Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione illustra come usare Analisi del testo per analizzare il testo non strutturato in Azure Synapse Analytics. Analisi del testo è uno dei servizi di Azure AI che consente di eseguire analisi del testo con funzionalità di elaborazione del linguaggio naturale (Natural Language Processing).
Questa esercitazione illustra l'uso dell'analisi del testo con SynapseML per:
- Rilevare le etichette di valutazione a livello di frase o documento
- Identificare la lingua per un input di testo specificato
- Riconoscere le entità da un testo con collegamenti a una knowledge base nota
- Estrarre frasi chiave da un testo
- Identificare le diverse entità in formato testo e classificarle in classi o tipi già definiti
- Identificare e ricompilate entità sensibili in un determinato testo
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- Area di lavoro di Azure Synapse Analytics con un account di archiviazione di Azure Data Lake Storage Gen2 configurato come risorsa archiviazione predefinita. È necessario essere il Collaboratore ai dati del BLOB della risorsa di archiviazione del file system di Data Lake Storage Gen2 con cui si lavora.
- Pool di Spark nell'area di lavoro di Azure Synapse Analytics. Per i dettagli, vedere Creare un pool di Spark in Azure Synapse.
- Procedura di preconfigurazione descritta nell'esercitazione Configurare i servizi di intelligenza artificiale di Azure in Azure Synapse.
Operazioni preliminari
Aprire Synapse Studio e creare un nuovo notebook. Per iniziare, importare SynapseML.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Configurare l'analisi del testo
Usare l'analisi del testo collegato configurata nei passaggi di preconfigurazione.
linked_service_name = "<Your linked service for text analytics>"
Valutazione del testo
L'analisi del sentiment del testo consente di rilevare le etichette del sentiment (ad esempio "negativo", "neutrale" e "positivo") e i punteggi di attendibilità a livello di frase e documento. Per l'elenco delle lingue abilitate, vedere le Lingue supportate nell'API dell’Analisi del testo.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Risultati previsti
| Testo | Valutazione |
|---|---|
| Sono così felice oggi, è soleggiato! | positivo |
| Sono frustrato da questo traffico dell'ora di punta | negativo |
| I servizi di Servizi di Azure AI non sono male | neutrale |
Rilevamento lingua
