Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Для получения дополнительной информации см. Дополнительные условия использования для предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать API завершения чата с многомодальными моделями, развернутыми в модели искусственного интеллекта Azure в службах ИИ Azure. Помимо ввода текста многомодальные модели могут принимать другие типы входных данных, такие как изображения или входные данные звука.
Предпосылки
Чтобы использовать модели завершения чата в приложении, вам потребуется:
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и одновременно создать подписку на Azure. Ознакомьтесь с материалом «Переход от моделей GitHub к моделям предсказания AI Azure», если вам это необходимо.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.

Установите пакет вывода искусственного интеллекта Azure для Python с помощью следующей команды:
pip install -U azure-ai-inference
Развертывание модели завершения чата с поддержкой звука и изображений. Если у вас нет одного, см. статью "Добавление и настройка моделей в службы ИИ Azure ", чтобы добавить модель завершения чата в ресурс.
- Для этой статьи используется
Phi-4-multimodal-instruct.
- Для этой статьи используется
Используйте завершение чата
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="Phi-4-multimodal-instruct"
)
Если вы настроили ресурс с поддержкой идентификатора Microsoft Entra, можно использовать следующий фрагмент кода для создания клиента.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=DefaultAzureCredential(),
model="Phi-4-multimodal-instruct"
)
Использование завершения чата с изображениями
Некоторые модели способны обрабатывать текст и изображения и генерировать текстовые дополнения на основе обоих типов входных данных. В этом разделе вы исследуете возможности некоторых визуальных моделей в чат-формате.
Это важно
Некоторые модели поддерживают только одно изображение для каждого поворота беседы в чате, и только последний образ сохраняется в контексте. При добавлении нескольких изображений это приведет к ошибке.
Чтобы увидеть эту возможность, скачайте изображение и закодируйте сведения в виде base64 строки. Полученные данные должны находиться внутри URL-адреса данных:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Визуализировать изображение:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

Теперь создайте запрос на завершение чата с изображением:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image_url=ImageUrl(url=data_url))
]),
],
temperature=1,
