Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это руководство поможет вам перейти к расширенным сетевым службам контейнеров (ACNS) в качестве основного решения для решения реальных вариантов использования сетей в Службе Azure Kubernetes (AKS). Устранение неполадок с разрешением DNS, оптимизация трафика и исходящего трафика или обеспечение соответствия политикам сети, в этом руководстве показано, как эффективно использовать панели мониторинга наблюдения ACNS, журналы сети контейнеров, метрики сети контейнеров и средства визуализации для эффективной диагностики и устранения проблем.
Расширенные сетевые службы контейнеров — это комплексная, корпоративная платформа отслеживания сети и безопасности корпорации Майкрософт , которая предоставляет самые сложные функции для мониторинга, анализа и устранения неполадок сетевого трафика в кластерах AKS. Она включает предварительно созданные панели мониторинга Grafana, метрики в режиме реального времени, подробные журналы и аналитические сведения, которые помогают получить глубокую видимость производительности сети, быстро определить проблемы и оптимизировать сетевую среду контейнеров с полной поддержкой Майкрософт.
Обзор панелей мониторинга расширенных сетевых служб контейнеров
Мы создали образцы панелей мониторинга для расширенных служб контейнерной сети, чтобы помочь вам визуализировать и анализировать сетевой трафик, DNS-запросы и потери пакетов в кластерах Kubernetes. Эти панели мониторинга предназначены для предоставления аналитических сведений о производительности сети, выявлении потенциальных проблем и оказании помощи в устранении неполадок. Чтобы узнать, как настроить эти панели мониторинга, см. в статье Настройка обзорности сети контейнеров для сервиса Azure Kubernetes (AKS) — Prometheus и Grafana, управляемые Azure.
Набор панелей мониторинга включает:
- Журналы потоков. Отображение потоков сетевого трафика между модулями pod, пространствами имен и внешними конечными точками.
- Журналы потоков (внешний трафик): показывает потоки сетевого трафика между модулями pod и внешними конечными точками.
- Кластеры: отображаются метрики уровня узла для кластеров.
- DNS (кластер): отображаются метрики DNS в кластере или выборе узлов.
- DNS (рабочая нагрузка): отображаются метрики DNS для указанной рабочей нагрузки (например, pod для daemonSet или deployment, например CoreDNS).
- Drops (Workload): отображает отпадает до указанной рабочей нагрузки (например, pod для развертывания или daemonSet).
- Потоки Pod (пространство имен): показывает потоки пакетов L4/L7 в/из указанного пространства имен (т. е. Pods в пространстве имен).
- Потоки Pod (Рабочая Нагрузка): показывает потоки пакетов L4/L7 к/от указанной рабочей нагрузки (например, Pod для Развертывания или DaemonSet).
- Потоки L7 (пространство имен): показывает потоки пакетов HTTP, Kafka и gRPC в и из указанного пространства имен (т. е. Pods в этом пространстве имен) при применении политики на основе уровня 7. Это доступно только для кластеров с использованием Cilium data plane.
- Потоки L7 (рабочая нагрузка): показывает потоки HTTP, Kafka и gRPC к/от указанной рабочей нагрузки (например, Pods развертывания или DaemonSet) при применении политики на основе 7-го уровня. Это доступно только для кластеров с использованием Cilium data plane.
Вариант использования 1. Интерпретация проблем с сервером доменных имен (DNS) для анализа первопричин (RCA)
Проблемы с DNS на уровне pod могут привести к сбою обнаружения служб, медленных ответов приложений или сбоев обмена данными между модулями pod. Эти проблемы часто возникают из неправильно настроенных политик DNS, ограниченной емкости запросов или задержки при разрешении внешних доменов. Например, если служба CoreDNS перегружена или вышестоящий DNS-сервер перестает отвечать, это может привести к сбоям в зависимых модулях pod. Для устранения этих проблем требуется не только идентификация, но и глубокое представление о поведении DNS в кластере.
Предположим, что вы настроили веб-приложение в кластере AKS, и теперь это веб-приложение недоступно. Вы получаете ошибки DNS, такие как
DNS_PROBE_FINISHED_NXDOMAINилиSERVFAIL, пока сервер DNS разрешает адрес веб-приложения.
Шаг 1. Изучение метрик DNS на панелях мониторинга Grafana
Мы уже создали две панели мониторинга DNS для изучения метрик DNS, запросов и ответов: DNS (кластер), которые отображают метрики DNS в кластере или выборе узлов, а также DNS (рабочая нагрузка), в которых отображаются метрики DNS для определенной рабочей нагрузки (например, pods daemonSet или Deployment, например CoreDNS).
Проверьте панель мониторинга кластера DNS , чтобы получить моментальный снимок всех действий DNS. Эта панель мониторинга предоставляет общий обзор запросов и ответов DNS, таких как то, какие типы запросов не отвечают, наиболее распространенный запрос и наиболее распространенный ответ. Он также выделяет основные ошибки DNS и узлы, которые создают большую часть этих ошибок.
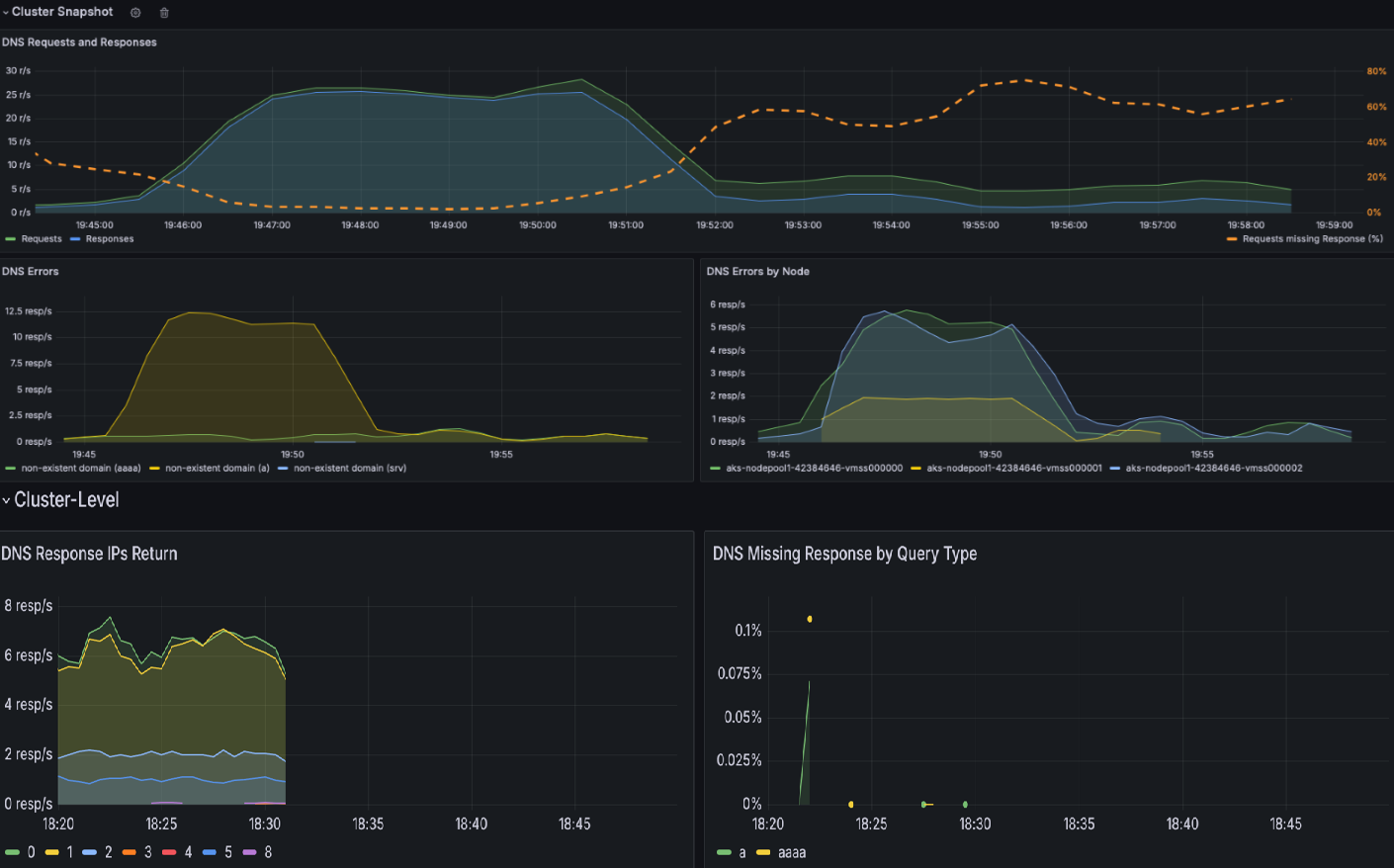
Прокрутите вниз, чтобы узнать контейнеры с больше всего запросов DNS и ошибок во всех пространствах имен.
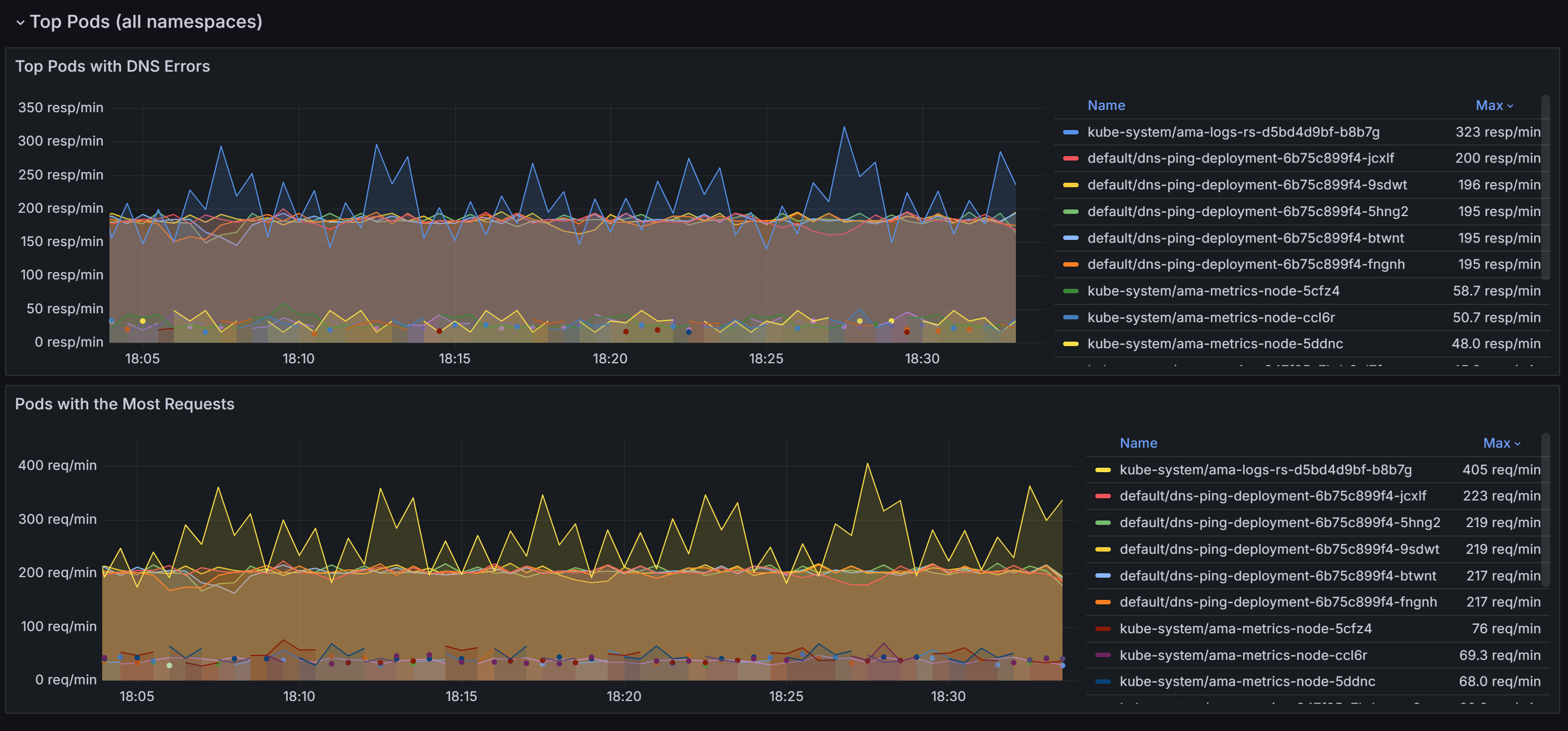
После определения модулей pod, вызывающих большинство проблем с DNS, вы можете перейти к панели мониторинга рабочей нагрузки DNS для более детального представления. Коррелируя данные на различных панелях на панели мониторинга, вы можете систематически сузить первопричины проблем.
Разделы "Запросы DNS " и " Ответы DNS " позволяют выявлять тенденции, такие как внезапное снижение частоты откликов или увеличение отсутствующих ответов. Высокий показатель Requests Missing Response % указывает на потенциальные проблемы с вышестоящим DNS-сервером или перегрузку запросов. На следующем снимке экрана с образцовой панели мониторинга вы можете увидеть внезапное увеличение числа запросов и ответов примерно в 15:22.

