Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server![]() Database SQL di Azure
Database SQL di Azure![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure![]() Database SQL in Microsoft Fabric
Database SQL in Microsoft Fabric
SQL Server 2016 (13.x) introduce l'analisi operativa in tempo reale, cioè la possibilità di eseguire contemporaneamente analisi e carichi di lavoro OLTP nelle stesse tabelle di database. Oltre a eseguire analisi in tempo reale, è possibile eliminare la necessità di ETL e di un data warehouse.
Spiegazione dell'analisi operativa in tempo reale
In passato le aziende usavano sistemi separati per i carichi di lavoro operativi, ad esempio OLTP, e per quelli di analisi. Per questi sistemi, i processi di estrazione, trasformazione e caricamento (ETL) spostano regolarmente i dati dall'archivio operativo in un archivio di analisi. I dati di analisi sono vengono in genere archiviati in un data warehouse o data mart dedicato all'esecuzione di query di analisi. Anche se questa soluzione ha rappresentato lo standard, presentava tre problemi principali:
- Complessità. L'implementazione di ETL può richiedere una notevole quantità di codifica, soprattutto per caricare solo le righe modificate. L'identificazione delle righe che sono state modificate può risultare difficile.
- Costo. L'implementazione di ETL richiede il costo di acquisto di licenze software e hardware aggiuntive.
- Latenza dei dati. L'implementazione di ETL aggiunge un ritardo per l'esecuzione delle analisi. Se, ad esempio, il processo ETL viene eseguito al termine di ogni giornata lavorativa, le query di analisi verranno eseguite sui dati che risalgono ad almeno un giorno prima. Per molte aziende questo ritardo è inaccettabile, perché le loro attività dipendono dall'analisi dei dati in tempo reale. Ad esempio, il rilevamento di frodi richiede l'analisi in tempo reale sui dati operativi.
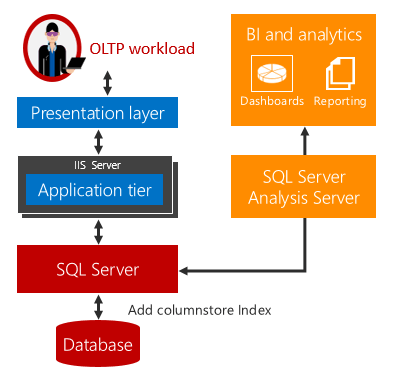
L'analisi operativa in tempo reale offre una soluzione a questi problemi.
Non si verifica alcun ritardo durante l'esecuzione di analisi e carichi di lavoro OLTP nella stessa tabella sottostante. Per gli scenari in cui è possibile usare l'analisi in tempo reale, i costi e la complessità vengono notevolmente ridotti eliminando la necessità di ETL e di acquistare e gestire un data warehouse separato.
Nota
L'analisi operativa in tempo reale è destinata allo scenario di una singola origine dati, ad esempio un'applicazione ERP (Enterprise Resource Planning) in cui è possibile eseguire sia i carichi di lavoro operativi che i carichi di lavoro di analisi. Ciò non sostituisce la necessità di un data warehouse separato quando è necessario integrare dati da più origini prima di eseguire il carico di lavoro di analisi o quando sono necessarie prestazioni delle analisi estremamente elevate usando dati preaggregati, ad esempio cubi.
L'analisi in tempo reale usa un indice non cluster columnstore aggiornabile in una tabella di tipo rowstore. L'indice columnstore gestisce una copia dei dati, quindi i carichi di lavoro OLTP e di analisi vengono eseguiti su copie separate dei dati. In questo modo si riduce al minimo l'impatto sulle prestazioni causato dall'esecuzione contemporanea di entrambi i carichi di lavoro. Il motore di database gestisce automaticamente le modifiche all'indice in modo che le modifiche OLTP siano sempre up-to-date per l'analisi. Con questa progettazione, è possibile e utile eseguire l'analisi in tempo reale su dati aggiornati. Ciò funziona sia per le tabelle basate su disco che per le tabelle ottimizzate per la memoria.
Esempio per iniziare
Per iniziare a usare l'analisi in tempo reale:
Nello schema operativo identificare le tabelle che contengono i dati necessari per l'analisi.
Per ogni tabella eliminare tutti gli indici ad albero B progettati principalmente per velocizzare l'analisi esistente sul carico di lavoro OLTP. Sostituirli con un singolo indice columnstore non clusterizzato. In questo modo è possibile migliorare le prestazioni complessive del carico di lavoro OLTP perché sono presenti meno indici da gestire.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;L'indice columnstore su una tabella ottimizzata per la memoria consente l'analisi operativa integrando le tecnologie In-memory OLTP e columnstore per fornire prestazioni elevate per i carichi di lavoro sia OLTP che di analisi. L'indice columnstore in una tabella ottimizzata per la memoria deve essere l'indice cluster, in altre parole deve includere tutte le colonne.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON );
A questo punto si è pronti per eseguire l'analisi operativa in tempo reale senza apportare modifiche all'applicazione. Le query di analisi verranno eseguite sull'indice columnstore e le operazioni OLTP continueranno a essere eseguite su indici ad albero B OLTP. I carichi di lavoro OLTP continuano a essere eseguiti, ma comportano un sovraccarico aggiuntivo per gestire l'indice columnstore. Vedere le ottimizzazioni delle prestazioni nella sezione successiva.