max_tokens=2048,
)
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
print(f"{response.choices[0].message.role}: {response.choices[0].message.content}")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
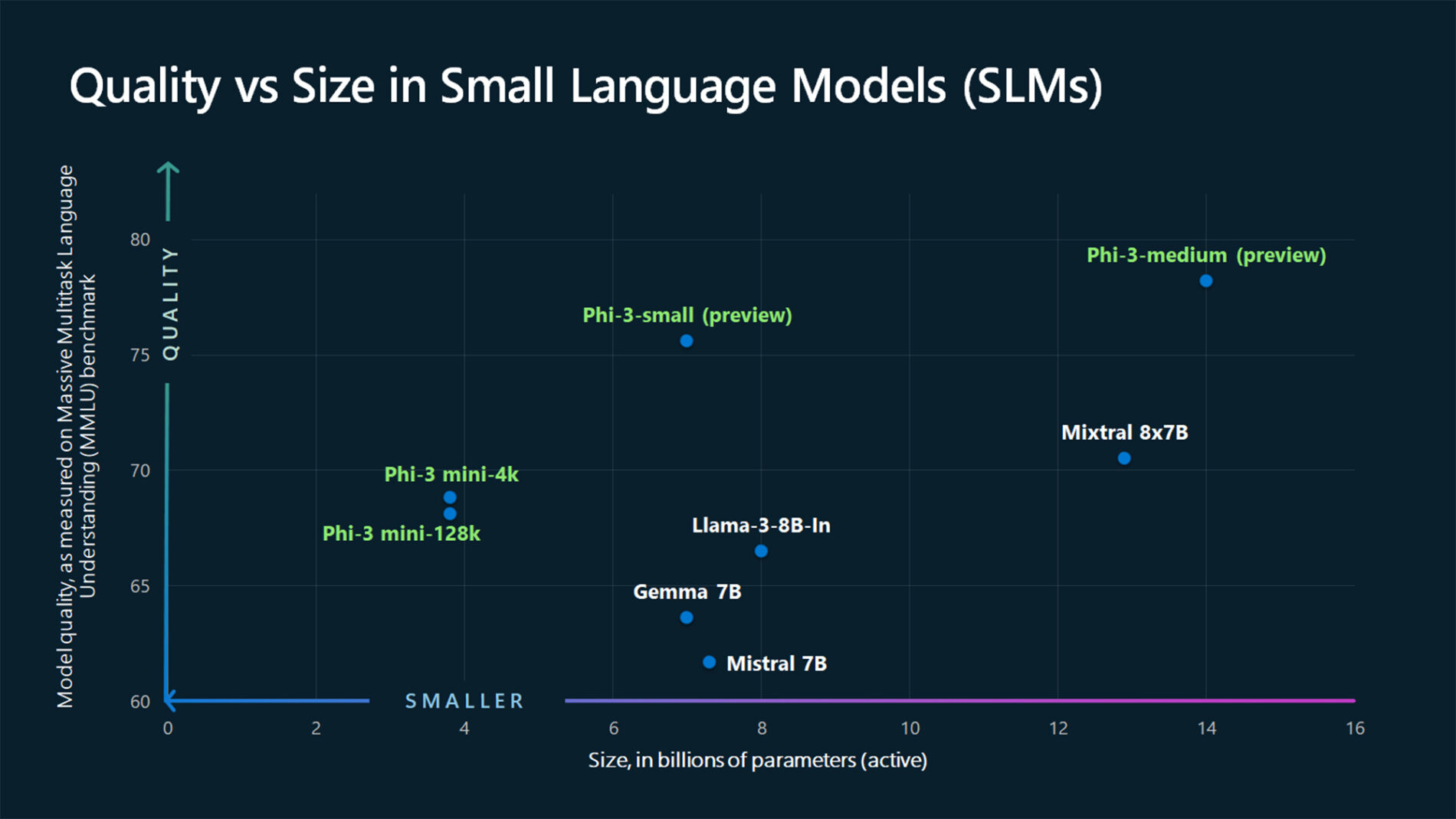
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: phi-4-omni
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Изображения разбиваются на маркеры и отправляются в модель для обработки. При обращении к изображениям каждый из этих маркеров обычно называется исправлениями. Каждая модель может разбить заданное изображение на разное количество фрагментов. Прочитайте карточку модели, чтобы узнать подробности.
Использование возможностей завершения чата с аудио
Некоторые модели могут рассуждать на основе текстовых и аудио данных. В следующем примере показано, как можно отправлять аудиоконтекст в модели завершения чатов, которые также поддерживают звук. Используйте InputAudio для загрузки содержимого звукового файла в пакет. Содержимое кодируется в формате base64 и отправляется в составе полезной нагрузки.
from azure.ai.inference.models import (
TextContentItem,
AudioContentItem,
InputAudio,
AudioContentFormat,
)
response = client.complete(
messages=[
SystemMessage("You are an AI assistant for translating and transcribing audio clips."),
UserMessage(
[
TextContentItem(text="Please translate this audio snippet to spanish."),
AudioContentItem(
input_audio=InputAudio.load(
audio_file="hello_how_are_you.mp3", audio_format=AudioContentFormat.MP3
)
),
],
),
],
)
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
print(f"{response.choices[0].message.role}: {response.choices[0].message.content}")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
Модель может считывать содержимое из доступного облачного расположения , передав URL-адрес в качестве входных данных. SDK для Python не предоставляет прямого способа это сделать, но вы можете указать данные следующим образом:
response = client.complete(
{
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips.",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "audio_url",
"audio_url": {
"url": "https://.../hello_how_are_you.mp3"
}
}
]
},
],
}
)
Звук разбивается на маркеры и отправляется в модель для обработки. Некоторые модели могут работать непосредственно над маркерами звука, а другие могут использовать внутренние модули для выполнения речи в текст, что приводит к различным стратегиям вычислений маркеров. Ознакомьтесь с карточкой модели, чтобы узнать, как работает каждая модель.