Проверьте наличие ошибок DNS по типу и проверьте пики определенных типов ошибок (например,
NXDOMAINдля несуществующих доменов). В этом примере наблюдается значительное увеличение ошибок отказа в запросе, что может свидетельствовать о несоответствии конфигураций DNS или неподдерживаемости запросов.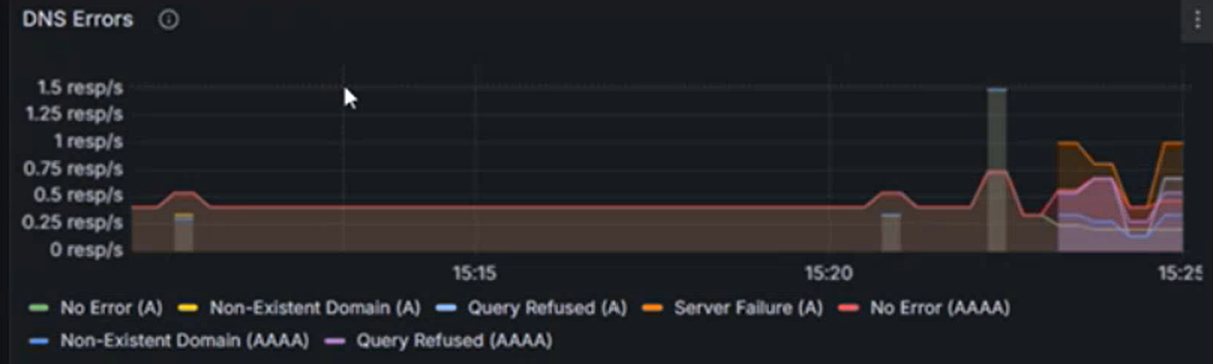
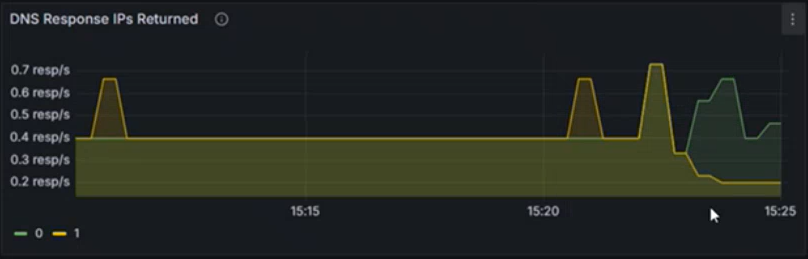
Используйте такие разделы, как возвращаемые IP-адреса ответа DNS, чтобы обеспечить обработку ожидаемых ответов. На этом графике отображается скорость успешных запросов DNS, обработанных в секунду. Эта информация полезна для понимания того, как часто dns-запросы успешно разрешаются для указанной рабочей нагрузки.
- Увеличение скорости может указывать на всплеск трафика или потенциальную атаку DNS (например, распределенное отказ в обслуживании (DDoS)).
- Снижение скорости может свидетельствовать о проблемах, связанных с внешним DNS-сервером, проблемой конфигурации CoreDNS или недоступной рабочей нагрузкой coreDNS.
Изучение наиболее частых ЗАПРОСОВ DNS может помочь определить шаблоны в сетевом трафике. Эта информация полезна для понимания распределения рабочих нагрузок и обнаружения необычных или непредвиденных действий запросов, которые могут потребовать внимания.

