Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo è destinato ai modellatori di dati di importazione che lavorano con Power BI Desktop. Si tratta di un importante argomento di progettazione di modelli essenziale per offrire modelli intuitivi, accurati e ottimali.
Per una discussione più approfondita sulla progettazione ottimale del modello, inclusi ruoli e relazioni tra tabelle, vedere Informazioni sullo schema star e sull'importanza di Power BI.
Scopo della relazione
Una relazione di modello propaga i filtri applicati alla colonna di una tabella del modello a una tabella del modello diversa. I filtri verranno propagati finché è presente un percorso di relazione da seguire, che può comportare la propagazione in più tabelle.
I percorsi delle relazioni sono deterministici, ovvero i filtri vengono sempre propagati nello stesso modo e senza variazioni casuali. Le relazioni possono, tuttavia, essere disabilitate o avere il contesto di filtro modificato dai calcoli del modello che usano funzioni DAX specifiche. Per altre informazioni, vedere l'argomento Relativo alle funzioni DAX più avanti in questo articolo.
Importante
Le relazioni tra modelli non applicano l'integrità dei dati. Per altre informazioni, vedere l'argomento Valutazione delle relazioni più avanti in questo articolo, che illustra il comportamento delle relazioni del modello quando si verificano problemi di integrità dei dati.
Ecco come le relazioni propagano i filtri con un esempio animato.
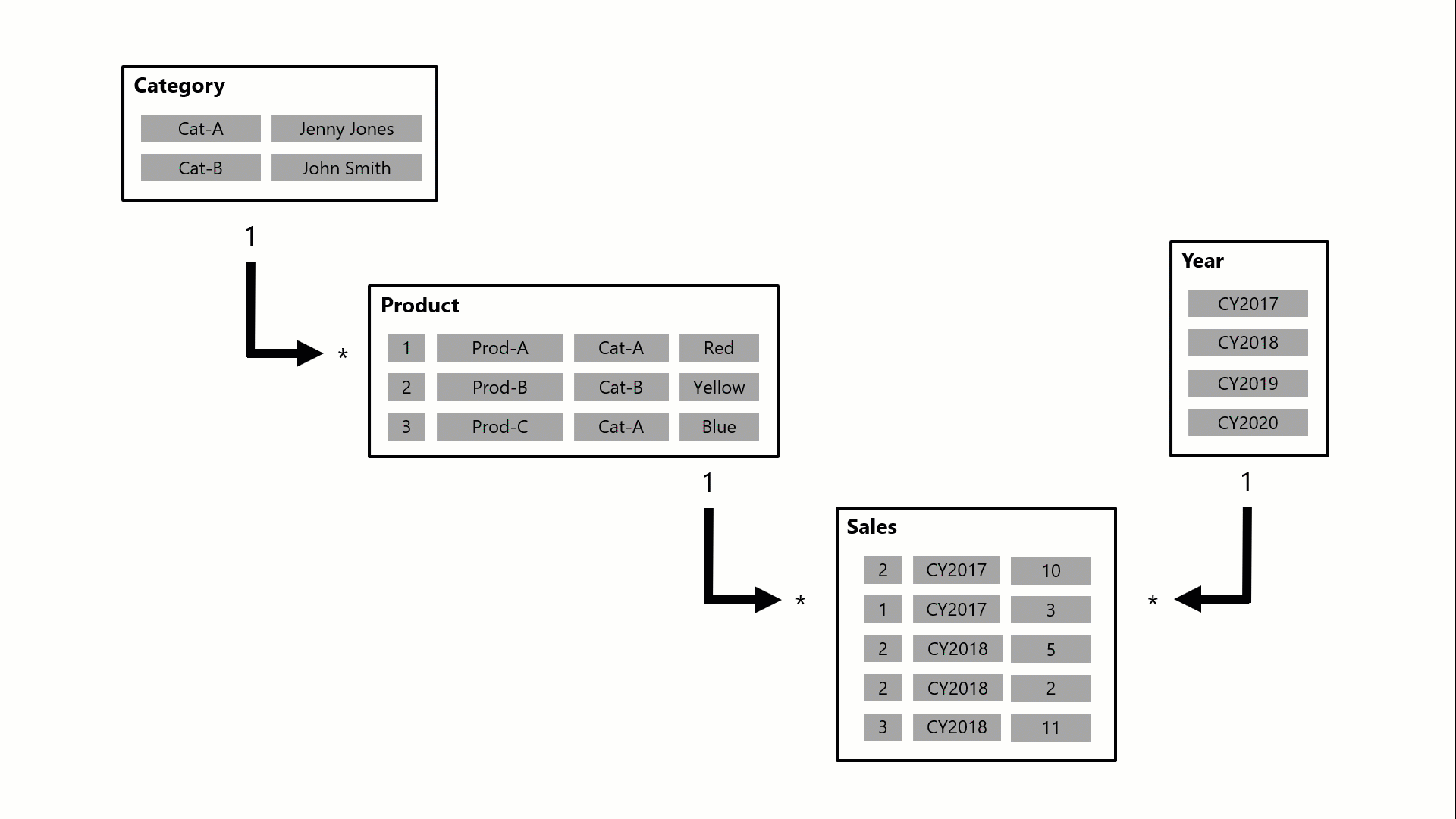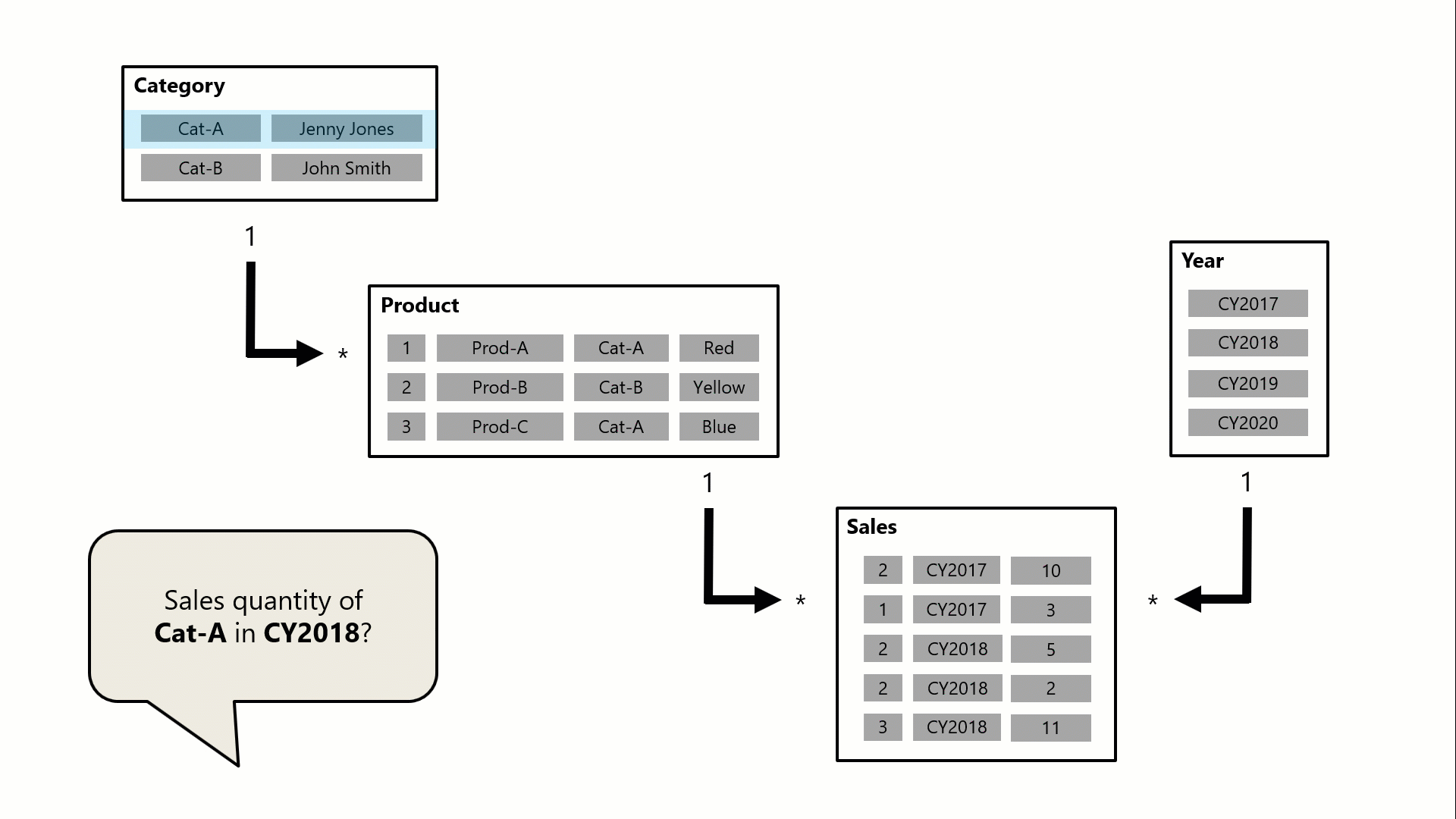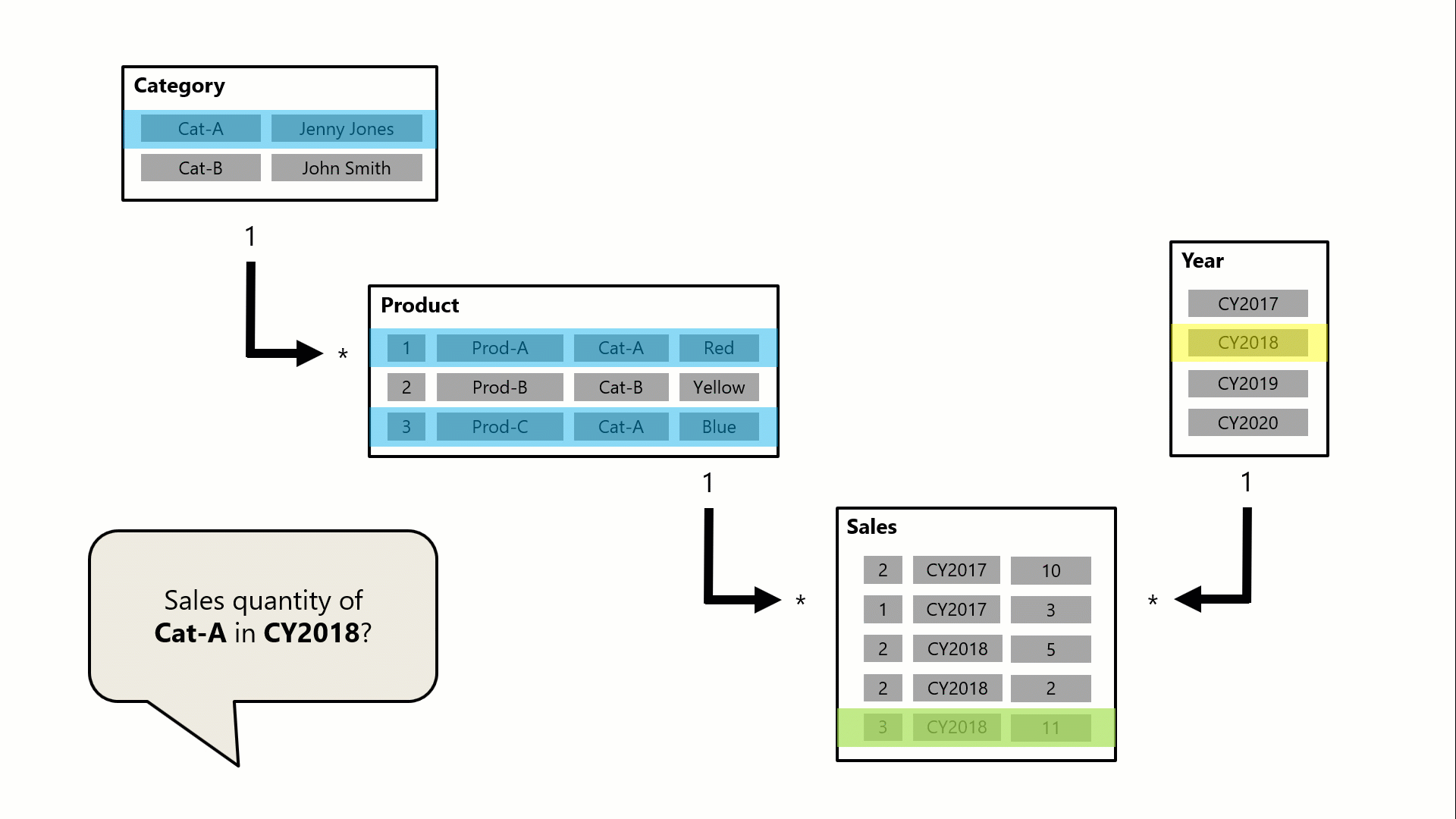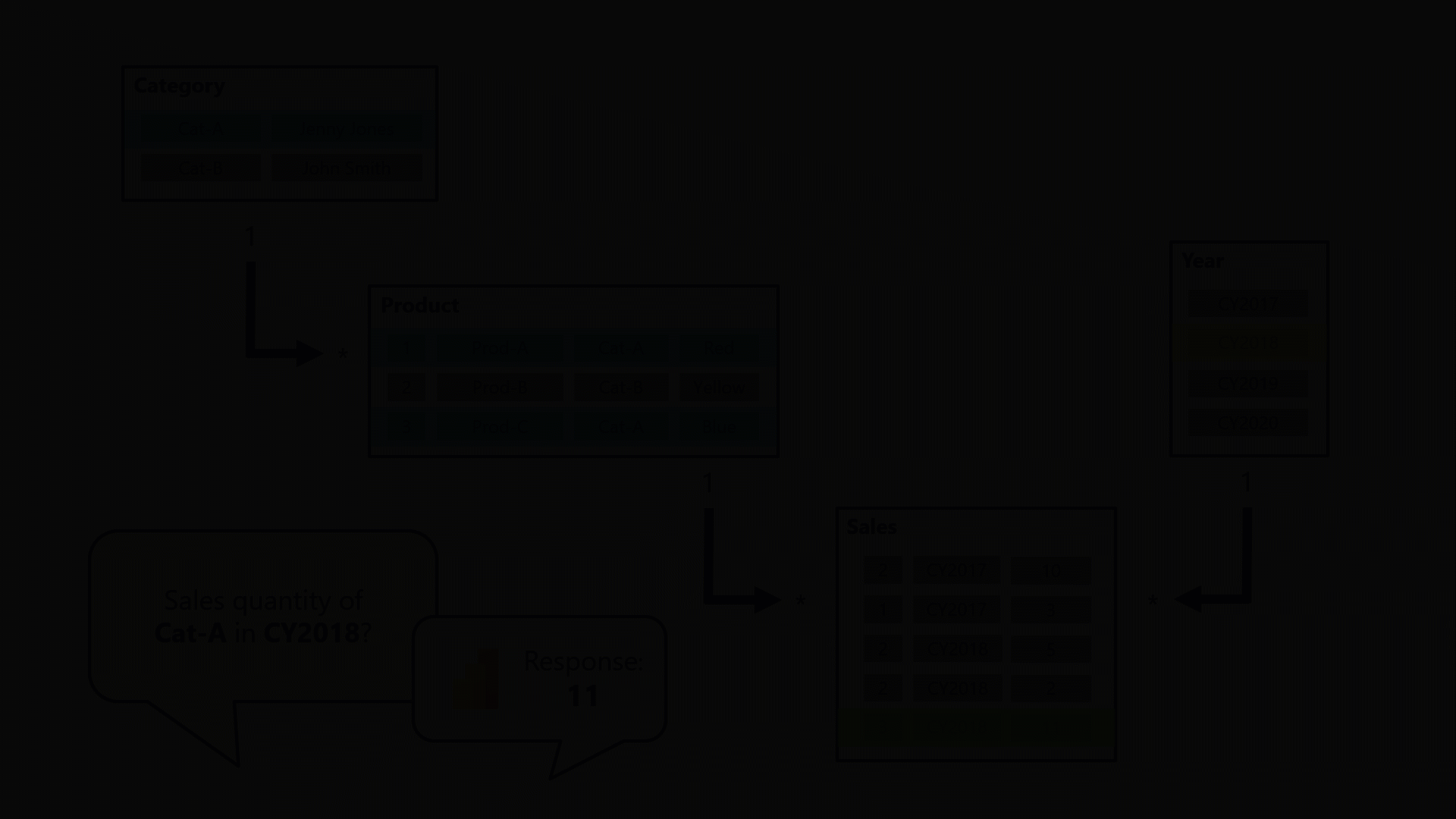
In questo esempio il modello è costituito da quattro tabelle: Category, Product, Year e Sales. La tabella Category è correlata alla tabella Product e la tabella Product è correlata alla tabella Sales . La tabella Year è correlata anche alla tabella Sales . Tutte le relazioni sono uno-a-molti (i cui dettagli sono descritti più avanti in questo articolo).
Una query, eventualmente generata da una scheda visualizzata in Power BI, richiede la quantità totale di vendite per gli ordini di vendita effettuati per una singola categoria, Cat-A, e per un singolo anno, CY2018. È per questo motivo che è possibile visualizzare i filtri applicati nelle tabelle Category e Year . Il filtro nella tabella Category viene propagato alla tabella Product per isolare due prodotti assegnati alla categoria Cat-A. I filtri della tabella Product vengono quindi propagati alla tabella Sales per isolare solo due righe di vendita per questi prodotti. Queste due righe di vendita rappresentano le vendite dei prodotti assegnati alla categoria Cat-A. La loro quantità combinata è di 14 unità. Allo stesso tempo, il filtro della tabella Year viene propagato per filtrare ulteriormente la tabella Sales , con conseguente solo una riga di vendita per i prodotti assegnati alla categoria Cat-A e ordinati nell'anno CY2018. Il valore di quantità restituito dalla query è 11 unità. Si noti che quando vengono applicati più filtri a una tabella (ad esempio la tabella Sales in questo esempio), si tratta sempre di un'operazione AND, che richiede che tutte le condizioni siano vere.
Applicare principi di progettazione dello schema star
È consigliabile applicare i principi di progettazione dello schema star per produrre un modello che comprende le tabelle delle dimensioni e dei fatti. È comune configurare Power BI per applicare regole che filtrano le tabelle delle dimensioni, consentendo alle relazioni del modello di propagare in modo efficiente tali filtri alle tabelle dei fatti.
