Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Le pipeline di Azure Data Factory già alimentano flussi di lavoro critici. Questo articolo illustra come inserirli in Fabric per sbloccare un'esperienza più integrata e pronta per l'analisi. Questa esperienza di migrazione predefinita consente di modernizzare i carichi di lavoro Azure Data Factory esistenti in pochi semplici clic.
L'esperienza di migrazione consente di:
- Valutare l'idoneità della pipeline direttamente in Azure Data Factory.
- Informazioni sulle lacune di compatibilità a livello di pipeline e attività.
- Eseguire la migrazione delle pipeline supportate a un'area di lavoro Fabric.
- Pianificare i passaggi successivi per gli elementi che richiedono aggiornamenti o che saranno presto disponibili.
Questo approccio di valutazione consente di garantire che le migrazioni siano intenzionali, trasparenti e incrementali. È possibile aggiornare le pipeline in base al proprio ritmo e convalidare i risultati prima di passare ai carichi di lavoro di produzione.
Come avviare la migrazione
È possibile avviare la migrazione delle pipeline Azure Data Factory da uno dei due punti di ingresso:
| Punto di ingresso | Ideale per | Passaggio iniziale |
|---|---|---|
| From Azure Data Factory | Esecuzione di una valutazione completa dell'idoneità della pipeline prima della migrazione | Opzione A: Inizia da Azure Data Factory |
| Da un'area di lavoro Fabric | Montaggio diretto e migrazione quando si conosce già la factory da trasferire | Opzione B: Inizia da Fabric |
Entrambi i percorsi convergeno al passaggio 4: Eseguire la migrazione delle pipeline.
Prerequisiti
Prima di iniziare, assicurarsi di avere:
- Istanza di Azure Data Factory esistente con pipeline.
- Accesso a un tenant Microsoft Fabric.
- Un'area di lavoro Fabric nello stesso tenant Microsoft Entra ID dell'istanza di Azure Data Factory.
- Se si parte da Fabric: uno spazio di lavoro Fabric in cui si dispone almeno delle autorizzazioni di collaboratore.
Opzione A: Iniziare da Azure Data Factory
Passaggio 1: Valutare le tue pipeline per la migrazione
Per eseguire la valutazione della migrazione, nell'area del contenuto di Azure Data Factory selezionare Migra a Fabric (anteprima)>Inizia (anteprima) per valutare le pipeline e le attività per l'idoneità alla migrazione.

Passaggio 2: Esaminare e comprendere i risultati della valutazione
Sia la fabbrica che le singole pipeline sono categorizzate con uno stato di idoneità: Pronto, Necessita revisione, In arrivo o Non compatibile. È anche possibile esportare i risultati della valutazione in un file CSV per supportare la pianificazione della revisione e della correzione offline.

A ogni pipeline e attività viene assegnato uno degli stati seguenti. Usare questi risultati per pianificare la migrazione.
| Condizione | Meaning |
|---|---|
| Ready | La migrazione è completamente supportata e sicura. |
| Da rivedere | Richiede aggiornamenti secondari, ad esempio modifiche al parametro o alla configurazione. |
| Presto disponibile | Il supporto è pianificato, eseguire la migrazione in un secondo momento. |
| Non compatibile | Nessuna Fabric equivalente. Riprogettazione richiesta. |
Passaggio 3: Selezionare un'area di lavoro Fabric e montare il Azure Data Factory
Dopo aver esaminato la valutazione, selezionare Avanti per montare il Azure Data Factory in un'area di lavoro Fabric e continuare il flusso di migrazione in Fabric. Il montaggio consente di fare riferimento all'istanza di Azure Data Factory (ADF) all'interno di un'area di lavoro Fabric senza eseguire la migrazione, la copia o la modifica dell'ambiente Azure Data Factory.

Al termine del montaggio, selezionare Continue in Fabric per procedere con i passaggi di migrazione.

