Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra come usare l'attività di copia nelle pipeline di Azure Data Factory e Synapse Analytics per copiare dati da e in Database di Azure per PostgreSQL. E come usare il flusso di dati per trasformare i dati in Database di Azure per PostgreSQL. Per altre informazioni, vedere gli articoli introduttivi per Azure Data Factory e Synapse Analytics.
Importante
La versione 2.0 di Azure Database per PostgreSQL offre un migliorato supporto nativo per Azure Database per PostgreSQL. Se si usa Database di Azure per PostgreSQL versione 1.0 nella soluzione, è consigliabile aggiornare il connettore database di Azure per PostgreSQL al più presto possibile.
Questo connettore è specializzato per il servizio Database di Azure per PostgreSQL. Per copiare i dati da un database PostgreSQL generico che si trova in locale o nel cloud, usare il connettore PostgreSQL.
Funzionalità supportate
Questo connettore di Database di Azure per PostgreSQL è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR | Endpoint privato gestito |
|---|---|---|
| Attività di copia (origine/sink) | ① ② | ✓ |
| Flusso di dati di mapping (origine/sink) | ① | ✓ |
| Attività di ricerca | ① ② | ✓ |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Le tre attività funzionano sul server singolo di Database di Azure per PostgreSQL, sul server flessibile e su Azure Cosmos DB per PostgreSQL.
Importante
Il server singolo di Database di Azure per PostgreSQL verrà ritirato il 28 marzo 2025. Eseguire la migrazione al server flessibile entro tale data. È possibile fare riferimento a questo articolo e domande frequenti per le indicazioni sulla migrazione.
Iniziare
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
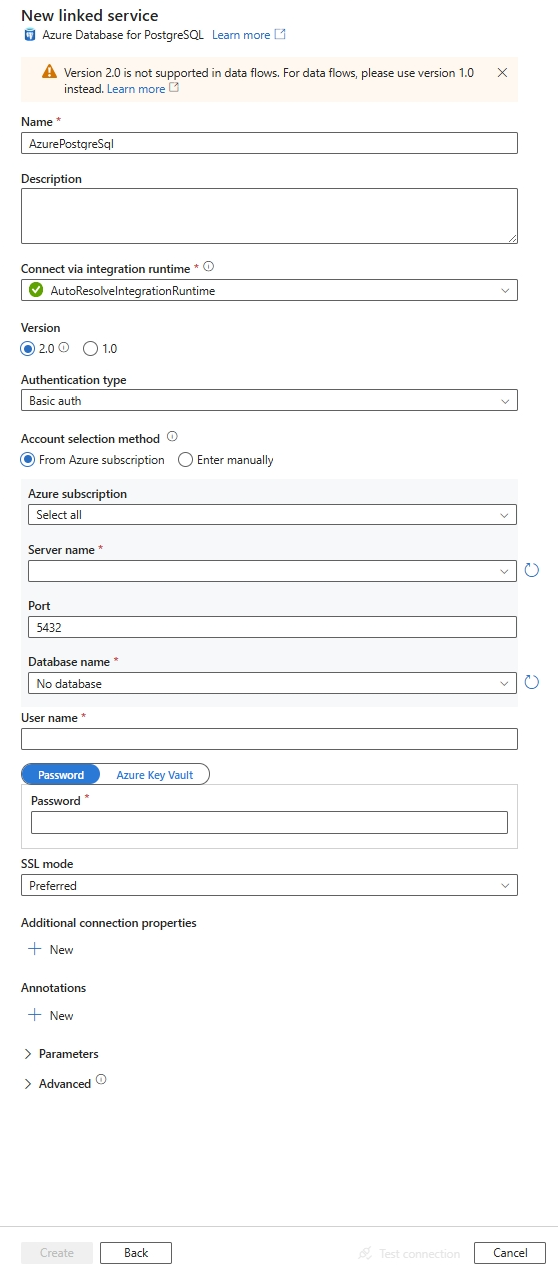
Creare un servizio collegato a Database di Azure per PostgreSQL tramite l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a Database di Azure per PostgreSQL nell'interfaccia utente del portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi selezionare Nuovo:
Cercare PostgreSQL e selezionare il connettore di Database di Azure per PostgreSQL.

Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti offrono informazioni dettagliate sulle proprietà usate per definire entità di Data Factory specifiche del connettore di Database di Azure per PostgreSQL.
Proprietà del servizio collegato
Il connettore Database di Azure per PostgreSQL versione 2.0 supporta le modalità Tls (Transport Layer Security) 1.3 e SSL (Secure Socket Layer). Fare riferimento a questa sezione per aggiornare la versione del connettore di database SQL di Azure dalla versione 1.0. Per informazioni dettagliate sulla proprietà, vedere le sezioni corrispondenti.
Versione 2.0
Quando si applica la versione 2.0, sono supportate le proprietà seguenti per il servizio collegato Database di Azure per PostgreSQL:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type deve essere impostata su: AzurePostgreSql. | Sì |
| versione | Versione specificata. Il valore è 2.0. |
Sì |
| tipo di autenticazione | Selezionare tra i tipi di autenticazione per identità gestita di base, entità servizio, identità gestita assegnata dal sistema o identità gestita assegnata dall'utente | Sì |
| server | Specifica il nome host e facoltativamente la porta in cui è in esecuzione Database di Azure per PostgreSQL. | Sì |
| porto | Porta TCP del server Azure per il database PostgreSQL. Il valore predefinito è 5432. |
NO |
| banca dati | Nome del database di Azure per PostgreSQL a cui connettersi. | Sì |
| sslMode | Controlla se viene usato SSL, a seconda del supporto del server. - Disabilita: SSL è disabilitato. Se il server richiede SSL, la connessione non riesce. - Consenti: preferisce le connessioni non SSL se il server le consente, ma consente le connessioni SSL. - Preferenza: preferisce le connessioni SSL se il server le consente, ma consente le connessioni senza SSL. - Richiedi: la connessione non riesce se il server non supporta SSL. - Verify-ca: la connessione non riesce se il server non supporta SSL. Verifica anche il certificato del server. - Verifica completa: la connessione non riesce se il server non supporta SSL. Verifica anche il certificato del server con il nome dell'host. Opzioni: Disabilita (0) / Consenti (1) / Preferisci (2) (impostazione predefinita) / Richiedi (3) / Verify-ca (4) / Verify-full (5) |
NO |
| connectVia | Questa proprietà rappresenta il runtime di integrazione da usare per connettersi all'archivio dati. È possibile usare il runtime di integrazione di Azure o il runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | NO |
| Proprietà di connessione aggiuntive: | ||
| schema | Imposta il percorso di ricerca dello schema. | NO |
| raggruppamento | Indica se usare il pool di connessioni. | NO |
| connectionTimeout | Tempo di attesa (in secondi) durante il tentativo di stabilire una connessione prima di terminare il tentativo e generare un errore. | NO |
| commandTimeout | Tempo di attesa (in secondi) durante il tentativo di esecuzione di un comando prima di terminare il tentativo e generare un errore. Impostare su zero per infinito. | NO |
| trustServerCertificate | Se considerare attendibile il certificato del server senza convalidarlo. | NO |
| dimensione del buffer di lettura (readBufferSize) | Determina le dimensioni del buffer interno usato da Npgsql durante la lettura. L'aumento può migliorare le prestazioni se si trasferiscono valori di grandi dimensioni dal database. | NO |
| fuso orario | Ottiene o imposta il fuso orario della sessione. | NO |
| codifica | Ottiene o imposta la codifica .NET per la codifica/decodifica dei dati stringa PostgreSQL. | NO |
Autenticazione di base
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| nome utente | Nome utente con cui connettersi. Non obbligatorio se si usa IntegratedSecurity. | Sì |
| parola d’ordine | Password con cui connettersi. Non obbligatorio se si usa IntegratedSecurity. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro. In alternativa, fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
Esempio:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Esempio:
Archiviare la password in Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Autenticazione dell'identità gestita assegnata dal sistema
Una data factory o un'area di lavoro di Synapse può essere associata a un'identità gestita assegnata dal sistema che rappresenta il servizio durante l'autenticazione ad altre risorse in Azure. È possibile usare questa identità gestita per l'autenticazione di Database di Azure per PostgreSQL. L'area di lavoro designata factory o Synapse può accedere e copiare dati da o nel database usando questa identità.
