Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Чтобы перенести реляционную базу данных в Azure Cosmos DB для NoSQL, можно внести изменения в модель данных для оптимизации.
Одним из распространенных преобразований является денормализация данных путем внедрения связанных подобъектов в один документ JSON. Здесь мы рассмотрим несколько вариантов использования Фабрики данных Azure или Azure Databricks. Дополнительные сведения о моделировании данных для Azure Cosmos DB см. в статье об моделировании данных в Azure Cosmos DB.
Пример сценария
Предположим, что в нашей базе данных SQL есть две таблицы: Orders и OrderDetails.

Мы хотим объединить данную связь "один к нескольким" в один JSON-документ во время миграции. Чтобы создать один документ, создайте запрос T-SQL с помощью FOR JSON:
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
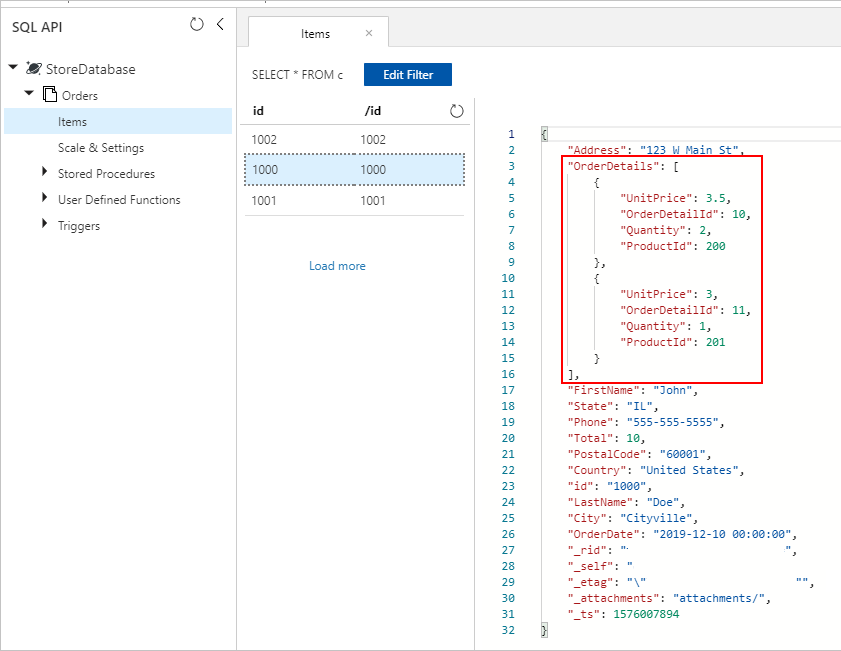
Результаты этого запроса будут содержать данные из таблицы Orders :

В идеале необходимо использовать одно действие копирования фабрики данных Azure (ADF) для запроса данных SQL в качестве источника и записи выходных данных непосредственно в приемник Azure Cosmos DB в качестве соответствующих объектов JSON. В настоящее время невозможно выполнить необходимое преобразование JSON в одном действии копирования. Если мы попытаемся скопировать результаты приведенного выше запроса в контейнер Azure Cosmos DB для NoSQL, то поле OrderDetails отображается как строковое свойство нашего документа, а не ожидаемый массив JSON.
Мы можем обойти это текущее ограничение одним из следующих способов:
-
Используйте Azure Data Factory с двумя операциями копирования:
- Получите данные в формате JSON из SQL в текстовый файл в промежуточном расположении BLOB-хранилища
- Загрузите данные из текстового файла JSON в контейнер в Azure Cosmos DB.
- Используйте Azure Databricks для чтения из SQL и записи в Azure Cosmos DB . Здесь представлены два варианта.
Рассмотрим эти подходы более подробно:
Фабрика данных Azure
Хотя мы не можем внедрить OrderDetails в виде массива JSON в целевом документе Azure Cosmos DB, мы можем обойти проблему с помощью двух отдельных действий копирования.
Действие копирования #1: "SqlJsonToBlobText"
Для исходных данных мы используем SQL-запрос, чтобы получить результирующий набор в виде одного столбца с одним объектом JSON (представляющий порядок) для каждой строки с помощью возможностей SQL Server OPENJSON и FOR JSON PATH:
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)

Для приемника SqlJsonToBlobText действия копирования мы выбираем "Разделителя текста" и указываем его на определенную папку в хранилище BLOB-объектов Azure. Этот приемник включает динамически созданное уникальное имя файла (например, @concat(pipeline().RunId,'.json').
Поскольку наш текстовый файл на самом деле не является "разделённым", мы не хотим, чтобы его анализировали на отдельные столбцы с помощью запятых. Мы также хотим сохранить двойные кавычки ("), установить для "Разделителя столбцов" значение "Tab ('\t')" или другой символ, не встречающийся в данных, а затем установить для "Символа кавычки" значение "Без символа кавычки".

