вы используете режим синхронизации с активацией , можно запустить синхронизацию с помощью пользовательского интерфейса, пакета SDK python или REST API.
Пользовательский интерфейс Databricks
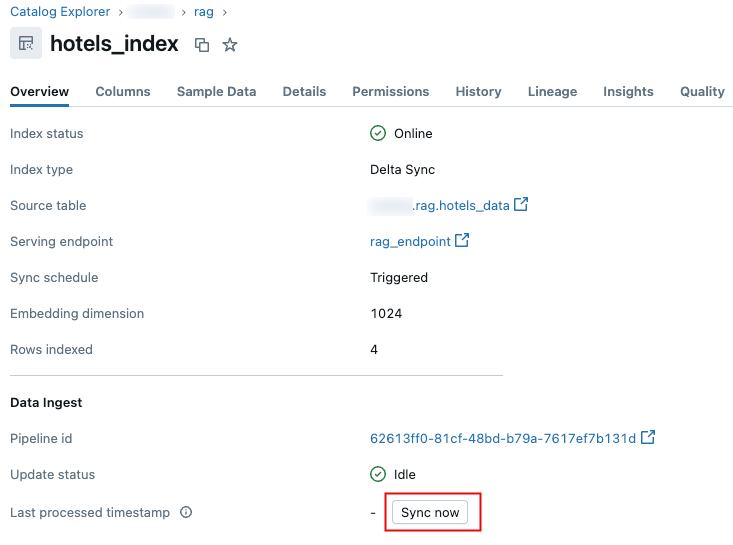
В обозревателе каталогов перейдите к индексу векторного поиска.
На вкладке "Обзор" в разделе " Прием данных " нажмите кнопку "Синхронизировать сейчас".
 .
.
Python SDK
Дополнительные сведения см. в справочнике по пакету SDK для Python.
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Обновление индекса прямого векторного доступа
Пакет SDK для Python или REST API можно использовать для вставки, обновления или удаления данных из индекса прямого векторного доступа.
Python SDK
Дополнительные сведения см. в справочнике по пакету SDK для Python.
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/indexes.
Для рабочих приложений Databricks рекомендует использовать служебные учетные записи вместо личных токенов доступа. Производительность можно улучшить на величину до 100 мс на запрос.
В следующем примере кода показано, как обновить индекс с помощью учетной записи службы.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
В следующем примере кода показано, как обновить индекс с помощью персонального токена доступа (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Запрос конечной точки векторного поиска
Вы можете запрашивать только конечную точку векторного поиска с помощью пакета SDK для Python, REST API или функции SQL vector_search() ИИ.
Заметка
Если пользователь, запрашивающий конечную точку, не является владельцем индекса векторного поиска, пользователь должен иметь следующие права UC:
- USE CATALOG в каталоге, который содержит индекс векторного поиска.
- USE SCHEMA на схеме, содержащей индекс векторного поиска.
- SELECT в индексе векторного поиска.
Тип запроса по умолчанию — ( ann приблизительный ближайший сосед). Чтобы выполнить поиск сходства с гибридными ключевыми словами, задайте параметру query_type значение hybrid. При гибридном поиске включены все столбцы метаданных текста, а возвращается не более 200 результатов.
Стандартная конечная точка пакета SDK для Python
Дополнительные сведения см. в справочнике по пакету SDK для Python.
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "field2"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "field2"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.9] * 1024,
columns=["id", "text"],
num_results=2
)
Конечная точка, оптимизированная для хранения пакета SDK для Python
Дополнительные сведения см. в справочнике по пакету SDK для Python.
Существующий интерфейс фильтра был перепроектирован для индексов векторного поиска, оптимизированных по хранилищу, чтобы использовать строку фильтра, более похожую на SQL, вместо словаря фильтров, применяемого в стандартных конечных точках векторного поиска.
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
# similarity search with query vector
results = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
# similarity search with query vector and filter string
results = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
# this is a single filter string similar to SQL WHERE clause syntax
filters="language = 'en' AND country = 'us'",
num_results=2
)
REST API
См. справочную документацию по REST API: POST /api/2.0/vector-search/indexes/{index_name}/query.
Для рабочих приложений Databricks рекомендует использовать служебные учетные записи вместо личных токенов доступа. Помимо улучшения управления безопасностью и доступом, использование служебных учетных записей может повысить производительность на запросах до 100 миллисекунд.
В следующем примере кода показано, как выполнить запрос к индексу с использованием сервисного аккаунта.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint, then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query vector search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query vector search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
В следующем примере кода показано, как запрашивать индекс с помощью токена личного доступа (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query vector search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query vector search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Важный
Функция vector_search() ИИ доступна в общедоступной предварительной версии.
Чтобы использовать эту функцию ИИ, см vector_search функцию.
Использовать фильтры для запросов
Запрос может определять фильтры на основе любого столбца в таблице Delta.
similarity_search возвращает только строки, соответствующие указанным фильтрам.
