Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНЯЕТСЯ КО ВСЕМ уровням управления API
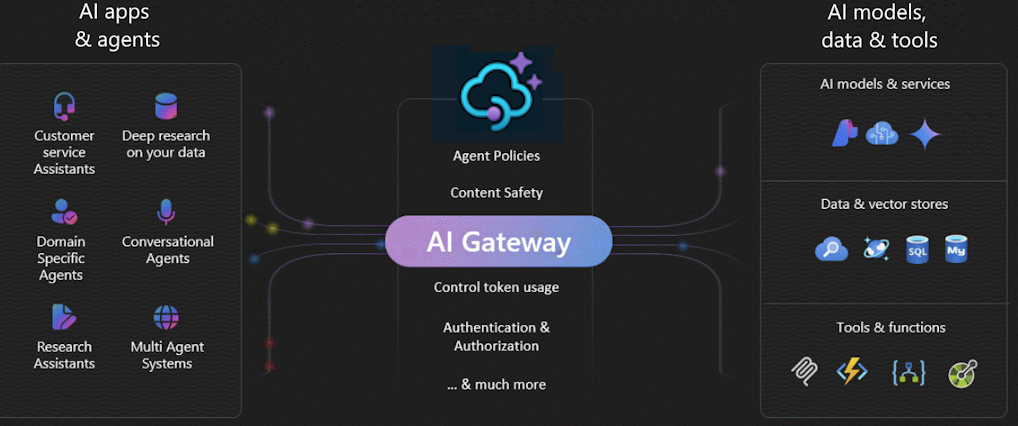
Шлюз AI в Azure API Management — это набор возможностей, которые помогают эффективно управлять серверными службами ИИ. Используйте эти возможности для защиты, масштабирования, мониторинга и управления моделями ИИ, агентами и инструментами, которые обеспечивают интеллектуальную разработку приложений и рабочих нагрузок.
Используйте шлюз ИИ для управления широким спектром конечных точек ИИ, в том числе:
API языковой модели , соответствующие одной из следующих схем API:
- Api завершения чата OpenAI или API ответов
- Anthropic Messages API (в настоящее время поддерживается на уровнях управления API версии 2)
- API ИИ Google Vertex
Модели можно развертывать в различных средах, включая Microsoft Foundry или немайкрософт поставщиков, таких как Amazon Bedrock.
Чтобы помочь вам управлять API языковых моделей от нескольких поставщиков, API Management также предоставляет унифицированный API для моделей (предварительная версия). Он предоставляет доступ к нескольким бэкендам через единый OpenAI-совместимый эндпоинт, автоматически выполняет преобразование форматов и позволяет один раз применять политики управления для всех моделей.
Удаленные серверы MCP и API агента A2A
Самостоятельно размещённые модели и конечные точки
Примечание
- Шлюз ИИ, включая возможности сервера MCP, расширяет существующий шлюз API управления API; это не отдельное предложение.
- Доступность возможностей зависит от уровня службы управления API. Дополнительные сведения см. в связанных статьях документации.
- Связанные функции управления и разработчика находятся в центре API Azure.
Tip
Теперь вы можете интегрировать шлюз ИИ непосредственно в Microsoft Foundry, что позволяет управлять моделями, агентами и инструментами ИИ из среды Foundry. Подробнее в разделе AI в Microsoft Foundry.
Зачем использовать шлюз ИИ?
Внедрение ИИ в организациях включает несколько этапов:
- Определение требований и оценка моделей искусственного интеллекта
- Создание приложений и агентов ИИ, которым требуется доступ к моделям и службам ИИ
- Эксплуатация и развертывание приложений ИИ и серверных компонентов в рабочей среде
По мере развития внедрения ИИ, особенно в крупных предприятиях, шлюз ИИ помогает решить ключевые проблемы. Она поможет вам в следующих аспектах.
- Проверка подлинности и авторизация доступа к службам ИИ
- Балансировка нагрузки между несколькими конечными точками ИИ
- Мониторинг и ведение журналов взаимодействия с ИИ
- Управление использованием токенов и квот в нескольких приложениях
- Включение самообслуживания для команд разработчиков
Посредничество в трафике и контроль
С помощью шлюза искусственного интеллекта можно:
- Быстро импортируйте и настройте OpenAI-совместимые или passthrough-эндпоинты LLM как API.
