Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo argomento descrive l'interfaccia ABI (Application Binary Interface) di base per x64, l'estensione a 64 bit per l'architettura x86. Gli argomenti trattati includono la convenzione di chiamata, il layout dei tipi, l'uso dello stack e dei registri, e altro ancora.
Convenzioni di chiamata x64
Due importanti differenze tra x86 e x64 sono:
- Funzionalità di indirizzamento a 64 bit
- Sedici registri a 64 bit per uso generico.
Dato il set di registri espanso, x64 usa la convenzione di chiamata __fastcall e un modello di gestione delle eccezioni basato su RISC.
La __fastcall convenzione usa i registri per i primi quattro argomenti e lo stack frame per passare più argomenti. Per informazioni dettagliate sulla convenzione di chiamata x64, tra cui l'utilizzo del registro, i parametri dello stack, i valori restituiti e la rimozione dello stack, vedere convenzione di chiamata x64.
Per ulteriori informazioni sulla convenzione di chiamata __vectorcall, vedere __vectorcall.
Abilitare l'ottimizzazione del compilatore x64
L'opzione del compilatore seguente consente di ottimizzare l'applicazione per x64:
Tipo x64 e layout di archiviazione
Questa sezione descrive l'archiviazione dei tipi di dati per l'architettura x64.
Tipi scalari
Anche se è possibile accedere ai dati con qualsiasi allineamento, allineare i dati sul limite naturale o un multiplo del limite naturale per evitare perdite di prestazioni. Le enumerazioni sono numeri interi costanti e vengono considerati numeri interi a 32 bit. La tabella seguente descrive la definizione del tipo e l'archiviazione consigliata per i dati in quanto riguarda l'allineamento usando i valori di allineamento seguenti:
- Byte - 8 bit
- Word - 16 bit
- Doppia parola - 32 bit
- Quadword - 64 bit
- Octaword - 128 bit
| Tipo scalare | tipo di dati C | Dimensioni di archiviazione (in byte) | Allineamento consigliato |
|---|---|---|---|
INT8 |
char |
1 | Byte |
UINT8 |
unsigned char |
1 | Byte |
INT16 |
short |
2 | Parola |
UINT16 |
unsigned short |
2 | Word |
INT32 |
int, long |
4 | Doppia parola |
UINT32 |
unsigned int, unsigned long |
4 | Doppia parola |
INT64 |
__int64 |
8 | Quadword |
UINT64 |
unsigned __int64 |
8 | Quadword |
FP32 (precisione singola) |
float |
4 | Doppia parola |
FP64 (precisione doppia) |
double |
8 | Quadword |
POINTER |
* | 8 | Quadword |
__m64 |
struct __m64 |
8 | Quadword |
__m128 |
struct __m128 |
16 | Octaword |
Layout di aggregazione e unione x64
Altri tipi, ad esempio matrici, struct e unioni, hanno requisiti di allineamento più rigorosi che garantiscono un'aggregazione coerente e l'archiviazione dell'unione e il recupero dei dati. Ecco le definizioni per matrice, struttura e unione:
Array
Contiene un gruppo ordinato di oggetti dati adiacenti. Ogni oggetto viene chiamato elemento . Tutti gli elementi all'interno di una matrice hanno le stesse dimensioni e tipo di dati.
Struttura
Contiene un gruppo ordinato di oggetti dati. A differenza degli elementi di una matrice, i membri di una struttura possono avere tipi di dati e dimensioni diversi.
Unione
Oggetto che contiene uno qualsiasi di un set di membri denominati. I membri del set denominato possono essere di qualsiasi tipo. Lo spazio di archiviazione allocato per un'unione è uguale allo spazio di archiviazione necessario per il membro più grande di tale unione, oltre a qualsiasi spaziatura interna necessaria per l'allineamento.
La tabella seguente illustra l'allineamento fortemente consigliato per i membri scalari di unioni e strutture.
| Tipo scalare | Tipo di dati C | Allineamento obbligatorio |
|---|---|---|
INT8 |
char |
Byte |
UINT8 |
unsigned char |
Byte |
INT16 |
short |
Parola |
UINT16 |
unsigned short |
Parola |
INT32 |
int, long |
Doppia parola |
UINT32 |
unsigned int, unsigned long |
Doppia parola |
INT64 |
__int64 |
Quadword |
UINT64 |
unsigned __int64 |
Quadword |
FP32 (precisione singola) |
float |
Doppia parola |
FP64 (precisione doppia) |
double |
Quadword |
POINTER |
* | Quadword |
__m64 |
struct __m64 |
Quadword |
__m128 |
struct __m128 |
Octaword |
Si applicano le regole di allineamento di aggregazione seguenti:
L'allineamento di una matrice è uguale all'allineamento di uno degli elementi della matrice.
