Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2016 (13.x) e versioni successive
SQL Server 2016 (13.x) e versioni successive
Questa esercitazione descrive come usare il servizio Archiviazione BLOB di Azure per i file di dati e i backup di SQL Server 2016 e versioni successive.
Il supporto per l'archiviazione BLOB di Azure in SQL Server è stato introdotto in SQL Server 2012 (11.x) Service Pack 1 CU2 e migliorato nelle versioni successive. Per una panoramica delle funzionalità e dei vantaggi dell'uso di questa funzionalità, vedere File di dati di SQL Server in Microsoft Azure.
Questa esercitazione illustra come usare i file di dati di SQL Server in Archiviazione BLOB di Azure in più sezioni. Ogni sezione è incentrata su un'attività specifica ed è necessario completare le sezioni in sequenza. In primo luogo, si apprenderà come creare un nuovo contenitore in Archiviazione BLOB con criteri di accesso archiviati e una firma di accesso condiviso. Si apprenderà quindi come creare credenziali di SQL Server per integrare SQL Server con Archiviazione BLOB di Azure. Eseguire quindi il backup di un database in Archiviazione BLOB e ripristinarlo in una macchina virtuale di Azure. Si usa quindi il backup del log delle transazioni di snapshot di file di SQL Server per eseguire il ripristino in un momento specifico e in un nuovo database. Infine, l'esercitazione illustra l'uso di stored procedure e funzioni del sistema di metadati per comprendere e usare i backup di snapshot di file.
Prerequisiti
Per completare l'esercitazione è necessario conoscere i concetti di backup e ripristino di SQL Server e la sintassi T-SQL.
Per usare questa esercitazione, sono necessari un account di archiviazione di Azure, SQL Server Management Studio (SSMS), l'accesso a un'istanza di SQL Server locale, l'accesso a una macchina virtuale di Azure che esegue SQL Server 2016 e un database AdventureWorks2022. Inoltre, l'account usato per eseguire i BACKUP comandi e RESTORE deve trovarsi nel ruolo del database db_backupoperator con modificare le autorizzazioni delle credenziali .
- Ottenere un account Azure gratuito.
- Creare un account di archiviazione di Azure.
- Installare SQL Server 2017 Developer Edition.
- Effettuare il provisioning di una macchina virtuale di Azure che esegue SQL Server.
- Installare SQL Server Management Studio.
- Scarica i database di esempio AdventureWorks .
- Assegnare l'account utente al ruolo db_backupoperator e concedere le autorizzazioni Modifica qualsiasi credenziale.
Importante
SQL Server non supporta Azure Data Lake Storage. Assicurarsi che lo spazio dei nomi gerarchico non sia abilitato nell'account di archiviazione usato per questa esercitazione.
1: Creare criteri di accesso archiviati e l'archivio di accesso condiviso
In questa sezione si usa uno script di Azure PowerShell per creare una firma di accesso condiviso in un contenitore di Archiviazione BLOB di Azure usando un criterio di accesso archiviato.
Annotazioni
Questo script è stato scritto con Azure PowerShell 5.0.10586.
Una firma di accesso condivisa è un URI che concede diritti di accesso limitati a contenitori, blob, code o tabelle. Un criterio di accesso archiviato offre un livello aggiuntivo di controllo sulle firme di accesso condiviso sul lato server, tra cui revoca, scadenza o estensione dell'accesso. Per usare questi nuovi miglioramenti, è necessario creare in un contenitore criteri con almeno diritti di lettura, scrittura ed elenco.
È possibile creare criteri di accesso archiviati e una firma di accesso condiviso usando Azure PowerShell, Azure Storage SDK, l'API REST di Azure o un'utilità di terze parti. Questa esercitazione illustra come usare uno script Azure PowerShell per completare questa attività. Lo script usa il modello di distribuzione Resource Manager e crea le nuove risorse seguenti
- Gruppo di risorse
- Account di archiviazione
- Container di Azure Blob Storage
- Politica di accesso condiviso SAS
Questo script inizia dichiarando diverse variabili per specificare i nomi per le risorse precedenti e i nomi dei valori di input necessari seguenti:
- Nome di prefisso usato nei nomi di altri oggetti risorsa
- Nome della sottoscrizione
- Ubicazione data center
Lo script viene completato generando l'istruzione appropriata CREATE CREDENTIALusata in 2 - Creare credenziali di SQL Server usando una firma di accesso condiviso. Questa dichiarazione viene copiata automaticamente negli Appunti per te e viene visualizzata nella console per consentirti di vederla.
Per creare i criteri per il contenitore e generare una chiave di firma di accesso condiviso (SAS), seguire questa procedura:
Aprire Windows PowerShell o Windows PowerShell ISE (vedere i requisiti della versione precedente).
Modificare e quindi eseguire lo script seguente:
# Define global variables for the script $prefixName = '<a prefix name>' # used as the prefix for the name for various objects $subscriptionID = '<your subscription ID>' # the ID of subscription name you will use $locationName = '<a data center location>' # the data center region you will use $storageAccountName = $prefixName + 'storage' # the storage account name you will create or use $containerName = $prefixName + 'container' # the storage container name to which you will attach the SAS policy with its SAS token $policyName = $prefixName + 'policy' # the name of the SAS policy # Set a variable for the name of the resource group you will create or use $resourceGroupName = $prefixName + 'rg' # Add an authenticated Azure account for use in the session Connect-AzAccount # Set the tenant, subscription and environment for use in the rest of Set-AzContext -SubscriptionId $subscriptionID # Create a new resource group - comment out this line to use an existing resource group New-AzResourceGroup -Name $resourceGroupName -Location $locationName # Create a new Azure Resource Manager storage account - comment out this line to use an existing Azure Resource Manager storage account New-AzStorageAccount -Name $storageAccountName -ResourceGroupName $resourceGroupName -Type Standard_RAGRS -Location $locationName # Get the access keys for the Azure Resource Manager storage account $accountKeys = Get-AzStorageAccountKey -ResourceGroupName $resourceGroupName -Name $storageAccountName # Create a new storage account context using an Azure Resource Manager storage account $storageContext = New-AzStorageContext -StorageAccountName $storageAccountName -StorageAccountKey $accountKeys[0].Value # Creates a new container in Blob Storage $container = New-AzStorageContainer -Context $storageContext -Name $containerName # Sets up a Stored Access Policy and a Shared Access Signature for the new container $policy = New-AzStorageContainerStoredAccessPolicy -Container $containerName -Policy $policyName -Context $storageContext -StartTime $(Get-Date). ToUniversalTime().AddMinutes(-5) -ExpiryTime $(Get-Date).ToUniversalTime().AddYears(10) -Permission rwld # Gets the Shared Access Signature for the policy $sas = New-AzStorageContainerSASToken -name $containerName -Policy $policyName -Context $storageContext Write-Host 'Shared Access Signature= '$($sas.Substring(1))'' # Sets the variables for the new container you just created $container = Get-AzStorageContainer -Context $storageContext -Name $containerName $cbc = $container.CloudBlobContainer # Outputs the Transact SQL to the clipboard and to the screen to create the credential using the Shared Access Signature Write-Host 'Credential T-SQL' $tSql = "CREATE CREDENTIAL [{0}] WITH IDENTITY='Shared Access Signature', SECRET='{1}'" -f $cbc.Uri, $sas.Substring(1) $tSql | clip Write-Host $tSql # Once you're done with the tutorial, remove the resource group to clean up the resources. # Remove-AzResourceGroup -Name $resourceGroupNameAl termine dello script, l'istruzione
CREATE CREDENTIALsi trova negli Appunti da usare nella sezione successiva.
2: Creare credenziali di SQL Server usando una firma di accesso condiviso
In questa sezione viene creata una credenziale per archiviare le informazioni di sicurezza, usate da SQL Server per scrivere e leggere dal contenitore di Archiviazione BLOB di Azure creato nel passaggio precedente.
Una credenziale di SQL Server è un oggetto utilizzato per archiviare le informazioni di autenticazione necessarie per connettersi a una risorsa all'esterno di SQL Server. Nelle credenziali vengono archiviati il percorso URI del contenitore di archiviazione BLOB di Azure e la firma di accesso condiviso per questo contenitore.
Per creare credenziali di SQL Server, seguire questa procedura:
Avviare SSMS.
Aprire una nuova finestra di query e connettersi all'istanza di SQL Server del motore di database nell'ambiente locale.
Nella nuova finestra di query incollare l'istruzione
CREATE CREDENTIALcon la firma di accesso condiviso della sezione 1 ed eseguire tale script.Lo script è simile al codice seguente.
/* Example: USE master CREATE CREDENTIAL [https://msfttutorial.blob.core.windows.net/containername] WITH IDENTITY='SHARED ACCESS SIGNATURE' , SECRET = 'sharedaccesssignature' GO */ USE master; CREATE CREDENTIAL [https://<storage-account>.blob.core.windows.net/<container-name>] -- this name must match the container path, start with https and must not contain a forward slash at the end WITH IDENTITY = 'SHARED ACCESS SIGNATURE', -- this is a mandatory string and should not be changed SECRET = 'sharedaccesssignature'; -- this is the shared access signature key that you obtained in section 1. GOPer visualizzare tutte le credenziali disponibili, è possibile eseguire l'istruzione seguente nella finestra di query collegata all'istanza:
SELECT * FROM sys.credentials;Aprire una nuova finestra di query e connettersi all'istanza di SQL Server del motore di database nella macchina virtuale di Azure.
