Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
I notebook di Jupyter offrono un ambiente interattivo per l'esplorazione, l'analisi e la visualizzazione dei dati nel data lake Microsoft Sentinel e nelle tabelle federate. Con i notebook è possibile scrivere ed eseguire codice, documentare il flusso di lavoro e visualizzare i risultati, il tutto in un'unica posizione. In questo modo è facile eseguire l'esplorazione dei dati, creare soluzioni di analisi avanzate e condividere informazioni dettagliate con altri utenti. Sfruttando Python e Apache Spark in Visual Studio Code, i notebook consentono di trasformare i dati di sicurezza non elaborati in intelligence pratica.
Questo articolo illustra come esplorare e interagire con i dati data lake usando i notebook di Jupyter in Visual Studio Code.
Prerequisiti
Eseguire l'onboarding nel data lake Microsoft Sentinel
Per usare i notebook nel data lake Microsoft Sentinel, è prima necessario eseguire l'onboarding nel data lake. Se non è stato ancora fatto l'onboarding nel data lake Sentinel, vedere Onboarding to Microsoft Sentinel data lake (Onboarding in Microsoft Sentinel data lake). Se di recente è stato eseguito l'onboarding nel data lake, potrebbe essere necessario del tempo prima che venga inserito un volume sufficiente di dati prima di poter creare analisi significative usando notebook.
Autorizzazioni
Microsoft Entra ID ruoli offrono un ampio accesso a tutte le aree di lavoro nel data lake. In alternativa, è possibile concedere l'accesso a singole aree di lavoro usando Azure ruoli controllo degli accessi in base al ruolo. Gli utenti con autorizzazioni Azure controllo degli accessi in base al ruolo per Microsoft Sentinel aree di lavoro possono eseguire notebook in tali aree di lavoro nel livello data lake. Per altre informazioni, vedere Ruoli e autorizzazioni in Microsoft Sentinel.
Facoltativamente, Microsoft Sentinel ambito o controllo degli accessi in base al ruolo a livello di riga può essere configurato per limitare ulteriormente l'accesso ai dati all'interno di un'area di lavoro. Se abilitata, l'ambito a livello di riga limita i dati restituiti dalle query in base all'ambito assegnato dall'utente. Se l'ambito a livello di riga non è configurato, il modello di autorizzazione a livello di area di lavoro esistente viene applicato invariato. Per altre informazioni, vedere Configurare Microsoft Sentinel ambito (controllo degli accessi in base al ruolo a livello di riga) (anteprima).
Per creare nuove tabelle personalizzate nel livello di analisi, all'identità gestita del data lake deve essere assegnato il ruolo Collaboratore Log Analytics nell'area di lavoro Log Analytics.
Per assegnare il ruolo, seguire questa procedura:
- Nella portale di Azure passare all'area di lavoro Log Analytics a cui si vuole assegnare il ruolo.
- Selezionare Controllo di accesso (IAM) nel riquadro di spostamento sinistro.
- Selezionare Aggiungi assegnazione di ruolo.
- Nella tabella Ruolo selezionare Log Analytics Contributor (Collaboratore Log Analytics) e quindi Avanti
- Selezionare Identità gestita e quindi Selezionare i membri.
- L'identità gestita del data lake è un'identità gestita assegnata dal sistema denominata
msg-resources-<guid>. Selezionare l'identità gestita e quindi selezionare Seleziona. - Selezionare Rivedi e assegna.
Per altre informazioni sull'assegnazione di ruoli alle identità gestite, vedere Assegnare ruoli Azure usando il portale di Azure.
Installare Visual Studio Code e l'estensione Microsoft Sentinel
Se Visual Studio Code non è già disponibile, scaricare e installare Visual Studio Code per Mac, Linux o Windows.
L'estensione Microsoft Sentinel per Visual Studio Code (VS Code) viene installata dal marketplace delle estensioni. Per installare l'estensione, seguire questa procedura:
- Selezionare Extensions Marketplace nella barra degli strumenti a sinistra.
- Cercare Sentinel.
- Selezionare l'estensione Microsoft Sentinel e selezionare Installa.
- Dopo l'installazione dell'estensione, nella barra degli strumenti a sinistra viene visualizzata
 .
.

