Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Понимание содержимого позволяет создавать пользовательские рабочие процессы классификации, которые классифицируют содержимое и направляют его в правильный анализатор. С помощью маршрутизации можно отправить несколько потоков данных через один конвейер и убедиться, что данные обрабатываются лучшим анализатором для его типа.
В этом руководстве описаны два шага.
- Создайте базовый классификатор, который классифицирует документы в пользовательские категории.
- Классификация и маршрутизация с помощью пользовательских анализаторов , которые объединяют классификацию с извлечением полей для каждой категории.
Необходимые условия
Чтобы приступить к работе, убедитесь, что у вас есть следующие ресурсы и разрешения:
- Подписка Azure. Если у вас нет подписки Azure, создайте бесплатную учетную запись.
- Ресурс Microsoft Foundry на портале Azure, созданном в поддерживаемом регионе.
- Этот ресурс указан в разделе Foundry>Foundry на портале.
- Настройте развертывания моделей по умолчанию для ресурса Content Understanding. По умолчанию вы создаете подключение к моделям Microsoft Foundry, используемым для запросов на распознавание контента. Выберите один из следующих методов:
Перейдите на страницу параметров распознавания содержимого.
Нажмите кнопку +Добавить ресурс в левом верхнем углу.
Выберите ресурс Foundry, который вы хотите использовать, и нажмите кнопку "Далее>сохранить".
Убедитесь, что установлен флажок Enable autodeployment для обязательных моделей, если отсутствуют значения по умолчанию. Этот выбор гарантирует, что ресурс полностью настроен с необходимыми моделями
GPT-4.1,GPT-4.1-miniиtext-embedding-3-large. Для различных предварительно созданных анализаторов требуются разные модели.
- cURL установлен для вашей среды разработки (для вкладки REST API).
Шаг 1. Создание базового классификатора
Базовый классификатор классифицирует документы по пользовательским категориям контента. Вы определяете категории с именами и описаниями, а служба использует эти определения для классификации входных файлов. Параметр enableSegment определяет, разбивает ли классификатор многодокументные файлы на сегменты или обрабатывает весь файл как один документ.
Войдите в Content Understanding Studio
Перейдите на портал Content Understanding Studio и войдите в систему, используя свои учетные данные. Если вы знакомы с классическим опытом работы с Azure Document Intelligence в Foundry Tools Studio, функция "Понимание содержимого" расширяет возможности извлечения содержимого и полей во всех модальностях— документе, изображении, видео и аудио. Выберите вариант, чтобы попробовать новый интерфейс "Распознавание содержимого" для доступа к мультимодальным возможностям.
Создание проекта классификатора
Начните с нового проекта: выберите "Создать проект " на домашней странице.
Выберите тип проекта: выберите параметр
Classify and route with custom categories.Отправка данных: отправка фрагмента примеров данных для начала классификации.
Создайте правила маршрутизации: на вкладке "Правила маршрутизации " выберите
Add category. Присвойте категории имя и описание. Для базового классификатора можно пропустить назначение определенного анализатора каждой категории.Протестируйте рабочий процесс классификации. Когда пользовательские правила маршрутизации готовы к тестированию, выберите "Выполнить анализ ", чтобы просмотреть выходные данные правил данных.