Nella nuova finestra di query incollare l'istruzione
CREATE CREDENTIALcon la firma di accesso condiviso della sezione 1 ed eseguire tale script.Ripetere i passaggi 5 e 6 per tutte le istanze di SQL Server aggiuntive che devono avere accesso al contenitore.
3: Backup del database su URL
In questa sezione viene eseguito il backup del database nell'istanza AdventureWorks2022 di SQL Server nel contenitore creato nella sezione 1.
Per eseguire il backup di un database nell'archiviazione BLOB, seguire questi passaggi:
Avviare SSMS.
Aprire una nuova finestra della query e connettersi all'istanza di SQL Server nella macchina virtuale di Azure.
Copiare e incollare lo script Transact-SQL seguente nella finestra della query. Modificare l'URL in modo appropriato per il nome di account di archiviazione e il contenitore specificato nella sezione 1 e quindi eseguire questo script.
-- To permit log backups, before the full database backup, modify the database to use the full recovery model. USE master; ALTER DATABASE AdventureWorks2022 SET RECOVERY FULL; -- Back up the full AdventureWorks2022 database to the container that you created in section 1 BACKUP DATABASE AdventureWorks2022 TO URL = 'https://<storage-account>.blob.core.windows.net/<container-name>/AdventureWorks2022_onprem.bak';Apri l'Esplora oggetti e connettiti all'archiviazione di Azure usando il tuo account di archiviazione e la tua chiave dell'account.
- Espandere Contenitori, espandere il contenitore creato nella sezione 1 e verificare che il backup del passaggio 3 sia visualizzato in precedenza in questo contenitore.
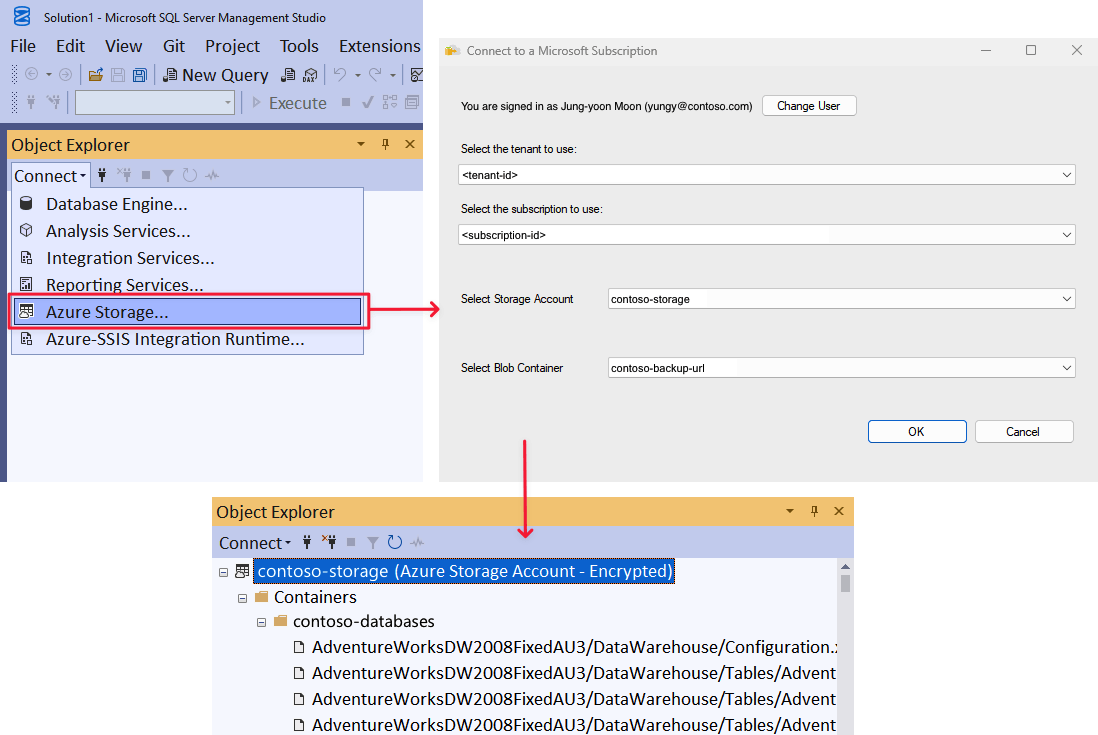

4: Ripristinare il database in una macchina virtuale da un URL
In questa sezione si ripristina il database nell'istanza AdventureWorks2022 di SQL Server nella macchina virtuale di Azure.
Annotazioni
Ai fini della semplicità in questa esercitazione, viene usato lo stesso contenitore per i file di dati e di log usati per il backup del database. In un ambiente di produzione probabilmente si usano più contenitori e spesso anche più file di dati. Si potrebbe anche considerare lo striping del backup su più BLOB per migliorare nelle prestazioni del backup quando si esegue il backup di un grande database.