Действие копирования #2: "BlobJsonToCosmos"
Затем мы изменим конвейер ADF, добавив второе действие копирования, которое ищет в хранилище Azure Blob Storage текстовый файл, созданный первым действием. Он обрабатывает его как источник JSON, чтобы вставить в приемник Azure Cosmos DB как один документ на строку JSON, найденную в текстовом файле.

При необходимости мы также добавим действие Delete в конвейер, чтобы удалить все предыдущие файлы, оставшиеся в папке /Orders/ перед каждым запуском. Теперь наш конвейер ADF выглядит примерно так:

После запуска упомянутого ранее конвейера мы видим файл, созданный в нашем промежуточном расположении блоб-хранилища Azure, содержащий один JSON-объект на строку.

Кроме того, мы видим документы Orders с правильно внедренными OrderDetails, включенными в коллекцию Azure Cosmos DB:

Azure Databricks
Мы также можем использовать Spark в Azure Databricks для копирования данных из источника базы данных SQL в назначение Azure Cosmos DB без создания промежуточных текстовых и JSON-файлов в хранилище BLOB-объектов Azure.
Замечание
Для ясности и простоты фрагменты кода включают в себя фиктивные пароли базы данных, вставленные прямо в код, но в идеале следует использовать секреты Azure Databricks.
Сначала мы создадим и присоединяем необходимый соединитель SQL и библиотеки соединителей Azure Cosmos DB к кластеру Azure Databricks. Перезапустите кластер, чтобы убедиться, что библиотеки загружены.

