Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это содержимое относится к:![]() v4.0 (GA) | Предыдущие версии:
v4.0 (GA) | Предыдущие версии:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Примечание.
Чтобы извлечь текст из изображений извне, таких как метки, уличные знаки и плакаты, используйте функцию анализа изображений Azure версии 4.0, оптимизированную для обычных (не документальных) изображений с синхронным API с улучшенной производительностью. Эта возможность упрощает внедрение OCR в сценарии взаимодействия с пользователем в режиме реального времени.
Модель оптического распознавания символов для чтения документов (OCR) выполняется с более высоким разрешением, чем azure Vision Read и извлекает печатный и рукописный текст из документов PDF и сканированных изображений. Она также включает поддержку извлечения текста из документов Microsoft Word, Excel, PowerPoint и HTML. Он обнаруживает абзацы, текстовые строки, слова, расположения и языки. Модель чтения — это базовый механизм OCR для других предварительно созданных моделей аналитики документов, таких как макет, общий документ, счет, квитанция, удостоверение (идентификатор), карточка медицинского страхования, W2 в дополнение к пользовательским моделям.
Что такое оптическое распознавание символов?
Оптическое распознавание символов (OCR) для документов оптимизировано для больших текстовых документов в нескольких форматах файлов и глобальных языках. Он включает такие функции, как сканирование изображений документов с более высоким разрешением, чтобы лучше обрабатывать меньший и плотный текст; обнаружение абзаца; и управление заполненными формами. Возможности OCR также включают расширенные сценарии, такие как одинарные поля символов и точное извлечение ключевых полей, часто найденных в счетах, квитанциях и других предварительно созданных сценариях.
Варианты разработки (версия 4)
Аналитика документов версии 4.0: 2024-11-30 (GA) поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Идентификатор модели |
|---|---|---|
| Чтение модели OCR | • Студия Document Intelligence • REST API • SDK для C# • SDK для Python • SDK для Java • SDK для JavaScript |
prebuilt-read |
Требования к входным данным (версия 4)
Поддерживаются следующие форматы файлов.
| Модель | Изображение: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Читать | ✔ | ✔ | ✔ |
| Макет | ✔ | ✔ | ✔ |
| Общий документ | ✔ | ✔ | |
| Предварительно собранный | ✔ | ✔ | |
| Настраиваемая функция извлечения | ✔ | ✔ | |
| Настраиваемая классификация | ✔ | ✔ | ✔ |
- Фотографии и сканы: для получения наилучших результатов предоставьте одну чёткую фотографию или высококачественный скан на каждый документ.
- PDF и TIFF: для PDF и TIFF можно обрабатывать до 2000 страниц. (С подпиской на бесплатный уровень обрабатываются только первые две страницы.)
- Размер файла: размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и 4 МБ для бесплатного уровня (F0).
- Размеры изображения: размеры должны находиться в диапазоне от 50 пикселей до 10 000 пикселей x 10 000 пикселей.
- Блокировки паролей. Если pdf-файлы заблокированы паролем, необходимо удалить блокировку перед отправкой.
- Высота текста: минимальная высота извлеченного текста составляет 12 пикселей для изображения 1024 x 768 пикселей. Это измерение соответствует примерно тексту размером 8 пунктов при 150 точках на дюйм.
- Обучение пользовательской модели: максимальное количество страниц для обучающих данных составляет 500 для пользовательской модели шаблона и 50 000 для пользовательской нейронной модели.
- Обучение пользовательской модели извлечения: общий размер обучающих данных составляет 50 МБ для модели шаблона и 1 ГБ для нейронной модели.
- Обучение пользовательской модели классификации: общий размер обучающих данных составляет 1 ГБ, не более 10 000 страниц. Для 2024-11-30 (GA) общий размер обучающих данных составляет 2 ГБ с максимум 10 000 страниц.
- Типы файлов Office (DOCX, XLSX, PPTX): максимальная длина строки составляет 8 миллионов символов.
Начало работы с моделью чтения (версия 4)
Попробуйте извлечь текст из форм и документов с помощью Document Intelligence Studio. Вам потребуются следующие ресурсы:
Подписка Azure — ее можно создать бесплатно.