L'allineamento dell'inizio di una struttura o di un'unione è l'allineamento massimo di qualsiasi singolo membro. Ogni membro all'interno della struttura o dell'unione deve essere posizionato in corrispondenza dell'allineamento corretto, come definito nella tabella precedente, che può richiedere spaziatura interna implicita, a seconda del membro precedente.
Le dimensioni della struttura devono essere un multiplo integrale del suo allineamento, il che può richiedere un riempimento dopo l'ultimo elemento. Poiché le strutture e le unioni possono essere raggruppate in matrici, ogni elemento di matrice di una struttura o di un'unione deve iniziare e terminare con l'allineamento corretto determinato in precedenza.
È possibile allineare i dati in modo tale da essere maggiori dei requisiti di allineamento purché vengano mantenute le regole precedenti.
Un singolo compilatore può modificare la compressione di una struttura per motivi di dimensioni. Ad esempio, /Zp (Struct Member Alignment) consente di regolare la compressione delle strutture.
Esempi di allineamento della struttura x64
I quattro esempi seguenti dichiarano una struttura o un'unione allineata e le figure corrispondenti illustrano il layout di tale struttura o unione in memoria. Ogni colonna di una figura rappresenta un byte di memoria e il numero nella colonna indica lo spostamento di tale byte. Il nome nella seconda riga di ogni figura corrisponde al nome di una variabile nella dichiarazione. Le colonne ombreggiate indicano la spaziatura interna necessaria per ottenere l'allineamento specificato.
Esempio 1
// Total size = 2 bytes, alignment = 2 bytes (word).
_declspec(align(2)) struct {
short a; // +0; size = 2 bytes
}

Esempio 2
// Total size = 24 bytes, alignment = 8 bytes (quadword).
_declspec(align(8)) struct {
int a; // +0; size = 4 bytes
double b; // +8; size = 8 bytes
short c; // +16; size = 2 bytes
}

Il diagramma mostra 24 byte di memoria. Il membro a, un int, occupa i byte da 0 a 3. Il diagramma mostra il riempimento per i byte da 4 a 7. Membro b, di tipo double, occupa i byte da 8 a 15. Membro c, di tipo short, occupa i byte da 16 a 17. I byte da 18 a 23 non sono usati.
Esempio 3
// Total size = 12 bytes, alignment = 4 bytes (doubleword).
_declspec(align(4)) struct {
char a; // +0; size = 1 byte
short b; // +2; size = 2 bytes
char c; // +4; size = 1 byte
int d; // +8; size = 4 bytes
}
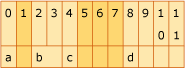
Il diagramma mostra 12 byte di memoria. Membro a, un carattere, occupa il byte 0. Byte 1 è riempimento. Membro b, breve, occupa byte da 2 a 4. Membro c, un char, occupa il byte 4. I byte da 5 a 7 sono padding. Membro d, un int, occupa byte da 8 a 11.
Esempio 4
// Total size = 8 bytes, alignment = 8 bytes (quadword).
_declspec(align(8)) union {
char *p; // +0; size = 8 bytes
short s; // +0; size = 2 bytes
long l; // +0; size = 4 bytes
}

Il diagramma mostra 8 byte di memoria. Elemento p, un char, occupa il byte numero 0. Membro s, un breve, occupa byte da 0 a 1. Membro l, una variabile di tipo long, occupa i byte da 0 a 3. I byte da 4 a 7 sono di riempimento.
Campi di bit
I campi di bit della struttura sono limitati a 64 bit e possono essere di tipo signed int, unsigned int, int64 o unsigned int64. I campi di bit che attraversano il limite del tipo saltano dei bit per allineare il campo di bit al successivo allineamento del tipo. Ad esempio, i campi di bit integer potrebbero non superare un limite a 32 bit.
Conflitti con il compilatore x86
I tipi di dati di dimensioni maggiori di 4 byte non vengono allineati automaticamente nello stack quando si usa il compilatore x86 per compilare un'applicazione. Poiché l'architettura per il compilatore x86 è uno stack allineato a 4 byte, qualsiasi valore maggiore di 4 byte, ad esempio un numero intero a 64 bit, non può essere allineato automaticamente a un indirizzo a 8 byte.
L'uso di dati non allineati ha due implicazioni.
L'accesso a posizioni non idonee potrebbe richiedere più tempo rispetto all'accesso alle posizioni allineate.
Non è possibile utilizzare posizioni non allineate nelle operazioni interbloccate.
Se è necessario un allineamento più rigoroso, usare __declspec(align(N)) nelle dichiarazioni di variabili. In questo modo il compilatore deve allineare dinamicamente lo stack in base alle specifiche. Tuttavia, la regolazione dinamica dello stack in fase di esecuzione può causare un rallentamento dell'esecuzione dell'applicazione.