- Управлять моделями, развернутыми в Microsoft Foundry или у таких поставщиков, как Amazon Bedrock.
- Управление завершением чата, ответами и API в режиме реального времени.
- Сделайте существующие REST API доступными как серверы MCP и поддерживайте сквозную передачу запросов к серверам MCP.
- Импорт и управление API-интерфейсами агента A2A.
Например, чтобы подключить модель, развернутую в Microsoft Foundry или другом поставщике, управление API предоставляет упрощенные мастера для импорта схемы и настройки проверки подлинности в конечную точку ИИ с помощью управляемого удостоверения, удалив необходимость ручной настройки. В рамках того же пользовательского интерфейса можно предварительно настроить политики для обеспечения масштабируемости, безопасности и наблюдаемости API.

Tip
В новых реализациях, предназначенных для управления языковыми моделями у разных поставщиков, унифицированный API моделей (предварительная версия) может предоставлять несколько серверных частей LLM через единую конечную точку для клиента. Она объединяет импорт, маршрутизацию, преобразование формата и управление политиками для моделей из нескольких поставщиков.
Подробнее:
- Создание API унифицированной модели (предварительная версия) и управление ими
- Import api Microsoft Foundry
- Импорт API языковой модели
- Предоставление REST API в качестве сервера MCP
- Открытие доступа и управление существующим сервером MCP
- Импорт API агента A2A
Масштабируемость и производительность
Одним из основных ресурсов в создаваемых службах ИИ является токены. Microsoft Foundry и другие поставщики назначают квоты для развертывания моделей в виде токенов в минуту (TPM). Вы распределяете эти маркеры между потребителями модели, такими как различные приложения, команды разработчиков или отделы в компании.
Если у вас есть одно приложение, подключающееся к серверной части службы ИИ, вы можете управлять потреблением маркеров с помощью ограничения TPM, настроенного непосредственно в развертывании модели. Однако при росте портфеля приложений может потребоваться несколько приложений, вызывающих одну или несколько конечных точек службы ИИ. Эти конечные точки могут быть экземплярами единиц пропускной способности с оплатой по мере использования или подготовленными единицами пропускной способности (PTU). Необходимо убедиться, что одно приложение не использует всю квоту доверенного платформенного модуля и блокирует доступ к нужным серверным службам других приложений.
Ограничение скорости токенов и квоты
Настройте политику ограничения токенов в API LLM для управления и принудительного применения ограничений для каждого потребителя API на основе использования токенов службы AI. С помощью этой политики можно задать ограничение TPM или квоту токенов на указанный период, например, почасовую, ежедневную, еженедельную, ежемесячную или годовую.

Эта политика обеспечивает гибкость в установлении лимитов, основанных на токенах, для любого счетчика, например, для ключа подписки, исходящего IP-адреса или произвольного ключа, определяемого через выражение политики. Политика также включает предварительное вычисление маркеров запроса на стороне Azure API Management, минимизируя ненужные запросы к серверной части службы ИИ, если запрос уже превышает ограничение.
Пример, который приводится ниже, демонстрирует, как установить лимит TPM 500 на ключ подписки:
<llm-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</llm-token-limit>
Подробнее:
Семантическое кэширование
Семантическое кэширование — это метод, который повышает производительность API LLM путем кэширования результатов (завершения) предыдущих запросов и повторного их использования путем сравнения вектора запроса с предыдущими запросами. Этот метод уменьшает количество вызовов, сделанных в серверной части службы ИИ, улучшает время отклика для конечных пользователей и может помочь сократить затраты.
В службе управления API включите семантическое кэширование с помощью Azure Managed Redis или другой внешний кэш, совместимый с RediSearch и подключённый к Azure API Management. Используя API встраивания, политики llm-semantic-cache-store и llm-semantic-cache-lookup сохраняют и извлекают семантически похожие завершения запросов из кэша. Данный подход обеспечивает повторное использование завершений, что приводит к снижению потребления токенов и улучшению производительности ответов.