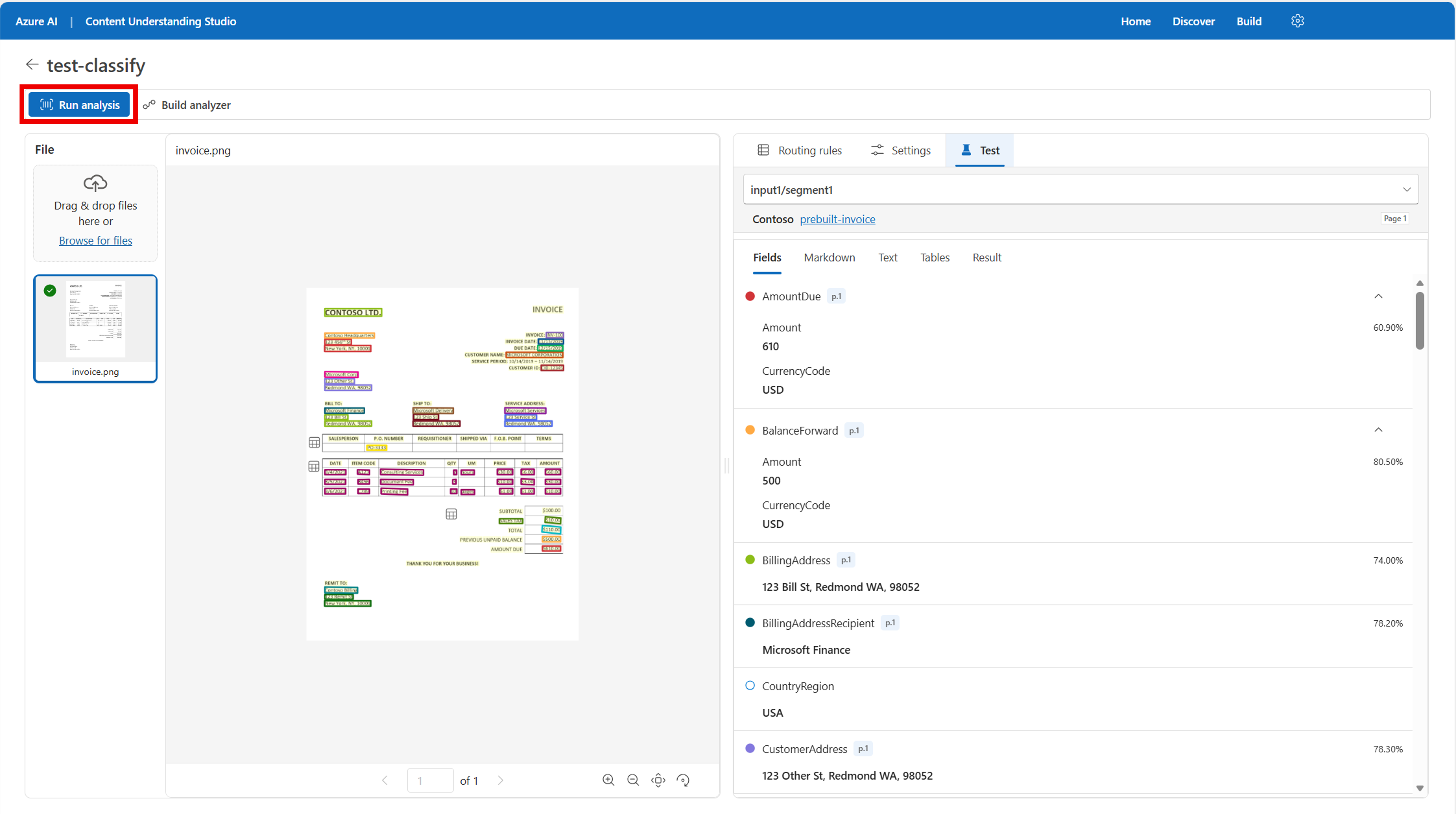
Создайте анализатор классификации: Когда вы удовлетворены выходными данными, нажмите кнопку "Собрать анализатор" в верхней части страницы. Присвойте анализатору имя и нажмите кнопку "Сохранить".

Шаг 2. Классификация и маршрутизация с помощью пользовательских анализаторов
Чтобы выйти за пределы базовой классификации, можно направлять каждую категорию к конкретному анализатору для извлечения полей. Этот подход объединяет классификацию с извлечением данных в одном конвейере: классификатор определяет тип документа, а затем направляет его в правильный анализатор, который извлекает поля, адаптированные к этой категории.
Чтобы успешно перенаправить данные, создайте пользовательские анализаторы для каждой категории. Дополнительные сведения о создании пользовательских анализаторов см. в статье "Создание и улучшение пользовательского анализатора" в Studio Content Understanding Studio.
Сначала создайте настраиваемые анализаторы: создайте настраиваемые анализаторы для каждого типа документа, который требуется маршрутизировать. Например, создайте пользовательский анализатор для приложений кредитов с схемой извлечения полей, относящуюся к данному типу документа.