Таблица ответа DNS помогает анализировать первопричину проблемы DNS путем выделения типов запросов, ответов и кодов ошибок, таких как SERVFAIL (сбой сервера). Он определяет проблемные запросы, шаблоны сбоев или неправильные конфигурации. Наблюдая тенденции в кодах возврата и скоростях отклика, можно определить определенные узлы, рабочие нагрузки или запросы, вызывающие нарушения или аномалии DNS.
В следующем примере можно увидеть, что для записей AAAA (IPV6) нет ошибок, но сбой сервера с записью A (IPV4). Иногда DNS-сервер может быть настроен для определения приоритета IPv6 по протоколу IPv4. Это может привести к ситуациям, когда IPv6-адреса возвращаются правильно, но у IPv4-адресов возникают проблемы.

При подтверждении проблемы с DNS на следующем графике определяются первые десять конечных точек, вызывающих ошибки DNS в определенной рабочей нагрузке или пространстве имен. Это можно использовать для определения приоритетов устранения неполадок с определенными конечными точками, обнаружения неправильной конфигурации или исследования проблем с сетью.









Шаг 2. Анализ проблем с разрешением DNS с помощью журналов сети контейнеров
Журналы сети контейнеров предоставляют подробные сведения о запросах DNS и их ответах в режимах хранения и по запросу. С помощью журналов сети контейнеров можно проанализировать трафик, связанный с DNS, для определенных модулей pod, где отображаются такие сведения, как DNS-запросы, ответы, коды ошибок и задержка. Чтобы просмотреть потоки DNS в рабочей области Log Analytics, используйте следующий запрос KQL:
RetinaNetworkFlowLogs | where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>)) | where Layer4.UDP.destination_port == 53 | where Layer7.type == "REQUEST" | where Reply == false or isnull(Reply) | project TimeGenerated, SourcePodName, DestinationPodName, Layer7.dns.query, Layer7.dns.qtypes, Verdict, TrafficDirection, AdditionalFlowData.Summary, NodeName, SourceNamespace, DestinationNamespace | order by TimeGenerated descЗамените нужный
<start-time>диапазон времени и замените<end-time>его в формате2025-08-12T00:00:00Z.Журналы сети контейнеров предоставляют исчерпывающую информацию о запросах DNS и их ответах, которые помогут диагностировать и устранять проблемы, связанные с DNS. Каждая запись журнала включает в себя такие сведения, как тип запроса (например , A или AAAA), запрашиваемое доменное имя, код ответа DNS (например, запрос отказано, несуществующий домен или сбой сервера), а также источник и назначение DNS-запроса.
Определите состояние запроса: проверьте поле вердикта для ответов, таких как DROPPED или FORWARDED, что указывает на проблемы с подключением к сети или применением политик.
Проверьте источник и назначение: убедитесь, что имена модулей, перечисленные в полях SourcePodName и DestinationPodName, правильны и что путь связи является ожидаемым.
Отслеживание шаблонов трафика. Просмотрите поле вердикта , чтобы понять, были ли перенаправлены или удалены запросы. Нарушения переадресации могут указывать на проблемы с сетью или конфигурацией.
Анализ меток времени: используйте поле TimeGenerated для сопоставления конкретных проблем DNS с другими событиями в системе для комплексной диагностики.
Фильтрация по модулям pod и пространствам имен. Используйте такие поля, как SourcePodName, DestinationPodName и SourceNamespace , чтобы сосредоточиться на определенных рабочих нагрузках, возникающих при возникновении проблем.
Шаг 3. Визуализация трафика DNS с помощью панелей мониторинга журналов сети контейнеров
Журналы сети контейнеров предоставляют широкие возможности визуализации с помощью панелей мониторинга портала Azure и Управляемой Grafana Azure. Визуализация диаграммы зависимостей службы и журналов потоков дополняет подробный анализ журналов, предоставляя визуальные сведения о трафике и зависимостях, связанных с DNS:
- Графы зависимостей служб: визуализация, отображающая, какие pod или службы отправляют высокие объемы запросов DNS и их взаимосвязи.
- Панели мониторинга журналов потоков: мониторинг шаблонов запросов DNS, частоты ошибок и времени отклика в режиме реального времени
- Анализ потока трафика. Определение удаленных пакетов DNS и путей связи к CoreDNS или внешним службам DNS