Per ripristinare il database AdventureWorks2022dall'archiviazione BLOB di Azure nell'istanza di SQL Server nella macchina virtuale di Azure, seguire questi passaggi:
Avviare SSMS.
Aprire una nuova finestra di query e connettersi all'istanza di SQL Server del motore di database nella macchina virtuale di Azure.
Copiare e incollare lo script Transact-SQL seguente nella finestra della query. Modificare l'URL in modo appropriato per il nome di account di archiviazione e il contenitore specificato nella sezione 1 e quindi eseguire questo script.
-- Restore AdventureWorks2022 from URL to SQL Server instance using Azure Blob Storage for database files RESTORE DATABASE AdventureWorks2022 FROM URL = 'https://<storage-account>.blob.core.windows.net/<container-name>/AdventureWorks2022_onprem.bak' WITH MOVE 'AdventureWorks2022_data' TO 'https://<storage-account>.blob.core.windows.net/<container-name>/AdventureWorks2022_Data.mdf', MOVE 'AdventureWorks2022_log' TO 'https://<storage-account>.blob.core.windows.net/<container-name>/AdventureWorks2022_Log.ldf' --, REPLACE;Apri Object Explorer e connettiti all'istanza di SQL Server di Azure.
In Esplora oggetti espandere il nodo Database e verificare che il
AdventureWorks2022database sia stato ripristinato (aggiornare il nodo in base alle esigenze).Fare clic con il pulsante destro del mouse su AdventureWorks2022 e scegliere Proprietà.
Selezionare File e verificare che i percorsi dei due file di database siano URL che puntano ai BLOB nel contenitore BLOB di Azure. Al termine, selezionare Annulla.
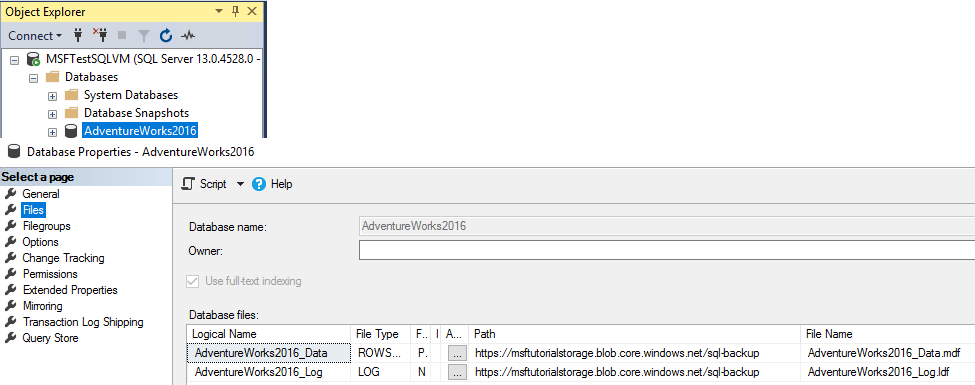
In Esplora oggetti, connettersi all'archiviazione di Azure.
- Espandere Contenitori, espandere il contenitore creato nella sezione 1 e verificare che e
AdventureWorks2022_Data.mdfAdventureWorks2022_Log.ldfnel passaggio 3 sia visualizzato in precedenza in questo contenitore, insieme al file di backup della sezione 3 (aggiornare il nodo in base alle esigenze).

- Espandere Contenitori, espandere il contenitore creato nella sezione 1 e verificare che e

5 - Eseguire il backup del database utilizzando il file-snapshot backup
In questa sezione viene eseguito il backup del AdventureWorks2022 database nella macchina virtuale di Azure usando il backup di snapshot di file per eseguire un backup quasi istantaneo usando gli snapshot di Azure. Per ulteriori informazioni sui backup snapshot di file, vedere Backup di snapshot di file per i file di database in Azure
Per eseguire il backup del database AdventureWorks2022 usando un backup di snapshot, eseguire queste operazioni:
Avviare SSMS.
Aprire una nuova finestra di query e connettersi all'istanza di SQL Server del motore di database nella macchina virtuale di Azure.
Copiare, incollare ed eseguire lo script di Transact-SQL seguente nella finestra di query (non chiudere questa finestra di query. Questo script viene eseguito di nuovo nel passaggio 5). Questa stored procedure di sistema consente di visualizzare i backup degli snapshot esistenti per ogni file che fa parte di un database specificato. È possibile notare che non sono presenti backup di snapshot di file per questo database.
-- Verify that no file snapshot backups exist SELECT * FROM sys.fn_db_backup_file_snapshots('AdventureWorks2022');Copiare e incollare lo script Transact-SQL seguente nella finestra della query. Modificare l'URL in modo appropriato per il nome di account di archiviazione e il contenitore specificato nella sezione 1 e quindi eseguire questo script. Si noti la rapidità con cui viene eseguito il backup.
-- Backup the AdventureWorks2022 database with FILE_SNAPSHOT BACKUP DATABASE AdventureWorks2022 TO URL = 'https://<storage-account>.blob.core.windows.net/<container-name>/AdventureWorks2022_Azure.bak' WITH FILE_SNAPSHOT;Dopo aver verificato che lo script del passaggio 4 è stato eseguito correttamente, eseguire di nuovo lo script seguente. L'operazione di backup dello snapshot di file nel passaggio 4 ha generato snapshot di file sia del file di dati che del file di log.
-- Verify that two file-snapshot backups exist SELECT * FROM sys.fn_db_backup_file_snapshots('AdventureWorks2022');
In Esplora oggetti, nell'istanza di SQL Server nella tua macchina virtuale di Azure, espandere il nodo Database e verificare che il database
AdventureWorks2022sia stato ripristinato in questa istanza (aggiornare il nodo se necessario).In Esplora oggetti, connettersi all'archiviazione di Azure.
Espandere Contenitori, espandere il contenitore creato nella sezione 1 e verificare che il
AdventureWorks2022_Azure.bakpassaggio 4 precedente venga visualizzato in questo contenitore, insieme al file di backup della sezione 3 e ai file di database della sezione 4 (aggiornare il nodo in base alle esigenze).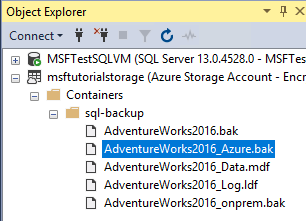

6 - Generare il registro delle attività e il backup utilizzando snapshot di file
In questa sezione viene generata l'attività AdventureWorks2022 nel database e vengono creati periodicamente backup del log delle transazioni usando backup di snapshot di file. Per ulteriori informazioni sull'utilizzo dei backup snapshot, vedere Backup snapshot per i file di database in Azure.
Per generare un'attività nel database AdventureWorks2022 e creare periodicamente backup del log delle transazioni tramite backup di snapshot di file, seguire questa procedura:
Avviare SSMS.
Aprire due nuove finestra di query e connettere ogni finestra all'istanza di SQL Server del motore di database nella macchina virtuale di Azure.
Copiare, incollare ed eseguire lo script Transact-SQL seguente in una delle finestre di query. La
Production.Locationtabella contiene 14 righe prima di aggiungere nuove righe nel passaggio 4.-- Verify row count at start SELECT COUNT(*) FROM AdventureWorks2022.Production.Location;Copiare e incollare gli script Transact-SQL seguenti nelle due diverse finestre di query. Modificare l'URL in modo appropriato per il nome di account di archiviazione e il contenitore specificato nella sezione 1 ed eseguire questi script contemporaneamente in due finestre di query distinte. Il completamento di questi script richiede alcuni minuti.
-- Insert 30,000 new rows into the Production.Location table in the AdventureWorks2022 database in batches of 75 DECLARE @count AS INT = 1, @inner AS INT; WHILE @count < 400 BEGIN BEGIN TRANSACTION; SET @inner = 1; WHILE @inner <= 75 BEGIN INSERT INTO AdventureWorks2022.Production.Location (Name, CostRate, Availability, ModifiedDate) VALUES (NEWID(), .5, 5.2, GETDATE()); SET @inner = @inner + 1; END COMMIT TRANSACTION; WAITFOR DELAY '00:00:01'; SET @count = @count + 1; END SELECT COUNT(*) FROM AdventureWorks2022.Production.Location;--take 7 transaction log backups with FILE_SNAPSHOT, one per minute, and include the row count and the execution time in the backup file name DECLARE @count INT=1, @device NVARCHAR(120), @numrows INT; WHILE @count <= 7 BEGIN SET @numrows = (SELECT COUNT (*) FROM AdventureWorks2022.Production.Location); SET @device = 'https://<storage-account>.blob.core.windows.net/<container-name>/tutorial-' + CONVERT (varchar(10),@numrows) + '-' + FORMAT(GETDATE(), 'yyyyMMddHHmmss') + '.bak'; BACKUP LOG AdventureWorks2022 TO URL = @device WITH FILE_SNAPSHOT; SELECT * from sys.fn_db_backup_file_snapshots ('AdventureWorks2022'); WAITFOR DELAY '00:1:00'; SET @count = @count + 1; END;Esaminare l'output del primo script. Si noti che il numero di righe finale è ora 29.939.
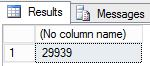
Esaminare l'output del secondo script e notare che ogni volta che viene eseguita l'istruzione
BACKUP LOGche vengono creati due nuovi snapshot di file, uno snapshot di file del file di log e uno snapshot del file di dati, per un totale di due snapshot di file per ogni file di database. Al termine del secondo script, si noti che sono ora presenti un totale di 16 snapshot di file, 8 per ogni file di database, uno dall'istruzioneBACKUP DATABASEe uno per ogni esecuzione dell'istruzioneBACKUP LOG.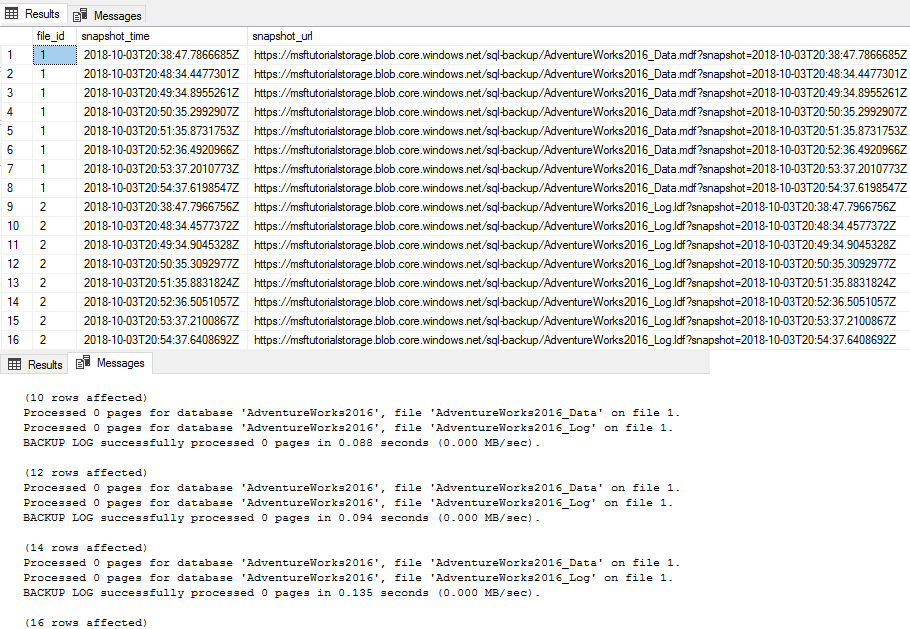
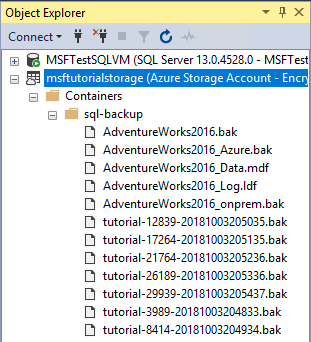
In Esplora oggetti, connettersi all'archiviazione di Azure.
Espandere Contenitori, espandere il contenitore creato nella sezione 1, verificare che i sette nuovi file di backup siano visualizzati con i file di dati delle sezioni precedenti. Se necessario aggiornare il nodo.

7: Ripristinare un database fino a un momento specifico
In questa sezione si ripristina il AdventureWorks2022 database a un punto nel tempo tra due dei backup del log delle transazioni.
Con i backup tradizionali, per eseguire il ripristino temporizzato, è necessario usare il backup completo del database, ad esempio un backup differenziale, e tutti i file di log delle transazioni fino a e subito dopo il momento in base al quale si esegue il ripristino. Per i backup di snapshot di file, sono necessari solo i due file di backup del log che delimitano il periodo di tempo a cui si desidera ripristinare. Sono necessari solo due set di backup snapshot dei file di log poiché ogni backup del log crea uno snapshot di ogni file del database (file di dati e log).
Per ripristinare un database a un punto specifico nel tempo dai set di backup dei file snapshot, seguire i seguenti passaggi:
Avviare SSMS.
Aprire una nuova finestra di query e connettersi all'istanza di SQL Server del motore di database nella macchina virtuale di Azure.
Copiare, incollare ed eseguire lo script Transact-SQL seguente nella finestra della query. Verificare che la tabella
Production.Locationcontenga 29.939 righe prima di ripristinarla a un momento precedente in cui, nel passaggio 4, sono presenti meno righe.-- Verify row count at start SELECT COUNT(*) FROM AdventureWorks2022.Production.Location;
Copiare e incollare lo script Transact-SQL seguente nella finestra della query. Selezionare due file di backup del log adiacenti e convertire il nome del file nella data e ora necessarie per questo script. Modificare l'URL in modo appropriato per il nome dell'account di archiviazione e il contenitore specificato nella sezione 1. Specificare il primo e il secondo nome di file di
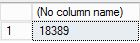
June 26, 2018 01:48 PMbackup, specificare l'oraSTOPATnel formato , quindi eseguire questo script. operazione il cui completamento richiede alcuni minuti.-- restore and recover to a point in time between the times of two transaction log backups, and then verify the row count ALTER DATABASE AdventureWorks2022 SET SINGLE_USER WITH ROLLBACK IMMEDIATE; RESTORE DATABASE AdventureWorks2022 FROM URL = 'https://<storage-account>.blob.core.windows.net/<container-name>/<firstbackupfile>.bak' WITH NORECOVERY, REPLACE; RESTORE LOG AdventureWorks2022 FROM URL = 'https://<storage-account>.blob.core.windows.net/<container-name>/<secondbackupfile>.bak' WITH RECOVERY, STOPAT = 'June 26, 2018 01:48 PM'; ALTER DATABASE AdventureWorks2022 SET MULTI_USER; -- get new count SELECT COUNT(*) FROM AdventureWorks2022.Production.Location;Esaminare l'output. Dopo il ripristino il numero di righe è 18.389, ovvero un numero di conteggio delle righe compreso tra il backup del log 5 e 6 (il numero di righe può variare).
