Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
С помощью пользовательской речи можно оценить и повысить точность распознавания речи для приложений и продуктов. Пользовательская модель речи может использоваться для преобразования речи в режиме реального времени в текст, перевод речи и пакетное транскрибирование.
Вне поля распознавание речи использует универсальную языковую модель в качестве базовой модели, которая обучена с данными, принадлежащими Майкрософт, и отражает часто используемый язык. Базовая модель предварительно обучена диалектами и фонетиками, представляющими различные общие домены. При выполнении запроса на распознавание речи по умолчанию используется последняя базовая модель для каждого поддерживаемого языка. Базовая модель хорошо работает в большинстве сценариев распознавания речи.
Пользовательскую модель можно использовать для расширения базовой модели, чтобы улучшить распознавание предметно-ориентированной лексики, характерной для приложения, путем предоставления текстовых данных для обучения модели. Ее также можно использовать для улучшения распознавания на основе определенных условий звука приложения, предоставляя звуковые данные с референтными транскрибированиями.
Модель также можно обучить структурированным текстом, если данные соответствуют шаблону, чтобы указать пользовательские произношения, а также настроить форматирование текста с помощью настраиваемой нормализации текста, настраиваемой перезаписи и настраиваемой фильтрации ненормативной лексики.
Как это работает?
С помощью пользовательской речи можно отправлять собственные данные, тестировать и обучать пользовательскую модель, сравнивать точность между моделями и развертывать модель в настраиваемую конечную точку.
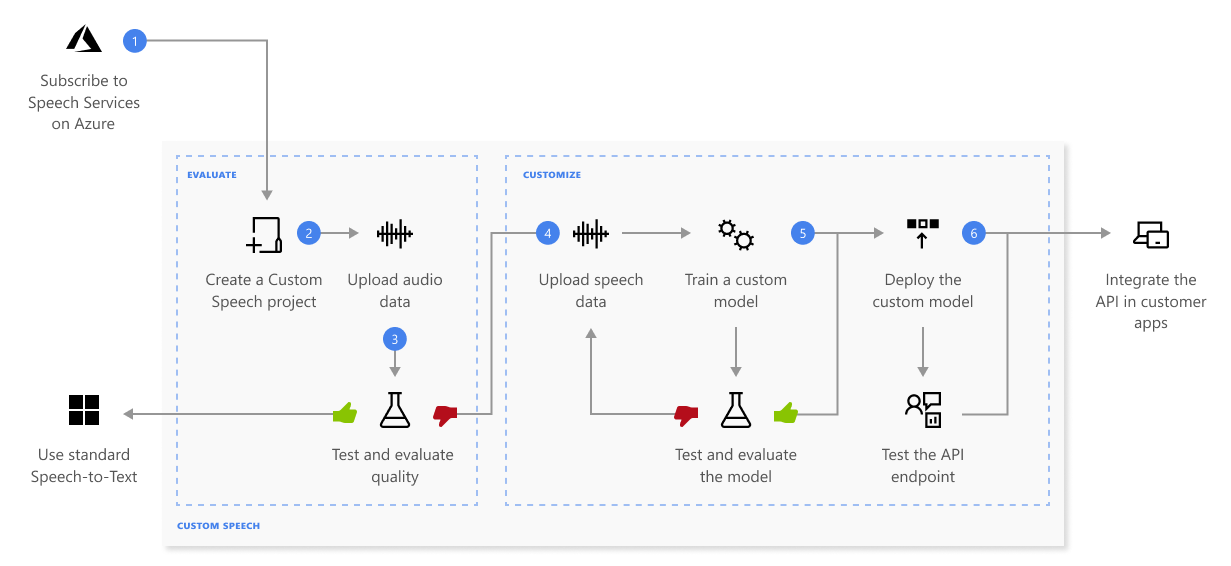
Ниже приведены дополнительные сведения о последовательности шагов, показанных на предыдущей схеме:
Создайте проект и выберите модель. Если вы обучаете пользовательскую модель с звуковыми данными, выберите ресурс службы в регионе с выделенным оборудованием для обучения звуковых данных. Дополнительные сведения см. в сносках в таблице регионов .
Загрузка тестовых данных. Отправьте тестовые данные для оценки речи в текстовое предложение для приложений, инструментов и продуктов.