L'immagine seguente è il diagramma del modello di dati di analisi delle vendite Adventure Works. Mostra una progettazione dello schema a stella che comprende una tabella singola dei fatti denominata Sales. Le altre quattro tabelle sono tabelle delle dimensioni che supportano l'analisi delle misure di vendita per data, stato, area e prodotto. Si notino le relazioni del modello che connettono tutte le tabelle. Queste relazioni propagano i filtri (direttamente o indirettamente) alla tabella Sales .
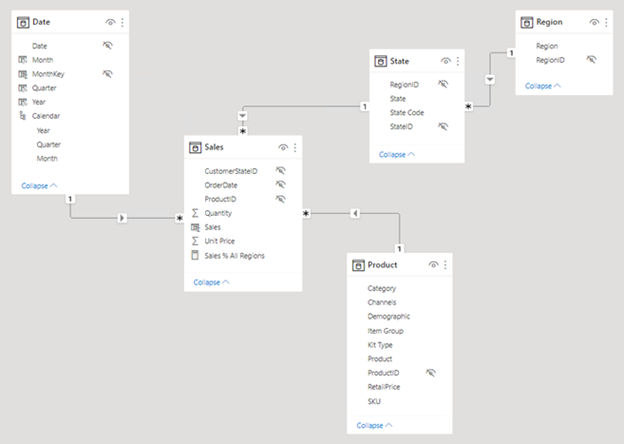
Tabelle disconnesse
È insolito che una tabella del modello non sia correlata a un'altra tabella del modello. Una tabella di questo tipo in una progettazione di modelli valida viene descritta come tabella disconnessa. Una tabella disconnessa non è progettata per propagare i filtri ad altre tabelle del modello. Accetta "input dell'utente" (ad esempio tramite una visualizzazione a selettore), consentendo ai calcoli del modello di usare il valore di input in modo significativo. Si consideri, ad esempio, una tabella disconnessa caricata con un intervallo di valori di tasso di cambio valuta. Se un filtro viene applicato per filtrare in base a un singolo valore di frequenza, un'espressione di misura può usare tale valore per convertire i valori di vendita.
Il parametro delle variabili ipotetiche di Power BI Desktop è una funzionalità che crea una tabella disconnessa. Per ulteriori informazioni, vedere Creare e utilizzare un parametro "What-If" per visualizzare variabili in Power BI Desktop.
Proprietà delle relazioni
Una relazione del modello consente di correlare una colonna di una tabella a una colonna di un'altra tabella. Esiste un caso specifico in cui questo requisito non è vero e si applica solo alle relazioni a più colonne nei modelli DirectQuery. Per altre informazioni, vedere l'articolo relativo alla funzione DAX COMBINEVALUES.
Nota
Non è possibile correlare una colonna a una colonna diversa nella stessa tabella. Questo concetto viene talvolta confuso con la possibilità di definire un vincolo di chiave esterna del database relazionale che si riferisce automaticamente alla tabella. È possibile usare questo concetto di database relazionale per archiviare le relazioni padre-figlio, ad esempio, ogni record di un dipendente è correlato al diretto superiore del dipendente. Tuttavia, non è possibile usare le relazioni del modello per generare una gerarchia di modelli basata su questo tipo di relazione. Per creare una gerarchia padre-figlio, vedere Funzioni padre e figlio.
Tipi di dati di colonne
Il tipo di dati per la colonna "from" e "to" della relazione deve essere lo stesso. L'utilizzo delle relazioni definite nelle colonne DateTime potrebbe non comportarsi come previsto. Il motore che archivia i dati di Power BI usa solo i tipi di dati DateTime; i tipi di dati Data, Ora e Data/Ora/Fuso orario sono costrutti di formattazione di Power BI implementati sopra. Tutti gli oggetti dipendenti dal modello verranno comunque visualizzati come DateTime nel motore , ad esempio relazioni, gruppi e così via. Di conseguenza, se un utente seleziona Data dalla scheda Modellazione per tali colonne, non viene comunque registrato come la stessa data, perché la parte relativa all'ora dei dati è ancora considerata dal motore. Altre informazioni su come vengono gestiti i tipi di data/ora. Per correggere il comportamento, i tipi di dati della colonna devono essere aggiornati nell'editor di Power Query per rimuovere la parte relativa all'ora dai dati importati, così quando il motore gestisce i dati, i valori appariranno uguali.
Cardinalità
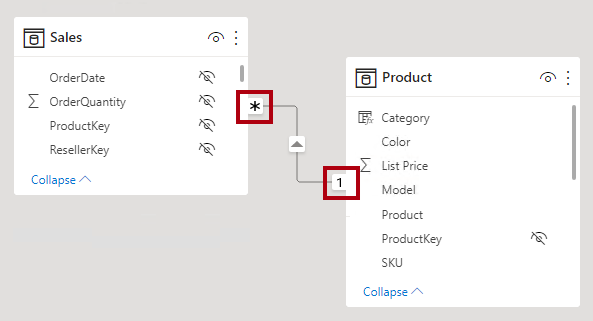
Ogni relazione del modello deve essere definita da un tipo di cardinalità. Sono disponibili quattro opzioni per il tipo di cardinalità, che rappresentano le caratteristiche dei dati delle colonne correlate con "da" e "a". Il lato "uno" indica che la colonna contiene valori univoci. Il lato "molti" indica che la colonna può contenere valori duplicati.
Nota
Se un'operazione di aggiornamento dati prova a caricare valori duplicati in una colonna lato "uno", l'intero aggiornamento dei dati avrà esito negativo.
Le quattro opzioni, insieme alle relative notazioni abbreviate, sono descritte nell'elenco puntato seguente:
- Uno a molti (1:*)
- Molti a uno (*:1)
- Uno-a-uno (1:1)
- Molti-a-molti (*:*)
Quando si crea una relazione in Power BI Desktop la finestra di progettazione rileva e imposta automaticamente il tipo di cardinalità. Power BI Desktop esegue una query sul modello per sapere quali colonne contengono valori univoci. Per i modelli di importazione, usa statistiche di archiviazione interne; per i modelli DirectQuery invia query di profilatura all'origine dati. A volte, tuttavia, Power BI Desktop può sbagliare. Ciò si verifica quando le tabelle devono essere ancora caricate con i dati o perché le colonne che si prevede contengano valori duplicati contengono attualmente valori univoci. In entrambi i casi, è possibile aggiornare il tipo di cardinalità a condizione che le colonne lato "uno" contengano valori univoci (o che la tabella debba ancora essere caricata con le righe di dati).