Installare l'estensione GitHub Copilot per Visual Studio Code per abilitare il completamento del codice e i suggerimenti nei notebook.
- Cercare GitHub Copilot in Extensions Marketplace e installarlo.
- Dopo l'installazione, accedere a GitHub Copilot usando l'account GitHub.
Esplorare le tabelle di livello Data Lake
Dopo aver installato l'estensione Microsoft Sentinel, è possibile iniziare a esplorare le tabelle di livello Data Lake e creare notebook di Jupyter per analizzare i dati.
Accedere all'estensione Microsoft Sentinel
Selezionare il Microsoft Sentinel
nella barra degli strumenti sinistra.Viene visualizzata una finestra di dialogo con il testo seguente L'estensione "Microsoft Sentinel" vuole accedere usando Microsoft. Selezionare Consenti.

Selezionare il nome dell'account per completare l'accesso.

Se si dispone di più account guest associati all'accesso, è possibile passare facilmente da un account all'altro. Per passare da un account all'altro, selezionare il nome dell'account nella parte inferiore sinistra della finestra di Visual Studio Code. È possibile selezionare un solo account alla volta.

Importante
Se si passa da un account all'altro, tutte le sessioni pyspark attive vengono disconnesse.



Visualizzare tabelle e processi data lake
Dopo l'accesso, l'estensione Sentinel visualizza un elenco di tabelle Lake e processi nel riquadro sinistro. Le tabelle vengono raggruppate in base al database e alla categoria. Le tabelle federate vengono visualizzate nella categoria Tabelle federate in Tabelle di sistema. Selezionare una tabella per visualizzare le definizioni di colonna.
Per informazioni sui processi, vedere Processi e pianificazione. Per altre informazioni sulle tabelle federate, vedere Uso di tabelle federate nel data lake Microsoft Sentinel.

Creare un nuovo notebook
Per creare un nuovo notebook, usare uno dei metodi seguenti.
Immettere > nella casella di ricerca o premere CTRL+MAIUSC+P e quindi immettere Crea nuovo Jupyter Notebook.

Selezionare File > nuovo file e quindi selezionare Jupyter Notebook dall'elenco a discesa.

Nel nuovo notebook incollare il codice seguente nella prima cella.
from sentinel_lake.providers import MicrosoftSentinelProvider data_provider = MicrosoftSentinelProvider(spark) table_name = "EntraGroups" df = data_provider.read_table(table_name) df_filtered = df.select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId").show(100, truncate=False) # Transform the dataframe df_transformed = df.filter(df.mail.isNotNull()).select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId") write_options = { 'mode': 'overwrite' } # Save to a new table data_provider.save_as_table(df_transformed, "EntraGroups_Processed_SPRK", write_options=write_options)


L'editor fornisce il completamento del codice intellisense sia per la MicrosoftSentinelProvider classe che per i nomi di tabella nel data lake.
Selezionare il triangolo Esegui per eseguire il codice nel notebook. I risultati vengono visualizzati nel riquadro di output sotto la cella di codice.

Selezionare Microsoft Sentinel nell'elenco per un elenco di pool di runtime.

Selezionare Medio per eseguire il notebook nel pool di runtime di medie dimensioni. Per altre informazioni sui diversi runtime, vedere Selezione del runtime di Microsoft Sentinel appropriato.




Nota
Se si seleziona il kernel, viene avviata la sessione Spark ed viene eseguito il codice nel notebook. Dopo aver selezionato il pool, l'avvio della sessione può richiedere 3-5 minuti. Successivamente viene eseguito più velocemente perché la sessione è già attiva.
All'avvio della sessione, il codice nel notebook viene eseguito e i risultati vengono visualizzati nel riquadro di output sotto la cella di codice, ad esempio: 
Per notebook di esempio che illustrano come interagire con il data lake Microsoft Sentinel, vedere Notebook di esempio per Microsoft Sentinel data lake.
Barra di stato
La barra di stato nella parte inferiore del notebook fornisce informazioni sullo stato corrente del notebook e sulla sessione Spark. La barra di stato include le informazioni seguenti:
Percentuale di utilizzo vCore per il pool Spark selezionato. Passare il puntatore del mouse sulla percentuale per visualizzare il numero di vCore usati e il numero totale di vCore disponibili nel pool. Le percentuali rappresentano l'utilizzo corrente nei carichi di lavoro interattivi e del processo per l'account connesso.
Stato della connessione della sessione Spark, ad esempio
Connecting,ConnectedoNot Connected.