Далее мы представляем два примера для Scala и Python.
Scala
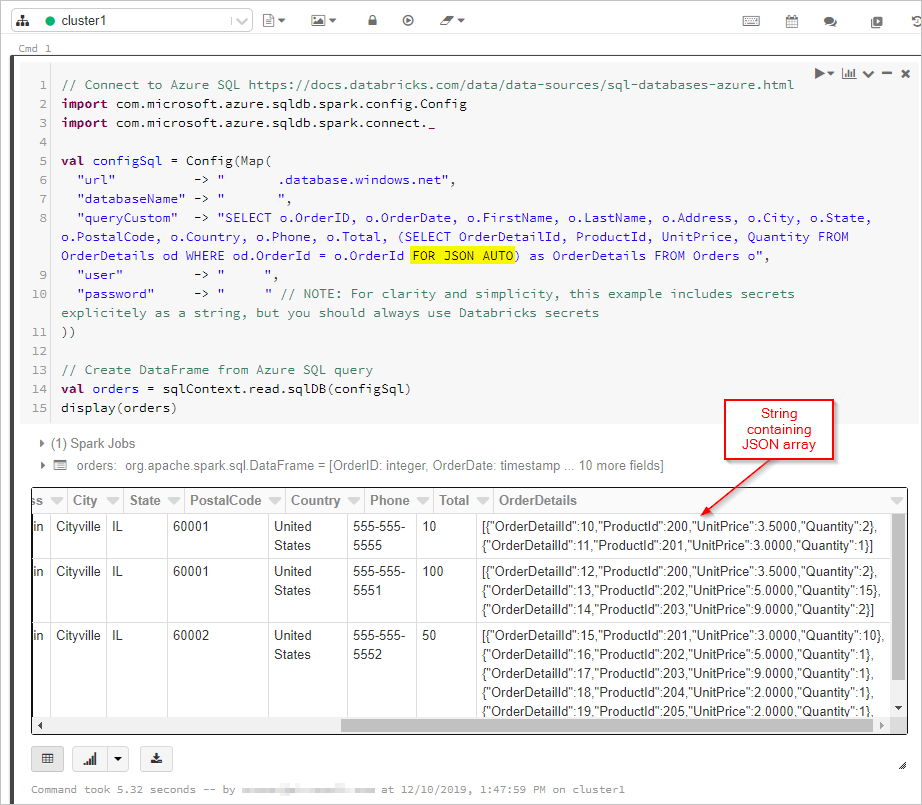
Здесь мы получаем результаты SQL-запроса в формате FOR JSON в DataFrame.
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
Затем мы подключаемся к базе данных и коллекции Azure Cosmos DB:
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
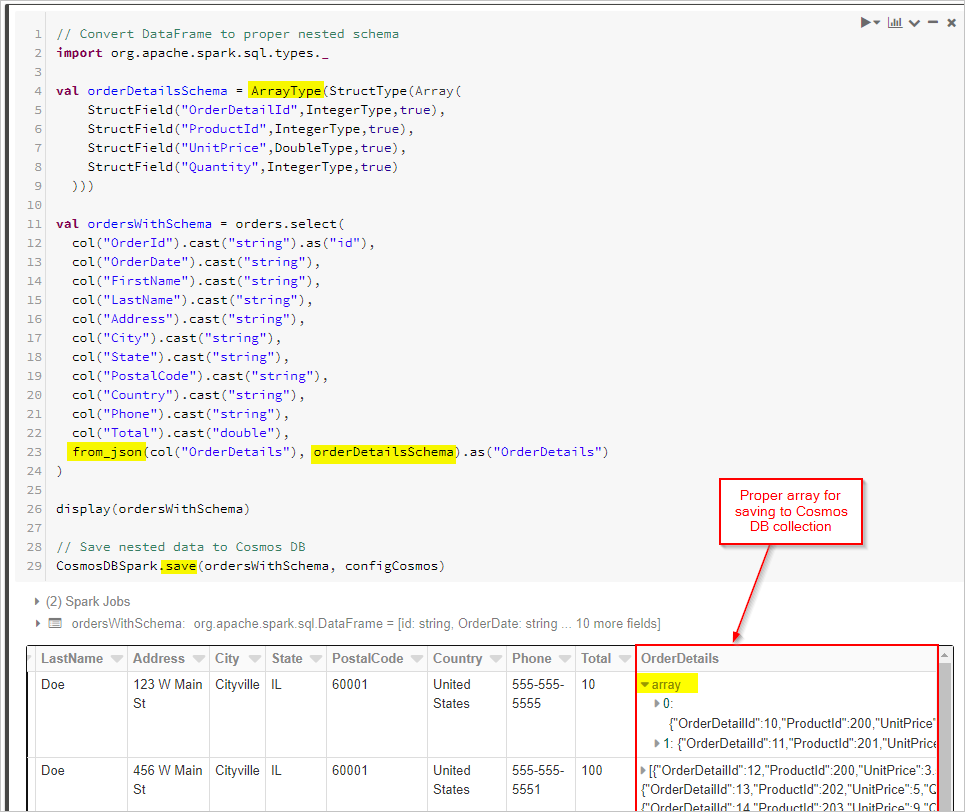
Наконец, мы определяем нашу схему и применяем функцию from_json для преобразования DataFrame перед его сохранением в коллекцию Cosmos DB.
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
Питон
В качестве альтернативного подхода может потребоваться выполнить преобразования JSON в Spark, если исходная база данных не поддерживает FOR JSON или аналогичную операцию. Кроме того, можно использовать параллельные операции для большого набора данных. Здесь представлен пример PySpark. Начните с настройки подключений к исходной и целевой базе данных в первой ячейке:
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
Затем мы запрашиваем исходную базу данных (в данном случае SQL Server) для получения записей заказов и записей подробностей заказов, помещая результаты в Spark DataFrame. ** Мы также создадим список, содержащий все идентификаторы заказов, и пул потоков для параллельных операций.
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
Затем создайте функцию для записи заказов в целевой API для коллекции NoSQL. Эта функция фильтрует сведения о всех заказах для заданного идентификатора заказа, преобразует их в массив JSON и вставляет массив в JSON-документ. Затем документ JSON записывается в целевой контейнер API для NoSQL для этого заказа:
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
Наконец, мы вызываем Python функцию writeOrder с использованием функции map в пуле потоков для параллельного выполнения, передавая в него список идентификаторов заказов, созданных ранее.
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
В любом случае в конце мы должны получить правильно сохранённые встроенные `OrderDetails` в каждом документе `Order` в коллекции `Azure Cosmos DB`.