Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать API внедрения с моделями, развернутыми в модели ИИ Azure в службах ИИ Azure.
Предварительные условия
Чтобы использовать модели внедрения в приложение, вам потребуется:
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свои возможности и одновременно создать подписку на Azure. Ознакомьтесь с тем, как перейти с моделей GitHub на использование модели ИИ Azure, если это относится к вам.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
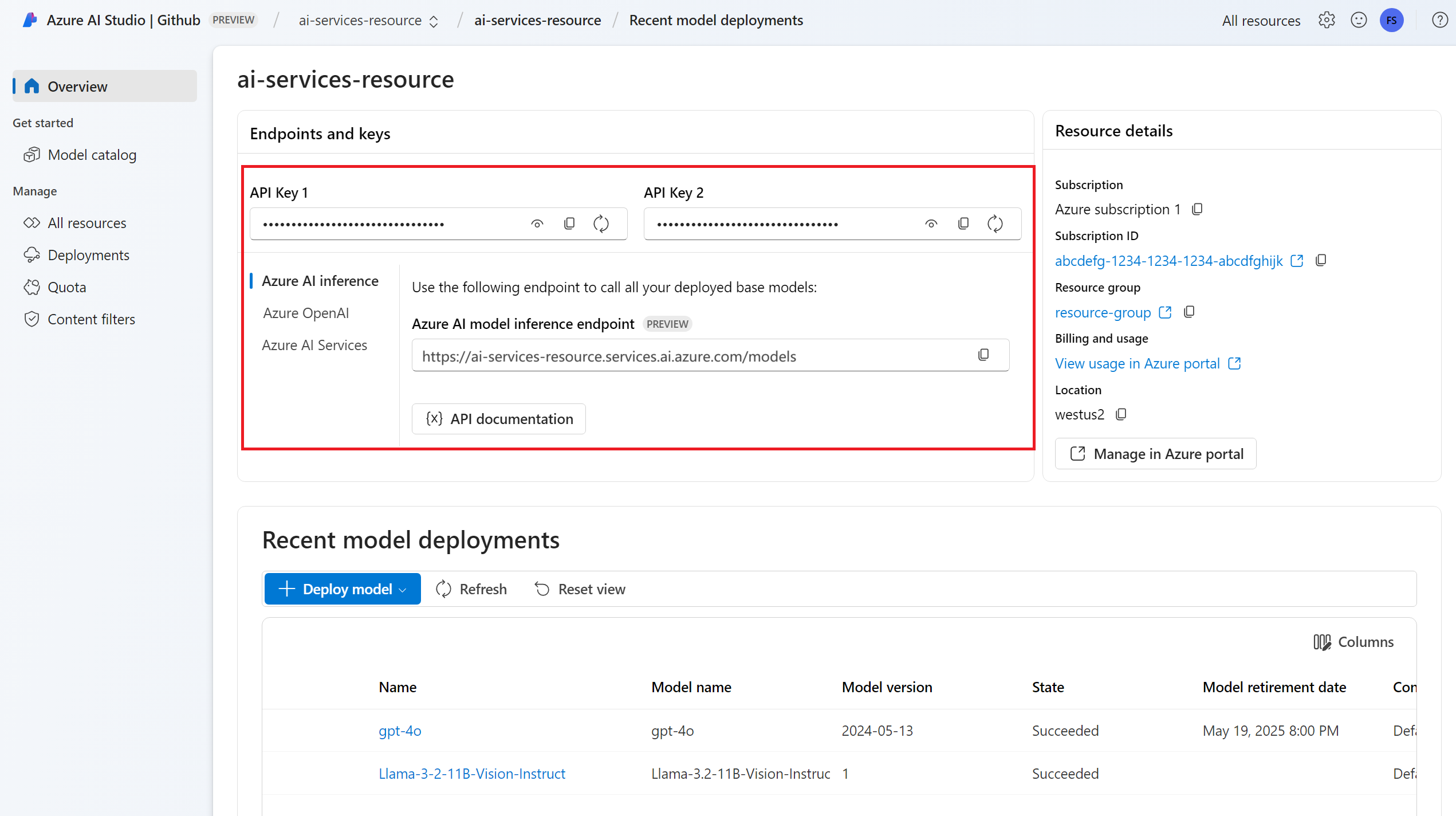
URL-адрес конечной точки и ключ.