Эти визуализации можно получить с помощью следующих способов:
- Портал Azure. Перейдите к кластеру AKS → Insights → Сетевые журналы → потоков
- Azure Managed Grafana: используйте заранее настроенные панели мониторинга "Журналы потоков" и "Журналы потоков (внешний трафик)"
Благодаря объединенным возможностям дашбордов Grafana, режиму хранения журналов сети контейнеров для исторического анализа и журналов по запросу для устранения неполадок в режиме реального времени, можно определить проблемы DNS и эффективно проводить анализ корневых причин.
Вариант использования 2. Определение падений пакетов на уровне кластера и pod из-за неправильно настроенной политики сети или проблем с сетевым подключением
Проблемы с подключением и применением сетевых политик часто возникают из-за неправильно настроенных политик сети Kubernetes, несовместимых подключаемых модулей сетевого интерфейса контейнера (CNI), перекрывающихся диапазонов IP-адресов или ослабления сетевого подключения. Такие проблемы могут нарушить функциональные возможности приложений, что приводит к сбоям служб и снижению производительности пользователей.
При удалении пакетов программы eBPF фиксируют событие и создают метаданные о пакете, включая причину удаления и его расположение. Эти данные обрабатываются программой пространства пользователя, которая анализирует информацию и преобразует ее в метрики Prometheus. Эти метрики предоставляют критически важные сведения о основных причинах удаления пакетов, что позволяет администраторам выявлять и устранять проблемы, такие как неправильно настроенные политики сети.
Помимо проблем, связанных с применением политик, проблемы с сетевым подключением могут привести к удалению пакетов из-за таких факторов, как ошибки TCP или повторные передачи. Администраторы могут отлаживать эти проблемы, анализируя таблицы повторной передачи TCP и журналы ошибок, которые помогают выявлять пониженные сетевые связи или узкие места. Используя эти подробные метрики и средства отладки, команды могут обеспечить гладкие сетевые операции, сократить время простоя и обеспечить оптимальную производительность приложения.
Предположим, у вас есть приложение на основе микросервисов, в котором фронтенд pod не может взаимодействовать с бэкенд pod из-за чрезмерно ограничивающей сетевой политики, блокирующей входящий трафик.
Шаг 1. Изучение метрик удаления в панелях мониторинга Grafana
Если имеются потери пакетов, начните исследование с панели потоков Pod (пространство имен). Эта панель мониторинга содержит разделы, которые помогают определить пространства имен с наибольшим числом падений, а также pods в этих пространствах имен с наибольшим числом падений. Например, давайте рассмотрим тепловую карту исходящих пакетов для самых важных исходных узлов или для целевых узлов, чтобы определить, какие узлы наиболее затронуты. Яркие цвета указывают на более высокие показатели падения. Сравните по времени, чтобы обнаружить шаблоны или пики в отдельных pod.
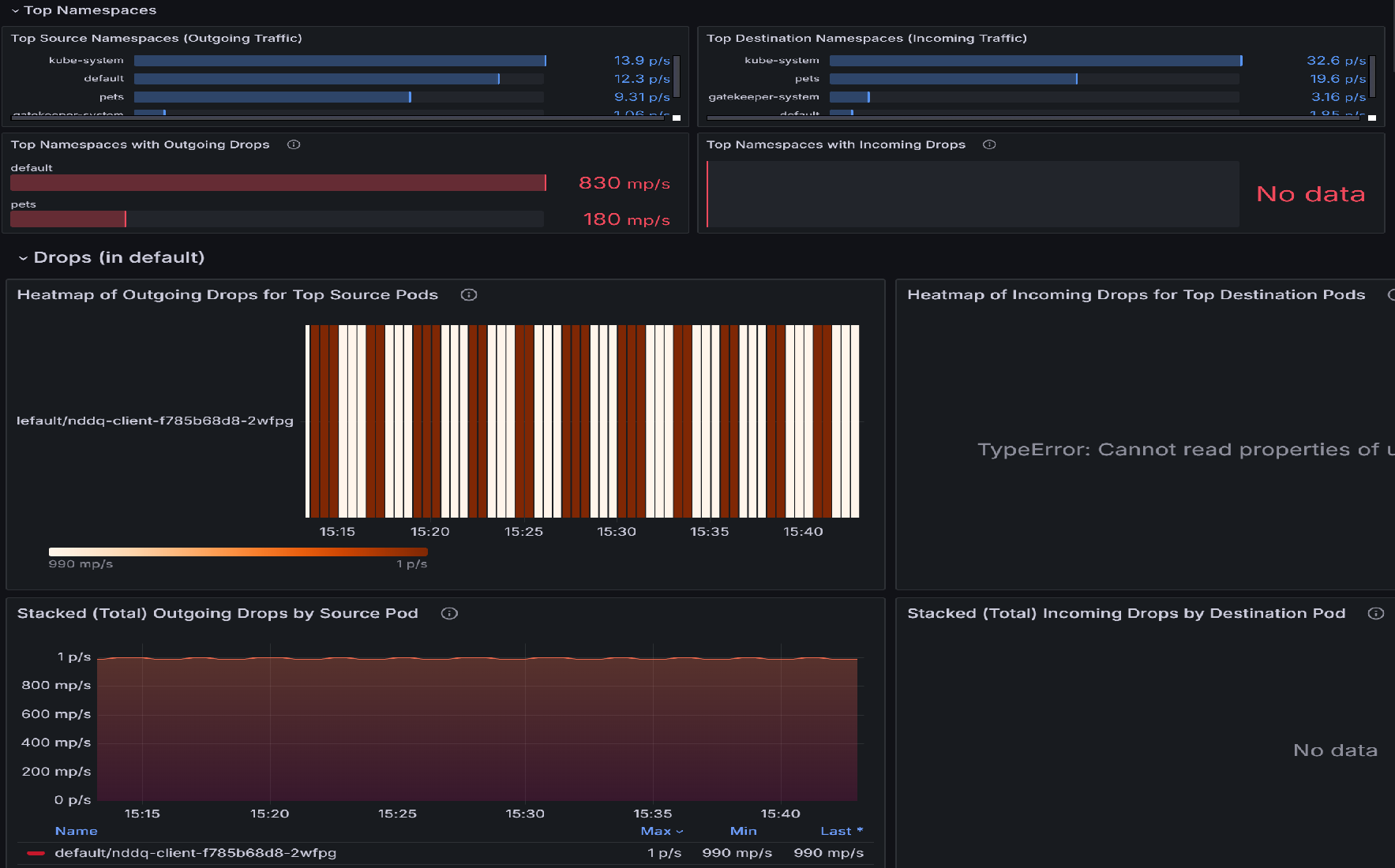
После определения верхних модулей pod с самыми высокими падениями перейдите на панель мониторинга drops (Рабочая нагрузка ). Эту панель мониторинга можно использовать для диагностики проблем с сетевым подключением, определяя закономерности в падении исходящего трафика из определенных подов. Визуализации выделяют, какие поды испытывают наибольшие падения, скорость этих падений и причины их возникновения, такие как отказы по политике. Коррелируя пики уровней потерь с определенными pod'ами или временными интервалами, вы можете определить неправильные конфигурации, перегруженные службы или проблемы с применением политик, которые могут нарушать подключение.
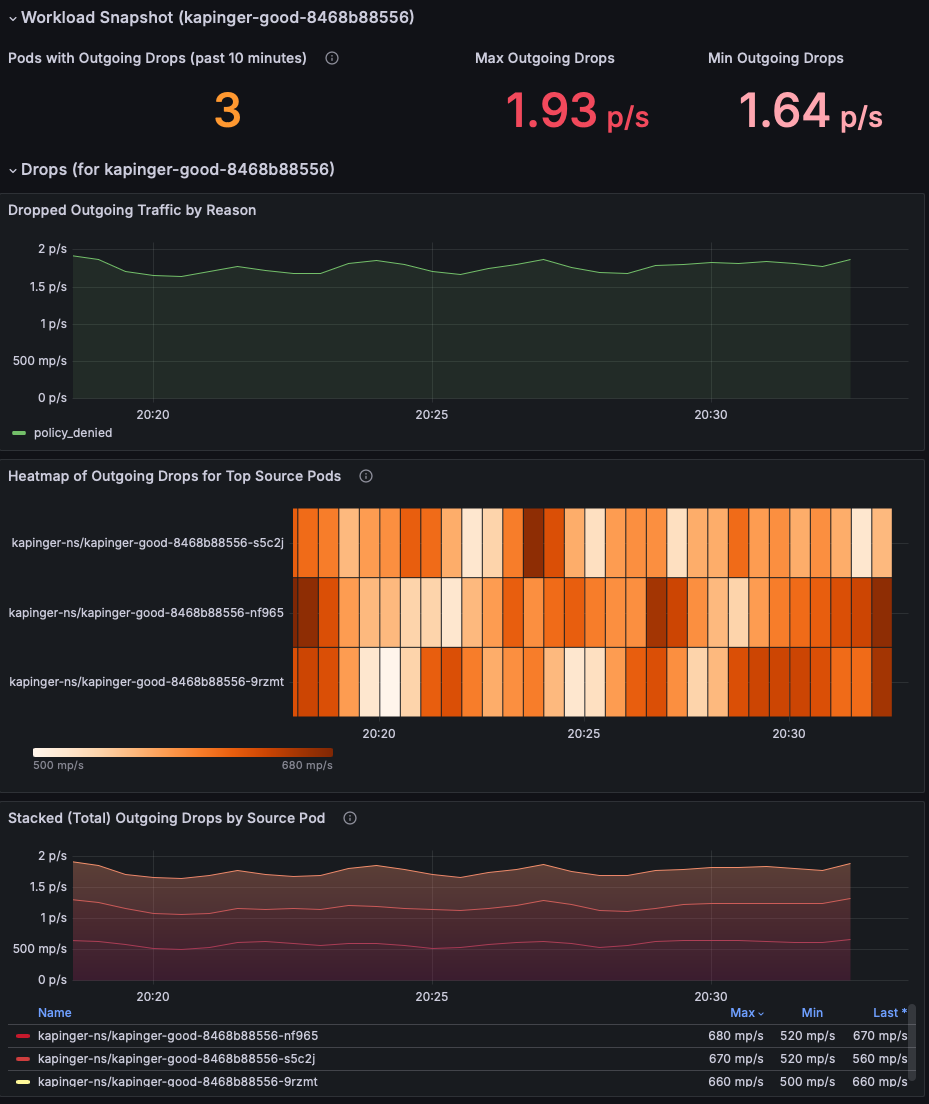
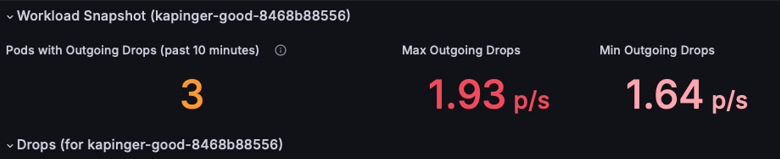
Просмотрите раздел моментального снимка рабочей нагрузки , чтобы определить модули pod с удалением исходящих пакетов. Сосредоточьтесь на метриках максимального исходящего удаления и минимального исходящего удаления , чтобы понять серьезность проблемы (в этом примере показаны 1,93 пакета/с). Приоритетно исследуйте pod с устойчиво высокой потерей пакетов.
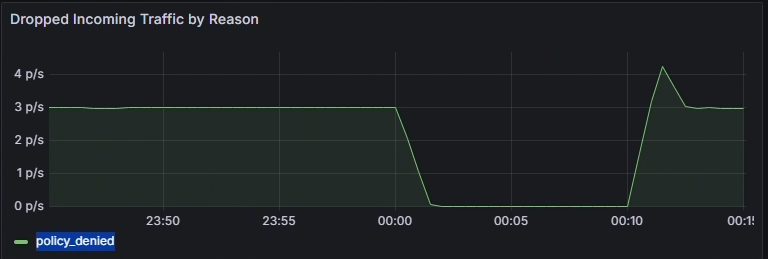
Используйте диаграмму "Отброшенный входящий/исходящий трафик по причине", чтобы определить первопричину падений. В этом примере причина заключается в том, что политика запрещена, что указывает на неправильно настроенные политики сети, блокирующие исходящий трафик. Проверьте, наблюдается ли рост количества отказов в каком-либо конкретном интервале времени, чтобы уточнить, когда началась проблема.
Используйте тепловую карту входящих пакетов для основных исходящих и целевых подов, чтобы определить, какие поды наиболее затронуты. Яркие цвета указывают на более высокие показатели падения. Сравните по времени, чтобы обнаружить шаблоны или пики в отдельных pod.
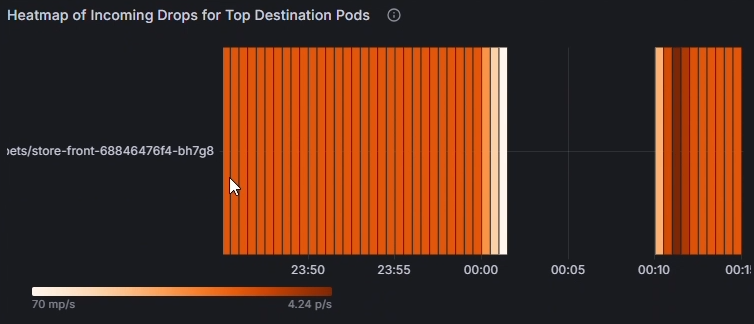
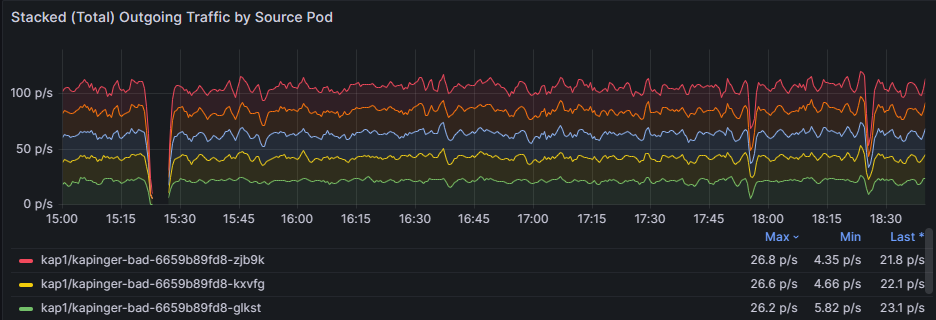
Используйте диаграмму Накопленные (всего) исходящие/входящие потери по исходным pod, чтобы сравнить частоту потерь между затронутыми pod. Определите, постоянно ли определенные модули pod показывают более высокие падения (например, капингер-bad-6659b89fd8-zjb9k в 26,8 p/s). Здесь p/s обозначает количество теряемых пакетов в секунду. Проверьте эти pod на соответствие их рабочим нагрузкам, меткам и сетевым политикам для диагностики потенциальных неправильных конфигураций.






