Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это содержимое относится к:![]() версии 4.0 (GA) | Предыдущие версии:
версии 4.0 (GA) | Предыдущие версии:![]() версии 3.1 (GA)
версии 3.1 (GA)![]() версии 3.0 (вывод из эксплуатации)
версии 3.0 (вывод из эксплуатации)![]() версии 2.1 (вывод из эксплуатации)
версии 2.1 (вывод из эксплуатации)
Это содержимое относится к:![]() версии 3.1 (GA) | Последняя версия:
версии 3.1 (GA) | Последняя версия:![]() версии 4.0 (GA) | Предыдущие версии:
версии 4.0 (GA) | Предыдущие версии:![]() версии 3.0
версии 3.0![]() версии 2.1
версии 2.1
Это содержимое относится к:![]() версия 2.1 | Последняя версия:
версия 2.1 | Последняя версия:![]() версия 4.0 (GA)
версия 4.0 (GA)
Аналитика документов использует расширенную технологию машинного обучения для идентификации документов, обнаружения и извлечения информации из форм и документов и возврата извлеченных данных в структурированных выходных данных JSON. С помощью аналитики документов можно использовать модели анализа документов, предварительно созданные, предварительно обученные или обученные автономные пользовательские модели.
Теперь пользовательские модели включают пользовательские модели классификации для сценариев, где необходимо определить тип документа перед вызовом модели извлечения. Модели классификатора доступны начиная с 2023-07-31 (GA) API. Модель классификации может быть связана с пользовательской моделью извлечения для анализа и извлечения полей из форм и документов, относящихся к вашему бизнесу. Автономные пользовательские модели извлечения можно объединить для создания составных моделей.
Типы пользовательских моделей документов
Пользовательские модели документов могут быть одним из двух типов, пользовательского шаблона или пользовательской формы и пользовательских нейронных или пользовательских моделей документов. Процесс маркировки и обучения для обеих моделей идентичен, но модели отличаются следующим образом:
Пользовательские модели извлечения
Чтобы создать пользовательскую модель извлечения, разметьте набор данных документов с нужными для извлечения значениями и обучите модель на размеченном наборе данных. Чтобы приступить к работе, вам потребуется только пять примеров одного и того же типа формы или документа.
Пользовательская нейронная модель
Важно
API Интеллектуального управления документами v4.0 2024-11-30 (GA) поддерживает пользовательскую нейронную модель с перекрывающимися полями, обнаружением подписей и уверенностью на уровне таблиц, строк и ячеек.
Пользовательская нейронная модель использует модели глубокого обучения и базовую модель, обученную на большой коллекции документов. Затем эта модель настраивается или адаптируется к вашим данным при обучении этой модели с использованием помеченного набора данных. Пользовательские нейронные модели поддерживают извлечение ключевых полей данных из структурированных, полуструктурированных и неструктурированных документов. При выборе между двумя типами моделей начните с нейронной модели, чтобы определить, соответствует ли она вашим функциональным потребностям. С помощью версии 4.0 пользовательская нейронная модель поддерживает обнаружение подписей, достоверность таблиц и перекрывающиеся поля. Дополнительные сведения о пользовательских моделях документов см. в разделе о нейронных моделях.
Пользовательская модель шаблона
Пользовательский шаблон или модель пользовательской формы использует единообразный визуальный шаблон для извлечения размеченных данных. Различия в визуальной структуре ваших документов сказываются на точности вашей модели. Структурированные формы, такие как анкеты или приложения, являются примерами согласованных визуальных шаблонов.
Обучающая выборка состоит из структурированных документов, в которых форматирование и макет являются статическими и постоянными от одного экземпляра документа к другому. Пользовательские модели шаблонов поддерживают пары "ключ-значение", метки выбора, таблицы, поля подписи и регионы. Модели шаблонов могут быть обучены на документах на каждом из поддерживаемых языков. Дополнительные сведения см. в разделе "Пользовательские модели шаблонов".
Если язык документов и сценариев извлечения поддерживает пользовательские нейронные модели, рекомендуется использовать пользовательские нейронные модели для моделей шаблонов для повышения точности.