Per usare l'identità gestita assegnata dal sistema, seguire questa procedura:
Una data factory o un'area di lavoro di Synapse può essere associata a un'identità gestita assegnata dal sistema. Altre informazioni, Generare un'identità gestita assegnata dal sistema
Dati di Azure per PostgreSQL con identità gestita assegnata dal sistema Attivo.

Nella risorsa database di Azure per PostgreSQL in Sicurezza
Seleziona Autenticazione
Selezionare solo l'autenticazione di Microsoft Entra o postgreSQL e il metodo di autenticazione Microsoft Entra .
Selezionare + Aggiungi amministratori di Microsoft Entra
Aggiungere l'identità gestita assegnata dal sistema per la risorsa Azure Data Factory come uno degli amministratori di Microsoft Entra

Configurare un servizio collegato di Database di Azure per PostgreSQL.


Esempio:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "SystemAssignedManagedIdentity"
}
}
}
Annotazioni
Questo tipo di autenticazione non è supportato nel runtime di integrazione self-hosted.
Autenticazione dell'identità gestita assegnata dall'utente
Una data factory o un'area di lavoro di Synapse può essere associata a un'identità gestita assegnata dall'utente che rappresenta il servizio durante l'autenticazione ad altre risorse in Azure. È possibile usare questa identità gestita per l'autenticazione di Database di Azure per PostgreSQL. L'area di lavoro designata factory o Synapse può accedere e copiare dati da o nel database usando questa identità.
Per usare l'autenticazione dell'identità gestita assegnata dall'utente, oltre alle proprietà generiche descritte nella sezione precedente, specificare le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| credenziali | Specificare l'identità gestita assegnata dall'utente come oggetto credenziale. | Sì |
È anche necessario seguire i passaggi seguenti:
Assicurarsi di creare una risorsa di Identità gestita assegnata dall'utente sul portale di Azure. Per altre informazioni, vedere Gestire le identità gestite assegnate dall'utente
Assegnare l'identità gestita assegnata dall'utente alla risorsa Database di Azure per PostgreSQL
Nella risorsa del database di Azure per il server PostgreSQL, in Sicurezza
Seleziona Autenticazione
Verificare se il metodo di autenticazione è solo Microsoft Entra o PostgreSQL e Microsoft Entra
Selezionare il collegamento + Aggiungi amministratori di Microsoft Entra e selezionare l'identità gestita assegnata dall'utente

Assegnare l'identità gestita assegnata dall'utente alla risorsa di Azure Data Factory
Selezionare Impostazioni e quindi Identità gestite
Nella scheda Assegnata dall'utente . Selezionare il collegamento + Aggiungi e selezionare l'identità gestita dall'utente

Configurare un servizio collegato di Database di Azure per PostgreSQL.