Это важно
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Для получения дополнительной информации см. Дополнительные условия использования для предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать API завершения чата с многомодальными моделями, развернутыми в модели искусственного интеллекта Azure в службах ИИ Azure. Помимо ввода текста многомодальные модели могут принимать другие типы входных данных, такие как изображения или входные данные звука.
Предпосылки
Чтобы использовать модели завершения чата в приложении, вам потребуется:
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и одновременно создать подписку на Azure. Ознакомьтесь с материалом «Переход от моделей GitHub к моделям предсказания AI Azure», если вам это необходимо.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Установите библиотеку вывода Azure для JavaScript с помощью следующей команды:
npm install @azure-rest/ai-inference npm install @azure/core-auth npm install @azure/identityЕсли вы используете Node.js, вы можете настроить зависимости в package.json:
package.json
{ "name": "main_app", "version": "1.0.0", "description": "", "main": "app.js", "type": "module", "dependencies": { "@azure-rest/ai-inference": "1.0.0-beta.6", "@azure/core-auth": "1.9.0", "@azure/core-sse": "2.2.0", "@azure/identity": "4.8.0" } }Импортируйте следующее:
import ModelClient from "@azure-rest/ai-inference"; import { isUnexpected } from "@azure-rest/ai-inference"; import { createSseStream } from "@azure/core-sse"; import { AzureKeyCredential } from "@azure/core-auth"; import { DefaultAzureCredential } from "@azure/identity";
Развертывание модели завершения чата с поддержкой звука и изображений. Если у вас нет одного, см. статью "Добавление и настройка моделей в службы ИИ Azure ", чтобы добавить модель завершения чата в ресурс.
- Для этой статьи используется
Phi-4-multimodal-instruct.
- Для этой статьи используется
Используйте завершение чата
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
const client = ModelClient(
"https://<resource>.services.ai.azure.com/models",
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Если вы настроили ресурс с поддержкой идентификатора Microsoft Entra, можно использовать следующий фрагмент кода для создания клиента.
const clientOptions = { credentials: { "https://cognitiveservices.azure.com" } };
const client = ModelClient(
"https://<resource>.services.ai.azure.com/models",
new DefaultAzureCredential()
clientOptions,
);
Используйте функции завершения чата с изображениями
Некоторые модели способны обрабатывать текст и изображения и генерировать текстовые дополнения на основе обоих типов входных данных. В этом разделе вы исследуете возможности некоторых визуальных моделей в чат-формате.
Это важно
Некоторые модели поддерживают только одно изображение для каждого этапа беседы в чате, и только последняя картинка сохраняется в контексте. При добавлении нескольких изображений это приведет к ошибке.
Чтобы увидеть эту возможность, скачайте изображение и закодируйте сведения в виде base64 строки. Полученные данные должны находиться внутри URL-адреса данных:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Визуализировать изображение:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
Теперь создайте запрос на завершение чата с изображением:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
model: "Phi-4-multimodal-instruct",
}
});
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: Phi-4-multimodal-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Изображения разбиваются на маркеры и отправляются в модель для обработки. При обращении к изображениям каждый из этих маркеров обычно называется исправлениями. Каждая модель может разбить заданное изображение на другое количество исправлений. Прочитайте карточку модели, чтобы узнать подробности.
Это важно
Некоторые модели поддерживают только одно изображение для каждого хода беседы в чате, и только последнее изображение сохраняется в контексте. При добавлении нескольких изображений это приведет к ошибке.
Использование завершения чата с звуком
Некоторые модели могут рассуждать на основе текстовых и аудио данных. В следующем примере показано, как можно отправлять аудиоконтекст в модели завершения чатов, которые также поддерживают звук.