Подробнее:
- Настройка внешнего кэша в Azure API Management
- Включение семантического кэширования для API LLM в Azure API Management
Собственные функции масштабирования в службе управления API
Управление API также предоставляет встроенные функции масштабирования, помогающие шлюзу обрабатывать большие объемы запросов к API ИИ. Эти функции включают автоматическое или ручное добавление единиц масштабирования шлюза и добавление региональных шлюзов для развертываний с несколькими регионами. Определенные возможности зависят от уровня службы управления API.
Подробнее:
- Обновление и масштабирование экземпляра службы управления API
- Развертывание экземпляра службы управления API в нескольких регионах
Примечание
Хотя управление API может масштабировать емкость шлюза, необходимо также масштабировать и распределять трафик на серверы ИИ для поддержания увеличенной нагрузки (см. раздел "Устойчивость). Например, чтобы воспользоваться преимуществами географического распределения системы в конфигурации с несколькими регионами, разверните внутренние службы ИИ в том же регионе, что и шлюзы управления API.
Безопасность и сохранность
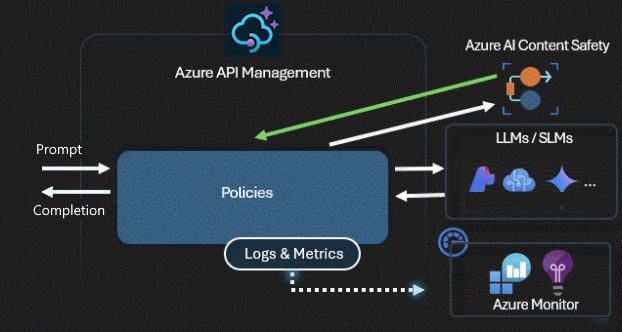
Шлюз искусственного интеллекта защищает и управляет доступом к API ИИ. С помощью шлюза искусственного интеллекта можно:
- Используйте управляемые удостоверения для проверки подлинности в службах ИИ в Azure, поэтому ключи API не требуются для проверки подлинности.
- Настройте авторизацию OAuth для приложений ИИ и агентов для доступа к API или серверам MCP с помощью диспетчера учетных данных управления API.
- Используйте политики для автоматической модерации запросов LLM с помощью Безопасность содержимого ИИ Azure.
Подробнее:
- Проверка подлинности и авторизация доступа к API LLM
- Сведения об учетных данных API и диспетчере учетных данных
- Принудительное применение проверок безопасности содержимого для запросов LLM
- Безопасный доступ к серверам MCP
Resiliency
Одной из проблем при создании интеллектуальных приложений является обеспечение устойчивости приложений к сбоям серверной части и может обрабатывать высокие нагрузки. Настроив конечные точки LLM с помощью backends в Azure API Management можно сбалансировать нагрузку. Вы также можете определить правила разбиения цепи, чтобы остановить перенаправление запросов на серверные серверы службы ИИ, если они не реагируют.
Подсистема балансировки нагрузки
Серверный балансировщик нагрузки поддерживает циклический перебор, взвешенную, приоритетную и балансировку нагрузки с учетом сеансов. Вы можете определить стратегию распределения нагрузки, которая соответствует вашим конкретным требованиям. Например, определите приоритеты в конфигурации подсистемы балансировки нагрузки, чтобы обеспечить оптимальную загрузку определенных конечных точек Microsoft Foundry, особенно приобретенных в качестве экземпляров PTU.

Средство разбиения цепи
Серверный выключатель включает динамическую длительность поездки, применяя значения из Retry-After заголовка, предоставленного серверной частью. Эта функция обеспечивает точное и своевременное восстановление серверной части, максимизируя использование приоритетных серверных компонентов.

Подробнее:
Наблюдаемость и управление
Управление API предоставляет комплексные возможности мониторинга и аналитики для отслеживания шаблонов использования маркеров, оптимизации затрат, обеспечения соответствия политикам управления ИИ и устранения неполадок с API. Используйте следующие возможности:
- Вести журнал подсказок и завершений в Azure Monitor.
- Отслеживайте метрики токенов для каждого потребителя в Application Insights.
- Просмотр встроенной панели мониторинга.
- Настройте политики с пользовательскими выражениями.
