Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il linguaggio di query Kusto (KQL) include funzioni predefinite di rilevamento e previsione anomalie per verificare il comportamento anomalo. Dopo aver rilevato un modello di questo tipo, è possibile eseguire un'analisi della causa radice per attenuare o risolvere l'anomalia.
Il processo di diagnosi è complesso e lungo e fatto da esperti di dominio. Il processo include:
- Recupero e unione di più dati da origini diverse per lo stesso intervallo di tempo
- Ricerca di modifiche nella distribuzione dei valori in più dimensioni
- Creazione di un grafico di altre variabili
- Altre tecniche basate sulla conoscenza e sull'intuizione del dominio
Poiché questi scenari di diagnosi sono comuni, i plug-in di Machine Learning sono disponibili per semplificare la fase di diagnosi e ridurre la durata dell'RCA.
Tutti e tre i plug-in di Machine Learning seguenti implementano algoritmi di clustering: autocluster, baskete diffpatterns. I autocluster plug-in e basket raggruppano un singolo set di record e il diffpatterns plug-in raggruppa le differenze tra due set di record.
Clustering di un singolo set di record
Uno scenario comune include un set di dati selezionato da criteri specifici, ad esempio:
- Intervallo di tempo che mostra un comportamento anomalo
- Letture dei dispositivi ad alta temperatura
- Comandi di durata prolungata
- Utenti con spesa superiore
Si vuole un modo semplice e rapido per trovare modelli comuni (segmenti) nei dati. I modelli sono un subset del set di dati i cui record condividono gli stessi valori su più dimensioni (colonne categoriche).
La query seguente compila e mostra una serie temporale di eccezioni del servizio nel periodo di una settimana, in contenitori di dieci minuti:
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")

Il numero di eccezioni del servizio è correlato al traffico complessivo del servizio. È possibile vedere chiaramente il modello giornaliero per i giorni lavorativi, da lunedì a venerdì. C'è un aumento dei conteggi delle eccezioni di servizio a mezzogiorno e un calo dei conteggi durante la notte. I conteggi bassi rimangono stabili durante il fine settimana. È possibile rilevare picchi di eccezioni usando il rilevamento anomalie delle serie temporali.
Il secondo picco dei dati si verifica martedì pomeriggio. La query seguente viene utilizzata per diagnosticare e verificare se si tratta di un picco improvviso. La query ridisegna il grafico attorno al picco in una risoluzione più alta, rappresentando l'intervallo di otto ore in sezioni di un minuto. È quindi possibile esaminare i suoi confini.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")
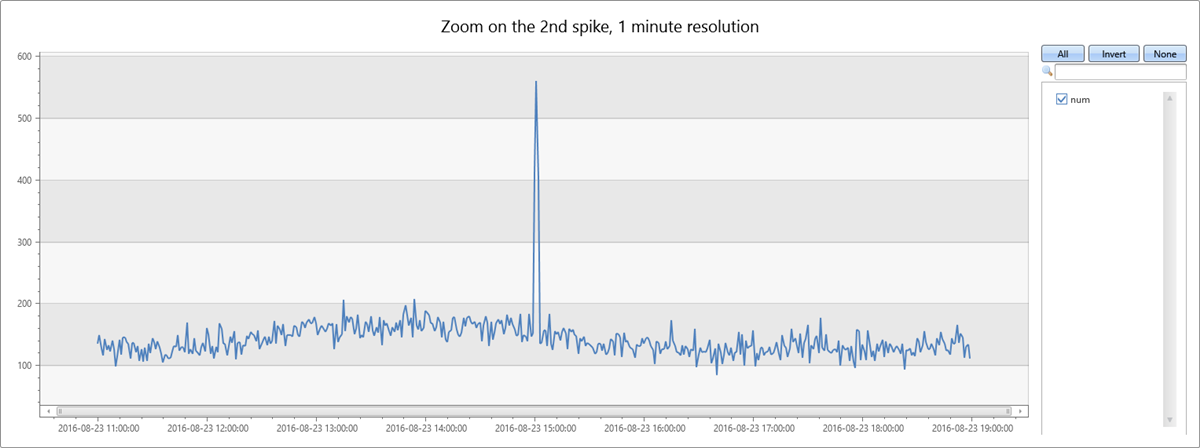
Si osserva un picco stretto di due minuti dalle 15:00 alle 15:02. Nella query seguente, conta le eccezioni in un intervallo di due minuti:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Conteggio |
|---|
| 972 |
Nella query seguente, seleziona 20 eccezioni su 972.