Passare al passaggio 4: Eseguire la migrazione delle pipeline.
Opzione B: Iniziare da Fabric
- Aprire l'area di lavoro di Fabric.
- Nella barra degli strumenti dell'area di lavoro selezionare Esegui migrazione.
- Nel pannello Migrare a Fabric, in Migrare a notebook, pool di Spark e altro, selezionare Data Factory.
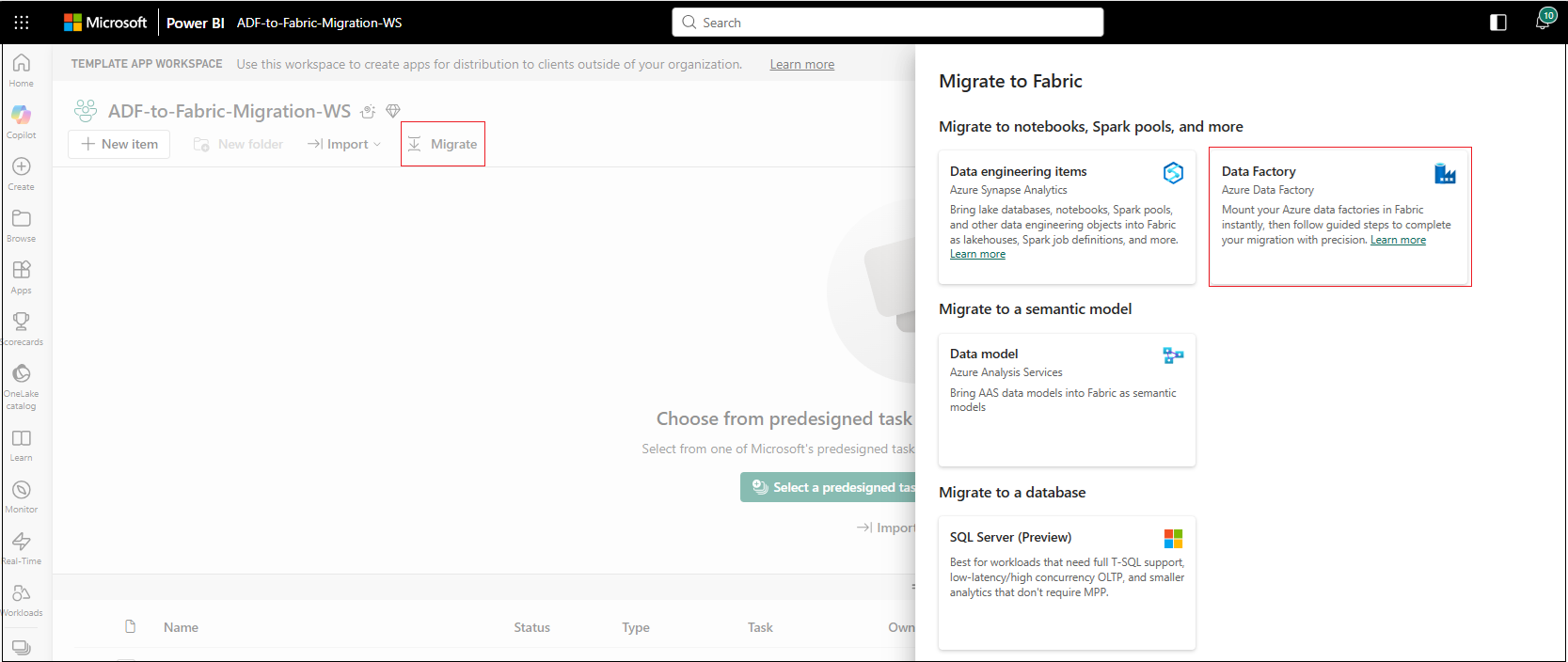
- Selezionare l'istanza di Azure Data Factory da montare in questa area di lavoro.
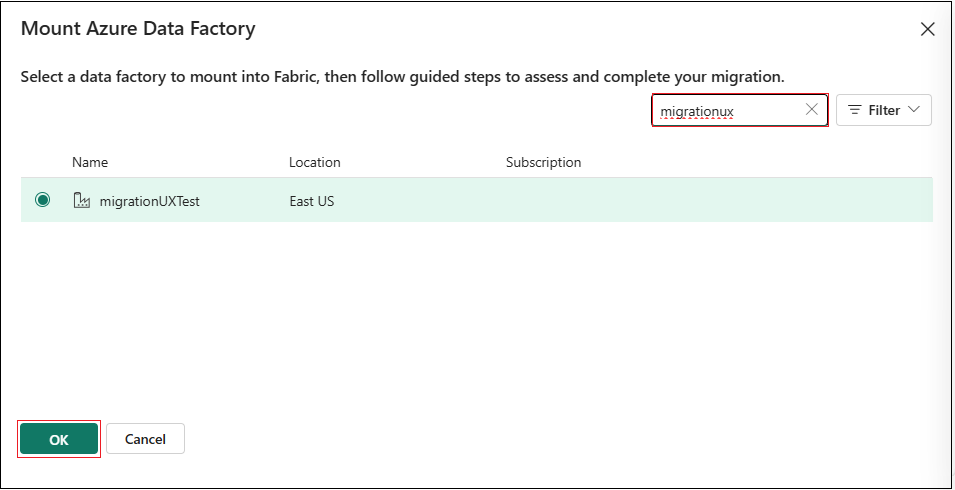
- Al termine del montaggio, continuare con il passaggio 4: Eseguire la migrazione delle pipeline.
Annotazioni
Partendo da Fabric salta la valutazione in ADF (passaggi 1–2). Per esaminare la conformità della pipeline prima della migrazione, iniziare da Pp 1: Valutare invece le pipeline per la migrazione in Azure Data Factory.
Passaggio 4: Eseguire la migrazione delle pipeline
Continuare la migrazione dall'esperienza di Fabric selezionando Migrate a Fabric (anteprima).

