Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Оповещения в Azure Monitor упреждающе определяют проблемы, связанные с работоспособностью и производительностью ресурсов Azure. В этой статье описывается, как включить и изменить набор рекомендуемых правил генерации оповещений метрик, предопределенных для кластеров Kubernetes.
Включите рекомендуемые правила генерации оповещений
Используйте один из следующих методов, чтобы включить рекомендуемые правила генерации оповещений для кластера. Вы можете включить правила оповещений метрик Prometheus и платформы для одного кластера.
Примечание.
Рекомендуемые оповещения для кластеров Kubernetes с включенным Arc находятся в предварительной версии и не поддерживают правила оповещений платформенных метрик.
Группа правил Prometheus будет создана с помощью портала Azure в том же регионе, что и кластер.
В меню "Оповещения" для кластера выберите пункт "Настройка рекомендаций".

Доступные правила оповещений Prometheus и платформы отображаются, при этом правила Prometheus организованы по подам, кластерам и уровням узлов. Переключите группу правил Prometheus, чтобы включить этот набор правил. Разверните группу, чтобы увидеть отдельные правила. Вы можете оставить значения по умолчанию или отключить отдельные правила и изменить их имя и серьезность.
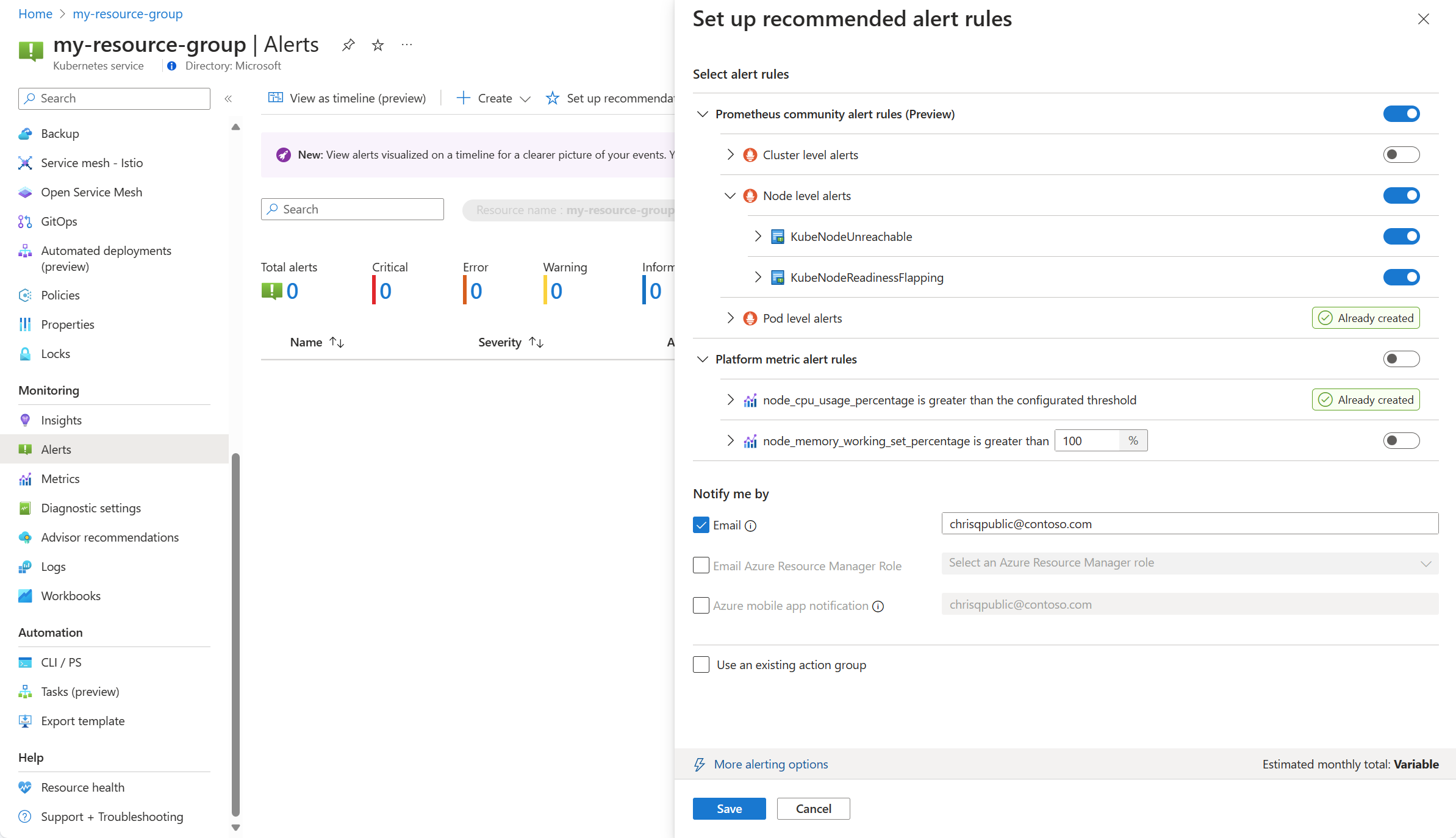
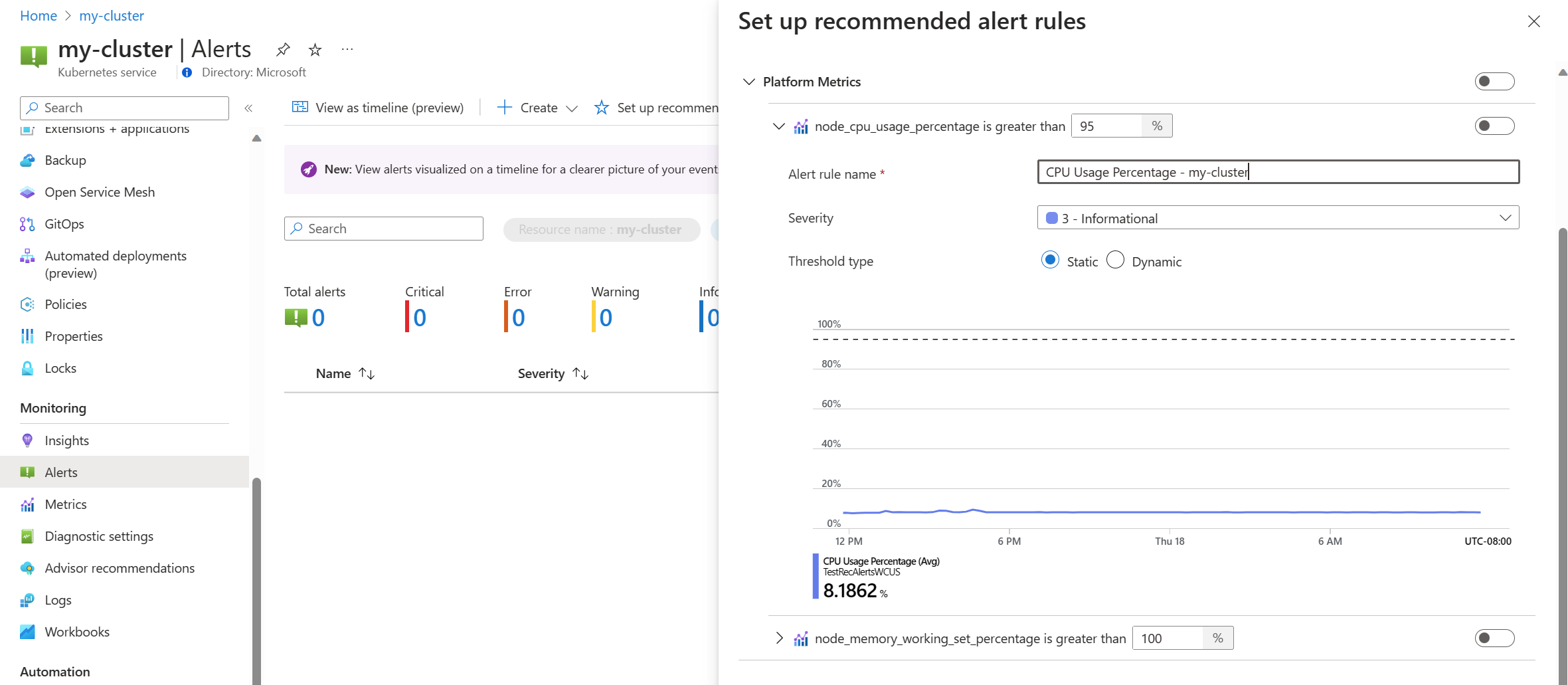
Переключите правило метрик платформы, чтобы включить это правило. Вы можете расширить правило, чтобы изменить его параметры, такие как название, серьезность и пороговое значение.