В следующей таблице перечислены поддерживаемые фильтры.
| Оператор фильтра | Поведение | Примеры |
|---|---|---|
NOT |
Стандартный: отрицает фильтр. Ключ должен заканчиваться значением NOT. Например, "цвет НЕ" со значением "красный" соответствует документам, где цвет не красный. Оптимизировано для хранения: см. оператор != (знак неравенства). |
Стандартный:{"id NOT": 2}{“color NOT”: “red”}Оптимизировано для хранения: "id != 2" "color != 'red'" |
< |
Стандартный: проверяет, меньше ли значение поля, чем значение фильтра. Ключ должен заканчиваться "<". Например, "цена <" со значением 200 соответствует документам, где цена меньше 200. Оптимизировано для хранения: <. |
Стандартный:{"id <": 200}Оптимизировано для хранения: "id < 200" |
<= |
Стандартный: проверяет, меньше ли значение поля или равно значению фильтра. Ключ должен заканчиваться "<=". Например, "цена <=" со значением 200 соответствует документам, где цена меньше или равна 200. Оптимизировано для хранения: см. оператор <= (знак меньше или равно). |
Стандартный:{"id <=": 200}Оптимизировано для хранения: "id <= 200" |
> |
Стандартный: проверяет, больше ли значение поля, чем значение фильтра. Ключ должен заканчиваться ">". Например, "цена >" со значением 200 соответствует документам, где цена превышает 200. Оптимизировано для хранения: см > . оператор подписи (gt). |
Стандартный:{"id >": 200}Оптимизировано для хранения: "id > 200" |
>= |
Стандартный: проверяет, больше ли значение поля или равно значению фильтра. Ключ должен заканчиваться ">=". Например, "цена >=" со значением 200 соответствует документам, где цена больше или равно 200. Оптимизировано для хранения: см. >=. |
Стандартный:{"id >=": 200}Оптимизировано для хранения: "id >= 200" |
OR |
Стандартный: проверяет, соответствует ли значение поля любому из значений фильтра. Ключ должен содержать OR для разделения нескольких подключей. Например, color1 OR color2 со значением ["red", "blue"] соответствует документам, где color1red или color2blue.Оптимизировано для хранения: см. or оператор. |
Стандартный:{"color1 OR color2": ["red", "blue"]}Оптимизировано для хранения: "color1 = 'red' OR color2 = 'blue'" |
LIKE |
Стандартный: соответствует маркерам, разделенным пробелами, в строке. См. приведенные ниже примеры кода. Оптимизировано для хранения: см. like оператор. |
Стандартный:{"column LIKE": "hello"}Оптимизировано для хранения: "column LIKE 'hello'" |
| Оператор фильтра не указан |
Стандартный: фильтр проверяет точное совпадение. Если задано несколько значений, он соответствует любому из значений. Оптимизировано для хранения: см. = (оператор знака равенства) и in предикат. |
Стандартный:{"id": 200}{"id": [200, 300]}Оптимизировано для хранения: "id = 200""id IN (200, 300)" |
to_timestamp (только оптимизированные для хранения конечные точки) |
Оптимизировано для хранения: фильтрация по метке времени. См. to_timestamp функции |
Оптимизировано для хранения: "date > TO_TIMESTAMP('1995-01-01')" |
См. следующие примеры кода:
Стандартная конечная точка пакета SDK для Python
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
Конечная точка, оптимизированная для хранения пакета SDK для Python
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters='title IN ("Ares", "Athena")',
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters='title = "Ares" OR id = "Athena"',
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters='title != "Hercules"',
num_results=2
)
REST API
См. раздел POST /api/2.0/vector-search/indexes/{index_name}/query.
Нравится
LIKE Примеры
{"column LIKE": "apple"}: совпадает с строками "apple" и "apple pear", но не совпадает с "ананас" или "груша". Обратите внимание, что он не соответствует "ананасу", хотя содержит подстроку "apple" --- он ищет точное совпадение среди маркеров, разделенных пробелом, как в "apple pear".
{"column NOT LIKE": "apple"} делает противоположное. Он соответствует "ананасу" и "груше", но не соответствует "яблоко" или "яблоко груши".
примеры записных книжек
В примерах этого раздела демонстрируется использование пакета SDK для поиска векторов Python. Справочные сведения см. в справочнике по пакету SDK для Python.
Примеры LangChain
Узнайте , как использовать LangChain с векторным поиском Mosaic AI для интеграции с пакетами LangChain.
В следующем блокноте показано, как преобразовать результаты поиска сходства в документы LangChain.
Векторный поиск с помощью блокнота Python SDK
Примеры ноутбуков для вызова модели эмбеддингов
В следующих записных книжках показано, как настроить конечную точку обслуживания модели Mosaic AI для генерации эмбеддингов.