Selezionare le pipeline di cui si vuole eseguire la migrazione.

Passaggio 5: Eseguire il mapping dei servizi collegati alle connessioni Fabric e completare la migrazione
Selezionare Visualizzare le connessioni per eseguire il mapping dei servizi collegati Azure Data Factory alle connessioni Fabric e quindi selezionare Confirm.
L'esperienza di migrazione tenta di creare automaticamente connessioni per i metodi di autenticazione che possono essere mappati in modo sicuro e affidabile da Azure Data Factory al modello di sicurezza e identità gestita di Fabric senza richiedere l'infrastruttura gestita dal cliente o la configurazione di rete.

Connessioni create automaticamente durante la migrazione (solo supportate)
| Connettore | autenticazione Azure Data Factory | autenticazione dell'infrastruttura Fabric |
|---|---|---|
| Archiviazione BLOB di Azure (archiviazione di oggetti Blob di Azure) | Chiave dell'account; Firma di accesso condiviso (SAS - Signature Access Shared); Principale del servizio; Identità gestita assegnata dal sistema | Chiave dell'account; Firma di accesso condiviso (SAS); Entità servizio; Identità dell'area di lavoro (identità gestita assegnata dal sistema) |
| Azure Data Lake Storage Gen2 | Chiave dell'account; Firma di accesso condiviso (SAS - Signature Access Shared); Principale del servizio; Identità gestita assegnata dal sistema | Chiave dell'account; Firma di accesso condiviso (SAS); Entità servizio; Identità dell'area di lavoro (identità gestita assegnata dal sistema) |
| SQL Server | Autenticazione di base (autenticazione SQL); Entità principale del servizio; Identità gestita assegnata dal sistema | Autenticazione di base; Entità servizio; Identità dell'area di lavoro (identità gestita assegnata dal sistema) |
| database SQL di Azure | Autenticazione di base (autenticazione SQL); Entità principale del servizio; Identità gestita assegnata dal sistema | Autenticazione di base; Entità servizio; Identità dell'area di lavoro (identità gestita assegnata dal sistema) |
| Esplora dati di Azure (Kusto) | Principal del servizio; Identità gestita assegnata dal sistema | Entità servizio, identità dell'area di lavoro (identità gestita assegnata dal sistema) |
| Azure Cosmos DB per NoSQL | Chiave dell'account | Chiave dell'account |
| Azure Cosmos DB per MongoDB | Basic authentication | Basic authentication |
| Istanza gestita di SQL di Azure (Istanza gestita di Azure SQL) | Chiave dell'account, entità servizio | Autenticazione di base; Principale del servizio |
| Database di Azure per PostgreSQL | Basic authentication | Basic authentication |
| Database di Azure per MySQL | Basic authentication | Basic authentication |
| MySQL | Basic authentication | Basic authentication |
| PostgreSQL | Basic authentication | Basic authentication |
Per altre connessioni, selezionare una connessione Fabric esistente o creare nuove connessioni usando l'esperienza moderna Recupera dati o dalle impostazioni dell'area di lavoro. Selezionare quindi Conferma.
Questa azione avvia la migrazione delle pipeline selezionate alla cartella radice nell'area di lavoro Fabric. Al termine della migrazione viene visualizzato un messaggio di conferma.

Al termine della migrazione, passare all'area di lavoro Fabric per esaminare le pipeline migrate. Ogni pipeline viene creata nell'area di lavoro e preceduta dal nome della fabbrica di origine. È possibile aprire ogni pipeline per esaminarla e convalidarla prima di continuare con altre configurazioni o test.

