Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La replica dell'area di lavoro di Log Analytics tra aree migliora la resilienza consentendo di passare all'area di lavoro replicata e continuare le operazioni in caso di errore a livello di area. Questo articolo illustra il funzionamento della replica dell'area di lavoro di Log Analytics, come replicare l'area di lavoro, come passare e tornare indietro e decidere quando passare da un'area di lavoro replicata all'altra.
Ecco un video che offre una rapida panoramica del funzionamento della replica dell'area di lavoro di Log Analytics:
Importante
Anche se a volte si usa il termine failover, ad esempio nella chiamata API, il failover viene comunemente usato anche per descrivere un processo automatico. Di conseguenza, questo articolo usa il termine switchover per sottolineare che il passaggio all'area di lavoro replicata è un'azione attivata manualmente.
Funzionamento della replica dell'area di lavoro Log Analytics
L'area di lavoro e l'area originali sono denominate primarie. L'area di lavoro replicata e l'area alternativa sono denominate secondarie.
Il processo di replica dell'area di lavoro crea un'istanza dell'area di lavoro nell'area secondaria. Il processo crea l'area di lavoro secondaria con la stessa configurazione dell'area di lavoro primaria e Monitoraggio di Azure aggiorna automaticamente l'area di lavoro secondaria con eventuali modifiche future apportate alla configurazione dell'area di lavoro primaria.
L'area di lavoro secondaria è un'area di lavoro "shadow" solo a scopo di resilienza. Non è possibile visualizzare l'area di lavoro secondaria nel portale di Azure e non è possibile gestirla o accedervi direttamente.
Quando si abilita la replica dell'area di lavoro, Monitoraggio di Azure invia nuovi log inseriti all'area di lavoro primaria anche all'area secondaria. I log inseriti nell'area di lavoro prima di abilitare la replica dell'area di lavoro non vengono copiati.
Nota
La replica dell'area di lavoro replica completamente tutti gli schemi di tabella, ma invia solo nuovi log inseriti dopo l'attivazione della replica. I log inseriti nell'area di lavoro prima di abilitare la replica dell'area di lavoro non vengono copiati.
Se un'interruzione influisce sull'area primaria, è possibile passare e reindirizzare tutte le richieste di inserimento e query all'area secondaria. Dopo che Azure riduce l'interruzione e l'area di lavoro primaria è nuovamente integra, è possibile tornare all'area primaria.
Quando si passa, l'area di lavoro secondaria diventa attiva e il database primario diventa inattivo. Monitoraggio di Azure inserisce quindi nuovi dati tramite la pipeline di inserimento nell'area secondaria anziché nell'area primaria. Quando si passa all'area secondaria, Monitoraggio di Azure replica tutti i dati inseriti dall'area secondaria all'area primaria. Il processo è asincrono e non influisce sulla latenza di inserimento.
Nota
Dopo il passaggio all'area secondaria, se l'area primaria non è in grado di elaborare i dati di log in ingresso, Monitoraggio di Azure memorizza i dati nell'area secondaria per un massimo di 11 giorni. Durante i primi quattro giorni, Monitoraggio di Azure ripete automaticamente la replica dei dati periodicamente.

Protezione dalla perdita di dati in transito durante un errore a livello di area
Azure Monitor offre diversi meccanismi per garantire che i dati in transito non vengano persi quando si verifica un errore nella regione primaria.
Monitoraggio di Azure protegge i dati che raggiungono l'endpoint di inserimento dell'area primaria quando la pipeline dell'area primaria non è disponibile per elaborare i dati. Quando la pipeline diventa disponibile, continua a elaborare i dati in transito e Monitoraggio di Azure inserisce e replica i dati nell'area secondaria.
Se l'endpoint di inserimento dell'area primaria non è disponibile, l'agente di Monitoraggio di Azure ripete regolarmente l'invio di dati di log all'endpoint. L'endpoint di inserimento dati nell'area secondaria inizia a ricevere i dati dagli agenti pochi minuti dopo l'attivazione del passaggio.