Rilevamento lingua valuta l'input di testo per ogni documento e restituisce gli identificatori di lingua con un punteggio che indica il livello di forza dell'analisi. Questa funzionalità è utile per gli archivi di contenuto che includono testo arbitrario, in cui la lingua è sconosciuta. Per l'elenco delle lingue abilitate, vedere le Lingue supportate nell'API dell’Analisi del testo.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Risultati previsti
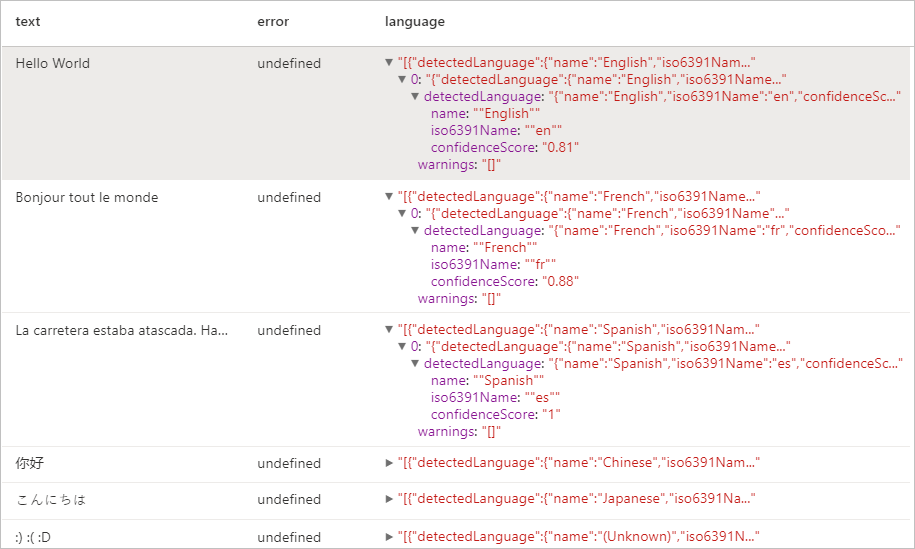
Rilevamento entità
Il Rilevamento entità restituisce un elenco di entità riconosciute con collegamenti a una knowledge base nota. Per l'elenco delle lingue abilitate, vedere le Lingue supportate nell'API dell’Analisi del testo.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Risultati previsti
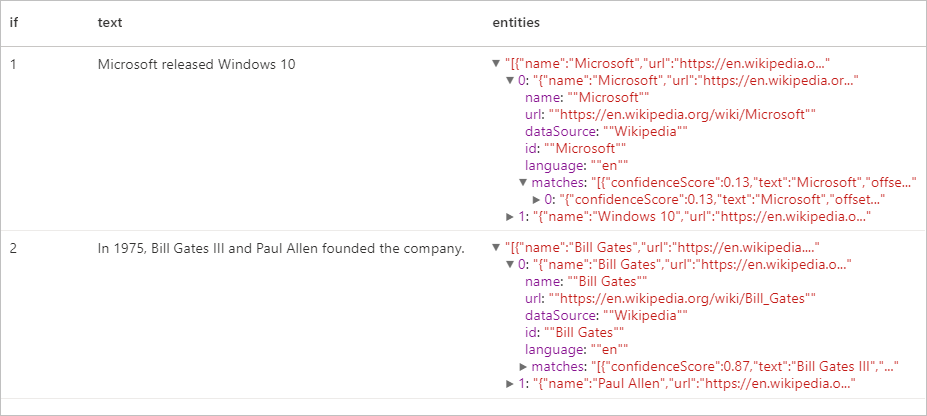
Estrattore di frasi chiave
La competenza Estrazione frasi chiave valuta il testo non strutturato e restituisce un elenco di frasi chiave. Questa funzionalità è utile se è necessario identificare rapidamente i punti rilevanti in una raccolta di documenti. Per l'elenco delle lingue abilitate, vedere le Lingue supportate nell'API dell’Analisi del testo.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Risultati previsti
| Testo | keyPhrases |
|---|---|
| Hello World. Questo è un testo di input che amo. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Riconoscimento delle entità denominate (NER)
Il riconoscimento dell’entità denominata (NER) è la possibilità di identificare entità diverse nel testo e classificarle in classi o tipi predefiniti, ad esempio persona, posizione, evento, prodotto e organizzazione. Per l'elenco delle lingue abilitate, vedere le Lingue supportate nell'API dell’Analisi del testo.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Risultati previsti
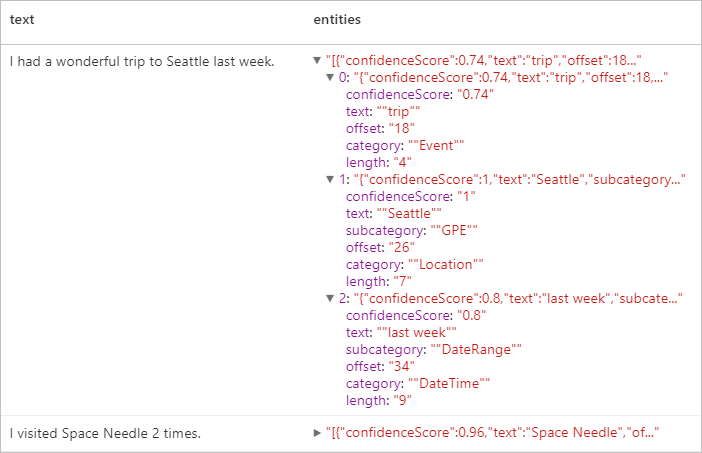
Informazioni personali (PII) V3.1
La funzionalità PII fa parte di NER e può identificare e revisionare entità sensibili nel testo associate a una singola persona, ad esempio: numero di telefono, indirizzo e-mail, indirizzo postale, numero di passaporto. Per l'elenco delle lingue abilitate, vedere le Lingue supportate nell'API dell’Analisi del testo.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Risultati previsti
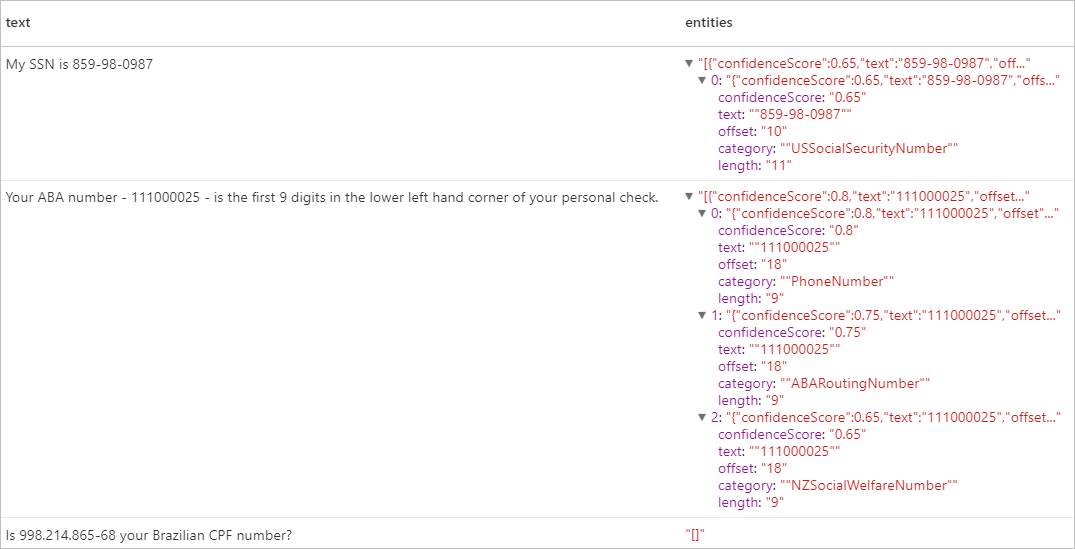
Pulire le risorse
Per assicurarsi che l'istanza di Spark venga arrestata, terminare tutte le sessioni connesse (notebook). Il pool si arresta quando viene raggiunto il tempo di inattività specificato nel pool di Apache Spark. Si può anche selezionare Termina sessione sulla barra di stato nella parte destra superiore del notebook.