В этом примере мы создаём функцию getAudioData для загрузки содержимого звукового файла, закодированного в данные base64, так как этого ожидала модель.
import fs from "node:fs";
/**
* Get the Base 64 data of an audio file.
* @param {string} audioFile - The path to the image file.
* @returns {string} Base64 data of the audio.
*/
function getAudioData(audioFile: string): string {
try {
const audioBuffer = fs.readFileSync(audioFile);
return audioBuffer.toString("base64");
} catch (error) {
console.error(`Could not read '${audioFile}'.`);
console.error("Set the correct path to the audio file before running this sample.");
process.exit(1);
}
}
Теперь используйте эту функцию для загрузки содержимого звукового файла, хранящегося на диске. Мы отправим содержимое звукового файла в сообщении пользователя. Обратите внимание, что в запросе также указывается формат звукового содержимого:
const audioFilePath = "hello_how_are_you.mp3"
const audioFormat = "mp3"
const audioData = getAudioData(audioFilePath);
const systemMessage = { role: "system", content: "You are an AI assistant for translating and transcribing audio clips." };
const audioMessage = {
role: "user",
content: [
{ type: "text", text: "Translate this audio snippet to spanish."},
{ type: "input_audio",
input_audio: {
audioData,
audioFormat,
},
},
]
};
const response = await client.path("/chat/completions").post({
body: {
messages: [
systemMessage,
audioMessage
],
model: "Phi-4-multimodal-instruct",
},
});
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
Модель может считывать содержимое из доступного облачного расположения , передав URL-адрес в качестве входных данных. SDK для Python не предоставляет прямого способа это сделать, но вы можете указать данные следующим образом:
const systemMessage = { role: "system", content: "You are a helpful assistant." };
const audioMessage = {
role: "user",
content: [
{ type: "text", text: "Transcribe this audio."},
{ type: "audio_url",
audio_url: {
url: "https://example.com/audio.mp3",
},
},
]
};
const response = await client.path("/chat/completions").post({
body: {
messages: [
systemMessage,
audioMessage
],
model: "Phi-4-multimodal-instruct",
},
});
Звук разбивается на маркеры и отправляется в модель для обработки. Некоторые модели могут работать непосредственно над маркерами звука, а другие могут использовать внутренние модули для выполнения речи в текст, что приводит к различным стратегиям вычислений маркеров. Ознакомьтесь с карточкой модели, чтобы узнать, как работает каждая модель.
В этой статье объясняется, как использовать API завершения чата с многомодальными моделями, развернутыми для вывода моделей искусственного интеллекта Azure в службах Azure AI. Помимо ввода текста многомодальные модели могут принимать другие типы входных данных, такие как изображения или входные данные звука.
Предпосылки
Чтобы использовать модели завершения чата в приложении, вам потребуется:
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и одновременно создать подписку на Azure. Ознакомьтесь с материалом «Переход от моделей GitHub к моделям предсказания AI Azure», если вам это необходимо.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Добавьте пакет вывода искусственного интеллекта Azure в проект:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.4</version> </dependency>Если вы используете Entra ID, вам также потребуется следующий пакет:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.15.3</version> </dependency>Импортируйте следующее пространство имен:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.ChatCompletionsClient; import com.azure.ai.inference.ChatCompletionsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.ai.inference.models.ChatCompletions; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Развертывание модели завершения сеансов чата. Если у вас её нет, прочитайте «Добавление и настройка моделей в службах ИИ Azure», чтобы добавить модель завершения чата в свой ресурс.
- В этом примере используется
phi-4-multimodal-instruct.
- В этом примере используется
Используйте завершение чата
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
ChatCompletionsClient client = new ChatCompletionsClientBuilder()
.credential(new AzureKeyCredential("{key}"))
.endpoint("https://<resource>.services.ai.azure.com/models")
.buildClient();
Если вы настроили ресурс с поддержкой идентификатора Microsoft Entra, можно использовать следующий фрагмент кода для создания клиента.
