Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come migliorare le prestazioni per le condivisioni file di Azure NFS (Network File System).
Si applica a
| Modello di gestione | Modello di fatturazione | Livello supporti | Ridondanza | Piccole e Medie Imprese (PMI) | NFS (Network File System) |
|---|---|---|---|---|---|
| Microsoft.Storage | Con provisioning v2 | HDD (standard) | Locale |
|
|
| Microsoft.Storage | Con provisioning v2 | HDD (standard) | Della zona |
|
|
| Microsoft.Storage | Con provisioning v2 | HDD (standard) | Geografica |
|
|
| Microsoft.Storage | Con provisioning v2 | HDD (standard) | GeoZone (GZRS) |
|
|
| Microsoft.Storage | Con provisioning v1 | SSD (Premium) | Locale |
|
|
| Microsoft.Storage | Con provisioning v1 | SSD (Premium) | Della zona |
|
|
| Microsoft.Storage | Pagamento in base al consumo | HDD (standard) | Locale |
|
|
| Microsoft.Storage | Pagamento in base al consumo | HDD (standard) | Della zona |
|
|
| Microsoft.Storage | Pagamento in base al consumo | HDD (standard) | Geografica |
|
|
| Microsoft.Storage | Pagamento in base al consumo | HDD (standard) | GeoZone (GZRS) |
|
|
Aumentare le dimensioni read-ahead per migliorare la velocità effettiva di lettura
Il read_ahead_kb parametro kernel in Linux rappresenta la quantità di dati che devono essere "letti in anticipo" o prelettura durante un'operazione di lettura sequenziale. Le versioni del kernel Linux precedenti alla 5.4 impostano il valore read-ahead sull'equivalente di 15 volte il file system montato, che rappresenta l'opzione di montaggio sul lato client per le dimensioni del rsizebuffer di lettura. In questo modo il valore read-ahead è sufficientemente elevato per migliorare la velocità effettiva di lettura sequenziale del client nella maggior parte dei casi.
Tuttavia, a partire dal kernel Linux versione 5.4, il client Linux NFS usa un valore predefinito read_ahead_kb di 128 KiB. Questo valore ridotto potrebbe ridurre la quantità di velocità effettiva di lettura per file di grandi dimensioni. I clienti che aggiornano le versioni di Linux con il valore read-ahead più grande per le versioni con il valore predefinito di 128 KiB potrebbero riscontrare una diminuzione delle prestazioni di lettura sequenziale.
Per i kernel Linux 5.4 o versioni successive, è consigliabile impostare in modo permanente su read_ahead_kb 15 MiB per migliorare le prestazioni.
Per modificare questo valore, impostare le dimensioni read-ahead aggiungendo una regola in udev, un gestore di dispositivi kernel Linux. Seguire questa procedura:
In un editor di testo creare il file /etc/udev/rules.d/99-nfs.rules immettendo e salvando il testo seguente:
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"In una console applicare la regola udev eseguendo il comando udevadm come utente con privilegi avanzati e ricaricando i file delle regole e altri database. È necessario eseguire questo comando una sola volta per rendere udev consapevole del nuovo file.