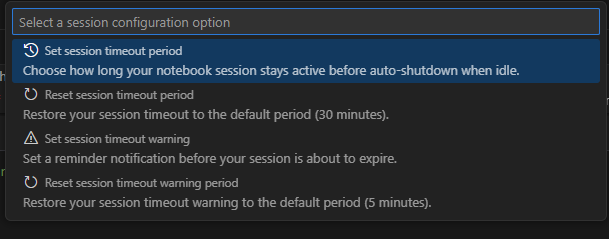
Impostare i timeout della sessione
È possibile impostare gli avvisi di timeout e timeout della sessione per i notebook interattivi. Queste impostazioni vengono mantenute nelle impostazioni dell'estensione in modo che vengano mantenute tra le sessioni.
Per modificare il timeout, selezionare lo stato della connessione nella barra di stato nella parte inferiore del notebook. Scegliere una delle seguenti opzioni:
Imposta periodo di timeout sessione: imposta il tempo in minuti prima del timeout della sessione. Il valore predefinito è 30 minuti.
Reimposta il periodo di timeout della sessione: reimposta il timeout della sessione sul valore predefinito di 30 minuti.
Imposta il periodo di avviso di timeout della sessione: imposta il tempo in minuti prima del timeout in cui viene visualizzato un avviso che indica che la sessione sta per scadere. Il valore predefinito è 5 minuti.
Reimpostare il periodo di avviso di timeout della sessione: reimposta l'avviso di timeout della sessione sul valore predefinito di 5 minuti.

Usare GitHub Copilot nei notebook
Usare GitHub Copilot per scrivere codice nei notebook. GitHub Copilot fornisce suggerimenti di codice e completamento automatico in base al contesto del codice. Per usare GitHub Copilot, assicurarsi di avere l'estensione GitHub Copilot installata in Visual Studio Code.
Copiare il codice dai notebook di esempio per Microsoft Sentinel data lake e salvarlo nella cartella notebook per fornire contesto per GitHub Copilot. GitHub Copilot sarà quindi in grado di suggerire i completamenti del codice in base al contesto del notebook.
L'esempio seguente illustra GitHub Copilot generazione di una revisione del codice.

Classe Provider Microsoft Sentinel
Per connettersi al data lake Microsoft Sentinel, usare la SentinelLakeProvider classe .
Questa classe fa parte del access_module.data_loader modulo e fornisce metodi per interagire con il data lake. Per usare questa classe, importarla e creare un'istanza della classe usando una spark sessione.
from sentinel_lake.providers import MicrosoftSentinelProvider
data_provider = MicrosoftSentinelProvider(spark)
Per altre informazioni sui metodi disponibili, vedere Microsoft Sentinel Riferimento alla classe Provider.
Selezionare il pool di runtime appropriato
Sono disponibili tre pool di runtime per eseguire i notebook di Jupyter nell'estensione Microsoft Sentinel. Ogni pool è progettato per carichi di lavoro e requisiti di prestazioni diversi. La scelta del pool di runtime influisce sulle prestazioni, sui costi e sul tempo di esecuzione dei processi Spark.
| Runtime Pool | Casi d'uso consigliati | Caratteristiche |
|---|---|---|
| Piccole dimensioni | Sviluppo, test e analisi esplorativa leggera. Carichi di lavoro di piccole dimensioni con trasformazioni semplici. L'efficienza dei costi è stata assegnata in ordine di priorità. |
Adatto per carichi di lavoro di piccole dimensioni Trasformazioni semplici. Costo inferiore, tempo di esecuzione più lungo. |
| Medium | Processi ETL con join, aggregazioni e training del modello di Machine Learning. Moderare i carichi di lavoro con trasformazioni complesse. |
Miglioramento delle prestazioni rispetto a Small. Gestisce il parallelismo e le operazioni con utilizzo moderato della memoria. |
| Grandi dimensioni | Carichi di lavoro di Apprendimento avanzato e Machine Learning. Rimescolamento completo dei dati, join di grandi dimensioni o elaborazione in tempo reale. Tempo di esecuzione critico. |
Memoria e potenza di calcolo elevate. Ritardi minimi. Ideale per carichi di lavoro di grandi dimensioni, complessi o sensibili al tempo. |
Nota
Al primo accesso, il caricamento delle opzioni del kernel potrebbe richiedere circa 30 secondi.
Dopo aver selezionato un pool di runtime, l'avvio della sessione può richiedere da 3 a 5 minuti.
Visualizzare messaggi, log ed errori
I log dei messaggi e i messaggi di errore vengono visualizzati in tre aree in Visual Studio Code.
Riquadro Output .
- Nel riquadro Output selezionare Microsoft Sentinel dall'elenco a discesa.
- Selezionare Debug per includere voci di log dettagliate.