Шаг 2. Анализ удаления пакетов с помощью журналов сети контейнеров
Журналы сети контейнеров предоставляют исчерпывающую информацию о удалениях пакетов, вызванных неправильно настроенными политиками сети с подробными, временными и историческими данными. Вы можете анализировать удаленные пакеты, проверяя конкретные причины удаления, шаблоны и затронутые рабочие нагрузки.
Используйте следующий запрос KQL в рабочей области Log Analytics, чтобы определить удаление пакетов:
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where Verdict == "DROPPED"
| summarize DropCount = count() by SourcePodName, DestinationPodName, SourceNamespace, bin(TimeGenerated, 5m)
| order by TimeGenerated desc, DropCount desc
Для анализа потерянных пакетов в режиме реального времени можно также фильтровать по определенным pod или пространствам имен.
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where Verdict == "DROPPED"
| where SourceNamespace == "<namespace-name>"
| project TimeGenerated, SourcePodName, DestinationPodName, SourceNamespace, DestinationNamespace, Verdict, TrafficDirection
| order by TimeGenerated desc
Замените нужный <start-time> диапазон времени и замените <end-time> его в формате2025-08-12T00:00:00Z.
Журналы сети контейнеров предоставляют подробные сведения об удаленных пакетах, помогая выявлять неправильно настроенные сетевые политики и проверять исправления. В журналах содержится детальная информация о причинах отклонения, затронутых подах и шаблонах трафика, которые могут направить ваши усилия по устранению неполадок.
Шаг 3. Визуализация потерь пакетов с помощью панелей мониторинга сетевых журналов контейнеров
Журналы сети контейнеров предоставляют визуальное представление потоков трафика и отброшенных пакетов с помощью панелей мониторинга портала Azure и Azure Managed Grafana. Панели мониторинга журналов потоков отображают взаимодействие между подами в одном пространстве имен, подами в других пространствах имен и трафиком извне кластера.
Основные функции визуализации включают:
- Анализ удаления по причине: определение причины удаления пакетов (отказ в политике, отслеживание подключений и т. д.)
- Карты потока трафика: визуальное представление разрешенных и запрещенных потоков трафика
- Аналитика пространства имен и уровня pod: подробные представления исходных и целевых связей
- Анализ временных рядов: исторические тенденции удаления пакетов и их причины

Эти данные играют важную роль в проверке политик сети, применяемых в кластере, что позволяет администраторам быстро выявлять и устранять любые неправильно настроенные или проблемные политики с помощью комплексного анализа журналов и визуальных представлений.
Вариант использования 3. Определение дисбалансов трафика в рабочих нагрузках и пространствах имен
Дисбаланс трафика возникает, когда определенные поды или службы в нагрузке или пространстве имен обрабатывают слишком большой объём сетевого трафика, чем другие. Это может привести к конкуренции за ресурсы, снижению производительности перегруженных модулей и низкой загруженности других. Такие дисбалансы часто возникают из-за неправильно настроенных служб, неравномерного распределения трафика балансировщиками нагрузки или непреднамеренных шаблонов использования. Без наблюдаемости сложно определить, какие модули pod или пространства имен перегружены или недоиспользуются. Расширенные сетевые службы контейнеров могут помочь в мониторинге шаблонов трафика в режиме реального времени на уровне pod, предоставляя метрики по использованию пропускной способности, скорости запросов и задержке, что упрощает определение дисбалансов.
Предположим, у вас есть интернет-розничная платформа, запущенная в кластере AKS. Платформа состоит из нескольких микрослужб, включая службу поиска продуктов, службу проверки подлинности пользователя и службу обработки заказов, которая взаимодействует через Kafka. Во время сезонной продажи служба поиска продуктов испытывает всплеск трафика, а другие службы остаются бездействуными. Подсистема балансировки нагрузки непреднамеренно направляет больше запросов к подмножеству модулей pod в развертывании поиска продукта, что приводит к перегрузке и увеличению задержки для поисковых запросов. Между тем другие модули pod в том же развертывании недостаточно используются.
Шаг 1. Изучение трафика pod с использованием панели мониторинга Grafana
Просмотрите панель мониторинга потоков Pod (рабочей нагрузки). Моментальный снимок рабочей нагрузки отображает различные статистические данные, такие как исходящий и входящий трафик, а также исходящие и входящие падения.

Проверьте колебания трафика для каждого типа трассировки. Значительные вариации в синих и зеленых линиях указывают на изменения объема трафика для приложений и служб, что может способствовать перегрузке. Определяя периоды с высоким трафиком, вы можете определить время застоя и исследовать дальше. Кроме того, сравните шаблоны исходящего и входящего трафика. Если существует значительный дисбаланс между исходящим и входящим трафиком, он может указывать на перегрузку сети или узкие места.

Тепловые карты представляют метрики потока трафика на уровне pod в кластере Kubernetes. Тепловая карта исходящего трафика для топ-исходных модулей pod показывает исходящий трафик из первых 10 исходных модулей pod, в то время как тепловая карта входящего трафика для основных целевых модулей pod отображает входящий трафик в первые 10 целевых модулей pod. Интенсивность цвета указывает объем трафика с темными оттенками, представляющими более высокий трафик. Согласованные шаблоны выделяют модули pod, генерирующие или получающие значительный трафик, например default/tcp-client-0, который может выступать в качестве центрального узла.
Следующая тепловая карта указывает на более высокий трафик, который поступает и выходит из одного пода. Если один и тот же модуль pod (например, default/tcp-client-0) отображается в обоих тепловых картах с высокой интенсивностью трафика, он может предположить, что он отправляет и получает большой объем трафика, потенциально выступая в качестве центрального узла в рабочей нагрузке. Вариации интенсивности в модулях pod могут указывать на неравномерное распределение трафика, при этом некоторые модули pod обрабатывают непропорционально больше трафика, чем другие.

Мониторинг трафика сброса TCP имеет решающее значение для понимания сетевого поведения, устранения неполадок, обеспечения безопасности и оптимизации производительности приложений. Он предоставляет ценные сведения о том, как подключения управляются и завершаются, позволяя сетевым и системным администраторам поддерживать здоровую, эффективную и безопасную среду. Эти метрики показывают, сколько модулей pod активно участвует в отправке или получении пакетов TCP RST, что может сигнализировать о нестабильном подключении или неправильно настроенных модулях pod, вызывающих перегрузку сети. Высокие показатели сброса могут указывать на то, что поды перегружены попытками подключения или сталкиваются с конкурентной борьбой за ресурсы.