Установите пакет вывода искусственного интеллекта Azure для Python с помощью следующей команды:
pip install -U azure-ai-inference
- Развертывание модели встраивания. Если у вас его нет, прочитайте «Добавление и настройка моделей в службах ИИ Azure», чтобы добавить модель эмбеддингов в ваш ресурс.
Используйте встраивания
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="text-embedding-3-small"
)
Если вы настроили ресурс с поддержкой Microsoft Entra ID, можно использовать следующий фрагмент кода для создания клиента.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="text-embedding-3-small"
)
Создание внедренных модулей
Создайте запрос на внедрение, чтобы просмотреть выходные данные модели.
response = model.embed(
input=["The ultimate answer to the question of life"],
)
Совет
При создании запроса учитывайте лимит токенов для модели. Если вам нужно внедрить более крупные части текста, вам потребуется стратегия фрагментирования.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Это может быть полезно для вычислений внедрения в входных пакетах. Параметр inputs может быть списком строк, где каждая строка имеет разные входные данные. В свою очередь ответ содержит список векторных представлений, где каждое векторное представление соответствует входным данным на той же позиции.
response = model.embed(
input=[
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
)
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Совет
При создании пакетов запросов учитывайте ограничение пакета для каждой модели. Ограничение на размер партии у большинства моделей составляет 1024.
Указание измерений внедрения
Можно указать количество измерений для эмбеддингов. В следующем примере кода показано, как создавать внедрения с 1024 измерениями. Обратите внимание, что не все модели внедрения поддерживают количество измерений в запросе и в этих случаях возвращается ошибка 422.
response = model.embed(
input=["The ultimate answer to the question of life"],
dimensions=1024,
)
Создавать различные типы эмбеддингов
Некоторые модели могут создавать несколько внедренных входных данных в зависимости от способа их использования. Эта возможность позволяет получить более точные внедрения для шаблонов RAG.
В следующем примере показано, как создать встраивания для документа, который будет храниться в векторной базе данных.
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type=EmbeddingInputType.DOCUMENT,
)
При работе с запросом для получения такого документа можно использовать следующий фрагмент кода, чтобы создать внедрения для запроса и максимально повысить производительность извлечения.
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["What's the ultimate meaning of life?"],
input_type=EmbeddingInputType.QUERY,
)
Обратите внимание, что не все модели внедрения поддерживают указание типа входных данных в запросе, и в таких случаях возвращается ошибка 422. По умолчанию возвращаются векторные представления типа Text.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать API внедрения с моделями, развернутыми в модели ИИ Azure в службах ИИ Azure.
Требования
Чтобы использовать модели внедрения в приложение, вам потребуется:
Подписка Azure. Если вы используете GitHub модели, вы можете улучшить свой опыт и создать подписку Azure в процессе. Ознакомьтесь с переходом от моделей GitHub к выводам моделей ИИ Azure, если это ваш случай.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Установите библиотеку вывода Azure для JavaScript с помощью следующей команды:
npm install @azure-rest/ai-inference npm install @azure/core-auth npm install @azure/identityЕсли вы используете Node.js, вы можете настроить зависимости в package.json:
package.json
{ "name": "main_app", "version": "1.0.0", "description": "", "main": "app.js", "type": "module", "dependencies": { "@azure-rest/ai-inference": "1.0.0-beta.6", "@azure/core-auth": "1.9.0", "@azure/core-sse": "2.2.0", "@azure/identity": "4.8.0" } }Импортируйте следующее:
import ModelClient from "@azure-rest/ai-inference"; import { isUnexpected } from "@azure-rest/ai-inference"; import { createSseStream } from "@azure/core-sse"; import { AzureKeyCredential } from "@azure/core-auth"; import { DefaultAzureCredential } from "@azure/identity";
- Развертывание модели внедрения. Если у вас нет, прочитайте "Добавление и настройка моделей для служб ИИ Azure", чтобы добавить модель для внедрения в ваш ресурс.
Используйте встраивания
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
const client = ModelClient(
"https://<resource>.services.ai.azure.com/models",
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Если вы настроили ресурс с поддержкой идентификатора Microsoft Entra, можно использовать следующий фрагмент кода для создания клиента.
const clientOptions = { credentials: { "https://cognitiveservices.azure.com" } };
const client = ModelClient(
"https://<resource>.services.ai.azure.com/models",
new DefaultAzureCredential()
clientOptions,
);
Создание эмбеддингов
Создайте запрос на внедрение, чтобы просмотреть выходные данные модели.