Post di blog
Leggere i post di blog seguenti per altre informazioni sull'analisi operativa in tempo reale. La lettura preliminare del blog potrebbe semplificare la comprensione delle sezioni relative ai suggerimenti sulle prestazioni.
Uso di un indice columnstore non cluster per l'analisi operativa in tempo reale
Un semplice esempio di uso di un indice columnstore non clusterizzato
Analisi operativa in tempo reale con tabelle ottimizzate per la memoria
Video
La serie video Data Exposed (Dati esposti) illustra in dettaglio alcune delle funzionalità e delle considerazioni.
- Parte 1: Come Azure SQL abilita l'analisi operativa in tempo reale (HTAP)
- Parte 2: Ottimizzare i database e le applicazioni esistenti con l'analisi operativa
- Parte 3: Come creare analitiche operative con le funzioni finestra.
Suggerimento per le prestazioni n. 1: usare indici filtrati per migliorare le prestazioni delle query
L'esecuzione dell'analisi operativa in tempo reale può compromettere le prestazioni del carico di lavoro OLTP. Tale impatto dovrebbe essere minimo. Esempio A illustra come usare gli indici filtrati per ridurre al minimo l'impatto dell'indice columnstore non cluster sul carico di lavoro transazionale, pur offrendo analisi in tempo reale.
Per ridurre al minimo l'overhead di gestione di un indice columnstore non clusterizzato in un carico di lavoro operativo, è possibile utilizzare una condizione filtrata per creare un indice columnstore non clusterizzato solo sui dati warm o a modifica lenta. Ad esempio, in un'applicazione di gestione degli ordini, è possibile creare un indice "columnstore" non clusterizzato sugli ordini che sono già stati spediti. Dopo la spedizione, l'ordine cambia raramente e pertanto i dati possono essere considerati stabili. Con un indice filtrato, i dati nell'indice columnstore non cluster richiedono meno aggiornamenti riducendo così l'impatto sul carico di lavoro transazionale.
Le query analitiche accedono in modo trasparente sia ai dati caldi che a quelli tiepidi, secondo necessità, per fornire analisi in tempo reale. Se una parte significativa del carico di lavoro operativo riguarda i dati "ad accesso frequente", tali operazioni non richiedono una manutenzione aggiuntiva dell'indice columnstore. Una procedura consigliata prevede la creazione di un indice cluster rowstore per le colonne usate nella definizione dell'indice filtrato. Il motore di database usa l'indice cluster per analizzare rapidamente le righe che non soddisfano la condizione filtrata. Senza questo indice cluster, per trovare queste righe è necessaria un'analisi completa della tabella rowstore, che può influire negativamente sulle prestazioni delle query analitiche. In assenza di un indice cluster si potrebbe creare un indice ad albero B non cluster filtrato complementare per identificare le righe, ma questa scelta non è consigliabile perché l'accesso a un ampio intervallo di righe usando indici ad albero B non cluster comporta costi elevati.
Nota
Un indice columnstore filtrato non raggruppato è supportato solo nelle tabelle basate su disco. Non è supportato nelle tabelle ottimizzate per la memoria.
Esempio A: accesso a dati caldi dall'indice B-tree e a dati tiepidi dall'indice columnstore
In questo esempio viene utilizzata una condizione filtrata (accountkey > 0) per stabilire quali righe sono incluse nell'indice columnstore. L'obiettivo è di progettare la condizione di filtraggio e le query successive per accedere ai dati "caldi", caratterizzati da modifiche frequenti, dall'indice B+ tree e di accedere ai dati più stabili dall'indice columnstore.

Nota
Query Optimizer considera, ma non sempre sceglie, l'indice columnstore per il piano di query. Quando Query Optimizer sceglie l'indice columnstore filtrato, combina in modo trasparente le righe dall'indice columnstore nonché le righe che non soddisfano la condizione filtrata per consentire l'analisi in tempo reale. Si tratta di un indice diverso da un normale indice filtrato non cluster che può essere usato solo nelle query limitate alle righe presenti nell'indice.
-- Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
CustomerName nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50)
);
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fulfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
WHERE OrderStatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT TOP (5) CustomerName, SUM(PurchasePrice)
FROM orders
WHERE PurchasePrice > 100.0
GROUP BY CustomerName;
La query di analisi viene eseguita con il piano di query seguente. Come si può notare, è possibile accedere alle righe che non soddisfano la condizione filtrata solo usando l'indice ad albero B cluster.