- Управление квотами токенов в приложениях.
Например, можно вводить метрики маркеров с помощью политики llm-emit-token-metric и добавить пользовательское измерение, которое можно использовать для фильтрации метрики в Azure Monitor. Следующий пример генерирует метрики токена с параметрами для IP-адреса клиента, ID API и ID пользователя (из пользовательского заголовка):
<llm-emit-token-metric namespace="llm-metrics">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</llm-emit-token-metric>

Кроме того, включите логирование для API LLM в Azure API Management, чтобы отслеживать использование токенов, запросов и завершений для выставления счетов и аудита. После включения ведения журнала можно проанализировать журналы в Application Insights и использовать встроенную панель мониторинга в Управлении API для просмотра шаблонов потребления токенов в ваших AI API.

Подробнее:
- Использование токенов для ведения журнала, генерация подсказок и завершение
- Выявление метрик потребления токенов
Опыт разработчика
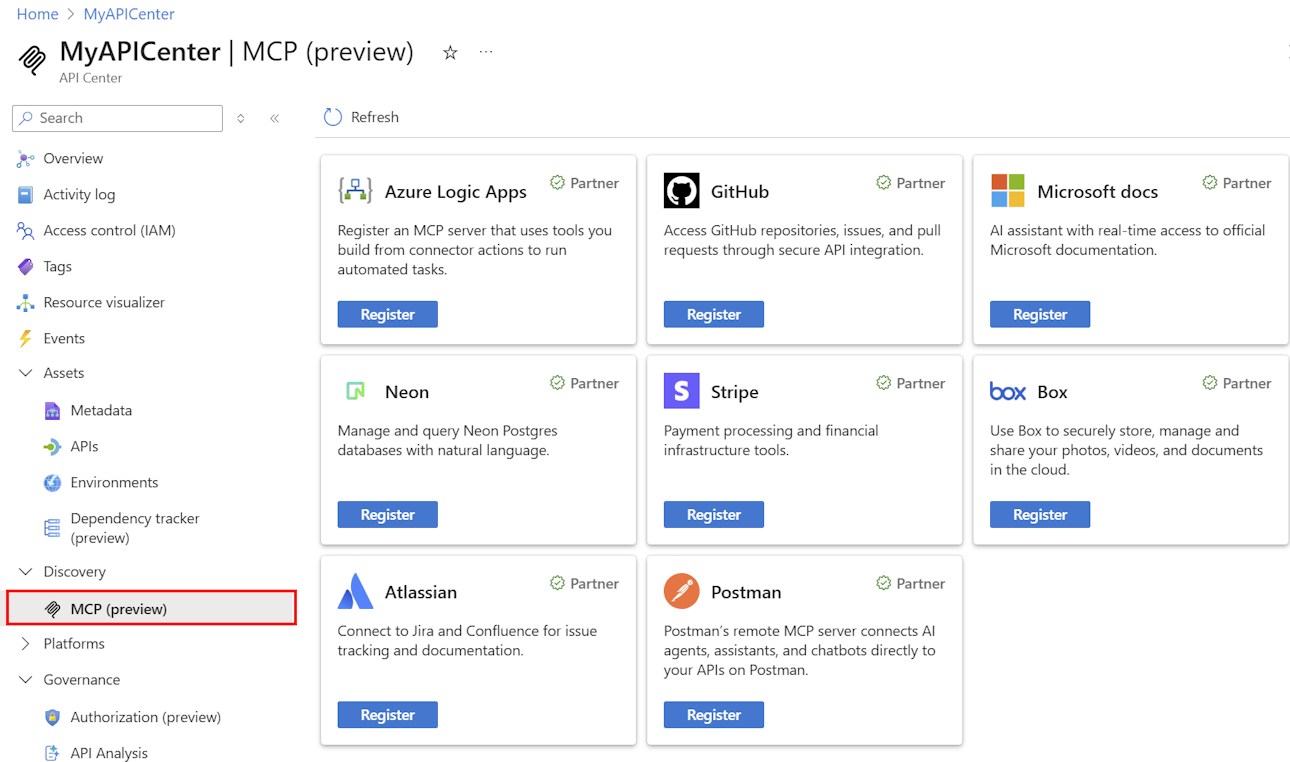
Используйте шлюз ИИ и Azure Центр API для упрощения разработки и развертывания API, серверов MCP и других ресурсов ИИ. Помимо пользовательского интерфейса настройки импорта и политики для распространенных сценариев искусственного интеллекта в службе управления API, воспользуйтесь этими функциями:
- Простая регистрация API, серверов MCP, навыков и других ресурсов в каталоге организации в центре API Azure
- Доступ в режиме самообслуживания через порталы для разработчиков в API Management и API Center
- Набор средств политики управления API для настройки
- Соединитель Центра API Copilot Studio для расширения возможностей агентов ИИ
Подробнее:
- Регистрация и обнаружение серверов MCP в Центре API
- Синхронизация API-интерфейсов и серверов MCP между управлением API и Центром API
- Портал разработчика службы управления API
- Портал Центра API
- набор инструментов политики Azure API Management
- Коннектор API Center Copilot Studio
Шлюз ИИ в Microsoft Foundry (предварительная версия)
Теперь вы можете интегрировать шлюз ИИ непосредственно в Microsoft Foundry, что позволяет управлять трафиком ИИ из среды Foundry.