Se si scrive un client personalizzato per inviare dati di log all'area di lavoro Log Analytics, assicurarsi che il client gestisca le richieste di inserimento non riuscite.
Considerazioni sulla distribuzione
Nota
La replica dell'area di lavoro attualmente non supporta la replica di tabelle ausiliarie e non deve essere abilitata nelle aree di lavoro che includono tabelle ausiliarie. Le tabelle ausiliarie non vengono replicate e pertanto non sono protette dalla perdita di dati in caso di errore a livello di area e non sono disponibili quando si passa all'area di lavoro secondaria.
Le operazioni di gestione dell'area di lavoro non possono essere avviate durante il passaggio, tra cui:
- Modifica della conservazione dell'area di lavoro, del piano tariffario, del limite giornaliero e così via
- Modifica delle impostazioni di rete
- Modifica dello schema tramite nuovi log personalizzati o connessione dei log della piattaforma da nuovi provider di risorse, ad esempio l'invio di log di diagnostica da un nuovo tipo di risorsa
Il processo di failover aggiorna i record DNS (Domain Name System) per reindirizzare tutte le richieste di inserimento all'area secondaria per l'elaborazione. Alcuni client HTTP hanno "connessioni permanenti" e potrebbero richiedere più tempo per la ricezione degli aggiornamenti DNS. Durante il passaggio, questi client potrebbero tentare di inserire i log nell'area primaria per un certo periodo di tempo. È possibile inserire log nell'area di lavoro primaria usando vari client, tra cui l'agente di Log Analytics legacy, l'agente di Monitoraggio di Azure, il codice (usando l'API di inserimento log o l'API di raccolta dati HTTP legacy) e altri servizi, ad esempio Microsoft Sentinel.
Importante
Le regole di avviso per la ricerca nei log continuano a funzionare quando si passa da una regione all'altra, a meno che il servizio Avvisi nella regione attiva non funzioni correttamente o che le regole di avviso non siano disponibili. Ciò può verificarsi, ad esempio, se la regione in cui sono state create le regole di avviso è completamente non funzionante. La replica delle regole di avviso tra aree non viene eseguita automaticamente come parte della replica dell'area di lavoro, ma può essere eseguita dall'utente, ad esempio esportando dall'area primaria e importando nel database secondario.
L'operazione di eliminazione, che elimina i record da un'area di lavoro, rimuove i record pertinenti dalle aree di lavoro primarie e secondarie. Se una delle istanze dell'area di lavoro non è disponibile, l'operazione di eliminazione ha esito negativo.
Microsoft Sentinel aggiorna i log nelle tabelle Watchlist e Threat Intelligence ogni 12 giorni. Pertanto, poiché solo i nuovi log vengono inseriti nell'area di lavoro replicata, possono essere necessari fino a 12 giorni per replicare completamente i dati Watchlist e Threat Intelligence nella posizione secondaria.
La funzionalità di destinazione della soluzione dell'agente di Log Analytics legacy non è supportata durante il passaggio. Durante il passaggio, i dati della soluzione vengono inseriti da tutti gli agenti.