Совет
Чтобы убедиться, что учебные документы представляют согласованный визуальный шаблон, удалите все введенные пользователем данные из каждой формы в наборе. Если пустые формы идентичны во внешнем виде, они представляют согласованный визуальный шаблон.
Дополнительные сведения см. в разделе"Интерпретация и повышение точности и достоверности" для пользовательских моделей.
Требования к входным данным
Для получения наилучших результатов предоставьте одну четкую фотографию или высококачественное сканирование на каждый документ.
Поддерживаемые форматы файлов:
Модель PDF Изображение: jpeg/jpg, ,pngbmptiffheifMicrosoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Прочитать ✔ ✔ ✔ Макет ✔ ✔ ✔ Общий документ ✔ ✔ Предварительно собранный ✔ ✔ Настраиваемое извлечение ✔ ✔ Настраиваемая классификация ✔ ✔ ✔ ✱ Microsoft Office файлы в настоящее время не поддерживаются для других моделей или версий.
Для PDF и TIFF можно обрабатывать до 2000 страниц (с подпиской на бесплатный уровень только первые две страницы обрабатываются).
Размер файла для анализа документов предназначен
500 MBдля платного уровня (S0) и4 MBбесплатного уровня (F0).Размеры изображения должны составлять от 50 x 50 пикселей до 10 000 пикселей x 10 000 пикселей.
Если pdf-файлы заблокированы паролем, перед отправкой необходимо удалить блокировку.
Минимальная высота извлеченного текста составляет 12 пикселей для изображения 1024 x 768 пикселей. Это измерение соответствует примерно тексту размером в
8пунктов при разрешении150точек на дюйм.Для обучения пользовательской модели максимальное количество страниц для обучающих данных составляет 500 для пользовательской модели шаблона и 50 000 для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет
50 MBдля шаблонной модели и1 GBдля нейронной сети.Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1 GBне более 10 000 страниц.
Оптимальные обучающие данные
Входные данные обучения являются основой любой модели машинного обучения. Он определяет качество, точность и производительность модели. Поэтому важно создать лучшие входные данные обучения для проекта Аналитики документов. При использовании пользовательской модели аналитики документов вы предоставляете собственные обучающие данные. Ниже приведены несколько советов, которые помогут эффективно обучить модели:
Используйте текстовые файлы, а не pdf-файлы на основе изображений, если это возможно. Одним из способов идентификации изображения*на основе PDF является попытка выбора определенного текста в документе. Если вы можете выбрать только все изображение текста, документ основан на изображении, а не на основе текста.
Организуйте свои обучающие документы, используя подпапку для каждого формата (JPEG/JPG, PNG, BMP, PDF или TIFF).
Используйте формы, имеющие все доступные поля.
Используйте формы с различными значениями в каждом поле.
Используйте более крупный набор данных (более пяти обучающих документов), если изображения являются низким качеством.
Определите, нужно ли использовать одну модель или несколько моделей, состоящих из одной модели.
Рассмотрите возможность сегментирования набора данных в папки, где каждая папка является уникальным шаблоном. Обучите одну модель для каждой папки и объедините полученные модели в одну конечную точку. Точность модели может уменьшиться при наличии различных форматов, проанализированных с помощью одной модели.
Рассмотрите возможность сегментирования набора данных для обучения нескольких моделей, если форма имеет варианты с форматами и разрывами страниц. Пользовательские формы используют согласованный визуальный шаблон.
Убедитесь, что у вас есть сбалансированный набор данных, учитывая форматы, типы документов и структуру.
Режим сборки
Эта build custom model операция добавляет поддержку шаблонов и нейронных пользовательских моделей. Предыдущие версии REST API и клиентских библиотек поддерживают только один режим сборки, который теперь называется режимом шаблона .
Модели шаблонов принимают только документы, имеющие ту же базовую структуру страницы ( унифицированный визуальный вид) или то же относительное расположение элементов в документе.