I messaggi in linea nel notebook forniscono commenti e informazioni sull'esecuzione delle celle di codice. Questi messaggi includono gli aggiornamenti dello stato di esecuzione, gli indicatori di stato e le notifiche di errore correlate al codice nella cella precedente
Un popup di notifica nell'angolo inferiore destro di Visual Studio Code, noto anche come messaggio di tipo avviso popup, fornisce avvisi e aggiornamenti in tempo reale sullo stato delle operazioni all'interno del notebook e della sessione spark. Queste notifiche includono messaggi, avvisi e avvisi di errore, ad esempio connessione riuscita a una sessione Spark e avvisi di timeout.



Processi e pianificazione
È possibile pianificare l'esecuzione di processi in orari o intervalli specifici usando l'estensione Microsoft Sentinel per Visual Studio Code. I processi consentono di automatizzare le attività di elaborazione dati per riepilogare, trasformare o analizzare i dati nel data lake Microsoft Sentinel. I processi vengono usati anche per elaborare i dati e scrivere risultati in tabelle personalizzate nel livello data lake o nel livello di analisi. Per altre informazioni sulla creazione e la gestione dei processi, vedere Creare e gestire processi notebook di Jupyter.
Parametri e limiti del servizio per i notebook di VS Code
La sezione seguente elenca i parametri e i limiti del servizio per Microsoft Sentinel data lake quando si usano notebook di VS Code.
| Categoria | Parametro/limite |
|---|---|
| Tabella personalizzata nel livello di analisi | Le tabelle personalizzate nel livello di analisi non possono essere eliminate da un notebook. Usare Log Analytics per eliminare queste tabelle. Per altre informazioni, vedere Aggiungere o eliminare tabelle e colonne nei log di monitoraggio Azure |
| Timeout del web socket del gateway | 2 ore |
| Timeout delle query interattive | 2 ore |
| Timeout interattivo dell'inattività della sessione | 20 minuti |
| Lingua | Python |
| Timeout query graph | 7,5 minuti |
| Timeout processo notebook | 8 ore |
| Numero massimo di processi di notebook simultanei | 3, i processi successivi vengono accodati |
| Numero massimo di utenti simultanei nell'esecuzione di query interattive | 8-10 in pool grande |
| Ora di avvio della sessione | L'avvio della sessione di calcolo Spark richiede circa 5-6 minuti. È possibile visualizzare lo stato della sessione nella parte inferiore del blocco appunti di VS Code. |
| Librerie supportate | Solo Azure Synapse librerie 3.4 e la libreria provider di Microsoft Sentinel per le funzioni astratte sono supportate per l'esecuzione di query sul data lake. Le installazioni pip o le librerie personalizzate non sono supportate. |
| Limite dell'esperienza utente di VS Code per visualizzare i record | 100.000 righe |
Risoluzione dei problemi
Per gli errori e le soluzioni comuni quando si usano i notebook, vedere Risolvere i problemi relativi ai notebook nel data lake Microsoft Sentinel.
Contenuto correlato
- Risolvere i problemi relativi ai notebook nel data lake Microsoft Sentinel
- Creare e gestire processi notebook
- Notebook di esempio per Microsoft Sentinel data lake
- riferimento alla classe provider Microsoft Sentinel
- Panoramica di Microsoft Sentinel data lake
- Microsoft Sentinel i ruoli e le autorizzazioni del data lake.