Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
Запустите конвейеры Azure Machine Learning в качестве шага в конвейерах Azure Data Factory и Synapse Analytics. Действие Machine Learning Execute Pipeline позволяет выполнять сценарии пакетного прогноза, такие как выявление возможных дефолтов по кредитам, определение тональности и анализ шаблонов поведения клиентов.
В приведенном ниже шестиминутном видеоролике рассказывается об этой функции и представлена демонстрация ее возможностей.
Создание действия выполнения конвейера машинного обучения с пользовательским интерфейсом
Чтобы использовать действие Machine Learning Execute Pipeline в конвейере, выполните следующие действия:
Найдите Machine Learning в области действий конвейера и перетащите действие "Выполнение конвейера Machine Learning" на холст конвейера.
Выберите новое действие Выполнение конвейера Machine Learning на холсте, если оно еще не выбрано, и вкладку Settings, чтобы изменить его параметры.
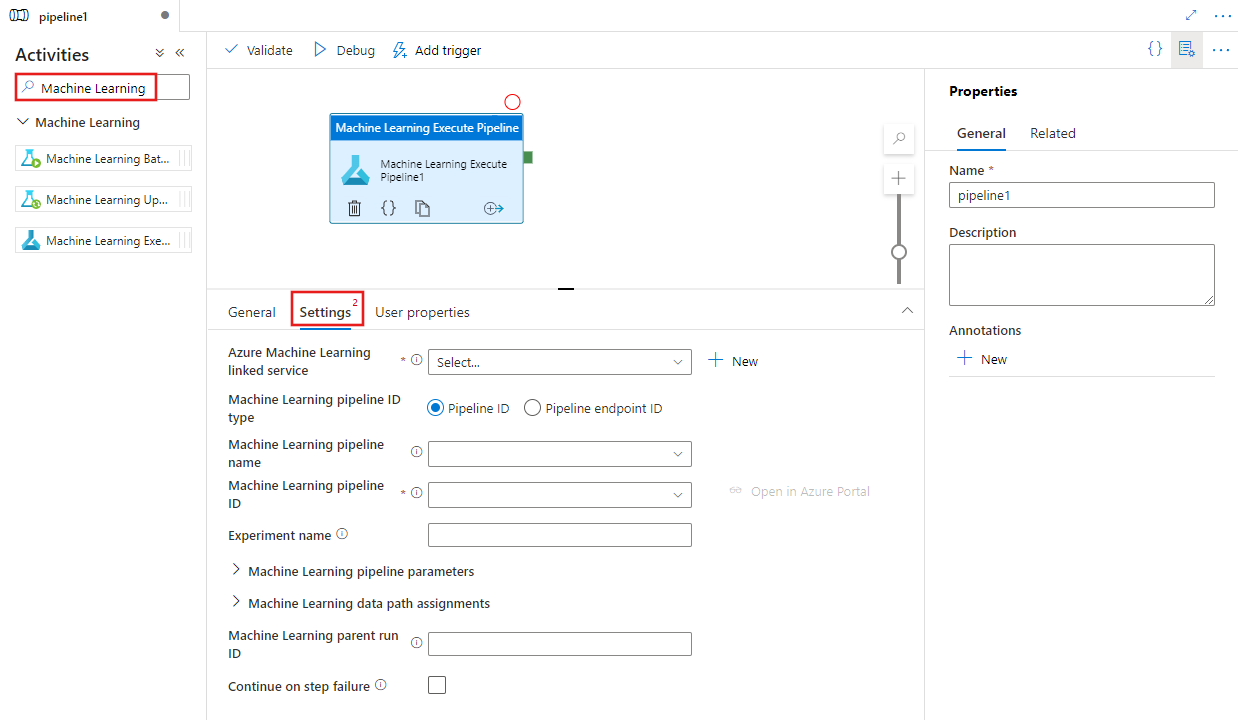
Выберите существующую или создайте связанную службу Azure Machine Learning и укажите сведения о конвейере и эксперименте, а также все параметры конвейера или назначения пути данных, необходимые для конвейера.
Синтаксис
{
"name": "Machine Learning Execute Pipeline",
"type": "AzureMLExecutePipeline",
"linkedServiceName": {
"referenceName": "AzureMLService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mlPipelineId": "machine learning pipeline ID",
"experimentName": "experimentName",
"mlPipelineParameters": {
"mlParameterName": "mlParameterValue"
}
}
}
Свойства типа
| Свойство | Описание | Допустимые значения | Обязательное поле |
|---|---|---|---|
| имя | Имя действия в конвейере. | Строка | Да |
| тип | Тип действия — "AzureMLExecutePipeline" | Строка | Да |
| linkedServiceName | Связанная служба с Azure Machine Learning | Ссылка на связанную службу | Да |
| mlPipelineId | Идентификатор опубликованного конвейера Azure Machine Learning | Строка (или выражение с типом результата "строка") | Да |
| название эксперимента | Имя эксперимента журнала выполнения запуска конвейера Machine Learning | Строка (или выражение с типом результата "строка") | Нет |
| mlPipelineParameters | Пары "ключ-значение", которые должны быть переданы в опубликованную конечную точку конвейера машинного обучения Azure. Ключи должны соответствовать именам параметров конвейера, определенных в опубликованном конвейере Machine Learning | Объект с парами "ключ-значение" (или выражение с объектом типа результат) | Нет |
| mlParentRunId | Идентификатор родительского запуска конвейера Azure Machine Learning | Строка (или выражение с типом результата "строка") | Нет |
| dataPathAssignments | Словарь, используемый для изменения путей данных в Azure Machine Learning. Включает переключение каналов данных | Объект с парами ключ-значение | Нет |
| continueOnStepFailure | Продолжать ли выполнение других шагов в конвейере машинного обучения, если один из шагов завершится сбоем | boolean | Нет |
Примечание.
Чтобы заполнить выпадающий список для имени и идентификатора конвейера в Machine Learning, пользователю необходимо иметь разрешение на просмотр списка конвейеров машинного обучения. Пользовательский интерфейс вызывает интерфейсы API AzureMLService напрямую, используя учетные данные пользователя, вошедшего в систему. Время обнаружения элементов выпадающего списка значительно увеличится при использовании частных конечных точек.
Связанный контент
Ознакомьтесь со следующими ссылками, в которых описаны способы преобразования данных другими способами: