Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Una topologia con distribuzione geografica a disponibilità elevata offre:
- Eliminazione di un singolo punto di errore: con le funzionalità di failover, è possibile ottenere un'infrastruttura AD FS a disponibilità elevata anche se uno dei data center in una parte di un globo diventa inattivo.
- Prestazioni migliorate: è possibile usare la distribuzione suggerita per fornire un'infrastruttura AD FS ad alte prestazioni
AD FS può essere configurato per uno scenario con distribuzione geografica a disponibilità elevata. La guida seguente illustra una panoramica di AD FS con i gruppi di disponibilità AlwaysOn di SQL e fornisce considerazioni e indicazioni sulla distribuzione.
Panoramica - Gruppi di disponibilità AlwaysOn
Per altre informazioni sui gruppi di disponibilità AlwaysOn, vedere Panoramica dei gruppi di disponibilità AlwaysOn (SQL Server)
Dal punto di vista dei nodi di una farm di SQL Server AD FS, il gruppo di disponibilità AlwaysOn sostituisce la singola istanza di SQL Server come database delle policy e degli artifact. Il listener del gruppo di disponibilità è ciò che il client (il servizio token di sicurezza AD FS) utilizza per connettersi a SQL. Il diagramma seguente illustra una farm di SQL Server AD FS con un gruppo di disponibilità AlwaysOn.
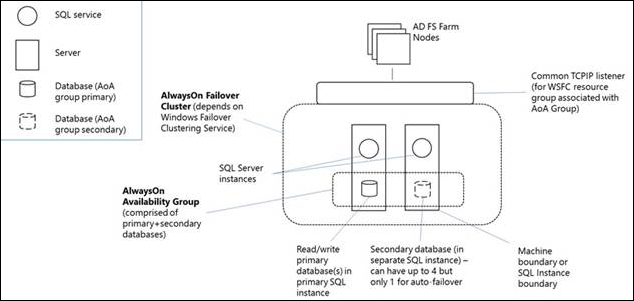
Un gruppo di disponibilità Always On è uno o più database utente che effettuano il failover insieme. Un gruppo di disponibilità è costituito da una replica di disponibilità primaria e da una a quattro repliche secondarie gestite tramite lo spostamento dei dati basato su log di SQL Server per la protezione dei dati senza la necessità di archiviazione condivisa. Ogni replica è ospitata da un'istanza di SQL Server in un nodo diverso del cluster WSFC. Il gruppo di disponibilità e un nome di rete virtuale corrispondente vengono registrati come risorse nel cluster WSFC.
Un listener del gruppo di disponibilità nel nodo della replica primaria risponde alle richieste client in ingresso per connettersi al nome della rete virtuale e, in base agli attributi nella stringa di connessione, reindirizza ogni richiesta all'istanza di SQL Server appropriata. In caso di failover, invece di trasferire la proprietà delle risorse fisiche condivise a un altro nodo, WSFC viene sfruttato per riconfigurare una replica secondaria in un'altra istanza di SQL Server per diventare la replica primaria del gruppo di disponibilità. La risorsa relativa al nome di rete virtuale del gruppo di disponibilità viene quindi trasferita a quell'istanza. In un determinato momento, solo una singola istanza di SQL Server può ospitare la replica primaria dei database di un gruppo di disponibilità, tutte le repliche secondarie associate devono risiedere in un'istanza separata e ogni istanza deve risiedere in nodi fisici separati.
Note
Se i computer sono in esecuzione in Azure, configurare le macchine virtuali di Azure per consentire alla configurazione del listener di comunicare con i gruppi di disponibilità AlwaysOn. Per ulteriori informazioni, Macchine Virtuali: SQL Always On Listener.
Per altre informazioni generali sui gruppi di disponibilità AlwaysOn, vedere Panoramica dei gruppi di disponibilità AlwaysOn (SQL Server).
Note
Se l'organizzazione richiede il failover in più data center, è consigliabile creare un database artefatto in ogni data center e abilitare una cache in background che riduce la latenza durante l'elaborazione delle richieste. Seguire le istruzioni per eseguire questa operazione in Ottimizzazione di SQL e Riduzione della latenza.
Linee guida per la distribuzione
- Prendere in considerazione il database corretto per gli obiettivi della distribuzione di AD FS. AD FS usa un database per archiviare la configurazione e in alcuni casi i dati transazionali correlati al servizio federativo. È possibile usare il software AD FS per selezionare il database interno di Windows (WID) o Microsoft SQL Server 2008 o versione successiva per archiviare i dati nel servizio federativo. Nella tabella seguente vengono descritte le differenze tra le funzionalità supportate tra un database WID e SQL.
| Category | Feature | Supportato da WID | Supportato da SQL |
|---|---|---|---|
| Funzionalità di AD FS | Distribuzione della server farm di federazione | Yes | Yes |
| Funzionalità di AD FS | Risoluzione degli artefatti SAML. Nota: questo non è comune per le applicazioni SAML | No | Yes |
| Funzionalità di AD FS | Rilevamento della duplicazione del token SAML/WS-Federation. Nota: obbligatorio solo quando AD FS riceve i token dagli IDP esterni. Questo non è obbligatorio se AD FS non funge da partner federativo. | No | Yes |
| Funzionalità del database | Ridondanza di base del database tramite la replica pull, in cui uno o più server che ospitano una copia di sola lettura delle modifiche alle richieste di database apportate in un server di origine ospitano una copia di lettura/scrittura del database | No | No |
| Funzionalità del database | Ridondanza del database tramite soluzioni a disponibilità elevata, ad esempio il clustering o il mirroring (a livello di database) | No | Yes |
| Funzionalità aggiuntive | Scenario di OAuth con Codice di Autenticazione | Yes | Yes |
Se si è un'organizzazione di grandi dimensioni con più di 100 relazioni di trust che devono fornire sia agli utenti interni che agli utenti esterni l'accesso Single Sign-On alle applicazioni o ai servizi federativi, SQL è l'opzione consigliata.
Se si è un'organizzazione con 100 o meno relazioni di trust configurate, WID fornisce ridondanza dei dati e del servizio federativo (in cui ogni server federativo replica le modifiche ad altri server federativi nella stessa farm). WiD non supporta il rilevamento della riproduzione dei token o la risoluzione degli artefatti e ha un limite di 30 server federativi. Per altre informazioni sulla pianificazione della distribuzione, vedere qui.
Soluzioni a disponibilità elevata di SQL Server
Se si usa SQL Server come database di configurazione di AD FS, è possibile configurare la ridondanza geografica per la farm AD FS usando la replica di SQL Server. La ridondanza geografica replica i dati tra due siti geograficamente distanti in modo che le applicazioni possano passare da un sito a un altro. In questo modo, in caso di errore di un sito, è comunque possibile avere tutti i dati di configurazione disponibili nel secondo sito. Se SQL è il database appropriato per gli obiettivi di distribuzione, procedere con questa guida alla distribuzione.
Questa guida illustra le procedure seguenti
- Distribuire AD FS
- Configurare AD FS per l'uso di gruppi di disponibilità AlwaysOn
- Installare il ruolo cluster di failover
- Eseguire test di convalida del cluster
- Abilitare i gruppi di disponibilità AlwaysOn
- Eseguire il backup di database AD FS
- Creare gruppi di disponibilità AlwaysOn
- Aggiungere database nel secondo nodo
- Aggiungere una Replica di disponibilità a un Gruppo di disponibilità
- Aggiornare la stringa di connessione SQL
Distribuire AD FS
Note
Se i computer sono in esecuzione in Azure, le macchine virtuali devono essere configurate in modo specifico per consentire al listener di comunicare con il gruppo di disponibilità AlwaysOn. Per informazioni sulla configurazione, vedere Configurare un servizio di bilanciamento del carico per un gruppo di disponibilità in macchine virtuali di SQL Server di Azure
Questa guida alla distribuzione mostrerà una farm a due nodi con due server SQL come esempio. Per distribuire AD FS, seguire i collegamenti iniziali seguenti per installare il servizio ruolo AD FS. Per configurare per un gruppo AoA, saranno necessari passaggi aggiuntivi per il ruolo.
- Aggiungere un computer a un dominio
- Registrare un certificato SSL per AD FS
- Installare il servizio ruolo AD FS
Configurazione di AD FS per l'uso di un gruppo di disponibilità AlwaysOn
La configurazione di una farm AD FS con i gruppi di disponibilità AlwaysOn richiede una leggera modifica alla procedura di distribuzione di AD FS. Assicurarsi che ogni istanza del server esegua la stessa versione di SQL. Per visualizzare l'elenco completo di prerequisiti, restrizioni e consigli per i gruppi di disponibilità AlwaysOn, leggere qui.
- I database di cui si vuole eseguire il backup devono essere creati prima di poter configurare i gruppi di disponibilità AlwaysOn. AD FS crea i database come parte dell'installazione e della configurazione iniziale del primo nodo del servizio federativo di una nuova farm di SQL Server AD FS. Specificare il nome host del database per la farm esistente usando SQL Server. Come parte della configurazione di AD FS, è necessario specificare una stringa di connessione SQL, quindi sarà necessario configurare la prima farm AD FS per connettersi direttamente a un'istanza SQL (solo temporanea). Per indicazioni specifiche sulla configurazione di una farm AD FS, inclusa la configurazione di un nodo della farm AD FS con una stringa di connessione di SQL Server, vedere Configurare un server federativo.
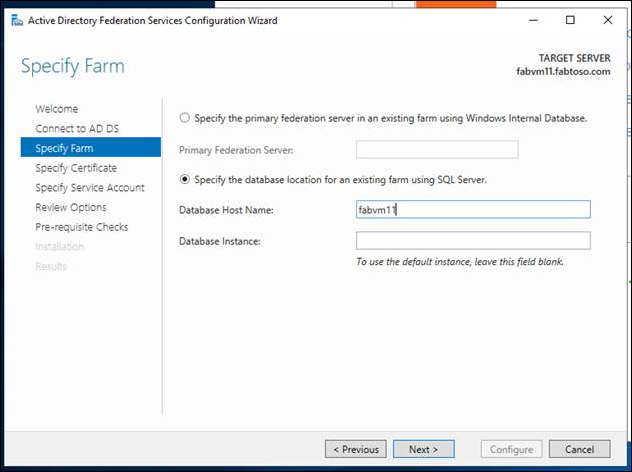
- Verificare la connettività al database usando SSMS e quindi connettersi al nome host del database di destinazione. Se si aggiunge un altro nodo alla farm federativa, connettersi al database di destinazione.
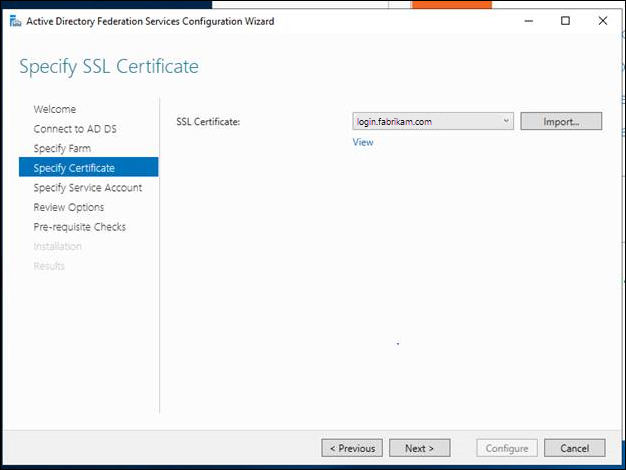
- Specificare il certificato SSL per la farm AD FS.
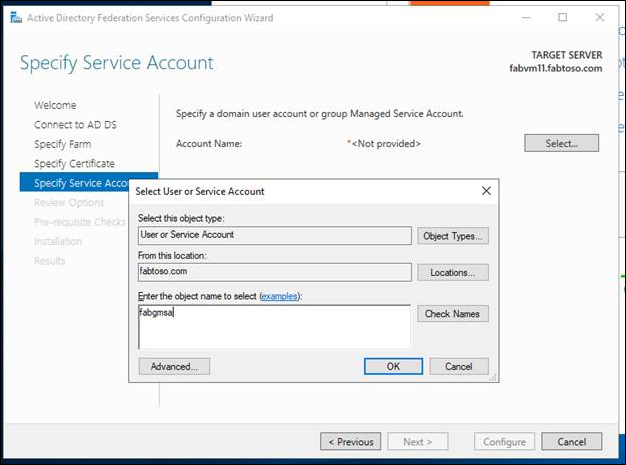
- Collegare la farm a un account di servizio o gMSA.
- Completare la configurazione e l'installazione della farm AD FS.
Note
SQL Server deve essere eseguito con un account di dominio per l'installazione di gruppi di disponibilità AlwaysOn. Per impostazione predefinita, viene eseguito come sistema locale.
Installare il ruolo cluster di failover
Il ruolo di Cluster di failover di Windows Server consente l'accesso a maggiori informazioni sui cluster di failover di Windows Server.
- Avviare Server Manager.
- Scegliere Aggiungi ruoli e funzionalità dal menu Gestisci.
- Nella pagina Prima di iniziare selezionare Avanti.
- Nella pagina Selezione tipo di installazione selezionare Installazione basata su ruoli o basata su funzionalità e quindi selezionare Avanti.
- Nella pagina Selezione server di destinazione selezionare il server SQL in cui si vuole installare la funzionalità e quindi selezionare Avanti.
- Nella pagina Selezione ruoli server selezionare Avanti.
- Nella pagina Selezione funzionalità, selezionare la casella di controllo Clustering di failover.
- Nella pagina Conferma selezioni installazione selezionare Installa. Un riavvio del server non è necessario per la funzionalità Clustering di failover.
- Al termine dell'installazione, selezionare Chiudi.
- Ripetere la procedura su tutti i server che si desidera aggiungere come nodi di failover del cluster.
Eseguire test di convalida del cluster
- In un computer in cui sono installati gli strumenti di gestione cluster di failover da Strumenti di amministrazione remota del server o in un server in cui è stata installata la funzionalità Clustering di failover, avviare Gestione cluster di failover. Per eseguire questa operazione in un server, avviare Server Manager e quindi scegliere Gestione cluster di failover dal menu Strumenti.
- Nel riquadro Gestione cluster di failover selezionare Convalida configurazione in Gestione.
- Nella pagina Prima di iniziare selezionare Avanti.
- Nella pagina Seleziona server o cluster immettere il nome NetBIOS o il nome di dominio completo di un server da aggiungere come nodo del cluster di failover e quindi selezionare Aggiungi. Ripetere questo passaggio per ogni server da aggiungere. Per aggiungere più server contemporaneamente, separare i nomi con una virgola o un punto e virgola. Ad esempio, immettere i nomi nel formato server1.contoso.com, server2.contoso.com. Al termine, selezionare Avanti.
- Nella pagina Opzioni di test selezionare Esegui tutti i test (scelta consigliata) e quindi selezionare Avanti.
- Nella pagina Conferma selezionare Avanti. Nella pagina Convalida in corso verrà visualizzato lo stato dei test in esecuzione.
- Nella pagina Riepilogo eseguire una delle operazioni seguenti:
- Se i risultati indicano che i test sono stati completati correttamente e che la configurazione è adatta per il clustering e si vuole creare immediatamente il cluster, assicurarsi che sia selezionata la casella di controllo Crea il cluster usando i nodi convalidati e quindi selezionare Fine. Poi, continuare con il passaggio 4 della procedura di creazione del cluster di failover.
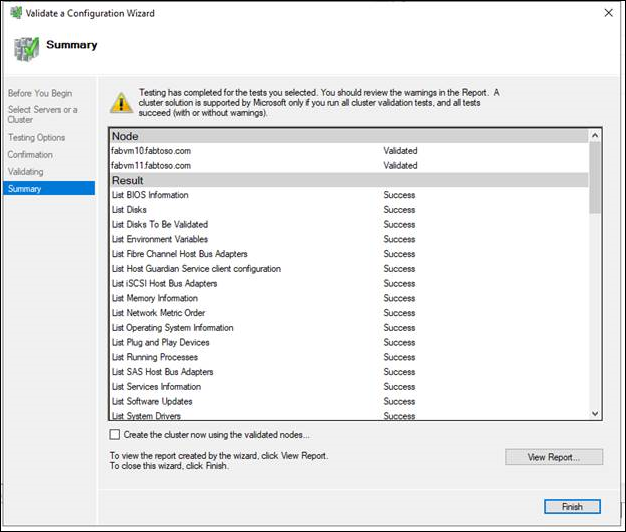
- Se i risultati indicano che si sono verificati avvisi o errori, selezionare Visualizza report per visualizzare i dettagli e determinare quali problemi devono essere corretti. Tenere presente che un avviso per un determinato test di convalida indica che questo aspetto del cluster di failover può essere supportato, ma potrebbe non soddisfare le procedure consigliate.
Note
Se viene visualizzato un avviso per il test Convalida prenotazione permanente degli spazi di archiviazione, vedere il post di blog sulla visualizzazione di un avviso relativo alla convalida del cluster di failover di Windows che indica che i dischi in uso non supportano le prenotazioni permanenti per gli spazi di archiviazione per ottenere altre informazioni. Per altre informazioni sui test di convalida dell'hardware, vedere Validate Hardware for a Failover Cluster.
Creare il cluster di failover
Per completare questo passaggio, verificare che l'account utente con cui si esegue l'accesso soddisfa i requisiti indicati nella sezione Verificare i prerequisiti di questo argomento.
- Avviare Server Manager.
- Scegliere Gestione cluster di failover dal menu Strumenti.
- Nel riquadro Gestione cluster di failover selezionare Crea cluster in Gestione. Verrà visualizzata la Creazione guidata cluster.
- Nella pagina Prima di iniziare selezionare Avanti.
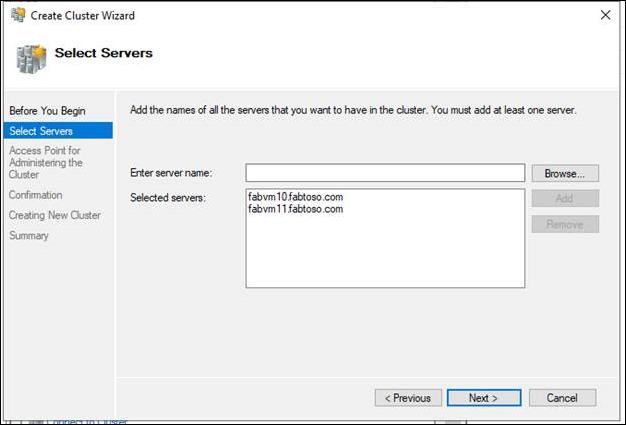
- Se viene visualizzata la pagina Seleziona server, nella casella Immetti nome immettere il nome NetBIOS o il nome di dominio completo di un server che si prevede di aggiungere come nodo del cluster di failover e quindi selezionare Aggiungi. Ripetere questo passaggio per ogni server da aggiungere. Per aggiungere più server contemporaneamente, separare i nomi con una virgola o un punto e virgola. Ad esempio, immettere i nomi nel formato server1.contoso.com; server2.contoso.com. Al termine, selezionare Avanti.
Note
Se si sceglie di creare il cluster immediatamente dopo l'esecuzione della convalida nella procedura di convalida della configurazione, non verrà visualizzata la pagina Selezione server. I nodi che hanno superato la convalida vengono aggiunti automaticamente alla Creazione guidata cluster e non sarà più necessario immetterli successivamente.
- Se la convalida è stata ignorata in precedenza, viene visualizzata la pagina Avviso di convalida. Consigliamo vivamente di eseguire la convalida del cluster. Solo i cluster che superano tutti i test di convalida sono supportati da Microsoft. Per eseguire i test di convalida, selezionare Sì e quindi selezionare Avanti. Completare la Convalida una Configurazione guidata come descritto in Convalidare la configurazione.
- Nella pagina Punto di accesso per l'amministrazione del cluster eseguire le operazioni seguenti:
- Nella casella Nome cluster immettere il nome da usare per amministrare il cluster. Prima di procedere, tuttavia, prendere nota delle informazioni seguenti:
- Durante la creazione del cluster, questo nome viene registrato come oggetto computer del cluster (noto anche come oggetto nome del cluster o CNO) in Active Directory Domain Services. Se si specifica un nome NetBIOS per il cluster, l'oggetto CNO viene creato nello stesso percorso in cui risiedono gli altri oggetti computer per i nodi del cluster. Questo può essere il contenitore Computer predefinito o un'unità organizzativa.
- Per specificare un percorso diverso per il CNO, è possibile immettere il nome distinto di un'unità organizzativa nella casella Nome cluster. Ad esempio: CN=ClusterName, OU=Clusters, DC=Contoso, DC=com.
- Se un amministratore di dominio ha pre-installato l'oggetto CNO in un'unità organizzativa differente rispetto a quella in cui risiedono i nodi del cluster, specificare il nome distinto fornito dall'amministratore.
- Se il server non dispone di una scheda di rete configurata per l'uso di DHCP, è necessario configurare uno o più indirizzi IP statici per il cluster di failover. Selezionare la casella di controllo accanto a ogni rete da usare per la gestione del cluster. Selezionare il campo Indirizzo accanto a una rete selezionata e quindi immettere l'indirizzo IP da assegnare al cluster. Questo indirizzo (o questi indirizzi) IP verranno associati al nome del cluster in ambito DNS (Domain Name System).
- Al termine, selezionare Avanti.
- Nella pagina Conferma esaminare le impostazioni. Per impostazione predefinita, è selezionata la casella di controllo Aggiungi tutte le risorse di archiviazione idonee al cluster. Deselezionarla se si intende procedere in uno dei modi seguenti:
- Si vuole configurare l'archiviazione in un secondo tempo.
- Si prevede di creare spazi di archiviazione in cluster tramite la Gestione Cluster di Failover o tramite i cmdlet di Windows PowerShell per il clustering di Failover e non sono stati ancora creati gli spazi di archiviazione nei Servizi di File e Archiviazione. Per altre informazioni, vedere Deploy Clustered Storage Spaces.
- Selezionare Avanti per creare il cluster di failover.
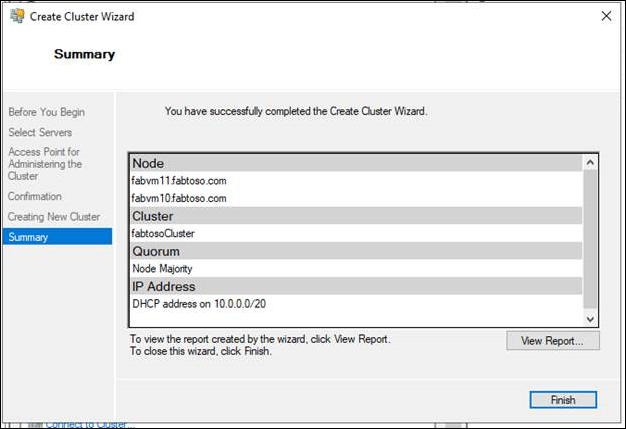
- Nella pagina Riepilogo verificare che il cluster di failover sia stato creato correttamente. Se si sono verificati avvisi o errori, visualizzare l'output di riepilogo o selezionare Visualizza report per visualizzare il report completo. Selezionare Fine.
- Per confermare che il cluster sia stato creato, verificare che il nome del cluster sia elencato in Gestione cluster di failover nell'albero di navigazione. È possibile espandere il nome del cluster e quindi selezionare gli elementi in Nodi, Archiviazione o Reti per visualizzare le risorse associate. Tenere presente che il completamento della replica del nome del cluster nel DNS potrebbe richiedere del tempo. Dopo aver completato la registrazione e la replica DNS, se si seleziona Tutti i server in Server Manager, il nome del cluster deve essere elencato come server con stato di gestibilità online.
Abilitare i gruppi di disponibilità AlwaysOn con Gestione configurazione SQL Server
- Connettersi al nodo WSFC (Windows Server Failover Cluster) che ospita l'istanza di SQL Server in cui si desidera abilitare i gruppi di disponibilità AlwaysOn.
- Nel menu Start scegliere Tutti i programmi, Microsoft SQL Server, Strumenti di configurazione e fare clic su Gestione configurazione SQL Server.
- In Gestione configurazione SQL Server fare clic su Servizi SQL Server, fare clic con il pulsante destro del mouse su SQL Server (
<instance name>), dove<instance name>è il nome di un'istanza del server locale per cui si desidera abilitare i gruppi di disponibilità AlwaysOn e fare clic su Proprietà. - Selezionare la scheda Always On High Availability.
- Verifica che il campo Nome del cluster di failover di Windows contenga il nome del cluster di failover locale. Se questo campo è vuoto, l'istanza del server attualmente non supporta i gruppi di disponibilità AlwaysOn. Il computer locale non è un nodo del cluster, il cluster WSFC è stato arrestato o questa edizione di SQL Server non supporta i gruppi di disponibilità Always On.
- Selezionare la casella di controllo Abilita gruppi di disponibilità AlwaysOn e fare clic su OK. Gestione configurazione SQL Server salva la modifica. È quindi necessario riavviare manualmente il servizio SQL Server. In questo modo è possibile scegliere un'ora per il riavvio che meglio soddisfa le esigenze aziendali. Quando il servizio SQL Server viene riavviato, Always On verrà abilitato e la proprietà del server IsHadrEnabled verrà impostata su 1.

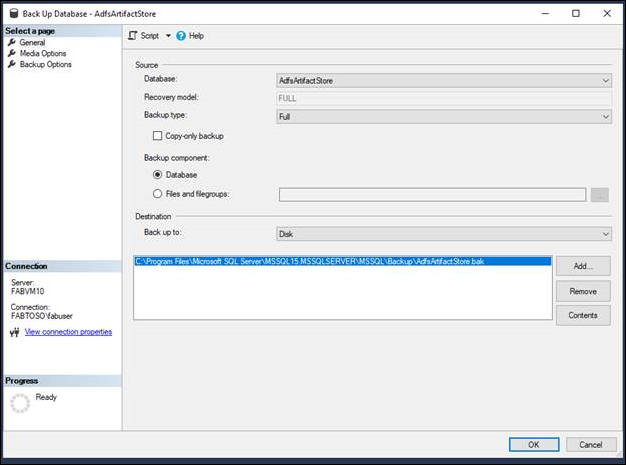
Eseguire il backup di database AD FS
Eseguire il backup della configurazione di AD FS e dei database degli artefatti con i log delle transazioni completi. Posizionare il backup nella destinazione scelta. Eseguire il backup dei database Artefatto e Configurazione di AD FS.
- Attività > Backup > completo > Aggiungi al file di backup > ok per la creazione
Creare un nuovo gruppo di disponibilità
- In Esplora oggetti, connettersi all'istanza del server che ospita la replica primaria.
- Espandere il nodo Disponibilità elevata Always On e il nodo Gruppi di disponibilità.
- Per avviare la Creazione guidata Nuovo gruppo di disponibilità, selezionare il comando Nuovo gruppo di disponibilità.
- La prima volta che si esegue questa procedura guidata, viene visualizzata una pagina Introduzione. Per ignorare questa pagina in futuro, è possibile fare clic su Non visualizzare di nuovo questa pagina. Dopo aver letto questa pagina, fare clic su Avanti.
- Nella pagina Specifica opzioni del gruppo di disponibilità, immettere il nome del nuovo gruppo di disponibilità nel campo Nome gruppo di disponibilità. Questo nome deve essere un identificatore di SQL Server valido e univoco nel cluster e nell'intero dominio. La lunghezza massima consentita per il nome del gruppo di disponibilità è 128 caratteri. e
- Successivamente, specificare il tipo di cluster. I tipi di cluster possibili dipendono dalla versione di SQL Server e dal sistema operativo. Scegliere WSFC, ESTERNO o NESSUNO. Per informazioni dettagliate, vedere Specificare il nome del gruppo di disponibilità

- Nella pagina Seleziona database la griglia elenca i database utente nell'istanza del server connesso idonea a diventare i database di disponibilità. Selezionare uno o più dei database elencati per usarli nel nuovo gruppo di disponibilità. Questi database saranno inizialmente i database primari iniziali. Per ogni database elencato, la colonna Dimensioni visualizza le dimensioni del database, se note. La colonna Stato indica se un determinato database soddisfa i prerequisiti per i database di disponibilità. Se i prerequisiti non sono soddisfatti, una breve descrizione dello stato indica il motivo per cui il database non è idoneo; ad esempio, se non usa il modello di recupero completo. Per altre informazioni, fare clic sulla descrizione relativa allo stato. Se si modifica un database per renderlo idoneo, fare clic su Aggiorna per aggiornare la griglia dei database. Se il database contiene una chiave master del database, immettere la password per la chiave master del database nella colonna Password.

8.Nella pagina Specifica repliche specificare e configurare una o più repliche per il nuovo gruppo di disponibilità. Questa pagina contiene quattro schede. La tabella seguente introduce queste schede. Per altre informazioni, vedere l'argomento Specifica repliche (Creazione guidata del Gruppo di Disponibilità: Creazione guidata Aggiunta Replica).
| Tab | Breve descrizione |
|---|---|
| Replicas | Usare questa scheda per specificare ogni istanza di SQL Server che ospiterà una replica secondaria. Si noti che l'istanza del server a cui si è attualmente connessi deve ospitare la replica primaria. |
| Endpoints | Utilizzare questa scheda per verificare eventuali endpoint di mirroring del database esistenti e anche se questo endpoint non è presente in un'istanza del server i cui account del servizio usano l'autenticazione di Windows, per creare automaticamente l'endpoint. |
| Preferenze di backup | Usare questa scheda per specificare le preferenze di backup per il gruppo di disponibilità nel suo complesso e le priorità di backup per le singole repliche di disponibilità. |
| Listener | Usa questa scheda per creare un listener per il gruppo di disponibilità. Per impostazione predefinita, la procedura guidata non crea un listener. |

- Nella pagina Selezione sincronizzazione dati iniziale scegliere la modalità di creazione e aggiunta dei nuovi database secondari al gruppo di disponibilità. Scegli una delle opzioni seguenti:
- Seeding automatico
- SQL Server crea automaticamente le repliche secondarie per ogni database nel gruppo. Il seeding automatico richiede che il percorso dei dati e del file di log sia lo stesso in ogni istanza di SQL Server inclusa nel gruppo. Disponibile in SQL Server 2016 (13.x) e versioni successive. Vedere Inizializzare automaticamente i gruppi di disponibilità AlwaysOn.
- Backup completo del database e del log
- Selezionare questa opzione se l'ambiente soddisfa i requisiti per l'avvio automatico della sincronizzazione dei dati iniziale . Per altre informazioni, vedere Prerequisiti, restrizioni e raccomandazioni, più indietro in questo argomento. Se si seleziona Full, dopo aver creato il gruppo di disponibilità, la procedura guidata eseguirà il backup di ogni database primario e del relativo log delle transazioni su una condivisione di rete e ripristinerà i backup in ogni istanza del server che ospita una replica secondaria. Ogni database secondario verrà quindi aggiunto al gruppo di disponibilità. Nel campo Specificare un percorso di rete condiviso accessibile da tutte le repliche: specificare una condivisione di backup in cui tutte le istanze del server che ospitano le repliche hanno accesso in lettura/scrittura. Per altre informazioni, vedere Prerequisiti, in precedenza in questo argomento. Nel passaggio di convalida la procedura guidata esegue un test per verificare che la posizione di rete sia valida e il test crea nella replica primaria un database "BackupLocDb_" seguito da un GUID, quindi esegue il backup nella posizione di rete specificata e quindi il ripristino nelle repliche secondarie. È possibile eliminare questo database insieme alla cronologia di backup e al file di backup nel caso in cui la procedura guidata non sia riuscita a eliminarli.
- Solo join
- Se sono stati preparati manualmente database secondari sulle istanze del server che ospiteranno le repliche secondarie, è possibile selezionare questa opzione. Tramite la procedura guidata, i database secondari esistenti verranno uniti al gruppo di disponibilità.
- Ignorare la sincronizzazione iniziale dei dati
- Selezionare questa opzione se si desidera utilizzare i propri backup del database e del log dei database primari. Per altre informazioni, vedere Avviare lo spostamento dati su un database secondario Always On (SQL Server).

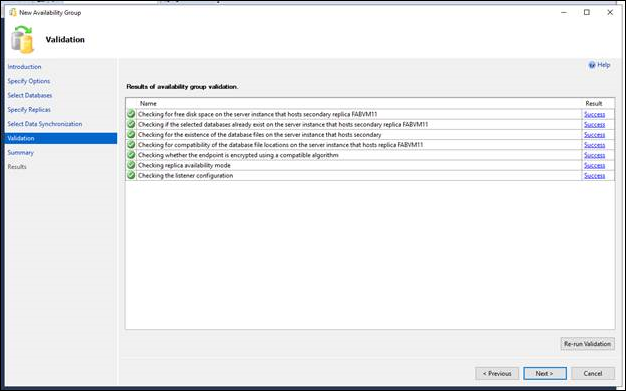
La pagina Convalida verifica se i valori specificati in questa procedura guidata soddisfano i requisiti della Procedura guidata per il nuovo gruppo di disponibilità. Per apportare una modifica, fare clic su Indietro per tornare a una pagina precedente della procedura guidata per modificare uno o più valori. Fare clic su Avanti per tornare alla pagina Convalida e fare clic su Esegui di nuovo convalida.
Nella pagina Riepilogo esaminare le opzioni disponibili per il nuovo gruppo di disponibilità. Per apportare una modifica, fare clic su Indietro per tornare alla pagina pertinente. Dopo aver apportato la modifica, fare clic su Avanti per tornare alla pagina Riepilogo.
Note
Quando l'account di servizio di SQL Server di un'istanza del server che ospiterà una nuova replica di disponibilità non esiste già come login, la Creazione guidata del gruppo di disponibilità deve creare il login. Nella pagina Riepilogo, la procedura guidata visualizza le informazioni relative al login da creare. Se si fa clic su Fine, la procedura guidata crea questo account di accesso per l'account del servizio SQL Server e concede l'autorizzazione login CONNECT. Se si è soddisfatti delle selezioni, facoltativamente fare clic su Script per creare uno script dei passaggi che verranno eseguiti dalla procedura guidata. Quindi, per creare e configurare il nuovo gruppo di disponibilità, fare clic su Fine.
- La pagina Stato visualizza lo stato di avanzamento dei passaggi per la creazione del gruppo di disponibilità (configurazione degli endpoint, creazione del gruppo di disponibilità e aggiunta della replica secondaria al gruppo).
- Al termine di questi passaggi, nella pagina Risultati viene visualizzato il risultato di ogni passaggio. Se tutti questi passaggi sono stati eseguiti correttamente, il nuovo gruppo di disponibilità è completamente configurato. Se si verifica un errore durante uno dei passaggi, potrebbe essere necessario completare manualmente la configurazione o usare una procedura dettagliata per il passaggio errato. Per informazioni sulla causa di un determinato errore, fare clic sul collegamento "Errore" associato nella colonna Risultato. Al termine della procedura guidata, fare clic su Chiudi per uscire.
Aggiungere database nel nodo secondario
Ripristinare il database degli artefatti tramite l'interfaccia utente nel nodo secondario usando i file di backup creati.

Ripristina il database in uno stato NON-RECOVERY.

Ripetere il processo per ripristinare il database di configurazione.
Aggiungere una replica di disponibilità a un gruppo di disponibilità
- In Esplora oggetti, connettersi all'istanza del server che ospita la replica secondaria e fare clic sul nome del server per espandere l'albero del server.
- Espandere il nodo Disponibilità elevata Always On e il nodo Gruppi di disponibilità.
- Selezionare il gruppo di disponibilità della replica secondaria a cui si è connessi.
- Fare clic con il pulsante destro del mouse sulla replica secondaria e scegliere Aggiungi al gruppo di disponibilità.
- Verrà visualizzata la finestra di dialogo "Join Replica to Availability Group".
- Per aggiungere la replica secondaria al gruppo di disponibilità, fare clic su OK.

Aggiornare la stringa di connessione SQL
Usare infine PowerShell per modificare le proprietà di AD FS per aggiornare la stringa di connessione SQL per usare l'indirizzo DNS del listener del gruppo di disponibilità AlwaysOn. Eseguire la modifica del database di configurazione in ogni nodo e riavviare il servizio AD FS in tutti i nodi AD FS. Il valore del catalogo iniziale cambia in base alla versione della farm.
PS:\>$temp= Get-WmiObject -namespace root/ADFS -class SecurityTokenService
PS:\>$temp.ConfigurationdatabaseConnectionstring=”data source=<SQLCluster\SQLInstance>; initial catalog=adfsconfiguration;integrated security=true”
PS:\>$temp.put()
PS:\> Set-AdfsProperties –artifactdbconnection ”Data source=<SQLCluster\SQLInstance >;Initial Catalog=AdfsArtifactStore;Integrated Security=True”