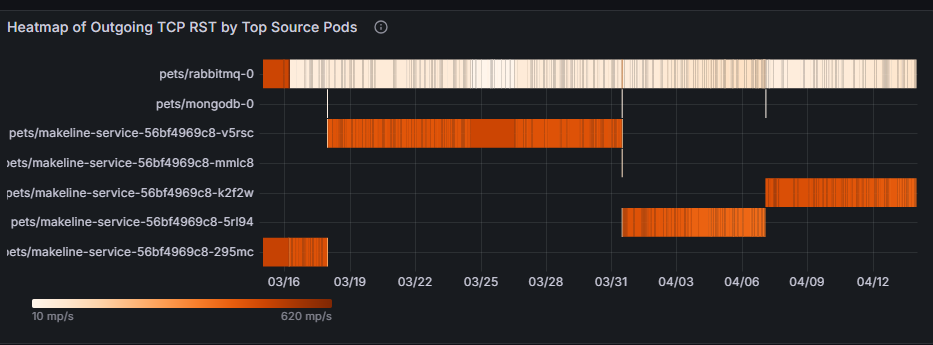
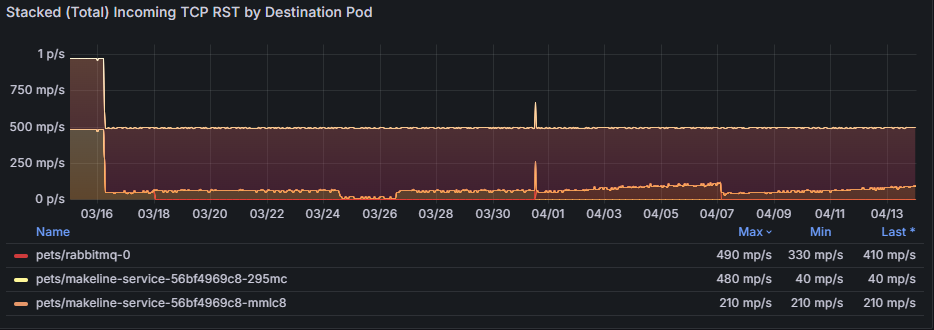
Тепловая карта исходящего TCP RST по ведущим исходным Pod-ам показывает, какие исходные Pod-ы генерируют большинство пакетов TCP RST и когда наблюдается всплеск активности. В следующем примере тепловой карты, если домашние животные или кролики-0 последовательно отображают высокие исходящие сбросы во время пиковых часов трафика, это может указывать на перегрузку приложения или его базовых ресурсов (ЦП, памяти). Решение может заключаться в оптимизации конфигурации этого pod, увеличении масштабов ресурсов или равномерном распределении трафика между репликами.
Тепловая карта входящих TCP RST по основным целевым pod-ам выявляет pod-ы, получающие наибольшее количество пакетов TCP RST, что указывает на потенциальные узкие места или проблемы с подключением в этих pod-ах. Если домашние животные или mongodb-0 часто получают пакеты RST, это может быть индикатор перегруженных подключений к базе данных или неисправных конфигураций сети. Решение может быть увеличение емкости базы данных, реализация ограничения скорости или исследование вышестоящих рабочих нагрузок, вызывающих чрезмерные подключения.
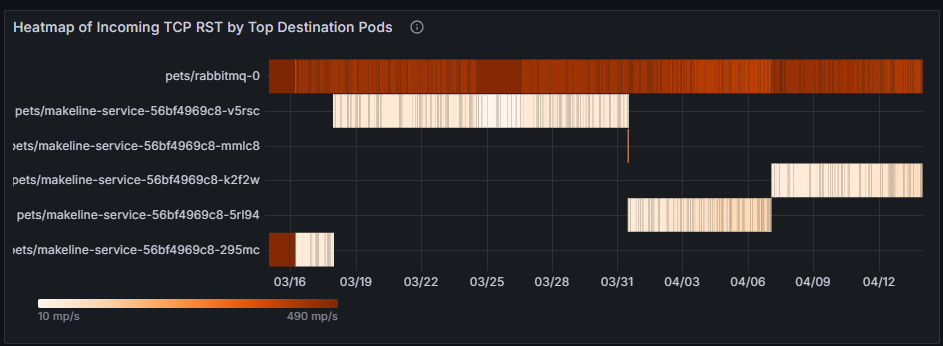
График суммарных (общих) исходящих TCP RST по исходному Pod`у предоставляет агрегированное представление о сбросах соединений, выявляя тенденции или аномалии с течением времени.

График Накопленные (общие) входящие TCP RST по целевому узлу агрегирует входящие сбросы, показывая, как перегрузка сети влияет на узлы назначения. Например, устойчивое увеличение сбросов для домашних животных/rabbitmq-0 может указывать на то, что эта служба не может эффективно обрабатывать входящий трафик, что приводит к истечении времени ожидания.








Анализ дисбалансов трафика с помощью журналов сети контейнеров
Помимо использования панелей мониторинга Grafana, можно использовать журналы сети контейнеров для анализа шаблонов трафика и выявления дисбалансов с помощью запросов KQL:
// Identify pods with high traffic volume (potential imbalances)
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| extend TCP = parse_json(Layer4).TCP
| extend SourcePort = TCP.source_port, DestinationPort = TCP.destination_port
| summarize TotalConnections = count() by SourcePodName, SourceNamespace
| top 10 by TotalConnections desc
// Analyze TCP reset patterns to identify connection issues
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| extend TCP = parse_json(Layer4).TCP
| extend Flags = TCP.flags
| where Flags contains "RST"
| summarize ResetCount = count() by SourcePodName, DestinationPodName, bin(TimeGenerated, 5m)
| order by TimeGenerated desc, ResetCount desc
Замените нужный <start-time> диапазон времени и замените <end-time> его в формате2025-08-12T00:00:00Z.
Эти запросы помогают определить дисбалансы трафика и проблемы с подключением, которые могут не сразу отображаться в визуализациях панели мониторинга.
Вариант использования 4. Мониторинг работоспособности сети и производительности кластера в режиме реального времени
Предоставление метрик работоспособности сети кластера на высоком уровне важно для обеспечения общей стабильности и производительности системы. Высокоуровневые метрики обеспечивают быстрое и комплексное представление о производительности сети кластера, позволяя администраторам легко определять потенциальные узкие места, сбои или неэффективные функции без детализации. Эти метрики, такие как задержка, пропускная способность, потери пакетов и частоты ошибок, предлагают моментальный снимок работоспособности кластера, обеспечивая упреждающий мониторинг и быстрое устранение неполадок.
У нас есть пример панели мониторинга, представляющей общую работоспособность кластера: Kubernetes/ Сети и кластеры. Давайте глубже рассмотрим общую панель мониторинга.
Определите узкие места сети: анализируя переадресованные графики байтов и пакетов , можно определить, есть ли внезапные падения или пики, указывающие на потенциальные узкие места или перегрузку в сети.

Обнаружение потери пакетов: разделы "Удалены пакеты " и " Удалены байты " помогают определить, возникает ли значительный объем потери пакетов в определенных кластерах, что может указывать на проблемы, такие как неисправное оборудование или неправильно настроенные параметры сети.

Мониторинг шаблонов трафика: с течением времени можно отслеживать шаблоны трафика, чтобы понять нормальное и ненормальное поведение, которое помогает в упреждающем устранении неполадок. Сравнивая максимальное и минимальное количество входящих и исходящих байтов и пакетов, можно проанализировать тенденции производительности и определить, вызывает ли определенное время суток или определенных рабочих нагрузок снижение производительности.

Диагностика причин удаления. Разделы причин удаления байтов по причине и пакетов, удаленных по причинам , помогают понять конкретные причины удаления пакетов, например отказы в политике или неизвестные протоколы.

Анализ, зависящий от узла: Байты, удаленные по узлам и пакетам, удаленным по графам узлов, предоставляют аналитические сведения о том, какие узлы сталкиваются с наибольшим падением пакетов. Это помогает определить проблемные узлы и принять корректирующие действия для повышения производительности сети.

Распределение TCP-подключений: график здесь означает распределение TCP-подключений между различными состояниями. Например, если на графе отображается необычно большое количество подключений в
SYN_SENTсостоянии, это может указывать на то, что узлы кластера испытывают проблемы с установкой подключений из-за задержки сети или неправильной настройки. С другой стороны, значительное количество подключений вTIME_WAITсостоянии может указывать на то, что подключения не освобождаются должным образом, что может привести к исчерпанию ресурсов.