Train a model (Обучение модели). Предоставьте письменные расшифровки и связанный текст вместе с соответствующими звуковыми данными. Тестирование модели до и после обучения является необязательным, но рекомендуется.
Примечание.
Вы оплачиваете использование пользовательской модели речи и размещение конечных точек. Вы также будете взимать плату за обучение пользовательской модели речи, если базовая модель была создана 1 октября 2023 г. и более поздних версий. Плата за обучение не взимается, если базовая модель была создана до октября 2023 года. Дополнительные сведения см. в разделе о ценах на службы "Azure Speech" в инструментах Foundry и разделе "Плата за адаптацию" в руководстве по миграции речи в текст 3.2.
Проверка качества распознавания речи. Используйте Speech Studio для воспроизведения загруженных аудиофайлов и проверки качества распознавания ваших тестовых данных.
Количественное тестирование модели. Оцените и улучшите точность преобразования речи в текстовую модель. Служба "Речь" предоставляет количественную частоту ошибок слова (WER), которую можно использовать для определения необходимости дополнительного обучения.
Развертывание модели. Когда результаты теста будут удовлетворительными, разверните модель в пользовательской конечной точке. За исключением пакетного транскрибирования, необходимо развернуть пользовательскую конечную точку для использования пользовательской модели речи.
Совет
Размещенная конечная точка развертывания не требуется для использования пользовательской речи с API транскрибирования пакетной службы. Вы можете сохранить ресурсы, если пользовательская модель речи используется только для пакетной транскрибирования. Дополнительные сведения см. в разделе Цены на службы "Речь".
Выбор модели
Существует несколько подходов к использованию пользовательских моделей речи:
- Базовая модель изначально обеспечивает точное распознавание речи для различных сценариев. Базовые модели периодически обновляются для повышения точности и качества. Если вы пользуетесь базовыми моделями, применяйте последние версии, заданные по умолчанию. Если необходимая возможность настройки доступна только для более старой модели, можно выбрать старую базовую модель.
- Пользовательская модель дополняет базовую модель, позволяя включить тематический словарь, который будет использоваться во всех областях личного домена.
- Можно использовать несколько пользовательских моделей, если личный домен содержит несколько областей, каждая из которых имеет определенный словарь.
Один из рекомендуемых способов узнать, достаточно ли базовой модели, чтобы проанализировать транскрибирование, созданное из базовой модели, и сравнить его с человеческой расшифровкой для того же звука. Вы можете сравнить расшифровки и получить оценку частоты ошибок в словах (WER). Если оценка WER высока, рекомендуется обучить пользовательскую модель для распознавания неправильно определенных слов.
Рекомендуется использовать несколько моделей, если словарь меняется в зависимости от предметных областей. Например, олимпийские комментаторы сообщают о различных событиях, для каждого из которых используется собственный жаргон. Поскольку все словари олимпийских мероприятий значительно отличаются друг от друга, создание пользовательской модели для определенного события повышает точность за счет связывания данных речевых фрагментов только с этим конкретным событием. В результате модели не требуется просматривать несвязанные данные при поиске сопоставления. Тем не менее для обучения по-прежнему требуется много разнообразных обучающих данных. Используйте записи речи нескольких комментаторов разного пола и возраста, с разными акцентами и т. д.
Стабильность и жизненный цикл модели
Базовая модель или пользовательская модель, развернутая в конечной точке с помощью пользовательской речи, исправлена, пока не решите обновить ее. Точность распознавания речи и качество остаются согласованными даже при выпуске новой базовой модели. Это позволяет блокировать поведение конкретной модели, пока вы не решите использовать более новую модель.
Вы можете использовать собственную обученную модель или моментальный снимок базовой модели, но только в течение ограниченного времени. Дополнительные сведения см. в разделе Жизненный цикл модели и конечной точки.
Ответственное применение ИИ
Система ИИ включает не только технологию, но и людей, которые используют ее, людей, пострадавших от нее, и среды, в которой она развернута. Ознакомьтесь с заметками о прозрачности, чтобы узнать об использовании и развертывании ответственного искусственного интеллекта в системах.
- Примечание о прозрачности и сценарии использования
- Характеристики и ограничения
- Интеграция и ответственное использование
- Данные, конфиденциальность и безопасность