var response = await client.path("/embeddings").post({
body: {
model: "text-embedding-3-small",
input: ["The ultimate answer to the question of life"],
}
});
Совет
При создании запроса учитывайте ограничение на количество токенов для модели. Если вам нужно внедрить более крупные части текста, вам потребуется стратегия фрагментирования.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Это может быть полезно для вычислений внедрения в входных пакетах. Параметр inputs может быть списком строк, где каждая строка имеет разные входные данные. В свою очередь ответ представляет собой список внедрения, где каждое внедрение соответствует входным данным в той же позиции.
var response = await client.path("/embeddings").post({
body: {
model: "text-embedding-3-small",
input: [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
}
});
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Совет
При создании пакетов запросов учитывайте ограничение пакета для каждой модели. Большинство моделей имеют ограничение пакета 1024.
Укажите размерности встраиваний
Можно указать количество измерений для эмбеддингов. В следующем примере кода показано, как создавать внедрения с 1024 измерениями. Обратите внимание, что не все модели внедрения поддерживают количество измерений в запросе и в этих случаях возвращается ошибка 422.
var response = await client.path("/embeddings").post({
body: {
model: "text-embedding-3-small",
input: ["The ultimate answer to the question of life"],
dimensions: 1024,
}
});
Создание различных типов внедрения
Некоторые модели могут создавать несколько представлений для одного и того же ввода, в зависимости от того, как вы планируете их использовать. Эта возможность позволяет получить более точные внедрения для шаблонов RAG.
В следующем примере показано, как создать внедрения, которые используются для создания внедрения документа, который будет храниться в векторной базе данных:
var response = await client.path("/embeddings").post({
body: {
model: "text-embedding-3-small",
input: ["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type: "document",
}
});
При работе с запросом для получения такого документа можно использовать следующий фрагмент кода, чтобы создать внедрения для запроса и максимально повысить производительность извлечения.
var response = await client.path("/embeddings").post({
body: {
model: "text-embedding-3-small",
input: ["What's the ultimate meaning of life?"],
input_type: "query",
}
});
Обратите внимание, что не все модели внедрения поддерживаются, указывающие тип входных данных в запросе и в этих случаях возвращается ошибка 422. По умолчанию возвращаются внедрения типов Text .
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать API встраивания с моделями, развернутыми для вывода в службах ИИ Azure.
Необходимые компоненты
Чтобы использовать модели внедрения в приложение, вам потребуется:
Подписка Azure. Если вы используете модели GitHub Models, вы можете улучшить свой опыт и при этом создать подписку на Azure. Ознакомьтесь с переходом от моделей GitHub к моделям прогнозирования ИИ Azure, если это относится к вам.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Добавьте пакет вывода искусственного интеллекта Azure в проект:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.4</version> </dependency>Если вы используете Entra ID, вам также потребуется следующий пакет:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.15.3</version> </dependency>Импортируйте следующее пространство имен:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.ChatCompletionsClient; import com.azure.ai.inference.ChatCompletionsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.ai.inference.models.ChatCompletions; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Импортируйте следующее пространство имен:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;Развертывание модели эмбеддингов. Если у вас еще нет такой модели, прочитайте статью «Добавление и настройка моделей в службах Azure AI», чтобы добавить модель для встраивания в ваш ресурс.
Использование векторных представлений
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
EmbeddingsClient client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Если вы настроили ресурс в службу поддержки идентификатора Microsoft Entra, можно использовать следующий фрагмент кода для создания клиента.
client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Создание внедренных модулей
Создайте запрос на внедрение, чтобы просмотреть выходные данные модели.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList("The ultimate answer to the question of life"));
Response<EmbeddingsResult> response = client.embed(requestOptions);
Совет
При создании запроса учитывайте лимит ввода токена для модели. Если вам нужно внедрить более крупные части текста, вам потребуется стратегия фрагментирования.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
System.out.println("Embedding: " + response.getValue().getData());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
Это может быть полезно для вычислений внедрения в входных пакетах. Параметр inputs может быть списком строк, где каждая строка имеет разные входные данные. В свою очередь ответ представляет собой список внедрения, где каждое внедрение соответствует входным данным в той же позиции.
requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList(
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
));
response = client.embed(requestOptions);
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
Совет
При создании пакетов запросов учитывайте ограничение пакета для каждой модели. Большинство моделей имеют ограничение на 1024 партии.
Указание измерений внедрения
Можно указать количество измерений для встраиваний. В следующем примере кода показано, как создавать внедрения с 1024 измерениями. Обратите внимание, что не все модели внедрения поддерживают количество измерений в запросе и в этих случаях возвращается ошибка 422.