Вариант использования 5. Диагностика проблем с сетью на уровне приложения
Наблюдение за трафиком L7 устраняет критически важные проблемы с сетью на уровне приложений, обеспечивая глубокую видимость трафика HTTP, gRPC и Kafka. Эти аналитические сведения помогают обнаруживать такие проблемы, как высокие частоты ошибок (например, ошибки на стороне клиента 4xx или 5xx), непредвиденные падения трафика, пики задержки, неравномерное распределение трафика между модулями pod и неправильно настроенные сетевые политики. Эти проблемы часто возникают в сложных архитектурах микрослужб, где зависимости между службами являются сложными, и распределение ресурсов является динамическим. Например, внезапный рост потерянных сообщений Kafka или задержка вызовов gRPC могут сигнализировать узкие места в обработке сообщений или перегрузку сети.
Предположим, у вас есть платформа электронной коммерции, развернутая в кластере Kubernetes, где интерфейсная служба использует несколько внутренних микрослужб, включая шлюз платежей (gRPC), каталог продуктов (HTTP) и службу обработки заказов, которая взаимодействует через Kafka. В последнее время пользователи стали сообщать о увеличившихся сбоях при оформлении заказа и медленной загрузке страниц. Давайте глубже рассмотрим, как выполнить RCA этой проблемы с помощью предварительно настроенных панелей мониторинга для трафика L7: Kubernetes/Networking/L7 (пространства имен) и Kubernetes/Networking/L7 (Рабочая нагрузка).
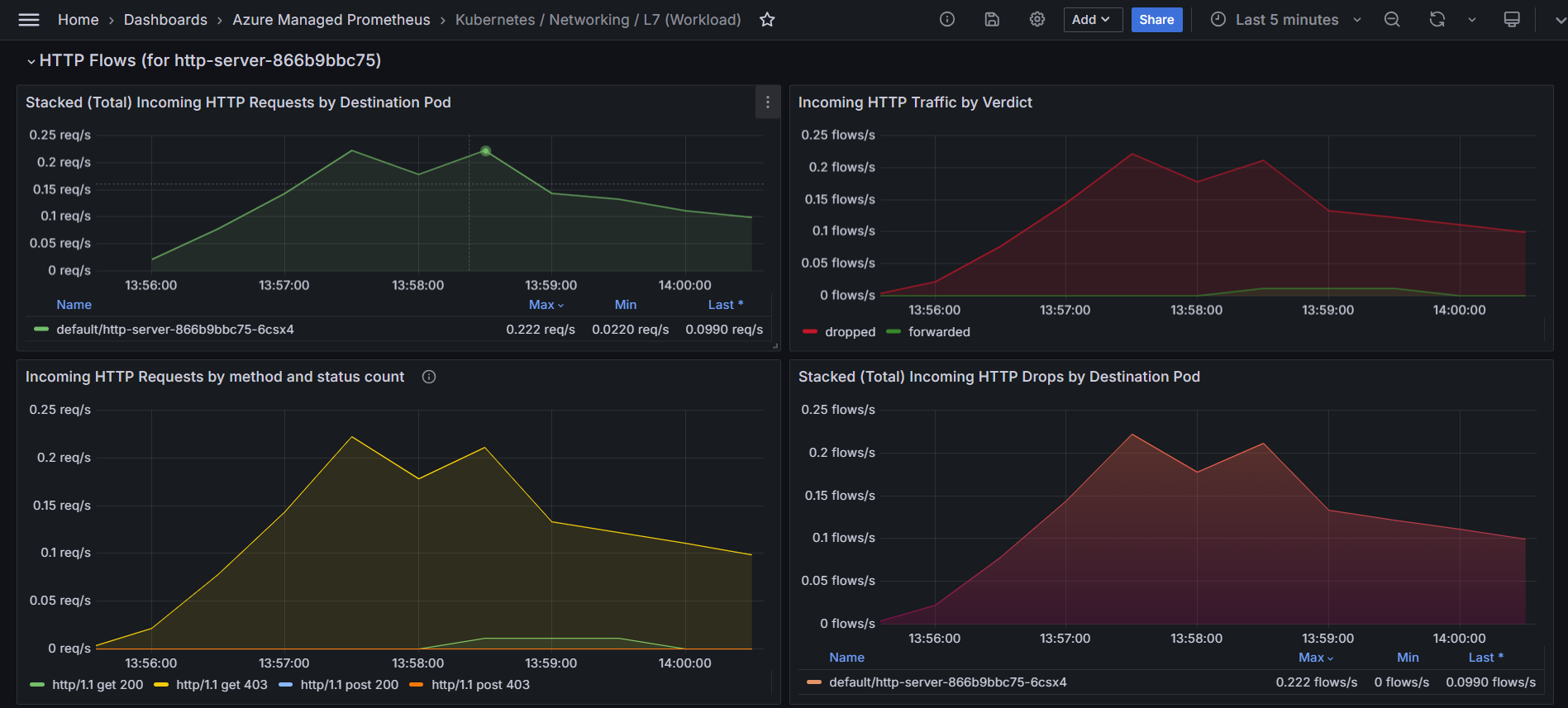
Определите шаблоны удаленных и переадресованных HTTP-запросов. На следующем графике исходящий HTTP-трафик сегментируется по вердикту, указывая, являются ли запросы "пересылаются" или "отклонены". Для платформы электронной коммерции этот график может помочь определить потенциальные узкие места или сбои в процессе оформления заказа. Если наблюдается заметное увеличение сброшенных потоков HTTP, это может указывать на такие проблемы, как неправильно настроенные политики сети, ограничения ресурсов или проблемы с подключением между фронтенд- и бэкенд-службами. Коррелируя этот график с определенными периодами времени жалоб пользователей, администраторы могут определить, совпадают ли эти падения с неудачами при оформлении заказа.

На следующем графике показана скорость исходящих HTTP-запросов с течением времени, классифицированная по их коду состояния (например, 200, 403). Этот график можно использовать для выявления пиков ошибок (например, 403 Запрещенных ошибок), которые могут указывать на проблемы с проверкой подлинности или контролем доступа. Сопоставив эти пики с определенными интервалами времени, вы можете исследовать и устранять основные проблемы, такие как неправильно настроенные политики безопасности или проблемы на стороне сервера.

Эта следующая тепловая карта указывает, какие модули pod имеют исходящие HTTP-запросы, которые привели к ошибкам 4xx. Вы можете использовать эту тепловую карту для быстрого выявления проблемных узлов и изучения причин ошибок. Устраняя эти проблемы на уровне pod, вы можете повысить общую производительность и надежность трафика L7.

Используйте следующие диаграммы, чтобы проверить, какие pods получают наибольший трафик. Это помогает определить перегруженные pod.
- Исходящие HTTP-запросы для топ-10 исходных модулей pod по умолчанию показывают стабильное количество исходящих HTTP-запросов с течением времени для первых десяти исходных модулей pod. Линия остается почти плоской, указывая на согласованный трафик без значительных пиков или падений.
- Тепловая карта исходящих HTTP-запросов для топ-10 исходных модулей pod по умолчанию использует цветовую кодировку для представления количества удаленных запросов. Темные цвета указывают на большее количество удаленных запросов, а более светлые цвета указывают на меньшее или нет удаленных запросов. Чередующиеся темные и светлые полосы указывают на периодические шаблоны в снижении количества запросов.
Эти графы предоставляют ценные сведения о сетевом трафике и производительности. Первый граф помогает понять согласованность и объем исходящего HTTP-трафика, который имеет решающее значение для мониторинга и поддержания оптимальной производительности сети. Второй график позволяет определить закономерности или периоды, когда возникают проблемы с потерянными запросами, что является ключевым для диагностики проблем с сетью или оптимизации производительности.





Ключевые факторы, на которые следует сосредоточиться во время анализа первопричин для трафика L7
Шаблоны трафика и объемы: анализ тенденций трафика для выявления всплесков, падений или дисбаланса в распределении трафика. Перегруженные узлы или службы могут привести к возникновению узких мест или отклонению запросов.
Скорость ошибок: отслеживание тенденций в ошибках 4xx (недопустимых запросов) и 5xx (сбои серверной части). Постоянные ошибки указывают на неправильные конфигурации клиента или ограничения ресурсов на стороне сервера.
Удаленные запросы: анализ удалений на определенных модулях pod или узлах. Потери часто сигнализируют о проблемах с подключением или об отказах, связанных с политикой.
Применение политик и настройка: оценка сетевых политик, механизмов обнаружения сервисов и параметров балансировки нагрузки на наличие неправильной настройки.
Тепловые карты и метрики потоков: визуализации, такие как тепловые карты, помогут быстро выявить модули с большим количеством ошибок или аномалии трафика.