Экземпляр Интеллектуальной обработки документов в портале Azure. Вы можете использовать бесплатный ценовой уровень (
F0), чтобы попробовать сервис. После развертывания ресурса выберите Перейти к ресурсу, чтобы получить ключ и конечную точку.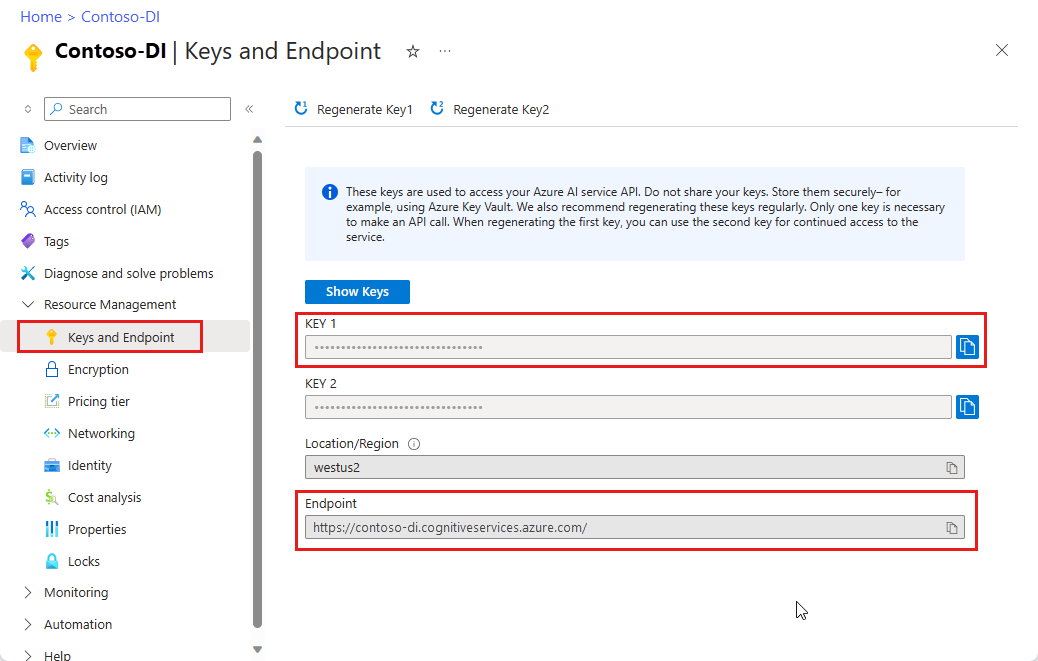
Примечание.
В настоящее время Студия аналитики документов не поддерживает форматы файлов Microsoft Word, Excel, PowerPoint и HTML.
Пример документа, обработанный с помощью Document Intelligence Studio

На домашней странице Document Intelligence Studio выберите "Чтение".
Вы можете проанализировать пример документа или отправить собственные файлы.
Нажмите кнопку "Выполнить анализ", а при необходимости настройте параметры анализа:

Поддерживаемые языки и локали (v4)
См. страницу "Поддержка языка" — модели анализа документов для полного списка поддерживаемых языков.
Извлечение данных (версия 4)
Примечание.
Microsoft Word и HTML-файл поддерживаются в версии 4.0. Следующие возможности в настоящее время не поддерживаются.
- Для каждого объекта страницы не возвращаются угол, ширина/высота и единица измерения.
- Для каждого обнаруженного объекта отсутствует ограничивающий многоугольник или ограничивающая область.
- Диапазон страниц (
pages) не возвращается в качестве возвращаемого параметра. - Нет
linesобъекта.
Pdf-файлы, доступные для поиска
Возможность PDF с возможностью поиска позволяет преобразовать аналоговый PDF-файл( например, сканированный PDF-файл в PDF-файл с внедренным текстом). Встроенный текст позволяет выполнять глубокий поиск по тексту в извлечённом содержимом PDF путём наложения обнаруженных текстовых элементов поверх файлов изображений.