Выберите один или несколько методов уведомлений для создания новой группы действий или выберите существующую группу действий с сведениями о уведомлении для этого набора правил генерации оповещений.
Нажмите кнопку "Сохранить", чтобы сохранить группу правил.



Подсказка
Рекомендуется также включить рекомендуемые оповещения для рабочей области Azure Monitor, в которой используются метрики Prometheus. Эти оповещения позволяют отслеживать ограничения приема и квоты и избегать регулирования метрик. Сведения о включении этих рекомендуемых оповещений см. в статье "Настройка рекомендуемых оповещений для рабочей области Azure Monitor".
Изменение рекомендуемых правил генерации оповещений
После создания группы правил нельзя использовать ту же страницу на портале для изменения правил. Для метрик Prometheus необходимо изменить группу правил, чтобы изменить в ней все правила, включая включение всех правил, которые еще не включены. Для метрик платформы можно изменить каждое правило генерации оповещений.
В меню "Оповещения" для кластера выберите пункт "Настройка рекомендаций". Все созданные правила или группы правил будут помечены как уже созданные.
Разверните правило или группу правил. Щелкните Посмотреть группу правил для Prometheus и Просмотреть правило оповещения для метрик платформы.
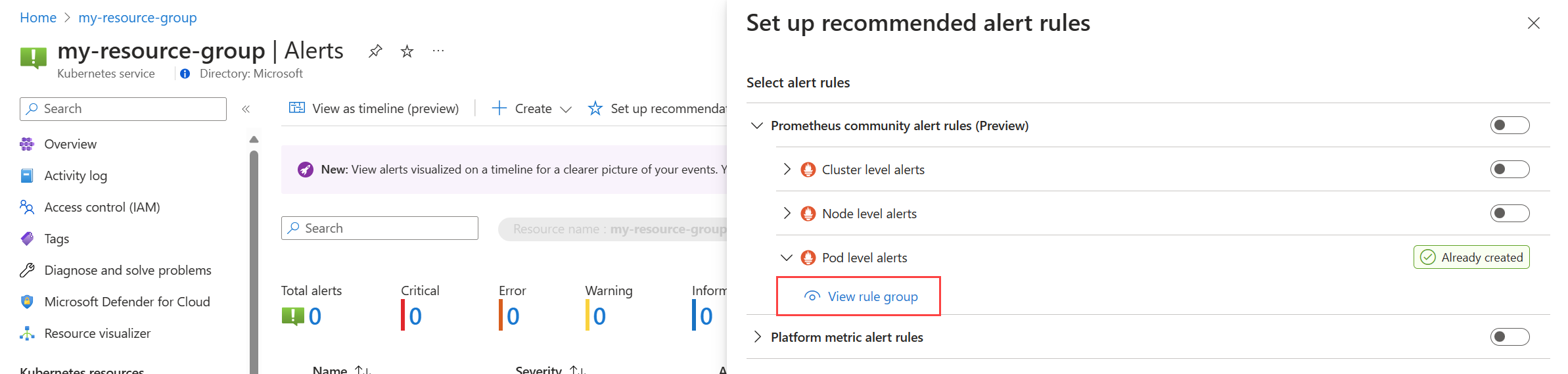
Для групп правил в системе Prometheus:
Выберите правила для просмотра правил генерации оповещений в группе.
Щелкните значок "Изменить" рядом с правилом, которое требуется изменить. Используйте инструкции из статьи "Создание правила генерации оповещений" для изменения правила.