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | Area geografica | ScaleUnit | ID di distribuzione | Punto di traccia | ServiceHost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scusa | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | scusa | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scusa | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scusa | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scusa | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Anche se sono presenti meno di mille eccezioni, è comunque difficile trovare segmenti comuni, poiché in ogni colonna sono presenti più valori. È possibile usare il plug-in autocluster() per estrarre immediatamente un breve elenco di segmenti comuni e trovare i cluster interessanti entro i due minuti del picco, come illustrato nella query seguente:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| ID segmento | Conteggio | Percento | Area geografica | ScaleUnit | ID di distribuzione | ServiceHost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scusa | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5,65843621399177 | Ueo | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
Dai risultati precedenti è possibile osservare che il segmento più dominante contiene 65,74% dei record di eccezione totali e condivide quattro dimensioni. Il segmento successivo è molto meno comune. Contiene solo 9,67% dei record e condivide tre dimensioni. Gli altri segmenti sono ancora meno comuni.
Autocluster usa un algoritmo proprietario per il data mining di più dimensioni e l'estrazione di segmenti interessanti. "Interessante" significa che ogni segmento ha una copertura significativa sia del set di record che del set di funzionalità. Anche i segmenti sono divergenti, vale a dire che ognuno è diverso dagli altri. Uno o più di questi segmenti potrebbero essere rilevanti per il processo RCA. Per ridurre al minimo la revisione e la valutazione dei segmenti, il cluster automatico estrae solo un elenco di segmenti di piccole dimensioni.
È anche possibile usare il plug-in basket() come illustrato nella query seguente:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| ID segmento | Conteggio | Percento | Area geografica | ScaleUnit | ID di distribuzione | Punto di traccia | ServiceHost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scusa | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scusa | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scusa | ||||
| 9 | 55 | 5,65843621399177 | Ueo | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9,25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Basket implementa l'algoritmo "Apriori" per il data mining del set di elementi. Estrae tutti i segmenti la cui copertura del set di record è superiore a una soglia (valore predefinito 5%). È possibile notare che più segmenti sono stati estratti con segmenti simili, ad esempio segmenti 0, 1 o 2, 3.
Entrambi i plug-in sono potenti e facili da usare. La limitazione è che raggruppano un singolo set di record in modo non supervisionato senza etichette. Non è chiaro se i modelli estratti caratterizzano il set di record selezionato, i record anomali o il set di record globale.
Clustering della differenza tra due insiemi di record
Il plug-in diffpatterns() supera la limitazione di autocluster e basket.
Diffpatterns accetta due set di record ed estrae i segmenti principali che differiscono. Un set contiene in genere il set di record anomalo da analizzare. Uno viene analizzato da autocluster e basket. L'altro set contiene il set di record di riferimento, la linea di base.
Nella query seguente, diffpatterns trova cluster interessanti nei due minuti del picco, che sono diversi dai cluster all'interno della linea di base. La finestra di base viene definita come l'otto minuti prima delle 15:00, all'avvio del picco. Si estende con una colonna binaria (AB) e si specifica se un record specifico appartiene all'insieme di base o a quello anomalo.
Diffpatterns implementa un algoritmo di apprendimento supervisionato, in cui le due etichette di classe erano derivate dal confronto tra il flag di anomalia e il flag di base (AB).
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| ID segmento | CountA | ConteggioB | PercentA | Percentuale B | DifferenzaPercentualeAB | Area geografica | ScaleUnit | ID di distribuzione | Punto di traccia |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 | 65.74 | 1.7 | 64.04 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | scusa | |||
| 2 | 92 | 356 | 9.47 | 28.9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25.81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5,66 | 20.45 | 14.8 | Ueo | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
Il segmento più dominante è lo stesso segmento estratto da autocluster. La copertura relativa alla finestra anomala di due minuti è pari a 65,74%. Tuttavia, la copertura nella finestra temporale di otto minuti è solo 1,7%. La differenza è 64.04%. Questa differenza sembra essere correlata al picco anomalo. Per verificare questo presupposto, la query seguente suddivide il grafico originale nei record che appartengono a questo segmento problematico e i record degli altri segmenti.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart

Questo grafico ci consente di vedere che il picco del martedì pomeriggio era dovuto a eccezioni di questo segmento specifico, scoperto usando il plug-in diffpatterns .
Riassunto
I plug-in di Machine Learning sono utili per molti scenari. E autoclusterbasket implementano un algoritmo di apprendimento non supervisionato e sono facili da usare.
Diffpatterns implementa un algoritmo di apprendimento supervisionato e, sebbene più complesso, è più potente per estrarre segmenti di differenziazione per RCA.
Questi plug-in vengono usati in modo interattivo in scenari ad hoc e in servizi di monitoraggio quasi in tempo reale automatici. Il rilevamento anomalie delle serie temporali è seguito da un processo di diagnosi. Il processo è altamente ottimizzato per soddisfare gli standard di prestazioni necessari.