Esempio:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "<your credential>",
"type": "CredentialReference"
}
}
}
}
Autenticazione di un'entità servizio
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| nome utente | Nome visualizzato dell'entità servizio. | Sì |
| inquilino | Il tenant in cui si trova il server di database di Azure per PostgreSQL | Sì |
| ID Principale del Servizio (servicePrincipalId) | ID applicazione dell'entità servizio | Sì |
| tipo di credenziale del servizio principale | Selezionare se il certificato dell'entità servizio o la chiave dell'entità servizio è il metodo di autenticazione desiderato - ServicePrincipalCert: impostato come certificato dell'entità servizio per il certificato dell'entità servizio. - ServicePrincipalKey: Impostala come chiave dell'entità servizio per l'autenticazione della chiave dell'entità di servizio. |
Sì |
| chiavePrincipaleDelServizio | Valore del segreto client. Usato quando è selezionata la chiave dell'entità servizio | Sì |
| azureCloudType | Selezionare il tipo di cloud di Azure del server di Database di Azure per PostgreSQL | Sì |
| servicePrincipalEmbeddedCert | File del certificato dell'entità servizio | Sì |
| servicePrincipalEmbeddedCertPassword | Password del certificato dell'entità servizio, se necessario | NO |
Esempio:
chiave dell'entità servizio
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalKey": "<service principal key>"
}
}
}
Esempio:
Certificato dell'entità servizio
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalEmbeddedCert": "<service principal certificate>",
"servicePrincipalEmbeddedCertPassword": "<service principal embedded certificate password>"
}
}
}
Annotazioni
L'autenticazione Microsoft Entra ID utilizzando l'entità servizio e l'identità gestita assegnata dall'utente è supportata nel runtime di integrazione autogestito versione 5.50 o successiva.
Versione 1.0
Le proprietà seguenti sono supportate per il servizio collegato Database di Azure per PostgreSQL quando si applica la versione 1.0:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type deve essere impostata su: AzurePostgreSql. | Sì |
| versione | Versione specificata. Il valore è 1.0. |
Sì |
| stringa di connessione | Stringa di connessione Npgsql per connettersi a Database di Azure per PostgreSQL. È anche possibile inserire una password in Azure Key Vault ed eseguire il pull della configurazione password all'esterno della stringa di connessione. Vedere gli esempi seguenti e Archiviare le credenziali in Azure Key Vault per altri dettagli. |
Sì |
| connectVia | Questa proprietà rappresenta il runtime di integrazione da usare per connettersi all'archivio dati. È possibile usare il runtime di integrazione di Azure o il runtime di integrazione self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | NO |
Una stringa di connessione tipica è host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>. Altre proprietà che è possibile impostare in base al caso sono riportate qui di seguito:
| Proprietà | Descrizione | Opzioni | Obbligatoria |
|---|---|---|---|
| EncryptionMethod (EM) | Il metodo usato dal driver per crittografare i dati inviati tra il driver e il server di database. Ad esempio, EncryptionMethod=<0/1/6>; |
0 (Nessuna crittografia) (impostazione predefinita) / 1 (SSL) / 6 (RequestSSL) | NO |
| ValidateServerCertificate (VSC) | Determina se il driver convalida il certificato inviato dal server di database quando la crittografia SSL è abilitata (Metodo di crittografia = 1). Ad esempio, ValidateServerCertificate=<0/1>; |
0 (disabilitato) (impostazione predefinita) / 1 (abilitato) | NO |
Esempio:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>"
}
}
}
Esempio:
Archiviare la password in Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere Set di dati. Questa sezione presenta un elenco di proprietà supportate da Database di Azure per PostgreSQL nei set di dati.
Per copiare dati dal Database di Azure per PostgreSQL, impostare la proprietà type del set di dati su AzurePostgreSqlTable. Sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type del set di dati deve essere impostata su AzurePostgreSqlTable. | Sì |
| schema | Nome dello schema. | No (se nell'origine dell'attività è specificato "query") |
| tabella | Nome della tabella/vista. | No (se nell'origine dell'attività è specificato "query") |
| tableName | Nome della tabella. Questa proprietà è supportata per garantire la compatibilità con le versioni precedenti. Per i nuovi carichi di lavoro, usare schema e table. |
No (se nell'origine dell'attività è specificato "query") |
Esempio:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Proprietà dell'attività Copy
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere Pipeline e attività. Questa sezione presenta un elenco di proprietà supportate da un database Azure per PostgreSQL.