Нейронные модели поддерживают документы, имеющие одну и ту же информацию, но разные структуры страниц. Примеры этих документов включают формы W2 Соединённых Штатов, которые содержат одну и ту же информацию, но различаются по внешнему виду среди разных компаний.
Эта таблица содержит ссылки на ссылки на справочники по языку программирования в режиме сборки и примеры кода на GitHub:
| Язык программирования | Справочник по пакету SDK | Пример кода |
|---|---|---|
| C#/.NET | Структура DocumentBuildMode | Sample_BuildCustomModelAsync |
| Java | Класс DocumentBuildMode | BuildDocumentModel |
| Javascript | Тип DocumentBuildMode | buildModel.js |
| Python | Перечисление DocumentBuildMode |
Сравнение функций модели
В следующей таблице сравниваются пользовательские функции шаблона и пользовательские нейронные функции:
| Функция | Кастомный шаблон (форма) | Настраиваемый нейронный (документ) |
|---|---|---|
| Структура документа | Шаблон, форма и структурированная структура | Структурированные, полуструктурированные и неструктурированные |
| Время обучения | 1–5 минут | 30 минут до 12 часов* |
| Извлечение данных | Пары "ключ-значение", таблицы, знаки выбора, координаты и подписи | Пары "ключ-значение", метки выделения и таблицы |
| Перекрывающиеся поля | Не поддерживается | Поддерживается |
| Варианты документов | Требуется модель для каждого варианта | Использует одну модель для всех вариантов |
| Поддержка языка | Пользовательский шаблон поддержки языков | Поддержка настройки нейронного языка |
*-По умолчанию время обучения составляет 30 минут; включите платное обучение, чтобы иметь возможность обучать модель дольше 30 минут. Проверить больше сведений о поддержке обучения для пользовательских нейронных сетей
Пользовательская модель классификации
Классификация документов — это новый сценарий, поддерживаемый аналитикой документов с API 2023-07-31 (v3.1 GA). API классификатора документов поддерживает сценарии классификации и разделения. Обучите модель классификации, чтобы определить различные типы документов, которые поддерживаются вашим приложением. Входной файл для модели классификации может содержать несколько документов и классифицирует каждый документ в соответствующем диапазоне страниц. Дополнительные сведения см. в разделе "Пользовательские модели классификации".
Примечание
Модель v4.0 2024-11-30 (GA) классификации документов поддерживает типы документов Office для классификации. Эта версия API также содержит добавочное обучение для модели классификации.
Средства пользовательской модели
Модели Аналитики документов версии 3.1 и более поздних версий поддерживают следующие средства, приложения и библиотеки, программы и библиотеки:
| Функция | Ресурсы | Идентификатор модели |
|---|---|---|
| Пользовательская модель | • Document Intelligence Studio • REST API • C# SDK • Python SDK |
custom-model-id |
Жизненный цикл пользовательской модели
Жизненный цикл пользовательской модели зависит от версии API, используемой для обучения. Если версия API является общедоступной версией, пользовательская модель имеет тот же жизненный цикл, что и эта версия. Пользовательская модель недоступна для вывода, если версия API устарела. Если версия API является предварительной версией, пользовательская модель имеет тот же жизненный цикл, что и предварительная версия API.
Аналитика документов версии 2.1 поддерживает следующие средства, приложения и библиотеки:
Примечание
Доступны пользовательские типы моделей: настраиваемые нейронные сети и настраиваемые шаблоны в API версии 3.1 и 3.0 для интеллектуальной обработки документов.
| Функция | Ресурсы |
|---|---|
| Пользовательская модель | • Инструмент разметки документов • REST API • Клиентская библиотека SDK • Контейнер Docker для разметки документов |
Создание пользовательской модели
Извлеките данные из конкретных или уникальных документов с помощью пользовательских моделей. Вам потребуются следующие ресурсы:
Подписка Azure. Вы можете создать его бесплатно.