Анализ трафика L7 с помощью журналов сети контейнеров
Журналы сети контейнеров предоставляют комплексные возможности анализа трафика L7 с помощью хранимых журналов и визуальных панелей мониторинга. Используйте следующие запросы KQL для анализа HTTP, gRPC и другого трафика уровня приложений:
// Analyze HTTP response codes and error rates
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where FlowType == "L7_HTTP"
| extend HTTP = parse_json(Layer4).HTTP
| extend StatusCode = HTTP.status_code
| summarize RequestCount = count() by StatusCode, SourcePodName, bin(TimeGenerated, 5m)
| order by TimeGenerated desc
// Identify pods with high HTTP 4xx or 5xx error rates
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where FlowType == "L7_HTTP"
| extend HTTP = parse_json(Layer4).HTTP
| extend StatusCode = tostring(HTTP.status_code)
| where StatusCode startswith "4" or StatusCode startswith "5"
| summarize ErrorCount = count(), UniqueErrors = dcount(StatusCode) by SourcePodName, DestinationPodName
| top 10 by ErrorCount desc
// Monitor gRPC traffic and response times
RetinaNetworkFlowLogs
| where TimeGenerated between (datetime(<start-time>) .. datetime(<end-time>))
| where FlowType == "L7_GRPC"
| extend GRPC = parse_json(Layer4).GRPC
| extend Method = GRPC.method
| summarize RequestCount = count() by SourcePodName, DestinationPodName, Method
| order by RequestCount desc
Замените нужный <start-time> диапазон времени и замените <end-time> его в формате2025-08-12T00:00:00Z.
Эти запросы дополняют визуальные панели мониторинга, предоставляя подробные сведения о производительности уровня приложений, шаблонах ошибок и распределении трафика в архитектуре микрослужб.
Мониторинг сети, включенный в мониторинг Azure
При включении управляемой службы Azure Monitor для Prometheus в кластере AKS базовые метрики мониторинга сети узлов собираются по умолчанию через целевой networkobservabilityRetina объект. Это обеспечивает следующее:
- Основные метрики сети на уровне узла: основные сведения о сетевом трафике на уровне узла
- Целевые объекты Prometheus по умолчанию: метрики наблюдаемости сети автоматически сломываются Azure Monitor
- Интеграция Azure Monitor: простая интеграция с Azure Monitor; Метрики автоматически собираются и могут быть визуализированы в Grafana
- Дополнительная настройка не требуется. Автоматическое включение при настройке Управляемого Prometheus в Azure Monitor
- Поддержка Майкрософт: поддерживается как часть Azure Monitor и AKS
Примечание. Для этого необходимо включить управляемую службу Azure Monitor для Prometheus в кластере AKS, которая может иметь связанные затраты.
Начало работы. Включение управляемой службы Azure Monitor для Prometheus в кластере AKS с помощью портала Azure или ИНТЕРФЕЙСА командной строки. Метрики наблюдаемости сети будут автоматически собираться и доступны для визуализации в Управляемой Grafana Azure.
Наблюдаемость сети с помощью Retina OSS
Хотя расширенные сетевые службы контейнеров (ACNS) — это платное предложение, которое обеспечивает комплексные возможности мониторинга сети, корпорация Майкрософт также поддерживает мониторинг сети с помощью Retina OSS, платформу наблюдения за сетями с открытым исходным кодом, которая обеспечивает основные возможности мониторинга сети.
Retina OSS — это платформа наблюдения с открытым кодом, доступная на retina.sh и GitHub. Он предоставляет:
- Наблюдаемость сети на основе eBPF: использует технологии eBPF для сбора аналитических сведений с минимальными затратами
- Глубокий анализ трафика с помощью контекста Kubernetes: комплексное отслеживание и анализ потоков сетевого трафика с полной интеграцией Kubernetes
- Расширенная коллекция метрик: метрики уровня 4, метрики DNS и возможности сбора распределенных пакетов
- Расширяемость на основе подключаемого модуля: настройка и расширение функциональных возможностей с помощью архитектуры подключаемого модуля
- Метрики, совместимые с Prometheus: экспорт комплексных сетевых метрик в формате Prometheus с настраиваемыми режимами метрик
- Распределённый захват пакетов: сбор пакетов по запросу на нескольких узлах для глубокого устранения неполадок
- Платформа и не зависящая от CNI: работает с любым кластером Kubernetes (AKS, с поддержкой Arc, локальной средой), любой ОС (Linux или Windows) и любой CNI
- Поддержка сообщества: открытый код с поддержкой сообщества и вкладами
- Самостоятельное управление: полный контроль над развертыванием и конфигурацией
- Интеграция Hubble: интегрируется с Hubble Cilium для получения дополнительных сведений о сети
Приступая к работе: развертывание OSS Retina с помощью диаграмм Helm или манифестов Kubernetes из официального репозитория Retina. Настройте Prometheus и Grafana для визуализации метрик, настройки глубокого анализа трафика с помощью контекста Kubernetes, включения сбора распределенных пакетов для расширенного устранения неполадок и настройки функциональности с помощью архитектуры на основе подключаемых модулей для конкретных вариантов использования.
Сравнение предложений для наблюдения за сетями
| Offering | Support | Себестоимость | Управление | Развертывание | Варианты использования |
|---|---|---|---|---|---|
| Расширенные сетевые службы контейнеров (ACNS) | Корпоративная поддержка Майкрософт | Платная служба Azure | Полностью управляемая корпорацией Майкрософт | Интеграция Azure с одним щелчком мыши | Управляемое корпоративное наблюдение: сетевые потоки на уровне pod, метрики уровня pod, метрики DNS, постоянные сохраненные журналы, анализ трафика уровня 7, применение политики безопасности сети, отчеты о соответствии, расширенные панели мониторинга Grafana, аналитические сведения, на основе ИИ |
| Мониторинг сети (Azure Monitor) | Поддержка Майкрософт в рамках Azure Monitor | Включена в управляемый Prometheus в Azure Monitor (применяются затраты на Azure Monitor) | Полностью управляемая корпорацией Майкрософт | Автоматический при включении Управляемого Prometheus в Azure Monitor | Мониторинг сети узлов: только метрики сети на уровне кластера и узла, нет видимости на уровне pod, без хранимых журналов, без анализа DNS, подходящего для базового мониторинга инфраструктуры и пользователей, которые хотят минимального сетевого наблюдения без дополнительной настройки |
| Сетчатка OSS | Поддержка сообщества | Бесплатный и открытый исходный код | Самостоятельное управление | Настройка вручную с помощью Helm/manifests в любом кластере Kubernetes | Неуправляемая расширенная наблюдаемость: сбор пакетов в режиме реального времени, сбор пользовательских метрик, глубокое сетевое анализ на основе eBPF, интеграция Hubble, многооблачные развертывания, настраиваемые конвейеры наблюдения, расширенная отладка с интеграцией tcpdump/Wireshark и среды разработки и тестирования |
Подробнее
Чтобы приступить к работе с сетевой наблюдаемостью в Azure Kubernetes Service (AKS):
Расширенные сетевые услуги контейнеров (ACNS)
- Настройка журналов сети контейнеров. Узнайте, как настроить журналы сети контейнеров для комплексного наблюдения за сетями.
- Дополнительные сведения о расширенных сетевых службах контейнеров для службы Azure Kubernetes (AKS) см. в статье "Что такое расширенные сетевые службы контейнеров для службы Azure Kubernetes (AKS)?"
- Настройка мониторинга. Настройкаинтеграции Управляемой Grafana Azure для расширенных визуализаций
- Сведения о сетевой безопасности: изучение функций безопасности сети контейнеров для применения политик и обнаружения угроз
Мониторинг сети (Azure Monitor)
- Интеграция Azure Monitor. Настройка Azure Monitor для контейнеров для просмотра базовых сетевых метрик
Сетчатка OSS
- Официальная документация: посетите retina.sh для получения комплексной документации и руководств
- Репозиторий GitHub: доступ к репозиторию Microsoft Retina GitHub для руководства по установке, примеры и поддержка сообщества
- Поддержка сообщества: присоединяйтесь к обсуждениям сообщества Retina для получения справки и рекомендаций