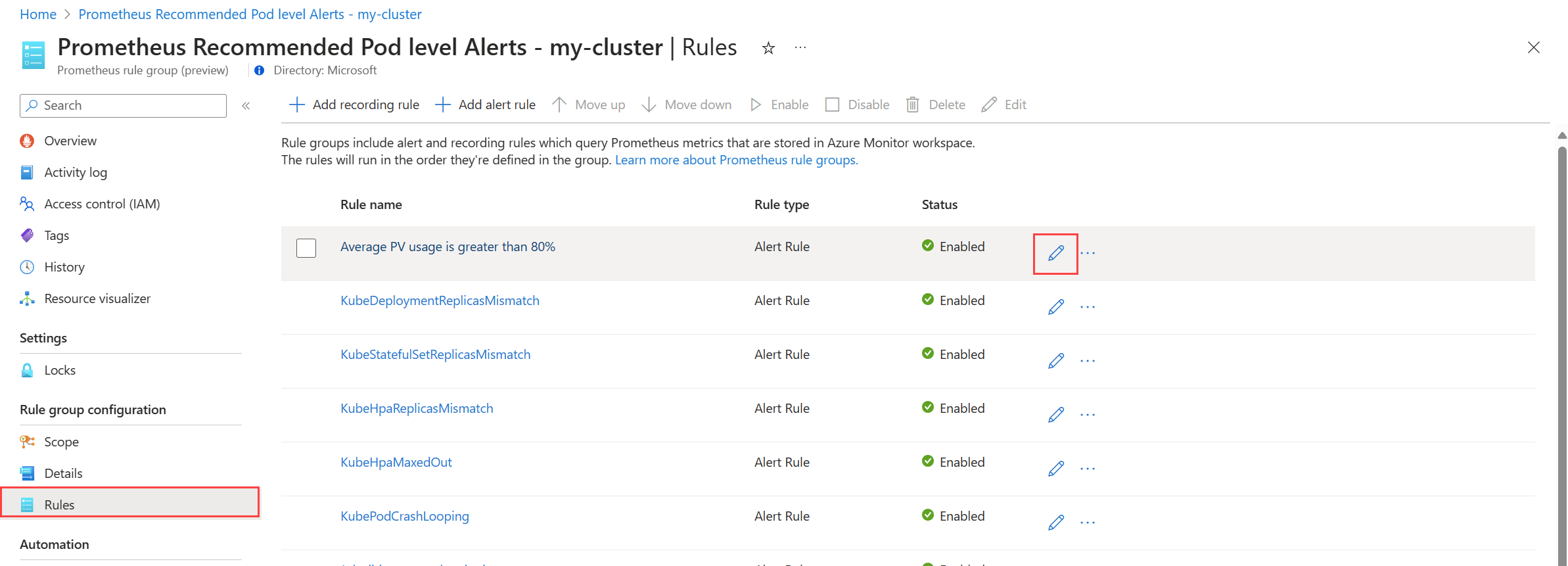
После завершения редактирования правил в группе нажмите кнопку "Сохранить ", чтобы сохранить группу правил.
Для метрик платформы:
Нажмите кнопку "Изменить", чтобы открыть сведения для правила генерации оповещений. Используйте инструкции из статьи "Создание правила генерации оповещений" для изменения правила.




Отключение группы правил генерации оповещений
Отключите группу правил, чтобы прекратить поступление предупреждений от содержащихся в ней правил.
Просмотрите группу правил оповещений Prometheus или правило метрики платформы, как описано в разделе "Редактирование рекомендуемых правил оповещений".
В меню "Обзор" выберите "Отключить".

Рекомендуемые детали правила оповещения
В следующих таблицах перечислены сведения о каждом рекомендуемом правиле генерации оповещений. Исходный код для каждого из них доступен в GitHub , а также руководства по устранению неполадок из сообщества Prometheus.