Примечание
Подробные сведения о требованиях к использованию экземпляра API Management в качестве шлюза ИИ в Foundry, включая необходимые разрешения и поддерживаемые ценовые категории служб, см. в документации Microsoft Foundry. На портале Foundry можно также создать новый экземпляр службы управления API для использования в качестве шлюза ИИ.
При создании или связывании экземпляра шлюза ИИ с ресурсом Foundry можно управлять, защищать и отслеживать ресурсы Foundry через шлюз.
Models: Настройте квоты токенов и лимиты скорости непосредственно в интерфейсе Foundry для всех размещений моделей, включая Azure OpenAI и других поставщиков.
Agents: регистрация агентов, работающих в любом месте — Azure, других облаках или локальных средах — в плоскостю управления Foundry для централизованного инвентаризации и управления. Просмотрите данные телеметрии в Foundry или Application Insights и примените такие политики, как регулирование или безопасность содержимого.
Средства. Регистрация средств MCP, размещенных в любой среде для автоматического управления и обнаружения. Инструменты отображаются в инвентаре Foundry, готовые к использованию агентами.
Для расширенных сценариев, таких как пользовательские политики, корпоративные сети или федеративные шлюзы, получите доступ к полному интерфейсу Azure API Management, при этом поддерживая непрерывность с ресурсами под управлением Foundry.
Подробнее:
- Включить AI-шлюз в Microsoft Foundry
- Регистрация пользовательских агентов в Foundry
- Управление инструментами с помощью шлюза ИИ
- Использование собственной модели в Foundry Agent Service
Ранний доступ к функциям шлюза ИИ
В качестве клиента управления API вы можете получить ранний доступ к новым функциям и возможностям через канал раннего выпуска шлюза ИИ. Этот доступ позволяет попробовать последние инновации шлюза искусственного интеллекта, прежде чем они общедоступны и предоставить отзывы, чтобы помочь сформировать продукт. В настоящее время канал раннего выпуска шлюза ИИ доступен на классических уровнях Azure API Management.
Подробнее:
Лаборатории и примеры кода
- возможности лабораторий шлюза AI
- Семинар по шлюзу ИИ
- Azure OpenAI с управлением API (Node.js)
- Python пример кода
- Шаблон проектирования единого шлюза ИИ
Архитектура и проектирование
- Эталонная архитектура шлюза ИИ с помощью управления API
- акселератор зоны посадки шлюза центра AI hub gateway
- Проектирование и реализация шлюзового решения с использованием ресурсов Azure OpenAI
- Использовать шлюз перед несколькими развертываниями Azure OpenAI
Связанный контент
- Blog: шлюз ИИ в Azure API Management теперь доступен в Microsoft Foundry
- Blog: введение возможностей ИИ в Azure API Management
- Блог: интеграция Azure Content Safety с менеджментом API
- Учебный курс. Управление api-интерфейсами создания ИИ
- Интеллектуальная балансировка нагрузки для конечных точек OpenAI