Annotazioni
Se non si esegue il mapping di connessioni durante questo passaggio, le pipeline vengono comunque migrate. Le attività all'interno di tali pipeline vengono disattivate ed è possibile configurarle in un secondo momento in Fabric.
Al termine della migrazione, convalidare le pipeline nell'esperienza di Fabric Data Factory.
Comportamento della migrazione
- Le pipeline migrano in un'area di lavoro di Fabric Data Factory.
- I nomi delle pipeline devono essere univoci all'interno di un'area di lavoro.
- Se esiste già una pipeline con lo stesso nome, lo strumento di migrazione ignora tale pipeline.
- Per garantire l'univocità, le pipeline migrate usano il formato di denominazione seguente:
<Source factory or workspace name>_<Pipeline name>. - Il flusso di migrazione include una fase di montaggio che consente di visualizzare la struttura factory esistente in Fabric prima della migrazione.
Convalida post-migrazione
Dopo la migrazione, completare le attività seguenti:
- Convalidare tutte le connessioni e le credenziali.
- Ricreare i parametri globali come librerie di variabili.
- Riabilitare e configurare i trigger (disabilitati per impostazione predefinita).
- Eseguire test end-to-end per confermare il comportamento della pipeline.
- Convalidare le migrazioni in un ambiente non di produzione prima di eseguire la migrazione dei carichi di lavoro di produzione.
Che cosa non rientra nell'ambito
Gli elementi seguenti non sono attualmente supportati nell'esperienza di migrazione basata sull'esperienza utente. Le pipeline che usano queste funzionalità richiedono approcci di riprogettazione o migrazione alternativi.
| Categoria | Elemento esterno all'ambito | dettagli |
|---|---|---|
| Runtime di integrazione | Runtime di integrazione self-hosted | Non è possibile eseguire la migrazione dei runtime di integrazione self-hosted. Sostituire con il gateway dati locale (OPDG) di Fabric. |
| Runtime di integrazione della rete virtuale gestita (runtime di integrazione di rete virtuale gestita)/Runtime di integrazione inserito nella rete virtuale (rete virtuale) | Fabric non supporta la migrazione dei runtime di integrazione della rete virtuale gestita. Il Fabric gateway di rete virtuale usa un modello diverso e richiede la riconfigurazione. | |
| SQL Server Integration Services Integration Runtime (SSIS IR) | La migrazione dell'infrastruttura, inclusi i runtime di integrazione SQL Server Integration Services, non è supportata. | |
| tipi di carico di lavoro | Change Data Capture di Azure Data Factory | I carichi di lavoro di Change Data Capture non rientrano nell'ambito e non ne viene eseguita la migrazione. |
| Risorse di Apache Airflow | Non è possibile eseguire la migrazione dell'orchestrazione basata su grafico aciclico diretto da Apache Airflow a Fabric. | |
| U-SQL (Unified Structured Query Language) /Azure Data Lake Analytics | Servizi deprecati e non supportati in Fabric. | |
| Carichi di lavoro di aggiornamento tra cloud o Azure Machine Learning | Il supporto dell'identità dell'area di lavoro è in corso. Questi carichi di lavoro non vengono migrati. | |
| Connettori | Connettori a coda lunga (ad esempio, SAP ERP Central Component (ECC), SAP Business Warehouse (BW), Multidimensional Expressions (MDX), SAP Core Data Services (CDS)) | Fabric non dispone di connettori equivalenti. È necessaria la riprogettazione. |
| Connettori software come servizio per marketing e finanza (HubSpot, Google Ads, QuickBooks, Shopify, Xero) | Non supportato oggi. | |
| Trigger e orchestrazione | Trigger di eventi personalizzati | Non è possibile eseguire la migrazione di trigger di eventi personalizzati. |
| Attivatori di eventi di archiviazione | Il supporto sarà presto disponibile. | |
| Trigger periodici | Nota come Pianificazione Basata su Intervalli in Fabric. I carichi di lavoro limite e back-fill devono essere riprogettati. | |
| Trigger di collegamento o di dipendenza | La semantica dei trigger di concatenamento e di dipendenza non è ancora supportata. | |
| Sicurezza e autenticazione | Configurazioni avanzate (chiavi gestite dal cliente), token duali, flussi FIC (Federated Identity Credential) | I modelli di autenticazione dell'identità dell'area di lavoro o dell'entità servizio non supportati non vengono migrati. |
| Autenticazione basata su certificati (attività Web) | Non supportato e richiede la riprogettazione. | |