Экземпляр Document Intelligence на портале Microsoft Azure. Вы можете использовать бесплатную ценовую категорию (
F0) для пробной службы. После развертывания ресурса выберите "Перейти к ресурсу" , чтобы получить ключ и конечную точку.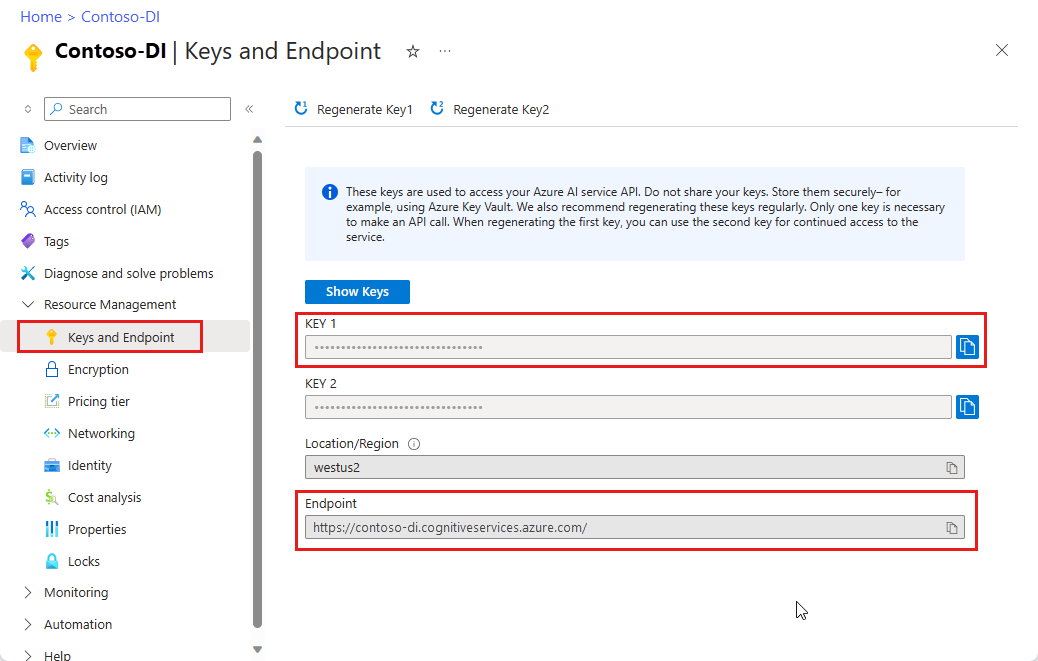
Пример средства маркировки
Совет
- Для улучшения пользовательского опыта и повышения качества модели воспользуйтесь Студией аналитики документов версии 3.0.
- Студия версии 3.0 поддерживает любую модель, обученную на данных, помеченных версией 2.1.
- Дополнительные сведения о миграции с версии 2.1 до версии 3.0 см. в руководстве по миграции API.
- Посмотрите наш REST API или C#, Java, JavaScript или Python SDK в разделе /quickstarts, чтобы начать работу с версией 3.0.
Средство создания меток для аналитики документов — это средство открытый код, позволяющее протестировать новейшие функции аналитики документов и оптического распознавания символов (OCR).
Попробуйте краткое руководство по работе с инструментом Sample Labeling, чтобы начать создавать и использовать пользовательскую модель.
Document Intelligence Studio
Примечание
Document Intelligence Studio доступен с API версии 3.1 и версии 3.0.
На домашней странице Document Intelligence Studio выберите пользовательские модели извлечения.
В разделе "Мои проекты" выберите "Создать проект".
Заполните поля сведений о проекте.
Сконфигурируйте ресурс службы, добавив учетную запись хранения и контейнер BLOB для подключения источника ваших данных для обучения.
Просмотрите и создайте проект.
Добавьте примеры документов для маркировки, сборки и тестирования вашей пользовательской модели.
Подробное пошаговое руководство по созданию первой пользовательской модели извлечения см. в статье"Создание пользовательской модели извлечения".