Правила генерации оповещений сообщества Prometheus
Оповещения на уровне кластера
| Имя оповещения | Описание | Порог по умолчанию | Временной интервал (минуты) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | Квота ресурсов ЦП, выделенная пространствам имен, превышает доступные ресурсы ЦП на узлах кластера более чем на 50 % за последние 5 минут. | >1.5 | 5 |
| Квота памяти Kubernetes с переполнением | Квота ресурса памяти, выделенная пространствам имен, превышает доступные ресурсы памяти на узлах кластера более чем на 50 % за последние 5 минут. | >1.5 | 5 |
| KubeContainerOOMKilledCount (количество случаев завершения процессов контейнера Kube из-за нехватки памяти) | Один или несколько контейнеров в модулях pod были убиты из-за отсутствия памяти (OOM) событий за последние 5 минут. | >0 | 5 |
| KubeClientErrors | Скорость ошибок клиента (коды состояния HTTP начиная с 5xx) в запросах API Kubernetes превышает 1% от общей частоты запросов API за последние 15 минут. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | Постоянный том заполняется и, как ожидается, истекает доступное пространство, вычисляемое на доступном соотношении пространства, используемом пространстве и прогнозируемой линейной тенденции доступного пространства за последние 6 часов. Эти условия оцениваются за последние 60 минут. | Н/П | шестьдесят |
| KubePersistentVolumeInodesFillingUp | За последние 15 минут доступны менее 3 % инодов в постоянном объёме. | <0.03 | 15 |
| Ошибки KubePersistentVolume | Один или несколько постоянных томов находятся на этапе сбоя или ожидания за последние 5 минут. | >0 | 5 |
| KubeContainerWaiting | Один или несколько контейнеров в подах Kubernetes находятся в состоянии ожидания в течение последних 60 минут. | >0 | шестьдесят |
| KubeDaemonSet не запланирован | Один или несколько модулей pod не запланированы на любом узле за последние 15 минут. | >0 | 15 |
| KubeDaemonSetMisScheduled (ошибка неверного расписания DaemonSet в Kubernetes) | Один или несколько подов неправильно запланированы в кластере за последние 15 минут. | >0 | 15 |
| Kube-квота почти заполнена | Использование квот ресурсов Kubernetes составляет от 90% до 100% от жестких ограничений за последние 15 минут. | >0.9 <1 | 15 |
Оповещения на уровне узла
| Имя оповещения | Описание | Порог по умолчанию | Временной интервал (минуты) |
|---|---|---|---|
| Узел Kube недоступен | Узел недоступен в течение последних 15 минут. | 1 | 15 |
| Переменное состояние готовности узла Kube | Состояние готовности узла изменилось более 2 раз за последние 15 минут. | 2 | 15 |
Оповещения уровня pod
| Имя оповещения | Описание | Порог по умолчанию | Временной интервал (минуты) |
|---|---|---|---|
| KubePVUsageHigh | Среднее использование постоянных томов (PV) в pod превышает 80 % за последние 15 минут. | >0.8 | 15 |
| НесоответствиеРепликKubeDeployment | Существует несоответствие между требуемым количеством реплик и количеством доступных реплик за последние 10 минут. | Н/П | 10 |
| Несоответствие_числа_реплик_в_KubeStatefulSet | Количество готовых реплик в StatefulSet не соответствует общему количеству реплик в StatefulSet за последние 15 минут. | Н/П | 15 |
| KubeHpaReplicasMismatch | Горизонтальное автомасштабирование pod в кластере не соответствовало требуемому количеству реплик за последние 15 минут. | Н/П | 15 |
| KubeHpaMaxedOut | Горизонтальный масштабировщик подов (HPA) в кластере работает на максимальном количестве реплик в течение последних 15 минут. | Н/П | 15 |
| KubePodCrashLooping | Один или несколько pod находится в состоянии CrashLoopBackOff, где pod непрерывно завершает работу после запуска и не удаётся успешно восстановиться в течение последних 15 минут. | >=1 | 15 |
| KubeJobStale | По меньшей мере один экземпляр задания не завершился успешно за последние 6 часов. | >0 | 360 |
| ПерезапускКонтейнераKubePod | Один или несколько контейнеров в кластере Kubernetes были перезапущены по крайней мере один раз в течение последнего часа. | >0 | 15 |
| СостояниеГотовностиKubePodНизкое | Процент модулей в состоянии готовности ниже 80 % для любого развертывания или демонсета в кластере Kubernetes в течение последних 5 минут. | <0.8 | 5 |
| KubePodFailedState | Один или несколько модулей pod находится в состоянии сбоя за последние 5 минут. | >0 | 5 |