Cardinalità uno-a-molti (e molti-a-uno)
Le opzioni di cardinalità uno-a-molti e molti-a-uno sono essenzialmente uguali e sono anche i tipi di cardinalità più comuni.
Quando si configura una relazione uno-a-molti o molti-a-uno, si sceglie ciò che corrisponde all'ordine in cui sono state correlate le colonne. Si consideri come configurare la relazione dalla tabella Product alla tabella Sales usando la colonna ProductID presente in ogni tabella. Il tipo di cardinalità sarà uno-a-molti, perché la colonna ProductID nella tabella Product contiene valori univoci. Se le tabelle sono correlate nella direzione inversa, da Vendite a Prodotto, la cardinalità sarà molti-a-uno.
Cardinalità uno-a-uno
Un relazione uno-a-uno indica che entrambe le colonne contengono valori univoci. Questo tipo di cardinalità non è comune ed è probabile che rappresenti una progettazione del modello non ottimale a causa dell'archiviazione di dati ridondanti.
Per altre informazioni sull'uso di questo tipo di cardinalità, vedere Linee guida per relazioni uno-a-uno.
Cardinalità molti a molti
Una relazione molti-a-molti indica che entrambe le colonne possono contenere valori duplicati. Questo tipo di cardinalità viene usato raramente. È in genere utile quando si progettano requisiti di modelli complessi. È possibile usarla per correlare fatti molti a molti o per correlare fatti di grana più alta. Ad esempio, quando i fatti di destinazione delle vendite vengono archiviati a livello di categoria di prodotto e la tabella delle dimensioni del prodotto viene archiviata a livello di prodotto.
Per istruzioni sull'uso di questo tipo di cardinalità, consultare Linee guida per le relazioni molti-a-molti.
Nota
Il tipo di cardinalità Molti-a-molti è supportato per i modelli sviluppati per Power BI Report Server dal gennaio 2024 e versioni successive.
Suggerimento
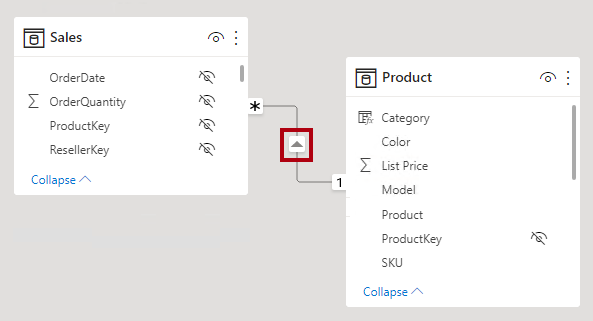
Nella visualizzazione modello di Power BI Desktop è possibile interpretare il tipo di cardinalità di una relazione esaminando gli indicatori (1 o *) su uno dei lati della linea della relazione. Per determinare quali colonne sono correlate, è necessario selezionare o passare il cursore sopra la riga della relazione per evidenziare le colonne.
Direzione dei filtri incrociati
Ogni relazione del modello viene definita con una direzione del filtro incrociato. L'impostazione determina la direzione o le direzioni in cui i filtri verranno propagati. Le opzioni di filtro incrociato possibili dipendono dal tipo di cardinalità.
| Tipo di cardinalità | Opzioni filtro incrociato |
|---|---|
| Uno-a-molti (o molti-a-uno) | Singolo Entrambi |
| Uno-a-uno | Entrambi |
| Molti-a-molti | Singolo (da Table1 a Table2) Singolo (da Tabella2 a Tabella1) Entrambi |
La direzione del filtro incrociato singolo indica "direzione singola" e Entrambi significano "entrambe le direzioni". Una relazione che filtra in entrambe le direzioni viene comunemente descritta come bidirezionale.
Per le relazioni uno-a-molti, la direzione del filtro incrociato è sempre dal lato "uno" e, facoltativamente, dal lato "molti" (bidirezionale). Per le relazioni uno-a-uno, la direzione del filtro incrociato è sempre da entrambe le tabelle. Infine, per le relazioni molti-a-molti, la direzione del filtro incrociato può provenire da una delle due tabelle o da entrambe. Si noti che quando il tipo di cardinalità include un lato "uno", i filtri vengono sempre propagati da tale lato.
Quando la direzione del filtro incrociato è impostata su Entrambi, diventa disponibile un'altra proprietà. Può applicare un filtro bidirezionale quando Power BI applica le regole di Sicurezza a livello di riga. Per altre informazioni sulla sicurezza a livello di riga, vedere Sicurezza a livello di riga con Power BI Desktop.
Puoi modificare la direzione del filtro incrociato della relazione, inclusa la possibilità di disabilitare la propagazione del filtro, usando un calcolo modellistico. Viene ottenuto usando la funzione DAX CROSSFILTER .
Tenere presente che le relazioni bidirezionali possono influire negativamente sulle prestazioni. Inoltre, il tentativo di configurare una relazione bidirezionale potrebbe provocare percorsi di propagazione del filtro ambigui. In questo caso, Power BI Desktop potrebbe non riuscire a eseguire il commit della modifica della relazione e verrà generato un avviso con un messaggio di errore. In alcuni casi, tuttavia, Power BI Desktop può consentire di definire percorsi di relazione ambigui tra le tabelle. La risoluzione dell'ambiguità del percorso delle relazioni è descritta più avanti in questo articolo.
Si consiglia di usare il filtro bidirezionale solo se necessario. Per altre informazioni, vedere Linee guida per la relazione bidirezionale.
Suggerimento
Nella visualizzazione modello di Power BI Desktop è possibile interpretare la direzione del filtro incrociato di una relazione notando la testa/e di freccia lungo la linea della relazione. Una singola freccia rappresenta un filtro a direzione singola nella direzione della freccia; una doppia freccia rappresenta una relazione bidirezionale.