Database di Azure per PostgreSQL come origine
Per copiare i dati da un Database di Azure per PostgreSQL, impostare il tipo di origine nell'attività di copia su AzurePostgreSqlSource. Nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type dell'origine dell'attività Copy deve essere impostata su AzurePostgreSqlSource | Sì |
| quesito | Usare la query SQL personalizzata per leggere i dati. Ad esempio, SELECT * FROM mytable o SELECT * FROM "MyTable". Si noti che il nome dell'entità in PostgreSQL viene considerato senza distinzione maiuscole/minuscole se non è racchiuso tra virgolette. |
No (se è specificata la proprietà tableName in un set di dati) |
| queryTimeout | Il tempo di attesa prima di terminare il tentativo di eseguire un comando e generare un errore, il valore predefinito è 120 minuti. Se il parametro è impostato per questa proprietà, i valori consentiti sono timepan, ad esempio "02:00:00" (120 minuti). Per altre informazioni, vedere CommandTimeout. | NO |
| opzioniDiPartizione | Specifica le opzioni di partizionamento dei dati usate per caricare dati dal database SQL di Azure. Valori consentiti: None (predefinito), PhysicalPartitionsOfTable e DynamicRange. Quando è abilitata un'opzione di partizione (diversa da None), il grado di parallelismo per caricare simultaneamente i dati da un database SQL di Azure è controllato dall'impostazione parallelCopies nell'attività di copia. |
NO |
| impostazioni di partizione | Specifica il gruppo di impostazioni per il partizionamento dei dati. Applicare quando l'opzione di partizione non è None. |
NO |
Si trova in partitionSettings: |
||
| nomi delle partizioni | Elenco di partizioni fisiche da copiare. Si applica quando l'opzione di partizione è PhysicalPartitionsOfTable. Se si usa una query per recuperare i dati di origine, associare ?AdfTabularPartitionName nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Database di Azure per PostgreSQL. |
NO |
| partitionColumnName | Specificare il nome della colonna di origine nel tipo integer o data/datetime (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone, o time without time zone) che verrà usato nel partizionamento per intervalli per la copia parallela. Se non specificato, la chiave primaria della tabella viene rilevata automaticamente e usata come colonna di partizione.Si applica quando l'opzione di partizione è DynamicRange. Se si usa una query per recuperare i dati di origine, associare ?AdfRangePartitionColumnName nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Database di Azure per PostgreSQL. |
NO |
| limite superiore di partizione | Valore massimo della colonna della partizione per la copia dei dati. Si applica quando l'opzione di partizione è DynamicRange. Se si usa una query per recuperare i dati di origine, associare ?AdfRangePartitionUpbound nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Database di Azure per PostgreSQL. |
NO |
| partitionLowerBound | Il valore minimo della colonna di partizione per esportare dati. Si applica quando l'opzione di partizione è DynamicRange. Se si usa una query per recuperare i dati di origine, associare ?AdfRangePartitionLowbound nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Database di Azure per PostgreSQL. |
NO |
Esempio:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Database di Azure per PostgreSQL come sink
Per copiare i dati in Database di Azure per PostgreSQL, nella sezione sinkdell'attività Copy sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type del sink dell'attività di copia deve essere impostata su AzurePostgreSqlSink. | Sì |
| preCopyScript | Specificare una query SQL per l'attività di copia da eseguire prima di scrivere i dati nel database di Azure per PostgreSQL in ogni esecuzione. È possibile usare questa proprietà per pulire i dati precaricati. | NO |
| writeMethod | Metodo usato per scrivere i dati in Database di Azure per PostgreSQL. I valori consentiti sono i seguenti: CopyCommand (impostazione predefinita, in grado di fornire maggiori prestazioni), BulkInsert. |
NO |
| writeBatchSize | Il numero di righe caricate nel database di Azure per PostgreSQL per batch. Il valore consentito è un numero intero che rappresenta il numero di righe. |
No, il valore predefinito è 1.000.000 |
| writeBatchTimeout | Tempo di attesa per l'operazione di inserimento batch da completare prima del timeout. I valori consentiti sono le stringhe Timespan. Ad esempio "00:30:00" (30 minuti). |
No, il valore predefinito è 00:30:00 |
Esempio:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSqlSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Copia parallela dal database di Azure per PostgreSQL
Il connettore di Database di Azure per PostgreSQL nell'attività di copia fornisce un partizionamento dei dati integrato per copiare i dati in parallelo. È possibile trovare le opzioni di partizionamento dei dati nella tabella Origine dell'attività di copia.