Utilizzo del registro x64
L'architettura x64 fornisce 16 registri per utilizzo generico (qui di seguito denominati registri interi), oltre a 16 registri XMM/YMM disponibili per l'uso a virgola mobile. I registri volatili sono registri temporanei che il chiamante suppone vengano eliminati con una chiamata. I registri non volatili devono conservare i relativi valori durante le chiamate di funzione e, se usati, devono essere salvati dal chiamante.
Registrare volatilità e conservazione
Nella tabella seguente viene descritto il modo in cui ogni registro viene usato durante le chiamate di funzione:
| Registrazione | Status | Utilizzo |
|---|---|---|
| RAX | Volatile | Registro del valore restituito |
| RCX | Volatile | Primo argomento intero |
| RDX | Volatile | Secondo argomento Integer |
| R8 | Volatile | Terzo argomento intero |
| R9 | Volatile | Quarto argomento intero |
| R10:R11 | Volatile | Deve essere mantenuto in base alle esigenze del chiamante. Viene usato nelle istruzioni syscall/sysret. |
| R12:R15 | Non volatile | Deve essere preservato dal chiamato. |
| RDI | Non volatile | Deve essere mantenuto dal chiamato. |
| RSI | Non volatile | Deve essere mantenuto dal chiamato. |
| RBX | Non volatile | Deve essere preservato dal chiamato. |
| RBP | Non volatile | Può essere usato come puntatore ai frame. Deve essere mantenuto dal chiamato. |
| RSP | Non volatile | Puntatore dello stack |
| XMM0, YMM0 | Volatile | Primo argomento FP; primo argomento di tipo vettore quando si usa __vectorcall. |
| XMM1, YMM1 | Volatile | Secondo argomento FP; secondo argomento di tipo vettore quando si usa __vectorcall. |
| XMM2, YMM2 | Volatile | Terzo argomento FP; terzo argomento di tipo vettore quando si usa __vectorcall. |
| XMM3, YMM3 | Volatile | Quarto argomento FP; quarto argomento di tipo vettore quando si usa __vectorcall. |
| XMM4, YMM4 | Volatile | Deve essere preservato secondo le necessità del chiamante; quinto argomento di tipo vettoriale quando si utilizza __vectorcall. |
| XMM5, YMM5 | Volatile | Deve essere mantenuto in base alle esigenze del chiamante; sesto argomento di tipo vettore quando si usa __vectorcall. |
| XMM6:XMM15, YMM6:YMM15 | Non volatile (XMM), volatile (metà superiore di YMM) | Deve essere preservato dal chiamato. I registri YMM devono essere mantenuti in base alle esigenze del chiamante. |
All'uscita e all'ingresso delle chiamate alla libreria di runtime C e delle chiamate di sistema di Windows, ci si aspetta che il flag di direzione nel registro dei flag della CPU venga cancellato.
Uso dello stack
Per informazioni dettagliate sull'allocazione dello stack, l'allineamento, i tipi di funzione e gli stack frame in x64, vedere Utilizzo dello stack x64.
Prologo ed epilogo
Ogni funzione che alloca spazio dello stack, chiama altre funzioni, salva registri non volatili o usa la gestione delle eccezioni deve avere un prologo i cui limiti di indirizzo sono descritti nei dati di unwind associati alla rispettiva voce di tabella delle funzioni e epiloghi a ogni uscita di una funzione. Per informazioni dettagliate sul codice di prologo ed epilogo richiesto su x64, vedere prologo ed epilogo x64.
Gestione delle eccezioni x64
Per informazioni sulle convenzioni e sulle strutture di dati usate per implementare la gestione delle eccezioni strutturata e il comportamento di gestione delle eccezioni C++ in x64, vedere Gestione delle eccezioni x64.
Istruzioni intrinseche e assembly in linea
Uno dei vincoli per il compilatore x64 non è supportato dall'assembler inline. Ciò significa che le funzioni che non possono essere scritte in C o C++ dovranno essere scritte come subroutine o come funzioni intrinseche supportate dal compilatore. Alcune funzioni sono sensibili alle prestazioni, mentre altre non lo sono. Le funzioni sensibili alle prestazioni devono essere implementate come funzioni intrinseche.
Gli intrinseci supportati dal compilatore sono descritti in Funzioni intrinseche del compilatore.
Formato immagine x64
Il formato di immagine eseguibile x64 è PE32+. Le immagini eseguibili (DLL e EXEs) sono limitate a una dimensione massima di 2 gigabyte, quindi è possibile usare l'indirizzamento relativo con uno spostamento a 32 bit per gestire i dati delle immagini statiche. Questi dati includono la tabella degli indirizzi di importazione, le costanti stringa, i dati globali statici e così via.