| Supporto dell'identità gestita assegnata dall'utente | Usare l'identità dell'area di lavoro (WI) come soluzione alternativa. | |
| Parametrizzazione e metadati | Parametri globali | Il supporto sarà presto disponibile. Ricreare utilizzando le librerie di variabili "Fabric". |
| Servizi collegati dinamici (connessioni con parametri) | Non supportato. Ogni permutazione deve essere una connessione separata e non può essere migrata. | |
| Pipeline guidate dai metadati | Non è possibile eseguire la migrazione di modelli basati su set di dati o servizi collegati altamente dinamici. | |
| Attività e calcolo | Definizione di un processo Spark di Azure Synapse o notebook | Parzialmente supportato. Richiede la riprogettazione nei notebook di Fabric o nei processi Spark. |
| Flussi di dati per mapping | Il supporto sarà presto disponibile. | |
| Attività Web, webhook o HTTP con autenticazione o intestazioni personalizzate | Gli scenari di autenticazione complessi devono essere ricompilati manualmente. | |
| Impostazioni dell'ambiente del pool di notebook | Non supportato. La migrazione è bloccata. | |
| Supporto dell'identità dell'area di lavoro delle attività batch o personalizzate | L'assenza del supporto per l'identità dell'area di lavoro blocca la migrazione per queste attività. | |
| Upsert dell'attività Copy nelle tabelle Lakehouse | Non supportato. Richiede la copia nell'area di gestione temporanea e un'operazione MERGE del notebook. |
Domande frequenti
La valutazione cambia la mia fabbrica?
No. La valutazione è di sola lettura. Analizza la configurazione della factory e presenta i risultati nel riquadro laterale senza modificare pipeline, attività o impostazioni. È possibile eseguirlo in modo sicuro per comprendere l'impatto della migrazione prima di eseguire qualsiasi azione.
È possibile rieseguire la valutazione o la migrazione dopo aver apportato modifiche?
Sì. È possibile rieseguire la valutazione in qualsiasi momento durante la convalida. Se si esegue nuovamente la migrazione per le stesse pipeline, è prima necessario eliminare le pipeline di cui è stata eseguita la migrazione in precedenza in Fabric, perché i nomi delle pipeline devono essere univoci all'interno di un'area di lavoro.
Il montaggio di Azure Data Factory esegue la migrazione delle mie pipeline?
No. Il montaggio è solo uno snapshot dell'istanza di Azure Data Factory esistente in un'area di lavoro Fabric. Non viene migrata alcuna pipeline fino a quando non si avvia esplicitamente la migrazione selezionando il pulsante Migra a Fabric (anteprima) dalla data factory montata in Fabric.
I trigger verranno migrati automaticamente?
I trigger di pianificazione vengono migrati automaticamente ma disabilitati dopo la migrazione in base alla progettazione. È necessario riabilitarli manualmente in Fabric. Tutti gli altri trigger devono essere riconfigurati manualmente e riabilitati in seguito alla convalida delle pipeline migrate.
Gli elementi non supportati bloccano l'intera migrazione?
No. Le attività non supportate influiscono solo sulle pipeline che le contengono. Altre pipeline supportate possono eseguire la migrazione in modo indipendente. La valutazione identifica chiaramente le pipeline che richiedono la riprogettazione.
È possibile eseguire la migrazione senza eseguire il mapping delle connessioni?
Sì. Le pipeline continuano a eseguire la migrazione, ma le attività che dipendono dalle connessioni non mappate vengono disattivate. È necessario configurare le connessioni necessarie di Fabric e riabilitare quelle attività prima di eseguire le pipeline.
È possibile convalidare le migrazioni prima di spostare i carichi di lavoro di produzione?
Sì. Microsoft consiglia di convalidare le migrazioni in un ambiente non di produzione, confermare connessioni, trigger ed esecuzione end-to-end prima della migrazione delle pipeline di produzione.
Quando alcune variabili di sistema si comportano in modo diverso in Fabric rispetto a Azure Data Factory?
Queste differenze sono previste man mano che le piattaforme si evolvono in modo indipendente e in genere possono essere risolte con una piccola regolazione durante la migrazione. Ad esempio, pipeline(). TriggerName è disponibile in Azure Data Factory ma non è attualmente supportato in Fabric Data Factory. Se la logica della pipeline dipende dal nome del trigger, è possibile usare i metadati dell'evento trigger supportati o passare il nome del trigger in modo esplicito come parametro della pipeline.