sudo udevadm control --reload
NFS nconnect
NFS nconnect è un'opzione di montaggio lato client per le condivisioni file NFS che consente di usare più connessioni TCP tra il client e la condivisione file NFS.
Vantaggi
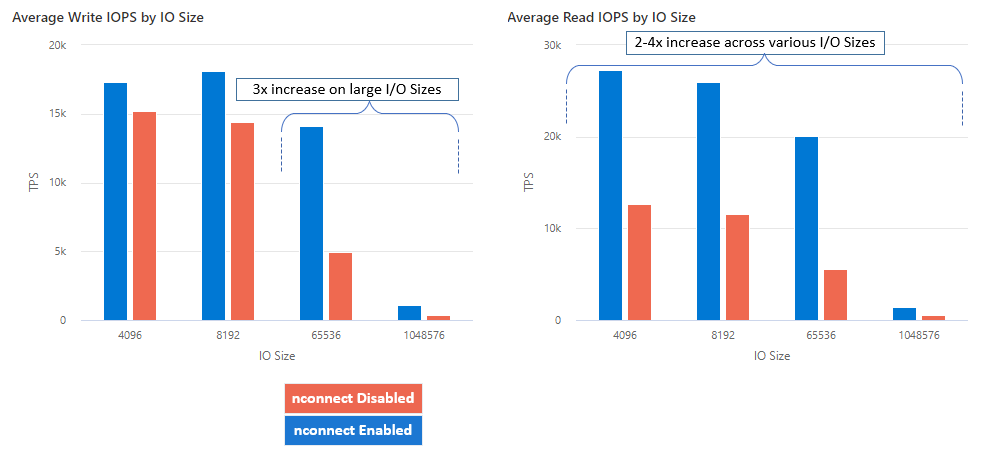
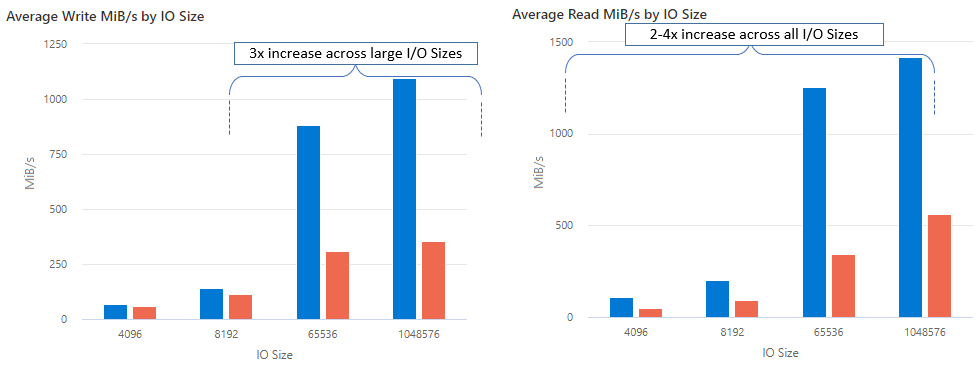
Con nconnect è possibile aumentare le prestazioni su larga scala usando un minor numero di computer client per ridurre il costo totale di proprietà (TCO). La funzionalità nconnect aumenta le prestazioni usando più canali TCP in una o più schede di interfaccia di rete, usando uno o più client. Senza nconnect, avresti bisogno di circa 20 macchine client per raggiungere i limiti di scalabilità della larghezza di banda (10 GiB/sec) offerti dalle dimensioni massime di provisioning della condivisione file SSD. Con nconnect è possibile raggiungere questi limiti usando solo 6-7 client, riducendo i costi di calcolo di quasi 70%, offrendo miglioramenti significativi nelle operazioni di I/O al secondo (IOPS) e velocità effettiva su larga scala. Vedi la tabella seguente.
| Metrica (operazione) | Dimensioni di I/O | Miglioramento delle prestazioni |
|---|---|---|
| Operazioni di I/O al secondo (scrittura) | 64 KiB, 1.024 KiB | 3x |
| Operazioni di I/O al secondo (lettura) | Tutte le dimensioni di I/O | 2-4 volte |
| Velocità effettiva (scrittura) | 64 KiB, 1.024 KiB | 3x |
| Velocità effettiva (lettura) | Tutte le dimensioni di I/O | 2-4 volte |
Prerequisiti
- Le distribuzioni Linux più recenti supportano completamente nconnect. Per le distribuzioni Linux precedenti, assicurarsi che la versione del kernel Linux sia 5.3 o successiva.
- La configurazione per montaggio è supportata solo quando viene usata una singola condivisione file per ogni account di archiviazione su un endpoint privato.
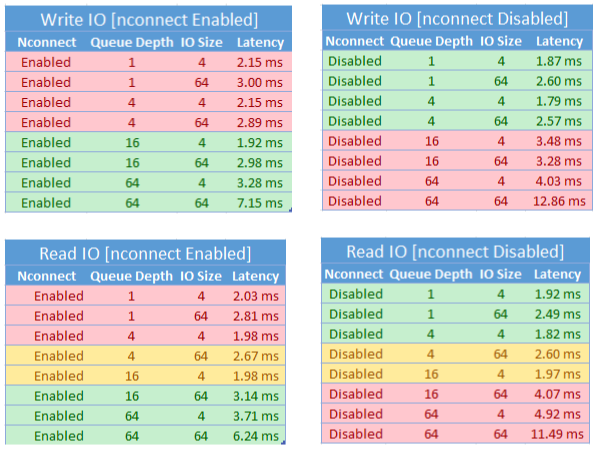
Impatto sulle prestazioni
Sono stati ottenuti i risultati delle prestazioni seguenti quando si usa l'opzione di montaggio nconnect con condivisioni file di Azure NFS nei client Linux su larga scala. Per altre informazioni su come sono stati ottenuti questi risultati, vedere Configurazione dei test delle prestazioni.
Consigli
Seguire queste raccomandazioni per ottenere i risultati migliori da nconnect.
Impostare nconnect=4
Anche se File di Azure supporta l'impostazione di nconnect fino all'impostazione massima di 16, è consigliabile configurare le opzioni di montaggio con l'impostazione ottimale di nconnect=4. Attualmente, non ci sono vantaggi oltre quattro canali per l'implementazione di nconnect per Azure Files. Infatti, il superamento di quattro canali a una singola condivisione file di Azure da un singolo client potrebbe influire negativamente sulle prestazioni a causa della saturazione della rete TCP.