Rendi attiva questa relazione
Tra due tabelle del modello può essere presente un solo percorso di propagazione del filtro attivo. Tuttavia, è possibile introdurre percorsi di relazione aggiuntivi, anche se è necessario impostare queste relazioni come inattive. Le relazioni inattive possono essere rese attive solo durante la valutazione del calcolo di un modello. Viene ottenuto usando la funzione USERELATIONSHIP DAX.
In genere, è consigliabile definire relazioni attive laddove possibile. Viene ampliato l'ambito e il potenziale del modo in cui gli autori di report possono usare il modello. Se si usano solo relazioni attive, le tabelle dimensionali di ruolo devono essere duplicate nel modello.
In circostanze specifiche, tuttavia, è possibile definire una o più relazioni inattive per una tabella di dimensioni con ruoli interpretativi. È possibile considerare questa progettazione quando:
- Non è necessario che gli oggetti visivi del report filtrino simultaneamente in base a ruoli diversi.
- Viene usata la funzione DAX
USERELATIONSHIPper attivare una relazione specifica per i calcoli del modello pertinenti.
Per altre informazioni, vedere Linee guida per relazioni attive e inattive.
Suggerimento
Nella visualizzazione modello di Power BI Desktop è possibile interpretare lo stato attivo o inattivo di una relazione. Una relazione attiva è rappresentata da una linea continua; una relazione inattiva è rappresentata da una linea tratteggiata.
Presupporre l'integrità referenziale
La proprietà Considera integrità referenziale è disponibile solo per le relazioni uno-a-molti e uno-a-uno tra due tabelle in modalità di archiviazione DirectQuery che appartengono allo stesso gruppo di origine. È possibile abilitare questa proprietà solo quando la colonna laterale "molti" non contiene valori NULL.
Se abilitata, le query native inviate all'origine dati creeranno un join tra le due tabelle usando INNER JOIN anziché OUTER JOIN. In generale, l'abilitazione di questa proprietà migliora le prestazioni delle query, anche se ciò dipende dalle specifiche dell'origine dati.
Abilitare sempre questa proprietà quando esiste un vincolo di chiave esterna del database tra le due tabelle. Anche quando non esiste un vincolo della chiave esterna, è consigliabile abilitare la proprietà, a condizione che esista l'integrità dei dati.
Importante
Se l'integrità dei dati dovesse essere compromessa, l'inner join eliminerà le righe non corrispondenti tra le tabelle. Si consideri, ad esempio, una tabella Sales del modello con un valore di colonna ProductID che non esiste nella tabella Product correlata. La propagazione del filtro dalla tabella Product alla tabella Sales eliminerà le righe di vendita per i prodotti sconosciuti. Questo comporterebbe una sottovalutazione dei risultati delle vendite.
Per ulteriori informazioni, consultare Impostazioni di integrità referenziale in Power BI Desktop.
Funzioni DAX pertinenti
Sono disponibili diverse funzioni DAX rilevanti per le relazioni del modello. Ogni funzione viene descritta brevemente nell'elenco puntato seguente:
- RELATED: recupera il valore dal lato "uno" di una relazione. È utile quando si effettuano calcoli provenienti da tabelle diverse che sono valutati nel contesto di riga.
- RELATEDTABLE: recupera una tabella di righe dal lato "molti" di una relazione.
- USERELATIONSHIP: consente a un calcolo di usare una relazione inattiva. Tecnicamente, questa funzione modifica il peso di una relazione specifica del modello inattivo, contribuendo a influenzarne l'uso. È utile quando il modello include una tabella delle dimensioni con ruoli e si sceglie di creare relazioni inattive da questa tabella. È anche possibile usare questa funzione per risolvere l'ambiguità nei percorsi di filtro.
- CROSSFILTER: modifica la direzione del filtro incrociato della relazione (a uno o entrambi) o disabilita la propagazione dei filtri (nessuno). È utile quando è necessario modificare o ignorare le relazioni del modello durante la valutazione di un calcolo specifico.
- COMBINEVALUES: unisce due o più stringhe di testo in una stringa di testo. Lo scopo di questa funzione è supportare relazioni a più colonne nei modelli DirectQuery quando le tabelle appartengono allo stesso gruppo di origine.
- TREATAS: applica il risultato di un'espressione di tabella come filtri alle colonne di una tabella non correlata. È utile negli scenari avanzati quando si vuole creare una relazione virtuale durante la valutazione di un calcolo specifico.
- Funzioni padre e figlio: una famiglia di funzioni correlate che è possibile usare per generare colonne calcolate per naturalizzare una gerarchia padre-figlio. È quindi possibile usare queste colonne per creare una gerarchia a livello fisso.
Valutazione delle relazioni
Le relazioni tra modelli, dal punto di vista della valutazione, vengono classificate come normali o limitate. Non si tratta di una proprietà della relazione configurabile. È in effetti dedotto dal tipo di cardinalità e dall'origine dati delle due tabelle correlate. È importante comprendere il tipo di valutazione poiché potrebbero verificarsi implicazioni o conseguenze sulle prestazioni in caso di compromissione dell'integrità dei dati. Queste implicazioni e le conseguenze per l'integrità sono descritte in questo argomento.
Per prima cosa, è necessaria una teoria di modellazione per comprendere completamente le valutazioni delle relazioni.
Un modello di importazione o DirectQuery origina tutti i suoi dati dalla cache Vertipaq o dal database di origine. In entrambi i casi, Power BI è in grado di determinare l'esistenza di un lato "uno" di una relazione.
Un modello composito, tuttavia, può includere tabelle usando modalità di archiviazione diverse (importazione, DirectQuery o doppia) o più origini DirectQuery. Ogni origine, inclusa la cache Vertipaq dei dati importati, viene considerata un gruppo di origine. Le relazioni tra modelli possono quindi essere classificate come gruppo di origine interno o tra gruppi di origine. Una relazione tra gruppi di origine correla due tabelle all'interno di un gruppo di origine, mentre una relazione tra gruppi di origine correla le tabelle tra due gruppi di origine. Si noti che le relazioni nei modelli di importazione o DirectQuery sono sempre all'interno del gruppo di origine.
Di seguito è riportato un esempio di modello di insieme.