Quando si abilita la copia partizionata, l'attività Copy esegue query parallele sull'origine di Database di Azure per PostgreSQL per caricare i dati in base alle partizioni. Il grado di parallelismo è controllato dall'impostazione parallelCopies sull'attività di copia. Se, ad esempio, si imposta parallelCopies su quattro, il servizio genera ed esegue simultaneamente quattro query basate sull'opzione di partizione e sulle impostazioni specificate e ogni query recupera una porzione di dati da Database di Azure per PostgreSQL.
È consigliabile abilitare la copia parallela con il partizionamento dei dati, soprattutto quando si caricano grandi quantità di dati dal database di Azure per PostgreSQL. Di seguito sono riportate le configurazioni consigliate per i diversi scenari: Quando si copiano dati in un archivio dati basato su file, è consigliabile scrivere in una cartella come più file (specificare solo il nome della cartella), nel qual caso le prestazioni sono migliori rispetto alla scrittura in un singolo file.
| Sceneggiatura | Impostazioni consigliate |
|---|---|
| Caricamento completo da una tabella di grandi dimensioni, con partizioni fisiche. | Opzione di partizione: partizioni fisiche della tabella. Durante l'esecuzione, il servizio rileva automaticamente le partizioni fisiche e copia i dati in base alle partizioni. |
| Caricamento completo da una tabella di grandi dimensioni, senza partizioni fisiche, con una colonna di numeri interi per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Colonna di partizione: specificare la colonna usata per il partizionamento dei dati. Se non è specificato, viene usata la colonna della chiave primaria. |
| Caricare una grande quantità di dati usando una query personalizzata, con partizioni fisiche. | Opzione di partizione: partizioni fisiche della tabella. Query: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Nome partizione: specificare uno o più nomi di partizione da cui copiare i dati. Se non specificato, il servizio rileva automaticamente le partizioni fisiche nella tabella specificata nel set di dati PostgreSQL. Durante l'esecuzione, il servizio sostituisce ?AdfTabularPartitionName con il nome effettivo della partizione e lo invia a Database di Azure per PostgreSQL. |
| Caricare una grande quantità di dati usando una query personalizzata, senza partizioni fisiche, con una colonna di numeri interi per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Query: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Colonna di partizione: specificare la colonna usata per il partizionamento dei dati. È possibile eseguire la partizione rispetto alla colonna con un tipo di dati integer o date/datetime. Limite superiore della partizione e limite inferiore della partizione: specificare se si desidera filtrare in base alla colonna di partizione per recuperare i dati solo tra l'intervallo inferiore e quello superiore. Durante l'esecuzione, il servizio sostituisce ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbounde ?AdfRangePartitionLowbound con il nome della colonna e gli intervalli di valori effettivi per ogni partizione e li invia a Database di Azure per PostgreSQL. Ad esempio, se la colonna di partizione "ID" viene impostata con il limite inferiore come 1 e il limite superiore come 80, con copia parallela impostata su 4, il servizio recupera i dati per quattro partizioni. Gli ID sono rispettivamente compresi tra [1, 20], [21, 40], [41, 60] e [61, 80]. |
Procedure consigliate per il caricamento di dati con opzione partizione:
- Scegliere una colonna distintiva come colonna partizione (ad esempio, chiave primaria o chiave univoca) per evitare l'asimmetria dei dati.
- Se la tabella include una partizione predefinita, usare l'opzione di partizione "Partizioni fisiche della tabella" per ottenere prestazioni migliori.
- Se si utilizza Azure Integration Runtime per copiare i dati, è possibile impostare "Unità di integrazione dati (DIU)" (>4) per utilizzare più risorse di calcolo. Controllare gli scenari applicabili.