Создание различных типов эмбеддингов
Некоторые модели могут генерировать несколько эмбеддингов для одного и того же ввода в зависимости от того, как вы планируете их использовать. Эта возможность позволяет получить более точные внедрения для шаблонов RAG.
В следующем примере показано, как создать эмбеддинги, которые используются для создания векторного представления документа, который будет храниться в векторной базе данных:
List<String> input = Arrays.asList("The answer to the ultimate question of life, the universe, and everything is 42");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
response = client.embed(requestOptions);
При работе с запросом для получения такого документа можно использовать следующий фрагмент кода, чтобы создать внедрения для запроса и максимально повысить производительность извлечения.
input = Arrays.asList("What's the ultimate meaning of life?");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
response = client.embed(requestOptions);
Обратите внимание, что не все модели внедрения поддерживают указание типа входных данных в запросе, и в таких случаях возвращается ошибка 422. По умолчанию возвращаются встраивания типа Text.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать API встраивания с моделями, развернутыми для инференции в службах ИИ Azure.
Предварительные условия
Чтобы использовать модели внедрения в приложение, вам потребуется:
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и в ходе этого процесса создать подписку Azure. Ознакомьтесь с обновлением моделей GitHub до модели ИИ Azure, если это ваше дело.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Установите пакет вывода искусственного интеллекта Azure с помощью следующей команды:
dotnet add package Azure.AI.Inference --prereleaseЕсли вы используете Entra ID, вам также потребуется следующий пакет:
dotnet add package Azure.Identity
- Развертывание модели эмбеддингов. Если у вас нет одного чтения "Добавление и настройка моделей" в службы ИИ Azure для добавления модели внедрения в ресурс.
Используйте векторы
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
EmbeddingsClient client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL"))
);
Если вы настроили ресурс с поддержкой идентификатора Microsoft Entra, можно использовать следующий фрагмент кода для создания клиента. Обратите внимание, что здесь includeInteractiveCredentials задано значение true только для демонстрационных целей, поэтому проверка подлинности может произойти с помощью веб-браузера. В рабочих нагрузках следует удалить такой параметр.
TokenCredential credential = new DefaultAzureCredential(includeInteractiveCredentials: true);
AzureAIInferenceClientOptions clientOptions = new AzureAIInferenceClientOptions();
BearerTokenAuthenticationPolicy tokenPolicy = new BearerTokenAuthenticationPolicy(credential, new string[] { "https://cognitiveservices.azure.com/.default" });
clientOptions.AddPolicy(tokenPolicy, HttpPipelinePosition.PerRetry);
client = new EmbeddingsClient(
new Uri("https://<resource>.services.ai.azure.com/models"),
credential,
clientOptions,
);
Создание внедренных модулей
Создайте запрос на внедрение, чтобы просмотреть выходные данные модели.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life"
},
Model = "text-embedding-3-small"
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Совет
При создании запроса учитывайте входной лимит для токенов модели. Если вам нужно внедрить более крупные части текста, вам потребуется стратегия фрагментирования.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
Console.WriteLine($"Embedding: {response.Value.Data}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Это может быть полезно для вычислений внедрения в входных пакетах. Параметр inputs может быть списком строк, где каждая строка имеет разные входные данные. В свою очередь ответ представляет собой список внедрения, где каждое внедрение соответствует входным данным в той же позиции.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
},
Model = "text-embedding-3-small"
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
Совет
При создании пакетов запросов учитывайте ограничение пакета для каждой модели. Большинство моделей имеют ограничение на размер партии в 1024.
Укажите размерность векторных представлений
Можно указать количество измерений для внедрения. В следующем примере кода показано, как создавать внедрения с 1024 измерениями. Обратите внимание, что не все модели внедрения поддерживают количество измерений в запросе и в этих случаях возвращается ошибка 422.
Создавать различные типы встраиваний
Некоторые модели могут создавать несколько векторных представлений для одного и того же входного сигнала в зависимости от того, как вы планируете их использовать. Эта возможность позволяет получить более точные внедрения для шаблонов RAG.
В следующем примере показано, как создать внедрения, которые используются для создания внедрения документа, который будет храниться в векторной базе данных:
var input = new List<string> {
"The answer to the ultimate question of life, the universe, and everything is 42"
};
var requestOptions = new EmbeddingsOptions()
{
Input = input,
InputType = EmbeddingInputType.DOCUMENT,
Model = "text-embedding-3-small"
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
При работе с запросом для получения такого документа можно использовать следующий фрагмент кода, чтобы создать внедрения для запроса и максимально повысить производительность извлечения.
var input = new List<string> {
"What's the ultimate meaning of life?"