Внимание
- В настоящее время только модель Read OCR
prebuilt-readподдерживает функцию PDF с возможностью поиска. При использовании этой функции укажитеmodelIdкакprebuilt-read. Другие типы моделей возвращают ошибку для этой предварительной версии. - PDF-файл с возможностью поиска входит в состав модели
2024-11-30GAprebuilt-readбез дополнительной платы за создание PDF-файла с возможностью поиска.
Использование pdf-файлов, доступных для поиска
Чтобы использовать PDF с возможностью поиска, выполните запрос POST с помощью операции Analyze и укажите в качестве формата вывода pdf:
POST {endpoint}/documentintelligence/documentModels/prebuilt-read:analyze?_overload=analyzeDocument&api-version=2024-11-30&output=pdf
{...}
202
Опрос по завершении Analyze операции. После завершения операции отправьте GET запрос на получение формата Analyze PDF результатов операции.
После успешного завершения PDF-файл можно получить и скачать как application/pdf. Эта операция позволяет напрямую загружать внедренную текстовую форму PDF вместо JSON в кодировке Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET {endpoint}/documentintelligence/documentModels/prebuilt-read/analyzeResults/{resultId}/pdf?api-version=2024-11-30
URI Parameters
Name In Required Type Description
endpoint path True
string
uri
The Document Intelligence service endpoint.
modelId path True
string
Unique document model name.
Regex pattern: ^[a-zA-Z0-9][a-zA-Z0-9._~-]{1,63}$
resultId path True
string
uuid
Analyze operation result ID.
api-version query True
string
The API version to use for this operation.
Responses
Name Type Description
200 OK
file
The request has succeeded.
Media Types: "application/pdf", "application/json"
Other Status Codes
DocumentIntelligenceErrorResponse
An unexpected error response.
Media Types: "application/pdf", "application/json"
Security
Ocp-Apim-Subscription-Key
Type: apiKey
In: header
OAuth2Auth
Type: oauth2
Flow: accessCode
Authorization URL: https://login.microsoftonline.com/common/oauth2/authorize
Token URL: https://login.microsoftonline.com/common/oauth2/token
Scopes
Name Description
https://cognitiveservices.azure.com/.default
Examples
Get Analyze Document Result PDF
Sample request
HTTP
HTTP
Copy
GET https://myendpoint.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-invoice/analyzeResults/3b31320d-8bab-4f88-b19c-2322a7f11034/pdf?api-version=2024-11-30
Sample response
Status code:
200
JSON
Copy
"{pdfBinary}"
Definitions
Name Description
DocumentIntelligenceError
The error object.
DocumentIntelligenceErrorResponse
Error response object.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
DocumentIntelligenceError
The error object.
Name Type Description
code
string
One of a server-defined set of error codes.
details
DocumentIntelligenceError[]
An array of details about specific errors that led to this reported error.
innererror
DocumentIntelligenceInnerError
An object containing more specific information than the current object about the error.
message
string
A human-readable representation of the error.
target
string
The target of the error.
DocumentIntelligenceErrorResponse
Error response object.
Name Type Description
error
DocumentIntelligenceError
Error info.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
Name Type Description
code
string
One of a server-defined set of error codes.
innererror
DocumentIntelligenceInnerError
Inner error.
message
string
A human-readable representation of the error.
In this article
URI Parameters
Responses
Security
Examples
200 OK
Content-Type: application/pdf
Параметр страниц
Коллекция страниц — это список страниц в документе. Каждая страница представлена последовательно в документе и включает угол ориентации, указывающий, поворачивается ли страница и ширина и высота (измерения в пикселях). Единицы страниц в выходных данных модели подсчитываются следующим образом:
| Формат файлов | Вычисленная единица страницы | Всего страниц |
|---|---|---|
| Изображения (JPEG/JPG, PNG, BMP, HEIF) | Каждое изображение = 1 единица страницы | Всего изображений |
| Каждая страница PDF = 1 единица страницы | Всего страниц в PDF | |
| TIFF | Каждое изображение в TIFF = 1 единица страницы | Общее количество изображений в TIFF |
| Word (DOCX) | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Общее количество страниц, каждая до 3 000 символов |
| Excel (XLSX) | Каждый рабочий лист считается одной страницей; встроенные и связанные изображения не поддерживаются | Всего листов |
| PowerPoint (PPTX) | Каждый слайд = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего слайдов |
| HTML | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Общее количество страниц, каждая до 3 000 символов |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Использование страниц для извлечения текста
Для больших многостраничных документов используйте параметр запроса pages, чтобы указать конкретные номера страниц или диапазоны страниц для извлечения текста.