- "Grado di parallelismo di copia" controlla i numeri di partizione, impostando questo numero troppo grande qualche tempo fa male alle prestazioni. È consigliabile impostare questo numero come (DIU o numero di nodi del runtime di integrazione self-hosted) * (da 2 a 4).
Esempio: caricamento completo da una tabella di grandi dimensioni con partizioni fisiche
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Esempio: query con partizionamento per intervalli dinamici
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Proprietà di mappatura del flusso di dati
Durante la trasformazione dei dati in un flusso di dati di mapping, è possibile leggere e scrivere nelle tabelle di Database di Azure per PostgreSQL. Per altre informazioni, vedere la trasformazione origine e la trasformazione sink nei flussi di dati per mapping. È possibile scegliere di usare un set di dati PostgreSQL nel Database di Azure o un set di dati inline come tipo di origine e destinazione.
Annotazioni
Attualmente è supportata solo l'autenticazione di base per le versioni V1 e V2 del connettore Database di Azure per PostgreSQL nei flussi di dati di mapping.
Trasformazione della sorgente
La tabella seguente elenca le proprietà supportate dalla sorgente di Azure Database per PostgreSQL. È possibile modificare queste proprietà nella scheda Opzioni origine.
| Nome | Descrizione | Obbligatoria | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Tabella | Se si seleziona Tabella come input, il flusso di dati recupera tutti i dati dalla tabella specificata nel set di dati. | NO | - | (solo per set di dati inline) tableName |
| Quesito | Se si seleziona Query come input, specificare una query SQL per recuperare i dati dall'origine, il che esegue l'override di ogni tabella specificata nel set di dati. L'uso delle query è un ottimo metodo per ridurre il numero di righe per test o ricerche. La clausola Order By non è supportata, ma è possibile impostare un'istruzione SELECT FROM completa. È possibile usare anche funzioni di tabella definite dall'utente. select * from udfGetData() è una funzione utente in SQL che restituisce una tabella possibile da usare nel flusso di dati. Esempio di query: select * from mytable where customerId > 1000 and customerId < 2000 o select * from "MyTable". Si noti che il nome dell'entità in PostgreSQL viene considerato senza distinzione maiuscole/minuscole se non è racchiuso tra virgolette. |
NO | string | quesito |
| Nome schema | Se si seleziona una procedura memorizzata come input, specificare un nome dello schema della procedura memorizzata, oppure selezionare Scopri per chiedere al servizio di individuare i nomi dello schema. | NO | string | schemaName |
| procedura memorizzata | Se si seleziona Stored procedure come input, specificare un nome della stored procedure per leggere i dati dalla tabella di origine, oppure selezionare Aggiorna per chiedere al servizio di individuare i nomi delle procedure. | Sì, se si seleziona Stored procedure come input | string | procedureName |
| Parametri della procedura | Se si seleziona Stored procedure come input, specificare i parametri di input per la stored procedure nell'ordine impostato nella procedura, oppure selezionare Importa per importare tutti i parametri della procedura usando il modulo @paraName. |
NO | Array | inputs |
| Dimensioni dei batch | Specificare una dimensione del batch per suddividere i dati di grandi dimensioni in batch. | NO | Integer | dimensione del batch |
| Livello di isolamento | Scegliere uno dei livelli di isolamento seguenti: - Read Committed - Read Uncommitted (impostazione predefinita) - Lettura ripetibile -Serializzabile - Nessuno (ignora il livello di isolamento) |
NO | READ_COMMITTED READ_UNCOMMITTED LETTURA RIPETIBILE SERIALIZABLE NESSUNO |
livello di isolamento |
Esempio di script di origine di Database di Azure per PostgreSQL
Quando si usa Database di Azure per PostgreSQL come tipo di origine, lo script del flusso di dati associato è il seguente:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Trasformazione sink
La tabella seguente elenca le proprietà supportate dal sink di Database di Azure per PostgreSQL. È possibile modificare queste proprietà nella scheda Opzioni sink.