TokenCredential defaultCredential = new DefaultAzureCredentialBuilder().build();
ChatCompletionsClient client = new ChatCompletionsClientBuilder()
.credential(defaultCredential)
.endpoint("https://<resource>.services.ai.azure.com/models")
.buildClient();
Использование завершения чата с изображениями
Некоторые модели способны обрабатывать текст и изображения и генерировать текстовые дополнения на основе обоих типов входных данных. В этом разделе вы исследуете возможности некоторых моделей для зрения в разговорной манере.
Чтобы увидеть эту возможность, скачайте изображение и закодируйте сведения в виде base64 строки. Полученные данные должны находиться внутри URL-адреса данных:
Path testFilePath = Paths.get("small-language-models-chart-example.jpg");
String imageFormat = "jpg";
Визуализировать изображение:
Теперь создайте запрос на завершение чата с изображением:
List<ChatMessageContentItem> contentItems = new ArrayList<>();
contentItems.add(new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"));
contentItems.add(new ChatMessageImageContentItem(testFilePath, imageFormat));
List<ChatRequestMessage> chatMessages = new ArrayList<>();
chatMessages.add(new ChatRequestSystemMessage("You are an AI assistant that helps people find information."));
chatMessages.add(ChatRequestUserMessage.fromContentItems(contentItems));
ChatCompletionsOptions options = new ChatCompletionsOptions(chatMessages);
options.setModel("phi-4-multimodal-instruct")
ChatCompletions response = client.complete(options);
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
System.out.println("Response: " + response.getValue().getChoices().get(0).getMessage().getContent());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
System.out.println("\tCompletion tokens: " + response.getValue().getUsage().getCompletionTokens());
Изображения разбиваются на маркеры и отправляются в модель для обработки. При обращении к изображениям каждый из этих маркеров обычно называется исправлениями. Каждая модель может разбить заданное изображение на разное количество фрагментов. Прочитайте карточку модели, чтобы узнать подробности.
Это важно
Некоторые модели поддерживают только одно изображение для каждого цикла беседы в чате, и только последнее изображение сохраняется в контексте. При добавлении нескольких изображений это приведет к ошибке.
Служба может считывать содержимое из доступного облачного расположения , передав URL-адрес в качестве входных данных.
Path testFilePath = Paths.get("https://.../small-language-models-chart-example.jpg");
List<ChatMessageContentItem> contentItems = new ArrayList<>();
contentItems.add(new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"));
contentItems.add(new ChatMessageImageContentItem(
new ChatMessageImageUrl(testFilePath)));
List<ChatRequestMessage> chatMessages = new ArrayList<>();
chatMessages.add(new ChatRequestSystemMessage("You are an AI assistant that helps people find information."));
chatMessages.add(ChatRequestUserMessage.fromContentItems(contentItems));
ChatCompletionsOptions options = new ChatCompletionsOptions(chatMessages);
options.setModel("phi-4-multimodal-instruct")
ChatCompletions response = client.complete(options);
Использование завершения чата с звуком
Некоторые модели могут рассуждать на основе текстовых и аудио данных. Эта возможность недоступна в пакете вывода искусственного интеллекта Azure для Java.
Это важно
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Для получения дополнительной информации см. Дополнительные условия использования для предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать API завершения чата с многомодальными моделями, развернутыми для инференса моделей ИИ в службах Azure AI. Помимо ввода текста многомодальные модели могут принимать другие типы входных данных, такие как изображения или входные данные звука.
Предпосылки
Чтобы использовать модели завершения чата в приложении, вам потребуется:
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и одновременно создать подписку на Azure. Ознакомьтесь с материалом «Переход от моделей GitHub к моделям предсказания AI Azure», если вам это необходимо.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Установите пакет вывода искусственного интеллекта Azure с помощью следующей команды:
dotnet add package Azure.AI.Inference --prereleaseЕсли вы используете Entra ID, вам также потребуется следующий пакет:
dotnet add package Azure.Identity
Развертывание модели завершения чата. Если у вас такой модели нет, прочитайте о том, как добавить и настроить модели в службах ИИ Azure, чтобы добавить модель для завершения чата в ваш ресурс.