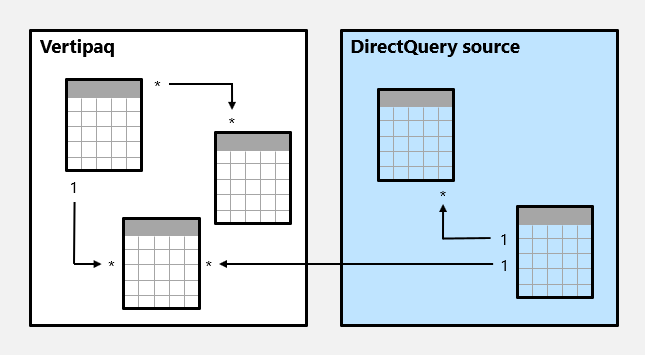
In questo esempio il modello composito è costituito da due gruppi di origine: un gruppo di origine Vertipaq e un gruppo di origine DirectQuery. Il gruppo di origine Vertipaq contiene tre tabelle e il gruppo di origine DirectQuery contiene due tabelle. Esiste una relazione tra gruppi di origine per correlare una tabella nel gruppo di origine Vertipaq a una tabella nel gruppo di origine DirectQuery.
Relazioni regolari
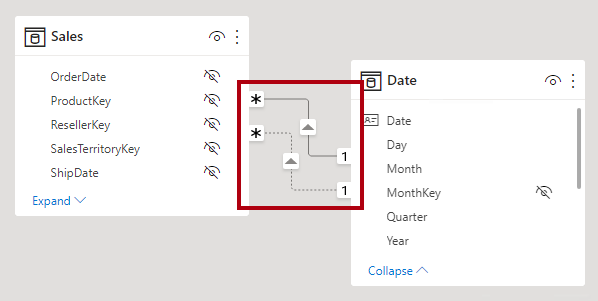
Una relazione di modello è regolare quando il motore di query può determinare il lato "uno" della relazione. Si ha conferma che la colonna "uno" contiene valori univoci. Tutte le relazioni uno-a-molti all'interno di un gruppo di origine sono relazioni regolari.
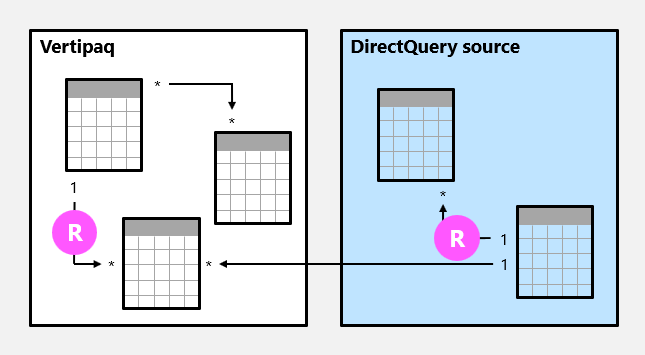
Nell'esempio seguente sono presenti due relazioni regolari, entrambe contrassegnate come R. Le relazioni includono la relazione uno-a-molti contenuta all'interno del gruppo di origine Vertipaq e la relazione uno-a-molti contenuta nell'origine DirectQuery.
Per i modelli di importazione, in cui tutti i dati vengono archiviati nella cache Vertipaq, Power BI crea una struttura di dati per ogni relazione regolare in fase di aggiornamento dei dati. Le strutture dei dati sono costituite da mapping indicizzati di tutti i valori da colonna a colonna e hanno lo scopo di accelerare l'unione di tabelle in fase di query.
In fase di query, le relazioni regolari consentono l'espansione della tabella . L'espansione della tabella comporta la creazione di una tabella virtuale includendo le colonne native della tabella di base e quindi espandendosi in tabelle correlate. Per le tabelle di importazione, l'espansione della tabella viene eseguita nel motore di query; per le tabelle DirectQuery viene eseguita nella query nativa inviata al database di origine , purché la proprietà Assumi integrità referenziale non sia abilitata. Il motore di query agisce quindi sulla tabella espansa applicando filtri e raggruppando i risultati in base ai valori nelle colonne della tabella espansa.
Nota
Le relazioni inattive vengono espanse, anche quando non vengono utilizzate da un calcolo. Le relazioni bidirezionali non hanno alcun effetto sull'espansione della tabella.
Per le relazioni uno-a-molti, l'espansione della tabella si verifica dal lato "molti" al lato "uno" usando la semantica LEFT OUTER JOIN. Quando non esiste un valore corrispondente dal lato "molti" al lato "uno", viene aggiunta una riga virtuale vuota alla tabella dal lato "uno". Questo comportamento si applica solo alle relazioni regolari, non alle relazioni limitate.
L'espansione della tabella si verifica anche per le relazioni uno-a-uno all'interno del gruppo di origine, ma usando la semantica FULL OUTER JOIN. Questo tipo di join garantisce che le righe virtuali vuote vengano aggiunte su entrambi i lati, quando necessario.
Le righe virtuali vuote sono di fatto membri sconosciuti. I membri sconosciuti rappresentano violazioni di integrità referenziale in cui il valore sul lato "molti" non ha un valore corrispondente sul lato "uno". Idealmente questi spazi vuoti non dovrebbero esistere. Possono essere eliminati pulendo o riparando i dati di origine.
Ecco come funziona l'espansione della tabella con un esempio animato.

In questo esempio il modello è costituito da tre tabelle: Categoria, Prodotto e Vendite. La tabella Category è correlata alla tabella Product con una relazione Uno-a-molti e la tabella Product è correlata alla tabella Sales con una relazione Uno-a-molti. La tabella Category contiene due righe, la tabella Product contiene tre righe e le tabelle Sales contiene cinque righe. Esistono valori corrispondenti su entrambi i lati di tutte le relazioni, vale a dire che non esistono violazioni di integrità referenziale. Una tabella espansa al momento della query viene visualizzata. La tabella è costituita dalle colonne di tutte e tre le tabelle. Si tratta in realtà di una prospettiva denormalizzata dei dati contenuti nelle tre tabelle. Una nuova riga viene aggiunta alla tabella Sales e ha un valore identificatore produzione (9) che non ha un valore corrispondente nella tabella Product. Si tratta di una violazione dell'integrità referenziale. Nella tabella espansa la nuova riga contiene valori (vuoti) per le colonne della tabella Category e Product.