| Nome | Descrizione | Obbligatoria | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Metodo di aggiornamento | Specificare le operazioni consentite nella destinazione del database. Per impostazione predefinita, sono consentiti solo gli inserimenti. Per operazioni di aggiornamento, upsert o eliminazione di righe, è necessaria una trasformazione Altera riga perché i tag siano applicati alle righe per queste azioni. |
Sì | true oppure false |
eliminabile insertable aggiornabile upsertable |
| Colonne chiave | Per gli aggiornamenti, gli upsert e le eliminazioni, è necessario impostare le colonne chiave per determinare quale riga modificare. Il nome della colonna selezionato come chiave viene utilizzato come parte dell'aggiornamento, upsert e dell'eliminazione successiva. Pertanto, è necessario selezionare una colonna esistente nella mappatura Sink. |
NO | Array | chiavi |
| Salta la scrittura delle colonne chiave | Se si desidera non scrivere il valore nella colonna chiave, selezionare "Ignora la scrittura di colonne chiave". | NO | true oppure false |
skipKeyWrites |
| Azione Tabella | Determina se ricreare o rimuovere tutte le righe dalla tabella di destinazione prima della scrittura. - Nessuno: non viene eseguita alcuna azione per la tabella. - Ricrea: la tabella viene eliminata e ricreata. Questa opzione è obbligatoria se si crea una nuova tabella in modo dinamico. - Truncate: tutte le righe della tabella di destinazione vengono rimosse. |
NO | true oppure false |
ricreare truncate |
| Dimensioni dei batch | Specificare il numero di righe scritte in ogni batch. Le dimensioni batch più grandi migliorano la compressione e l'ottimizzazione della memoria, ma possono comportare il rischio di eccezioni di memoria insufficiente durante la memorizzazione nella cache dei dati. | NO | Integer | dimensione del batch |
| Selezionare lo schema del database utente | Per impostazione predefinita, viene creata una tabella temporanea nello schema sink come staging. In alternativa, è possibile deselezionare l'opzione Usa schema sink e specificare invece un nome di schema in cui Data Factory crea una tabella di staging per caricare i dati upstream e pulirli automaticamente al completamento. Assicurarsi di disporre dell'autorizzazione create table nel database e di modificare l'autorizzazione per lo schema. | NO | string | stagingSchemaName |
| Pre e post-script SQL | Specificare script SQL su più righe che verranno eseguiti prima (pre-elaborazione) e dopo la scrittura dei dati (post-elaborazione) nel database Sink. | NO | string | preSQLs postSQLs |
Suggerimento
- Dividere gli script batch singoli con più comandi in più batch.
- Possono essere eseguite come parte di un batch solo le istruzioni DDL (Data Definition Language) e DML (Data Manipulation Language) che restituiscono un semplice conteggio di aggiornamento. Per altre informazioni, vedere Esecuzione di operazioni batch
Abilita estrazione incrementale: usare questa opzione per indicare ad ADF di elaborare solo le righe modificate dall'ultima esecuzione della pipeline.
Colonna incrementale: quando si usa la funzionalità di estrazione incrementale, è necessario scegliere la colonna data/ora o numerica da usare come filigrana nella tabella di origine.
Iniziare a leggere dall'inizio: l'impostazione di questa opzione con l'estrazione incrementale indica ad ADF di leggere tutte le righe alla prima esecuzione di una pipeline con l'estrazione incrementale attivata.
Esempio di script del sink di Database di Azure per PostgreSQL
Quando si usa Database di Azure per PostgreSQL come tipo di sink, lo script del flusso di dati associato è il seguente:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSqlSink
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività di Ricerca.
Aggiornare il connettore Database di Azure per PostgreSQL
Nella pagina Modifica servizio collegato selezionare 2.0 in Versione e configurare il servizio collegato facendo riferimento alle proprietà del servizio collegato versione 2.0.
Contenuto correlato
Per un elenco degli archivi dati supportati dall'attività di copia come origini e destinazioni, vedere Archivi dati supportati.