8: Ripristinare come nuovo database dal backup del log
In questa sezione si ripristina il AdventureWorks2022 database come nuovo database da un backup del log delle transazioni di snapshot di file.
In questo scenario si esegue un ripristino in un'istanza di SQL Server in una macchina virtuale diversa ai fini dell'analisi aziendale e della creazione di report. Il ripristino su un'altra istanza su una macchina virtuale diversa trasferisce il carico di lavoro a una macchina virtuale dedicata e dimensionata per questo scopo, rimuovendo le sue richieste di risorse dal sistema transazionale.
Il ripristino da un backup del log delle transazioni con il backup di snapshot di file è molto più rapido rispetto ai backup di streaming tradizionali. Con i backup di streaming tradizionali, è necessario usare il backup completo del database, ad esempio un backup differenziale e alcuni o tutti i backup del log delle transazioni (o un nuovo backup completo del database). Con i backup del log dello snapshot di file, invece, è necessario solo il backup del log più recente oppure qualsiasi altro backup del log o due backup del log adiacenti per il ripristino temporizzato in un momento tra due orari di backup del log. Per maggiore chiarezza, è necessario un solo set di backup di snapshot di file di log poiché ogni backup del log di snapshot di file crea uno snapshot di ogni file del database (file di dati e file di log).
Per ripristinare un database in un nuovo database da un backup del log delle transazioni usando il backup di snapshot di file, eseguire i passaggi seguenti:
Avviare SSMS.
Aprire una nuova finestra della query e connettersi all'istanza di SQL Server del motore di database in una macchina virtuale di Azure.
Se si tratta di una macchina virtuale di Azure diversa da quella usata per le sezioni precedenti, assicurarsi di aver eseguito i passaggi descritti in 2: Creare una credenziale di SQL Server usando una firma di accesso condiviso. Per eseguire il ripristino in un contenitore diverso, seguire i passaggi descritti in 1: Creare criteri di accesso archiviati e l'archivio di accesso condiviso per il nuovo contenitore.
Copiare e incollare lo script Transact-SQL seguente nella finestra della query. Selezionare il file di backup del log che si vuole usare. Modificare l'URL in modo appropriato per il nome di account di archiviazione e il contenitore specificato nella sezione 1, specificare il nome del file di backup del log e quindi eseguire questo script.
-- restore as a new database from a transaction log backup file RESTORE DATABASE AdventureWorks2022_EOM FROM URL = 'https://<storage-account>.blob.core.windows.net/<container-name>/<logbackupfile.bak>' WITH MOVE 'AdventureWorks2022_data' TO 'https://<storage-account>.blob.core.windows.net/<container-name>/AdventureWorks2022_EOM_Data.mdf', MOVE 'AdventureWorks2022_log' TO 'https://<storage-account>.blob.core.windows.net/<container-name>/AdventureWorks2022_EOM_Log.ldf', RECOVERY --, REPLACE;Rivedere l'output per verificare il completamento del ripristino.
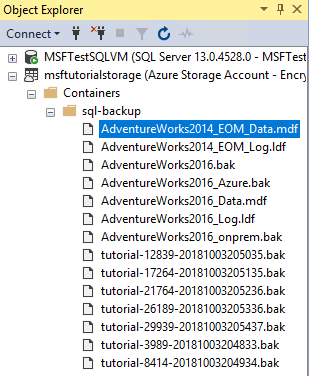
In Esplora oggetti, connettersi all'archiviazione di Azure.
Espandere Contenitori, espandere il contenitore creato nella sezione 1, aggiornare se necessario e verificare che i nuovi file di dati e di log siano visualizzati nel contenitore con i BLOB delle sezioni precedenti.
9: Gestire set di backup e backup di snapshot di file
In questa sezione si elimina un set di backup usando la stored procedure di sistema sp_delete_backup . Questa procedura memorizzata di sistema elimina il file di backup e lo snapshot del file su ogni file di database associato a questo set di backup.
Annotazioni
Se si tenta di eliminare un set di backup eliminando il file di backup dal contenitore di Archiviazione BLOB di Azure, si elimina solo il file di backup stesso. Gli snapshot di file associati rimangono. Se ci si trova in questo scenario, usare la funzione di sistema sys.fn_db_backup_file_snapshots per identificare l'URL degli snapshot dei file orfani e usare la stored procedure di sistema sp_delete_backup_file_snapshot per eliminare ogni snapshot del file orfano. Per ulteriori informazioni, vedere Backup delle istantanee dei file per i file di database in Azure.