Ridimensionare attentamente le macchine virtuali
A seconda dei requisiti del carico di lavoro, è importante ridimensionare correttamente le macchine virtuali client per evitare di essere limitate dalla larghezza di banda di rete prevista. Non sono necessari più controller di interfaccia di rete (NIC) per ottenere la velocità effettiva di rete prevista. Anche se è comune usare macchine virtuali per utilizzo generico con File di Azure, sono disponibili vari tipi di vm a seconda delle esigenze del carico di lavoro e della disponibilità dell'area. Per altre informazioni, vedere Selettore di macchine virtuali di Azure.
Mantenere la profondità della coda minore o uguale a 64
La profondità della coda è il numero di richieste di I/O in sospeso che possono essere eseguite da una risorsa di archiviazione. Non è consigliabile superare la profondità ottimale della coda di 64 perché non verranno visualizzati altri miglioramenti delle prestazioni. Per altre informazioni, vedere Profondità coda.
Configurazione per installazione
Se un carico di lavoro richiede il montaggio di più condivisioni con uno o più account di archiviazione con impostazioni nconnect diverse da un singolo client, non è possibile garantire che tali impostazioni siano persistenti durante il montaggio sull'endpoint pubblico. La configurazione per montaggio è supportata solo quando viene usata una singola condivisione file di Azure per ogni account di archiviazione sull'endpoint privato, come descritto nello scenario 1.
Scenario 1: per configurazione di montaggio su endpoint privato con più account di archiviazione (supportati)
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Scenario 2: per configurazione di montaggio su endpoint pubblico (non supportato)
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Nota
Anche se l'account di archiviazione si risolve in un indirizzo IP diverso, non possiamo garantire che quell'indirizzo rimanga invariato perché gli endpoint pubblici non sono indirizzi statici.
Scenario 3: per la configurazione di montaggio su endpoint privato con più condivisioni in un singolo account di archiviazione (non supportata)
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
Configurazione dei test delle prestazioni
Sono stati usati gli strumenti di benchmark e risorse seguenti per ottenere e misurare i risultati descritti in questo articolo.
- Client singolo: macchina virtuale di Azure (serie DSv4) con una singola scheda di interfaccia di rete
- Sistema operativo: Linux (Ubuntu 20.40)
-
Archiviazione NFS: Condivisione file SSD (con 30 TiB pre-allocati, set
nconnect=4)
| Dimensione | vCPU | Memoria | Archiviazione temporanea (SSD) | Numero massimo di dischi dati | Numero massimo di schede di interfaccia di rete | Larghezza di banda di rete prevista |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64 GiB | Solo archiviazione remota | 32 | 8 | 12.500 Mbps |
Strumenti e test di benchmarking
È stato usato un tester di I/O flessibile (FIO), uno strumento di I/O su disco open source gratuito usato sia per benchmark che per la verifica hardware/stress. Per installare FIO, seguire la sezione Pacchetti binari nel file FIO README da installare per la piattaforma preferita.
Anche se questi test si concentrano su modelli di accesso di I/O casuali, si ottengono risultati simili quando si usano operazioni di I/O sequenziali.
Operazioni di I/O al secondo elevate: letture al 100%
Dimensioni di I/O 4k - lettura casuale - Profondità coda 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Dimensioni di I/O 8k - lettura casuale - Profondità coda 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Velocità effettiva elevata: letture al 100%
Dimensioni I/O di 64 KiB - Lettura casuale - Profondità coda 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
1.024 KiB dimensione I/O - 100% lettura casuale - profondità della coda 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Operazioni di I/O al secondo elevate: scritture al 100%
Dimensione I/O di 4 KiB - 100% scrittura casuale - coda di profondità 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Dimensione blocco I/O di 8 KiB - 100% scrittura casuale - 64 di profondità della coda
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Velocità effettiva elevata: 100% scritture
Dimensioni I/O di 64 KiB - 100% scrittura casuale - Profondità coda 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Dimensioni di I/O 1024 KiB - 100% scrittura casuale - Profondità coda 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Considerazioni sulle prestazioni per nconnect
Quando si usa l'opzione nconnect di montaggio, è consigliabile valutare attentamente i carichi di lavoro con le caratteristiche seguenti:
- Carichi di lavoro di scrittura sensibili alla latenza che sono a thread singolo e/o usano una profondità bassa della coda (inferiore a 16)
- Carichi di lavoro di lettura sensibili alla latenza che sono a thread singolo e/o usano una profondità bassa della coda in combinazione con dimensioni di I/O inferiori
Non tutti i carichi di lavoro richiedono operazioni di I/O al secondo su larga scala o prestazioni. Per i carichi di lavoro di scalabilità più piccoli, nconnect potrebbe non essere opportuno. Usare la tabella seguente per decidere se nconnect è vantaggioso per il carico di lavoro. Gli scenari evidenziati in verde sono consigliati, mentre gli scenari evidenziati in rosso non sono. Gli scenari evidenziati in giallo sono neutri.