Сводка извлечения пользовательских моделей
В этой таблице сравниваются поддерживаемые области извлечения данных:
| Модель | Поля формы | Метки выделения | Структурированные поля (таблицы) | Подпись | Маркировка регионов | Перекрывающиеся поля |
|---|---|---|---|---|---|---|
| Пользовательский шаблон | ✔ | ✔ | ✔ | ✔ | ✔ | n/a |
| Настраиваемый нейронный | ✔ | ✔ | ✔ | ✔ | * | ✔ |
Символы таблицы:
✔ — поддерживается
**n/a— в настоящее время недоступно;
*-Ведет себя по-разному в зависимости от модели. При использовании моделей шаблонов искусственные данные создаются во время обучения. При использовании нейронных моделей выбран существующий текст, распознанный в регионе.
Совет
Чтобы выбрать между двумя типами моделей, начните с пользовательской нейронной модели, если она соответствует вашим функциональным потребностям. Дополнительные сведения о пользовательских нейронных моделях см. в разделе "Настраиваемые нейронные модели".
Параметры разработки пользовательской модели
В следующей таблице описываются функции, доступные с соответствующими инструментами и клиентскими библиотеками. В качестве рекомендации убедитесь, что вы используете совместимые инструменты, перечисленные здесь.
| Тип документа | REST API | SDK | Модели маркировки и тестирования |
|---|---|---|---|
| Пользовательский шаблон версии 4.0 v3.1 v3.0 | Аналитика документов 3.1 | Пакет SDK для аналитики документов | Document Intelligence Studio |
| Кастомная нейросеть v4.0, v3.1, v3.0 | Аналитика документов 3.1 | Пакет SDK для аналитики документов | Document Intelligence Studio |
| Пользовательская форма версии 2.1 | API Интеллекта Документов 2.1 GA | Пакет SDK для аналитики документов | Пример средства маркировки |
Примечание
Пользовательские модели шаблонов, обученные с помощью API 3.0, имеют несколько улучшений по сравнению с API 2.1, которые связаны с усовершенствованиями подсистемы OCR. Наборы данных, используемые для обучения пользовательской модели шаблона с помощью API 2.1, по-прежнему можно использовать для обучения новой модели с помощью API 3.0.
Для получения наилучших результатов следует предоставить одно четкое фото или высококачественное сканирование на документ.
Поддерживаемые форматы файлов: JPEG/JPG, PNG, BMP, TIFF и PDF (текстовые или сканированные). PDF-файлы с встраиваемым текстом наилучшим образом устраняют возможность ошибки в извлечении символов и их расположении.
Файлы PDF и TIFF, до 2000 страниц, можно обрабатывать. С подпиской на бесплатный уровень обрабатываются только первые две страницы.
Размер файла должен быть менее 500 МБ для платного уровня (S0) и 4 МБ для бесплатного уровня (F0).
Размеры изображения должны составлять от 50 x 50 пикселей до 10 000 x 10 000 пикселей.
Размеры PDF до 17 x 17 дюймов, соответствующие размеру бумаги Legal, A3 или меньшему.
Общий размер обучающих данных составляет 500 страниц или меньше.
PDF-файлы, заблокированные паролем, должны удалить блокировку пароля перед отправкой.
Совет
Обучающие данные:
- По возможности используйте текстовые PDF-документы вместо документов на основе изображений. Сканированные PDF-файлы обрабатываются как изображения.
- Укажите только один экземпляр формы для каждого документа.
- Для заполненных форм используйте примеры с заполненными полями.
- Используйте формы с разными значениями в каждом поле.
- Если изображения форм имеют более низкое качество, используйте более крупный набор данных. Например, используйте от 10 до 15 изображений.
Поддерживаемые языки и локали
Ознакомьтесь со страницей поддержки языка — пользовательские модели для полного списка поддерживаемых языков.
Дальнейшие действия
Попробуйте обработать собственные формы и документы с помощью средства маркировки образцов для интеллектуального анализа документов.
Выполните краткое руководство по анализу документов и начните создавать приложение для обработки документов на выбранном языке разработки.
Попробуйте обработать собственные формы и документы с помощью Document Intelligence Studio.
Выполните краткое руководство по анализу документов и начните создавать приложение для обработки документов на выбранном языке разработки.