Per ulteriori informazioni, consultare il Blog: Indice columnstore nonclustered filtrato.
Suggerimento per le prestazioni n. 2: trasferire l'analisi a una replica secondaria Always On leggibile
Anche se è possibile ridurre al minimo la manutenzione degli indici columnstore usando un indice columnstore filtrato, le query di analisi possono richiedere comunque risorse di calcolo elevate (CPU, I/O, memoria) che influiscono sulle prestazioni del carico di lavoro operativo. Per i carichi di lavoro maggiormente mission-critical, si consiglia di usare la configurazione AlwaysOn. In questa configurazione è possibile eliminare l'impatto dell'esecuzione dell'analisi scaricandone il carico su una replica secondaria accessibile.
Suggerimento per le prestazioni n. 3: Riduzione della frammentazione dell'indice mantenendo i dati più utilizzati nei gruppi di righe delta.
Le tabelle con indice columnstore potrebbero essere frammentate in modo significativo (in particolare a causa delle righe contrassegnate come eliminate) se il carico di lavoro aggiorna o elimina righe compresse. Un indice columnstore frammentato determina un utilizzo inefficiente della memoria o dell'archiviazione. Oltre all'uso inefficiente delle risorse, influisce negativamente sulle prestazioni delle query di analisi a causa dell'I/O aggiuntivo e della necessità di filtrare le righe eliminate dal set di risultati.
Le righe eliminate non vengono fisicamente rimosse fino a quando non si esegue la deframmentazione degli indici con il comando REORGANIZE o si ricompila l'indice columnstore nell'intera tabella o nelle partizioni interessate. Le operazioni di indicizzazione REORGANIZE e REBUILD sono costose in termini di risorse, che altrimenti potrebbero essere utilizzate per il carico di lavoro. Inoltre, se le righe vengono compresse troppo presto, potrebbe essere necessario ricomprimerle più volte a causa di aggiornamenti causando un sovraccarico inutile nei processi di compressione.
È possibile ridurre al minimo la frammentazione dell'indice usando l'opzione COMPRESSION_DELAY.
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int
);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY.
-- The columnstore index will keep the rows in closed delta rowgroup
-- for 100 minutes after it has been marked closed.
CREATE NONCLUSTERED COLUMNSTORE INDEX t_colstor_cci ON t_colstor
(accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION = COLUMNSTORE, COMPRESSION_DELAY = 100);
Per altre informazioni, vedere Blog: Ritardo della compressione.
Le procedure consigliate sono le seguenti:
Carico di lavoro Inserisci/Query: Se il carico di lavoro inserisce principalmente dati ed esegue query su di esso, il valore predefinito di 0 è l'opzione consigliata
COMPRESSION_DELAY. Le nuove righe inserite verranno compresse dopo l'inserimento di 1 milione di righe in un singolo rowgroup delta. Alcuni esempi di tali carichi di lavoro sono un carico di lavoro DW tradizionale o un'analisi del flusso di selezione quando è necessario analizzare il modello di selezione in un'applicazione Web.Carico di lavoro OLTP: se il carico di lavoro è pesante di DML, ovvero un'intensa combinazione di aggiornamenti, eliminazioni e inserimenti, potrebbe verificarsi la frammentazione dell'indice columnstore esaminando la DMV
sys.dm_db_column_store_row_group_physical_stats. Se si noterà che > 10% righe vengono contrassegnate come eliminate nei rowgroup compressi di recente, è possibile usare l'opzioneCOMPRESSION_DELAYper aggiungere un ritardo di tempo quando le righe diventano idonee per la compressione. Ad esempio, se per il tuo carico di lavoro, il dato appena inserito rimane "caldo" (ovvero viene aggiornato più volte) per, diciamo, 60 minuti, dovresti scegliereCOMPRESSION_DELAYcome 60.
Il valore predefinito dell'opzione COMPRESSION_DELAY deve funzionare per la maggior parte dei clienti.
Per gli utenti avanzati, è consigliabile eseguire la query seguente e raccogliere % di righe eliminate negli ultimi sette giorni.
SELECT row_group_id,
CAST(deleted_rows AS float)/CAST(total_rows AS float)*100 AS [% fragmented],
created_time
FROM sys.dm_db_column_store_row_group_physical_stats
WHERE object_id = OBJECT_ID('FactOnlineSales2')
AND state_desc = 'COMPRESSED'
AND deleted_rows > 0
AND created_time > DATEADD(day, -7, GETDATE())
ORDER BY created_time DESC;
Se il numero di righe eliminate nei rowgroup compressi > 20%, stabilizzato nei rowgroup meno recenti con < una variazione di 5% (denominati rowgroup freddi), impostare COMPRESSION_DELAY = (youngest_rowgroup_created_time - current_time). Questo approccio funziona meglio con un carico di lavoro stabile e relativamente omogeneo.