- В этом примере используется
phi-4-multimodal-instruct.
- В этом примере используется
Используйте завершение чата
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
);
Если вы настроили ресурс с поддержкой идентификатора Microsoft Entra, можно использовать следующий фрагмент кода для создания клиента.
TokenCredential credential = new DefaultAzureCredential(includeInteractiveCredentials: true);
AzureAIInferenceClientOptions clientOptions = new AzureAIInferenceClientOptions();
BearerTokenAuthenticationPolicy tokenPolicy = new BearerTokenAuthenticationPolicy(credential, new string[] { "https://cognitiveservices.azure.com/.default" });
clientOptions.AddPolicy(tokenPolicy, HttpPipelinePosition.PerRetry);
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
credential,
clientOptions,
);
Использование завершения чата с изображениями
Некоторые модели способны обрабатывать текст и изображения и генерировать текстовые дополнения на основе обоих типов входных данных. В этом разделе вы исследуете возможности некоторых моделей для зрения в разговорной манере.
Это важно
Некоторые модели поддерживают только одно изображение для каждого хода в беседе в чате, и только последнее изображение сохраняется в контексте. При добавлении нескольких изображений это приведет к ошибке.
Чтобы увидеть эту возможность, скачайте изображение и закодируйте сведения в виде base64 строки. Полученные данные должны находиться внутри URL-адреса данных:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Визуализировать изображение:
Теперь создайте запрос на завершение чата с изображением:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
Model = "Phi-4-multimodal-instruct",
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: Phi-4-multimodal-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Изображения разбиваются на маркеры и отправляются в модель для обработки. При обращении к изображениям каждый из этих маркеров обычно называется исправлениями. Каждая модель может разбить заданное изображение на разное количество фрагментов. Прочитайте карточку модели, чтобы узнать подробности.
Это важно
Некоторые модели поддерживают только одно изображение на каждый ход в беседе в чате, и только последнее изображение сохраняется в контексте. При добавлении нескольких изображений это приведет к ошибке.
Использование завершения чата с звуком
Некоторые модели могут рассуждать на основе текстовых и аудио данных. В следующем примере показано, как можно отправлять аудиоконтекст в модели завершения чатов, которые также поддерживают звук. Используйте InputAudio для загрузки содержимого звукового файла в пакет. Содержимое кодируется в формате base64 и отправляется в составе полезной нагрузки.
var requestOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatRequestSystemMessage("You are an AI assistant for translating and transcribing audio clips."),
new ChatRequestUserMessage(
new ChatMessageTextContentItem("Please translate this audio snippet to spanish."),
new ChatMessageAudioContentItem("hello_how_are_you.mp3", AudioContentFormat.Mp3),
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
Модель может считывать содержимое из доступного облачного расположения , передав URL-адрес в качестве входных данных. SDK для Python не предоставляет прямого способа это сделать, но вы можете указать данные следующим образом:
var requestOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatRequestSystemMessage("You are an AI assistant for translating and transcribing audio clips."),
new ChatRequestUserMessage(
new ChatMessageTextContentItem("Please translate this audio snippet to spanish."),
new ChatMessageAudioContentItem(new Uri("https://.../hello_how_are_you.mp3"))),
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
Звук разбивается на маркеры и отправляется в модель для обработки. Некоторые модели могут работать непосредственно над маркерами звука, а другие могут использовать внутренние модули для выполнения речи в текст, что приводит к различным стратегиям вычислений маркеров. Ознакомьтесь с карточкой модели, чтобы узнать, как работает каждая модель.