};
var requestOptions = new EmbeddingsOptions()
{
Input = input,
InputType = EmbeddingInputType.QUERY,
Model = "text-embedding-3-small"
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Обратите внимание, что не все модели встраивания поддерживают указание типа входных данных в запросе, и в этих случаях возвращается ошибка 422. По умолчанию возвращаются векторные представления типа Text.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать API внедрения с моделями, развернутыми в модели ИИ Azure в службах ИИ Azure.
Предварительные условия
Чтобы использовать модели внедрения в приложение, вам потребуется:
Подписка Azure. Если вы используете модели GitHub, вы можете обновить интерфейс и создать подписку Azure в процессе. Ознакомьтесь с обновлением с моделей GitHub на использование моделей ИИ Azure, если у вас такой случай.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
- Развертывание модели внедрения. Если у вас его нет, прочтите «Добавление и настройка моделей в службу Azure AI» для добавления эмбеддинговой модели в ваш ресурс.
Использование внедрения
Чтобы использовать внедренные тексты, используйте маршрут /embeddings , добавленный к базовому URL-адресу, а также учетные данные, указанные в api-key.
Authorization Заголовок также поддерживается в формате Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Если вы настроили ресурс с поддержкой Microsoft Entra ID, передайте токен в заголовке Authorization с форматом Bearer <token>. Используйте область https://cognitiveservices.azure.com/.default.
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Использование идентификатора Microsoft Entra может потребовать дополнительной конфигурации в ресурсе для предоставления доступа. Узнайте, как настроить проверку подлинности без ключей с помощью идентификатора Microsoft Entra.
Создание внедренных модулей
Создайте запрос на внедрение, чтобы просмотреть выходные данные модели.
{
"model": "text-embedding-3-small",
"input": [
"The ultimate answer to the question of life"
]
}
Совет
При создании запроса принимайте во внимание ограничение на количество символов токена для модели. Если вам нужно внедрить более крупные части текста, вам потребуется стратегия фрагментирования.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 9,
"completion_tokens": 0,
"total_tokens": 9
}
}
Это может быть полезно для вычисления эмбеддингов в пакетах входных данных. Параметр inputs может быть списком строк, где каждая строка имеет разные входные данные. В свою очередь ответ представляет собой список внедрения, где каждое внедрение соответствует входным данным в той же позиции.
{
"model": "text-embedding-3-small",
"input": [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
]
}
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
},
{
"index": 1,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 19,
"completion_tokens": 0,
"total_tokens": 19
}
}
Совет
При создании пакетов запросов учитывайте ограничение пакета для каждой модели. Большинство моделей имеют ограничение размера пакета в 1024.
Укажите размерности векторов встраивания
Можно указать количество измерений для эмбедингов. В следующем примере кода показано, как создавать внедрения с 1024 измерениями. Обратите внимание, что не все модели внедрения поддерживают количество измерений в запросе и в этих случаях возвращается ошибка 422.
{
"model": "text-embedding-3-small",
"input": [
"The ultimate answer to the question of life"
],
"dimensions": 1024
}
Создание различных типов эмбеддингов
Некоторые модели могут создавать несколько встраиваний для одного и того же ввода в зависимости от того, как вы планируете их использовать. Эта возможность позволяет получить более точные внедрения для шаблонов RAG.
В следующем примере показано, как создать встраивания, которые используются для создания встраивания документа, который будет храниться в векторной базе данных. Так как text-embedding-3-small эта возможность не поддерживается, мы используем модель внедрения из Cohere в следующем примере:
{
"model": "cohere-embed-v3-english",
"input": [
"The answer to the ultimate question of life, the universe, and everything is 42"
],
"input_type": "document"
}
При работе с запросом для получения такого документа можно использовать следующий фрагмент кода, чтобы создать внедрения для запроса и максимально повысить производительность извлечения. Так как text-embedding-3-small эта возможность не поддерживается, мы используем модель внедрения из Cohere в следующем примере:
{
"model": "cohere-embed-v3-english",
"input": [
"What's the ultimate meaning of life?"
],
"input_type": "query"
}
Обратите внимание, что не все модели внедрения поддерживают указание типа входных данных в запросе, и в таких случаях возвращается ошибка 422. По умолчанию возвращаются векторы типа Text.