Извлечение абзацев
Модель OCR чтения в Document Intelligence извлекает все определенные блоки текста в paragraphs коллекции как объект верхнего уровня в разделе analyzeResults. Каждая запись в этой коллекции представляет собой текстовый блок и включает извлечённый текст в content, а также координаты ограничивающей рамки polygon. Сведения span указывают на фрагмент текста в свойстве верхнего уровня content , содержающем полный текст документа.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Извлечение текста, строк и слов
Модель Read OCR распознаёт печатный и рукописный текст как lines и words. Модель возвращает координаты ограничивающих рамок polygon и confidence для извлеченных слов. Коллекция styles включает все обнаруженные рукописные стили линий, а также диапазоны, указывающие на соответствующий текст. Эта функция применяется к поддерживаемым языкам рукописного ввода.
Для Microsoft Word, Excel, PowerPoint и HTML модель чтения документов версии 3.1 и более поздних версий извлекает весь внедренный текст как есть. Тексты экстракированы как слова и абзацы. Внедренные образы не поддерживаются.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Извлечение стиля рукописного текста
Ответ включает классификацию текста, является ли каждая строка входного текста рукописной или нет, а также оценку достоверности. Дополнительные сведения см. в статьео поддержке рукописного языка. В следующем примере показан пример фрагмента КОДА JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Если вы включили возможность добавления шрифта и стиля, вы также получите результат шрифта или стиля в составе styles объекта.
Дальнейшие действия версии 4.0
Выполните инструкции из краткого руководства по Document Intelligence:
Ознакомьтесь с нашим REST API:
Дополнительные примеры на сайте GitHub:
Это содержимое относится к:![]() v3.0 (GA) | Последние версии:
v3.0 (GA) | Последние версии:![]() v4.0 (GA)
v4.0 (GA)![]() v3.1
v3.1
Внимание
Поддержка API Azure Document Intelligence v3.0 (2022-08-31) прекращается 30 марта 2029 г. Чтобы избежать сбоев в рабочей среде, используйте Azure Аналитика документов 2024-11-30 версии 4.0 для всех новых разработок и перенос существующих рабочих нагрузок в Azure Аналитика документов 2024-11-30 версии 4.0 до этой даты. Инструкции по миграции см. в руководстве по миграции Document Intelligence.
Примечание.
Чтобы извлечь текст из изображений извне, таких как метки, уличные знаки и плакаты, используйте функцию анализа изображений Azure версии 4.0, оптимизированную для обычных (не документальных) изображений с синхронным API с улучшенной производительностью. Эта возможность упрощает внедрение OCR в сценарии взаимодействия с пользователем в режиме реального времени.
Модель оптического распознавания символов для чтения документов (OCR) выполняется с более высоким разрешением, чем azure Vision Read и извлекает печатный и рукописный текст из документов PDF и сканированных изображений. Она также включает поддержку извлечения текста из документов Microsoft Word, Excel, PowerPoint и HTML. Он обнаруживает абзацы, текстовые строки, слова, расположения и языки. Модель чтения — это базовый механизм OCR для других предварительно созданных моделей аналитики документов, таких как макет, общий документ, счет, квитанция, удостоверение (идентификатор), карточка медицинского страхования, W2 в дополнение к пользовательским моделям.
Что такое OCR для документов?
Оптическое распознавание символов (OCR) для документов оптимизировано для больших текстовых документов в нескольких форматах файлов и глобальных языках. Он включает такие функции, как сканирование изображений документов с более высоким разрешением, чтобы лучше обрабатывать меньший и плотный текст; обнаружение абзаца; и управление заполненными формами. Возможности OCR также включают расширенные сценарии, такие как одинарные поля символов и точное извлечение ключевых полей, часто найденных в счетах, квитанциях и других предварительно созданных сценариях.