| KubePod не готов по причине контроллера | Один или несколько модулей pod не находятся в состоянии готовности (т. е. на этапе "Ожидание" или "Неизвестно") за последние 15 минут. | >0 | 15 |
| Несоответствие_поколений_KubeStatefulSet | Текущая версия Kubernetes StatefulSet не совпадает с версией его метаданных за последние 15 минут. | Н/П | 15 |
| KubeJobFailed | Сбой одного или нескольких заданий Kubernetes за последние 15 минут. | >0 | 15 |
| Высокое среднее значение ЦП контейнера Kubernetes | Среднее использование ЦП на контейнер превышает 95 % за последние 5 минут. | >0.95 | 5 |
| Высокое среднее использование памяти в контейнере Kubernetes | Среднее использование памяти на контейнер превышает 95 % за последние 5 минут. | >0.95 | 10 |
| Высокая задержка запуска пода Kubelet | 99-й процентиль задержки запуска pod превышает 60 секунд за последние 10 минут. | >60 | 10 |
Правила генерации оповещений метрик платформы
| Имя оповещения | Описание | Порог по умолчанию | Временной интервал (минуты) |
|---|---|---|---|
| Процент ЦП узла превышает 95 % | Процент ЦП узла превышает 95 % за последние 5 минут. | 95 | 5 |
| Процент рабочих наборов памяти узла превышает 100 % | Процент рабочих наборов памяти узла превышает 100 % в течение последних 5 минут. | 100 | 5 |
Устаревшие оповещения метрик аналитики контейнеров (предварительная версия)
Правила метрик в аналитике контейнеров были прекращены 31 мая 2024 г. Эти правила были в общедоступной предварительной версии, но не достигли общей доступности, поскольку новые рекомендуемые оповещения метрик, описанные в этой статье, теперь доступны.
Если эти устаревшие правила генерации оповещений уже включены, их следует отключить и включить новый интерфейс.
Отключить правила оповещений метрик
- В меню "Аналитика" для кластера выберите рекомендуемые оповещения (предварительная версия).
- Измените состояние каждого правила генерации оповещений на "Отключено".
Сопоставление устаревших оповещений
В следующей таблице каждый из устаревших оповещений метрик аналитики контейнеров сопоставляется с эквивалентными рекомендуемыми оповещениями метрик Prometheus.
| Рекомендуемое оповещение пользовательской метрики | Рекомендуемое оповещение эквивалентной метрики Prometheus/Platform | Условие |
|---|---|---|
| Число завершенных заданий | KubeJobStale (оповещения уровня Pod) | По меньшей мере один экземпляр задания не завершился успешно за последние 6 часов. |
| Процент ЦПУ контейнера | KubeContainerAverageCPUHigh (оповещения уровня pod) | Среднее использование ЦП на контейнер превышает 95 % за последние 5 минут. |
| Память рабочего набора контейнера (%) | KubeContainerAverageMemoryHigh (оповещения уровня pod) | Среднее использование памяти на контейнер превышает 95 % за последние 5 минут. |
| Количество неудачных модулей pod | KubePodFailedState (оповещения уровня Pod) | Один или несколько модулей pod находится в состоянии сбоя за последние 5 минут. |
| Процент ЦП узла | Процент ЦП узла превышает 95 % (метрика платформы) | Процент ЦП узла превышает 95 % за последние 5 минут. |
| Использование диска на узле % | Н/П | Среднее использование диска для узла превышает 80 %. |
| Состояние узла NotReady | KubeNodeUnreachable (оповещения на уровне узла) | Узел недоступен в течение последних 15 минут. |
| Процент памяти рабочего набора узла | Процент рабочих наборов памяти узла превышает 100 % | Процент рабочих наборов памяти узла превышает 100 % в течение последних 5 минут. |
| Контейнеры, убитые из-за нехватки памяти (OOM) | KubeContainerOOMKilledCount (оповещения на уровне кластера) | Один или несколько контейнеров в модулях pod были убиты из-за отсутствия памяти (OOM) событий за последние 5 минут. |
| Процент использования сохраняемого тома | KubePVUsageHigh (оповещения уровня pod) | Среднее использование постоянных томов (PV) в pod превышает 80 % за последние 15 минут. |
| Готовые объекты pod (%) | KubePodReadyStateLow (оповещения на уровне капсулы) | Процент модулей в состоянии готовности ниже 80 % для любого развертывания или демонсета в кластере Kubernetes в течение последних 5 минут. |
| Число перезапускаемых контейнеров | KubePodContainerRestart (оповещения уровня Pod) | Один или несколько контейнеров в кластере Kubernetes были перезапущены по крайней мере один раз в течение последнего часа. |
Сопоставление наследованных метрик
В следующей таблице каждая из устаревших пользовательских метрик Аналитики контейнеров сопоставляется с эквивалентными метриками Prometheus.