Это важно
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Для получения дополнительной информации см. Дополнительные условия использования для предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать API завершения чата с многомодальными моделями, развернутыми для вывода моделей в службах ИИ Azure. Помимо ввода текста многомодальные модели могут принимать другие типы входных данных, такие как изображения или входные данные звука.
Предпосылки
Чтобы использовать модели завершения чата в приложении, вам потребуется:
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и одновременно создать подписку на Azure. Ознакомьтесь с материалом «Переход от моделей GitHub к моделям предсказания AI Azure», если вам это необходимо.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Развертывание модели завершения чата. Если у вас нет одного, см. статью "Добавление и настройка моделей в службы ИИ Azure ", чтобы добавить модель завершения чата в ресурс.
- Для этой статьи используется
Phi-4-multimodal-instruct.
- Для этой статьи используется
Используйте завершение чата
Чтобы использовать API завершения чата, используйте маршрут /chat/completions , добавленный к базовому URL-адресу, а также учетные данные, указанные в api-key.
Authorization Заголовок также поддерживается в формате Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Если вы настроили ресурс с поддержкой Microsoft Entra ID, передайте токен в заголовке Authorization с форматом Bearer <token>. Используйте область https://cognitiveservices.azure.com/.default.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Использование идентификатора Microsoft Entra может потребовать дополнительной конфигурации в ресурсе для предоставления доступа. Узнайте, как настроить проверку подлинности без ключей с помощью идентификатора Microsoft Entra.
Использование завершения чата с изображениями
Некоторые модели способны обрабатывать текст и изображения и генерировать текстовые дополнения на основе обоих типов входных данных. В этом разделе вы исследуете возможности некоторых моделей для зрения в разговорной манере.
Это важно
Некоторые модели поддерживают только одно изображение для каждого шага в беседе чата, и только последнее изображение сохраняется в контексте. При добавлении нескольких изображений это приведет к ошибке.
Чтобы увидеть эту возможность, скачайте изображение и закодируйте сведения в виде base64 строки. Полученные данные должны находиться внутри URL-адреса данных:
Подсказка
Вам потребуется создать URL-адрес данных с помощью языка сценариев или программирования. В этой статье используется этот образ в формате JPEG. URL-адрес данных имеет следующий формат: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ...
{kind=link}
Визуализировать изображение:
Теперь создайте запрос на завершение чата с изображением:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}
Изображения разбиваются на маркеры и отправляются в модель для обработки. При обращении к изображениям каждый из этих маркеров обычно называется исправлениями. Каждая модель может разбить заданное изображение на разное количество фрагментов. Прочитайте карточку модели, чтобы узнать подробности.
Использование завершения чата с звуком
Некоторые модели могут рассуждать на основе текстовых и аудио данных. В следующем примере показано, как можно отправлять аудиоконтекст в модели завершения чатов, которые также поддерживают звук.
Следующий пример отправляет звуковое содержимое, закодированное в base64 данных в журнале чата:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "input_audio",
"input_audio": {
"data": "0xABCDFGHIJKLMNOPQRSTUVWXYZ...",
"format": "mp3"
}
}
]
}
],
}
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hola. ¿Cómo estás?",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 77,
"completion_tokens": 7,
"total_tokens": 84
}
}
Модель может считывать содержимое из доступного облачного расположения , передав URL-адрес в качестве входных данных. Пэйлоад можно указать следующим образом:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "audio_url",
"audio_url": {
"url": "https://.../hello_how_are_you.mp3",
}
}
]
}
],
}
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hola. ¿Cómo estás?",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 77,
"completion_tokens": 7,
"total_tokens": 84
}
}
Звук разбивается на маркеры и отправляется в модель для обработки. Некоторые модели могут работать непосредственно над маркерами звука, а другие могут использовать внутренние модули для выполнения речи в текст, что приводит к различным стратегиям вычислений маркеров. Ознакомьтесь с карточкой модели, чтобы узнать, как работает каждая модель.