Варианты разработки
Аналитика документов версии 3.1 поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Идентификатор модели |
|---|---|---|
| Чтение модели OCR | • Document Intelligence Studio • REST API • пакет SDK для C# • пакет SDK для Python • пакет SDK для Java • пакет SDK для JavaScript |
prebuilt-read |
Аналитика документов версии 3.0 поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Идентификатор модели |
|---|---|---|
| Чтение модели OCR | • Document Intelligence Studio • REST API • пакет SDK для C# • пакет SDK для Python • пакет SDK для Java • пакет SDK для JavaScript |
prebuilt-read |
Требования к входным данным
Поддерживаются следующие форматы файлов.
| Модель | Изображение: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Читать | ✔ | ✔ | ✔ |
| Макет | ✔ | ✔ | ✔ |
| Общий документ | ✔ | ✔ | |
| Предварительно собранный | ✔ | ✔ | |
| Настраиваемая функция извлечения | ✔ | ✔ | |
| Настраиваемая классификация | ✔ | ✔ | ✔ |
- Фотографии и сканы: для получения наилучших результатов предоставьте одну чёткую фотографию или высококачественный скан на каждый документ.
- PDF и TIFF: для PDF и TIFF можно обрабатывать до 2000 страниц. (С подпиской на бесплатный уровень обрабатываются только первые две страницы.)
- Размер файла: размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и 4 МБ для бесплатного уровня (F0).
- Размеры изображения: размеры должны находиться в диапазоне от 50 пикселей до 10 000 пикселей x 10 000 пикселей.
- Блокировки паролей. Если pdf-файлы заблокированы паролем, необходимо удалить блокировку перед отправкой.
- Высота текста: минимальная высота извлеченного текста составляет 12 пикселей для изображения 1024 x 768 пикселей. Это измерение соответствует примерно тексту размером 8 пунктов при 150 точках на дюйм.
- Обучение пользовательской модели: максимальное количество страниц для обучающих данных составляет 500 для пользовательской модели шаблона и 50 000 для пользовательской нейронной модели.
- Обучение пользовательской модели извлечения: общий размер обучающих данных составляет 50 МБ для модели шаблона и 1 ГБ для нейронной модели.
- Обучение пользовательской модели классификации: общий размер обучающих данных составляет 1 ГБ, не более 10 000 страниц. Для 2024-11-30 (GA) общий размер обучающих данных составляет 2 ГБ с максимум 10 000 страниц.
- Типы файлов Office (DOCX, XLSX, PPTX): максимальная длина строки составляет 8 миллионов символов.
Начало работы с моделью распознавания текста
Попробуйте извлечь текст из форм и документов с помощью Document Intelligence Studio. Вам потребуются следующие ресурсы:
Подписка Azure — ее можно создать бесплатно.
Экземпляр Document Intelligence в портале Azure. Вы можете использовать бесплатный ценовой уровень (
F0), чтобы опробовать сервис. После развертывания ресурса выберите Перейти к ресурсу, чтобы получить ключ и конечную точку.
Примечание.
В настоящее время Студия аналитики документов не поддерживает форматы файлов Microsoft Word, Excel, PowerPoint и HTML.
Пример документа, обработанный с помощью Document Intelligence Studio
На домашней странице Document Intelligence Studio выберите "Чтение".
Вы можете проанализировать пример документа или отправить собственные файлы.
Нажмите кнопку "Выполнить анализ", а при необходимости настройте параметры анализа:
Поддерживаемые языки и региональные настройки
См. страницу "Поддержка языка" — модели анализа документов для полного списка поддерживаемых языков.
Извлечение данных
Примечание.
Microsoft Word и HTML-файл поддерживаются в версии 4.0. Следующие возможности в настоящее время не поддерживаются.
- Для каждого объекта страницы не возвращаются угол, ширина/высота и единица измерения.
- Для каждого обнаруженного объекта отсутствует ограничивающий многоугольник или ограничивающая область.
- Диапазон страниц (
pages) не возвращается в качестве возвращаемого параметра. - Нет
linesобъекта.