Создайте или обновите правила маршрутизации: на вкладке "Правила маршрутизации " выберите
Add category. Присвойте категории имя и описание и выберите анализатор, соответствующий этой маршруту. Это средство позволяет предварительно просмотреть схему для каждого анализатора, чтобы удостовериться, что он подходит.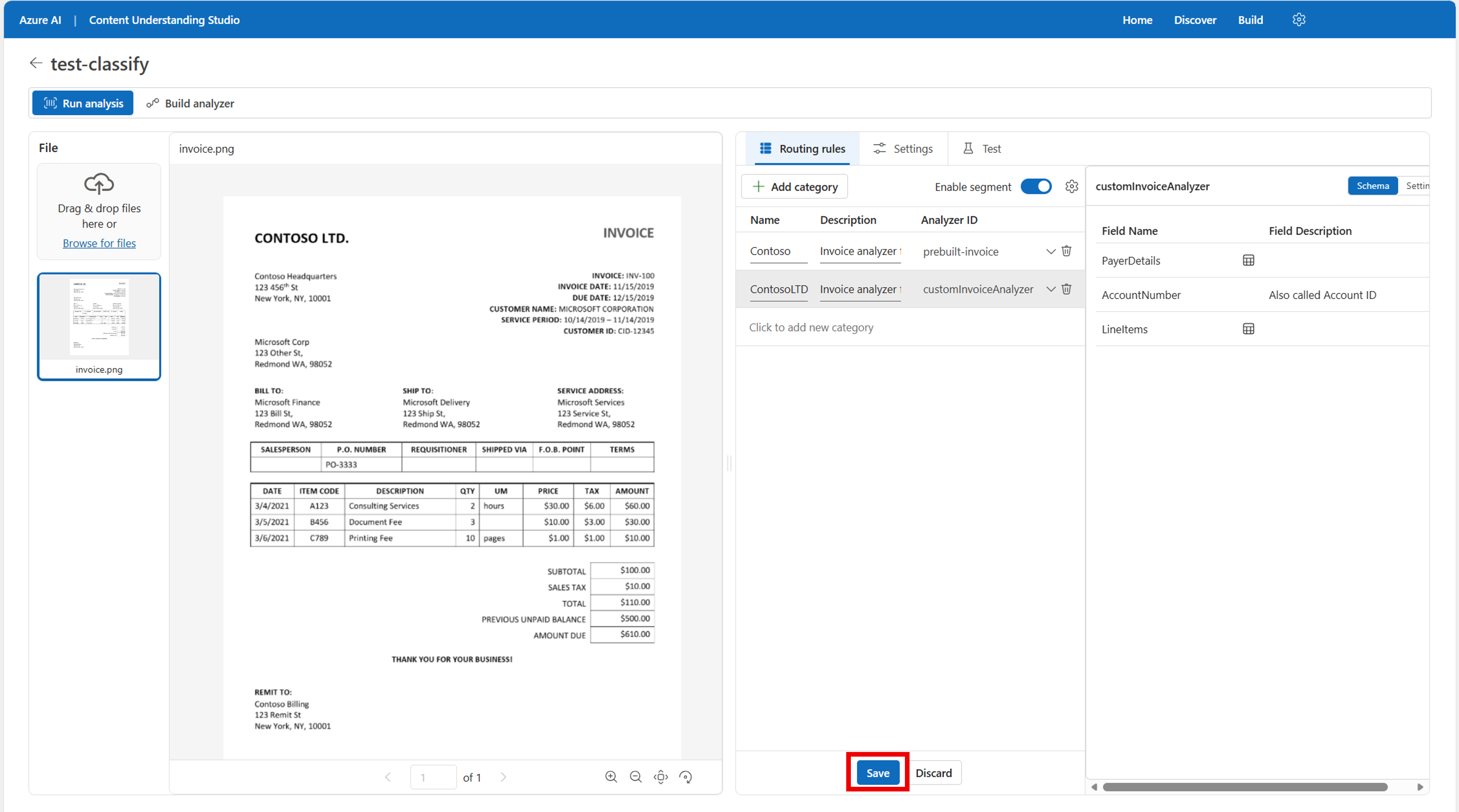
Проверьте рабочий процесс классификации: выберите "Выполнить анализ ", чтобы просмотреть выходные данные правил данных. Вы можете отправить дополнительные примеры данных для тестирования, чтобы узнать, как он работает с несколькими различными правилами.
Создайте анализатор классификации: Когда вы удовлетворены выходными данными, нажмите кнопку "Собрать анализатор" в верхней части страницы. Присвойте анализатору имя и нажмите кнопку "Сохранить".
Используйте анализатор классификации. Теперь у вас есть конечная точка анализатора, которую можно использовать в собственном приложении с помощью REST API.

Совет
Для полного сквозного Python-ноутбука см. пример классификатора на GitHub.
Дальнейшие действия
- Дополнительные сведения о передовых методах распознавания содержимого Azure в инструментах Foundry.
- Следуйте инструкциям из руководства по созданию пользовательского анализатора с помощью REST API.
- Изучите основные понятия классификатора для расширенных сценариев.