Per eliminare un set di backup di snapshot di file, seguire questi passaggi:
Avviare SSMS.
Aprire una nuova finestra della query e connettersi all'istanza di SQL Server del motore di database nella macchina virtuale di Azure (o a qualsiasi istanza di SQL Server con autorizzazioni di lettura e scrittura sul contenitore).
Copiare e incollare lo script Transact-SQL seguente nella finestra della query. Selezionare il backup del log che si vuole eliminare insieme ai relativi snapshot di file associati. Modificare l'URL in modo appropriato per il nome di account di archiviazione e il contenitore specificato nella sezione 1, specificare il nome del file di backup del log e quindi eseguire questo script.
EXECUTE sys.sp_delete_backup 'https://<storage-account>.blob.core.windows.net/<container-name>/tutorial-21764-20181003205236.bak';In Esplora oggetti, connettersi all'archiviazione di Azure.
Espandere Contenitori, espandere il contenitore creato nella sezione 1 e verificare che il file di backup usato nel passaggio 3 non sia più visualizzato in questo contenitore. Aggiornare il nodo se necessario.
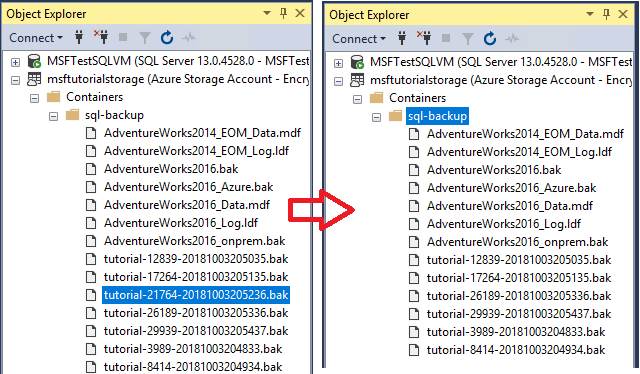
Copiare, incollare ed eseguire lo script Transact-SQL seguente nella finestra della query per verificare che i due snapshot di file siano stati eliminati.
-- verify that two file snapshots have been removed SELECT * FROM sys.fn_db_backup_file_snapshots('AdventureWorks2022');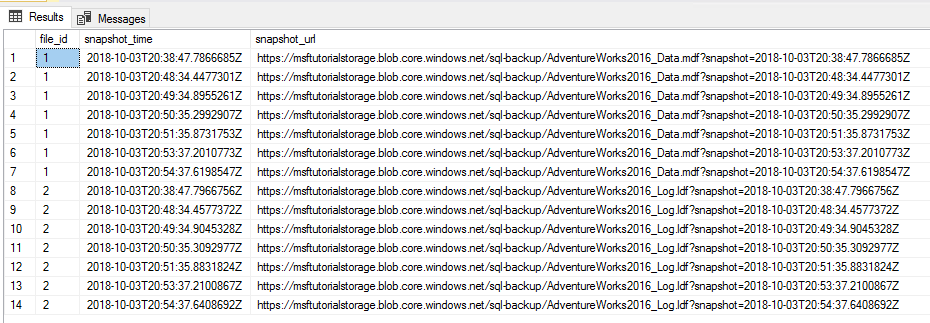

10: Rimuovere le risorse
Dopo aver completato questa esercitazione, per risparmiare risorse, assicurarsi di eliminare il gruppo di risorse creato in questa esercitazione.
Per eliminare il gruppo di risorse, eseguire il codice PowerShell seguente:
# Define global variables for the script
$prefixName = '<prefix name>' # should be the same as the beginning of the tutorial
# Set a variable for the name of the resource group you will create or use
$resourceGroupName=$prefixName + 'rg'
# Adds an authenticated Azure account for use in the session
Connect-AzAccount
# Set the tenant, subscription and environment for use in the rest of
Set-AzContext -SubscriptionId $subscriptionID
# Remove the resource group
Remove-AzResourceGroup -Name $resourceGroupName
Contenuti correlati
- I file di dati di SQL Server in Microsoft Azure
- Backup di snapshot di file per i file di database in Azure
- Backup di SQL Server su URL per Microsoft Azure Blob Storage
- Shared Access Signatures, parte 1: Comprendere il modello SAS
- Creare un contenitore
- Imposta ACL del contenitore
- Ottenere l'ACL del contenitore
- Credenziali (motore di database)
- CREATE CREDENTIAL (Transact-SQL)
- sys.credentials (Transact-SQL)
- sp_delete_backup (Transact-SQL)
- sys.fn_db_backup_file_snapshots (Transact-SQL)
- sp_delete_backup_file_snapshot (Transact-SQL)