| Настраиваемая метрика | Эквивалентная метрика Prometheus |
|---|---|
| использование CPU в миллиядрах | rate(container_cpu_usage_seconds_total[5m]) * 1000 |
| процентИспользованияЦП | 100 * rate(container_cpu_usage_seconds_total{cluster="$cluster"}[5m]) |
| процентИспользованияДоступногоПроцессора | 100 * ( sum by (cluster) (node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{cluster="$cluster"}) / sum by (cluster) (instance:node_num_cpu:sum{cluster="$cluster"}) |
| memoryRssByte | container_memory_rss{cluster="$cluster"} |
| ПроцентИспользованияПамятиRSS | 100 * (sum by (instance, cluster) (container_memory_rss{job="cadvisor", cluster="$cluster"}) / sum by (instance, cluster) (machine_memory_bytes{job="cadvisor", cluster="$cluster"})) |
| процент выделяемой памяти RSS | 100 * (сумма по (узел, кластер) (container_memory_rss{cluster="$cluster"}) / сумма по (узел, кластер) (node_memory_MemTotal_bytes{cluster="$cluster"})) |
| объемРабочегоНабораПамяти | container_memory_working_set_bytes{cluster="$cluster"} |
| процент нагрузки на оперативную память | 100 * (sum by (node, cluster) (container_memory_working_set_bytes{cluster="$cluster"}) / sum by (node, cluster) (node_memory_MemTotal_bytes{cluster="$cluster"})) |
| количество узлов | count(kube_node_status_condition{condition="Ready", status="true", cluster="$cluster"}) |
| ПроцентИспользованияДиска | 100 * (node_filesystem_size_bytes{cluster="$cluster"} - node_filesystem_free_bytes{cluster="$cluster"}) / node_filesystem_size_bytes{cluster="$cluster"}} |
| podCount | Подсчет (count) по (pod, namespace, cluster) (kube_pod_info{cluster="$cluster"}) |
| количествоЗавершённыхЗаданий | count(kube_job_status_succeeded{status="true", cluster="$cluster"} и time() - kube_job_status_start_time > 6 * 3600) |
| Количество перезапуска контейнера | sum by(container, namespace, cluster) (rate(kube_pod_container_status_restarts_total{cluster="$cluster"}[5m])) |
| Количество oomKilled контейнеров | sum by(container, namespace, cluster) (kube_pod_container_status_terminated_reason{reason="OOMKilled", cluster="$cluster"}) Примечание: Данная команда используется для агрегирования метрик завершённых контейнеров по причине "OOMKilled", что означает завершение из-за недостатка памяти. |
| podReadyPercentage | 100 * (sum(kube_pod_status_phase{phase="Running", cluster="$cluster"}) по (пространство имен, кластер) / sum(kube_pod_status_phase{phase!="Succeeded", cluster="$cluster"}) по (пространство имен, кластер)) |
Следующие шаги
- Ознакомьтесь с различными типами правил генерации оповещений в Azure Monitor.
- Ознакомьтесь с группами правил генерации оповещений в управляемой службе Azure Monitor для Prometheus.