Relazioni limitate
Una relazione di modello è limitata quando non esiste un lato "uno" garantito. Una relazione limitata può verificarsi per due motivi:
- La relazione utilizza una cardinalità di tipo molti a molti (anche se una o entrambe le colonne contengono valori unici).
- La relazione è tra gruppi di origine incrociati (cosa che può esistere solo per i modelli compositi).
Nell'esempio seguente sono presenti due relazioni limitate, entrambe contrassegnate come L. Le due relazioni includono la relazione molti-a-molti contenuta nel gruppo di origine Vertipaq e la relazione incrociata uno-a-molti tra gruppi di origine.

Per i modelli di importazione, le strutture dei dati non vengono mai create per le relazioni limitate. In questo caso, Power BI risolve i join delle tabelle al momento della query.
L'espansione della tabella non viene mai eseguita per le relazioni limitate. I join di tabella vengono realizzati utilizzando la semantica INNER JOIN e, di conseguenza, le righe virtuali vuote non vengono aggiunte per compensare le violazioni dell'integrità referenziale.
Esistono altre restrizioni correlate alle relazioni limitate:
- Non è possibile usare la funzione DAX
RELATEDper recuperare i valori della colonna lato "uno". - L'applicazione di RLS presenta restrizioni topologiche.
Suggerimento
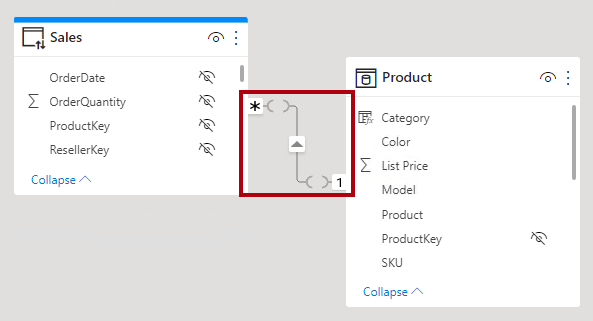
Nella visualizzazione modello di Power BI Desktop è possibile interpretare una relazione come limitata. Una relazione limitata è rappresentata con segni simili a parentesi ( ) dopo gli indicatori di cardinalità.
Risolvere l'ambiguità del percorso della relazione
Le relazioni bidirezionali possono introdurre più percorsi di propagazione del filtro, e pertanto ambigui, tra le tabelle del modello. Quando si valuta l'ambiguità, Power BI sceglie il percorso di propagazione del filtro in base alla priorità e al peso.
Priorità
I livelli di priorità definiscono una sequenza di regole usate da Power BI per risolvere l'ambiguità del percorso delle relazioni. La prima corrispondenza della regola determina il percorso che Verrà seguito da Power BI. Ogni regola seguente descrive il flusso dei filtri da una tabella di origine a una tabella di destinazione.
- Percorso costituito da relazioni uno-a-molti.
- Percorso costituito da relazioni uno-a-molti o molti-a-molti.
- Percorso costituito da relazioni molti a uno.
- Percorso costituito da relazioni uno-a-molti dalla tabella di origine a una tabella intermedia seguita da relazioni molti-a-uno dalla tabella intermedia alla tabella di destinazione.
- Percorso costituito da relazioni uno-a-molti o molti-a-molti dalla tabella di origine a una tabella intermedia seguita da relazioni molti-a-uno o molti-a-molti dalla tabella intermedia alla tabella di destinazione.
- Qualsiasi altro percorso.
Quando una relazione è inclusa in tutti i percorsi disponibili, viene rimossa dalla valutazione di tutti i percorsi.
Peso
Ogni relazione in un percorso ha un peso. Per impostazione predefinita, ogni peso della relazione è uguale a meno che non venga usata la funzione USERELATIONSHIP . Il peso del percorso è il massimo di tutti i pesi di relazione lungo il percorso. Power BI usa i pesi del percorso per risolvere l'ambiguità tra più percorsi nello stesso livello di priorità. Non sceglierà un percorso con una priorità più bassa, ma sceglierà il percorso con il peso maggiore. Il numero di relazioni nel percorso non influisce sul peso.
È possibile influenzare il peso di una relazione usando la funzione USERELATIONSHIP . Il peso è determinato dal livello di annidamento della chiamata a questa funzione, in cui la chiamata più interna riceve il peso più alto.
Si consideri l'esempio seguente. La misura Product Sales assegna un peso maggiore alla relazione tra Sales[ProductID] e Product[ProductID], seguita dalla relazione tra Inventory[ProductID] e Product[ProductID].
Product Sales =
CALCULATE(
CALCULATE(
SUM(Sales[SalesAmount]),
USERELATIONSHIP(Sales[ProductID], Product[ProductID])
),
USERELATIONSHIP(Inventory[ProductID], Product[ProductID])
)
Nota
Se Power BI rileva più percorsi con la stessa priorità e lo stesso peso, restituirà un errore di percorso ambiguo. In questo caso, è necessario risolvere l'ambiguità influenzando i pesi delle relazioni usando la funzione USERELATIONSHIP o rimuovendo o modificando le relazioni del modello.
Preferenza per le prestazioni
Nell'elenco seguente vengono ordinate le prestazioni di propagazione del filtro, dalle prestazioni più veloci a quelle più lente:
- Relazioni uno-a-molti all'interno del gruppo sorgente
- Relazioni di modello molti-a-molti ottenute con una tabella intermedia e che implicano almeno una relazione bidirezionale.
- Relazioni di cardinalità molti a molti
- Relazioni tra gruppi di origine
Contenuto correlato
Per altre informazioni su questo articolo, consultare le risorse seguenti:
- Comprendere lo schema star e l'importanza di Power BI
- Linee guida per relazioni uno-a-uno
- Linee guida per le relazioni molti a molti
- Linee guida per relazioni attive e inattive
- Linee guida per la relazione bidirezionale
- guida alla risoluzione dei problemi delle relazioni
- Video: Cosa fare e cosa non fare nei rapporti Power BI
- Domande? Chiedi alla community di Power BI
- Suggerimenti? Contribuire con idee per migliorare Power BI