Pdf-файл, доступный для поиска
Возможность PDF с возможностью поиска позволяет преобразовать аналоговый PDF-файл( например, сканированный PDF-файл в PDF-файл с внедренным текстом). Встроенный текст позволяет выполнять глубокий поиск по тексту в извлечённом содержимом PDF путём наложения обнаруженных текстовых элементов поверх файлов изображений.
Внимание
- В настоящее время только модель Read OCR
prebuilt-readподдерживает функцию поиска в PDF. При использовании этой функции укажитеmodelIdкакprebuilt-read. Другие типы моделей возвращают ошибку. - Pdf-файл, доступный для поиска, включается в
2024-11-30prebuilt-readмодель без дополнительных затрат для создания выходных данных PDF с возможностью поиска.- В настоящее время доступный для поиска PDF-файл поддерживает только pdf-файлы в качестве входных данных.
Использование PDF с возможностью поиска
Чтобы использовать PDF с возможностью поиска, выполните запрос POST с помощью операции Analyze и укажите в качестве формата вывода pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Опрос по завершении Analyze операции. После завершения операции отправьте GET запрос на получение формата Analyze PDF результатов операции.
После успешного завершения PDF-файл можно получить и скачать как application/pdf. Эта операция позволяет напрямую загружать внедренную текстовую форму PDF вместо JSON в кодировке Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Страницы
Коллекция страниц — это список страниц в документе. Каждая страница представлена последовательно в документе и включает угол ориентации, указывающий, поворачивается ли страница и ширина и высота (измерения в пикселях). Единицы страниц в выходных данных модели подсчитываются следующим образом:
| Формат файлов | Вычисленная единица страницы | Всего страниц |
|---|---|---|
| Изображения (JPEG/JPG, PNG, BMP, HEIF) | Каждое изображение = 1 единица страницы | Всего изображений |
| Каждая страница PDF = 1 единица страницы | Всего страниц в PDF | |
| TIFF | Каждое изображение в TIFF = 1 единица страницы | Общее количество изображений в TIFF |
| Word (DOCX) | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Общее количество страниц, каждая до 3 000 символов |
| Excel (XLSX) | Каждый рабочий лист считается одной страницей; встроенные и связанные изображения не поддерживаются | Всего листов |
| PowerPoint (PPTX) | Каждый слайд = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего слайдов |
| HTML | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Общее количество страниц, каждая до 3 000 символов |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Выбор страниц для извлечения текста
Для больших многостраничных документов используйте параметр запроса pages, чтобы указать конкретные номера страниц или диапазоны страниц для извлечения текста.
Абзацы
Модель OCR чтения в Document Intelligence извлекает все определенные блоки текста в paragraphs коллекции как объект верхнего уровня в разделе analyzeResults. Каждая запись в этой коллекции представляет собой текстовый блок и включает извлечённый текст в content, а также координаты ограничивающей рамки polygon. Сведения span указывают на фрагмент текста в свойстве верхнего уровня content , содержающем полный текст документа.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Текст, строки и слова
Модель Read OCR распознаёт печатный и рукописный текст как lines и words. Модель возвращает координаты ограничивающих рамок polygon и confidence для извлеченных слов. Коллекция styles включает все обнаруженные рукописные стили линий, а также диапазоны, указывающие на соответствующий текст. Эта функция применяется к поддерживаемым языкам рукописного ввода.
Для Microsoft Word, Excel, PowerPoint и HTML модель чтения документов версии 3.1 и более поздних версий извлекает весь внедренный текст как есть. Тексты экстракированы как слова и абзацы. Внедренные образы не поддерживаются.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Рукописный стиль для текстовых строк
Ответ включает классификацию текста, является ли каждая строка входного текста рукописной или нет, а также оценку достоверности. Дополнительные сведения см. в статьео поддержке рукописного языка. В следующем примере показан пример фрагмента КОДА JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Если вы включили возможность добавления шрифта и стиля, вы также получите результат шрифта или стиля в составе styles объекта.
Следующие шаги
Выполните инструкции из краткого руководства по Document Intelligence:
Ознакомьтесь с нашим REST API:
Дополнительные примеры на сайте GitHub:
Перенос рабочих нагрузок версии 3.0 на версию 4.0 до 30 марта 2029 г. Инструкции по миграции см. в руководстве по миграции аналитики документов.