Queste funzionalità attualmente non sono supportate o sono supportate solo parzialmente:
Funzionalità Supporto tecnico Piani tabella ausiliari Non supportato. Monitoraggio di Azure non replica i dati nelle tabelle con il piano di log ausiliario nell'area di lavoro secondaria. Pertanto, questi dati non sono protetti dalla perdita di dati in caso di errori regionali e non sono disponibili quando si passa all'area di lavoro secondaria. Processi di ricerca, Ripristino Parzialmente supportato: le operazioni di ricerca e ripristino creano tabelle e le popolano con i risultati della ricerca o i dati ripristinati. Dopo aver abilitato la replica dell'area di lavoro, le nuove tabelle create per queste operazioni vengono replicate nell'area di lavoro secondaria. Le tabelle popolate prima di abilitare la replica non vengono replicate. Se queste operazioni sono in corso quando si passa, il risultato è imprevisto. Il completamento potrebbe essere completato ma non replicato oppure potrebbe non riuscire, a seconda dell'integrità dell'area di lavoro e della tempistica esatta. Application Insights sulle aree di lavoro di Log Analytics Non supportato Informazioni dettagliate macchina virtuale Non supportato Informazioni dettagliate contenitore Non supportato Collegamenti privati Non supportato durante il failover
Aree geografiche supportate
La replica dell'area di lavoro è attualmente supportata per le aree di lavoro in un set limitato di aree, organizzate per gruppi di aree (gruppi di aree geograficamente adiacenti). Quando si abilita la replica, selezionare una località secondaria dall'elenco delle aree supportate nello stesso gruppo di aree del percorso primario dell'area di lavoro. Ad esempio, un'area di lavoro in Europa occidentale può essere replicata in Europa settentrionale, ma non negli Stati Uniti occidentali 2, poiché queste aree si trovano in gruppi di aree diverse.
Attualmente sono supportati i gruppi di aree e le aree seguenti:
| Gruppo di regioni | Aree primarie | Aree secondarie (posizioni di replica) |
|---|---|---|
| America del Nord | Canada centrale Canada orientale Stati Uniti centrali Stati Uniti orientali* Stati Uniti orientali 2* Stati Uniti centro-settentrionali Stati Uniti centro-meridionali* Stati Uniti centro-occidentali Stati Uniti occidentali Stati Uniti occidentali 2 Stati Uniti occidentali 3 |
Canada centrale Stati Uniti centrali Stati Uniti orientali* Stati Uniti orientali 2* Stati Uniti occidentali West US 2 (Regione Ovest degli Stati Uniti 2) |
| America del Sud | Brasile sud Brasile meridionale |
Brasile sud Brasile meridionale |
| Europa | Francia centrale Francia meridionale Germania settentrionale Germania centro-occidentale Italia settentrionale Europa settentrionale Norvegia orientale Norvegia occidentale Polonia centrale Regno Unito meridionale Spagna centrale Svezia centrale Svezia meridionale Svizzera settentrionale Svizzera occidentale Europa occidentale Regno Unito occidentale |
Francia centrale Europa settentrionale Regno Unito meridionale Europa occidentale |
| Medio Oriente | Qatar centrale Emirati Arabi Uniti centrali Emirati Arabi Uniti settentrionali |
Qatar centrale Emirati Arabi Uniti centrali Emirati Arabi Uniti settentrionali |
| India | India centrale India meridionale |
India centrale India meridionale |
| Asia Pacifico | Asia orientale Giappone orientale Giappone occidentale Corea centrale Corea del Sud Sud-est asiatico |
Asia orientale Giappone orientale Corea centrale |
| Oceania | Australia centrale Australia centrale 2 Australia orientale Australia sud-orientale |
Australia centrale Australia orientale Australia sud-orientale |
| Africa | Sudafrica settentrionale Sudafrica occidentale |
Sudafrica settentrionale Sudafrica occidentale |
Nota
Le aree di lavoro che si trovano negli Stati Uniti orientali, negli Stati Uniti orientali 2 e negli Stati Uniti centro-meridionali possono essere replicate solo nelle aree secondarie al di fuori di tale set di tre. Selezionare un'altra località secondaria dal gruppo area America del Nord.
Requisiti di residenza dei dati
Diversi clienti hanno requisiti di residenza dei dati diversi, quindi è importante controllare dove vengono archiviati i dati. Monitoraggio di Azure elabora e archivia i log nelle aree primarie e secondarie scelte. Per altre informazioni, vedere Aree supportate.
Supporto per Microsoft Sentinel e altri servizi
Vari servizi e funzionalità che usano le aree di lavoro di Log Analytics sono compatibili con la replica e il passaggio all'area di lavoro. Questi servizi e funzionalità continuano a funzionare quando si passa all'area di lavoro secondaria.
Ad esempio, i problemi di rete a livello di area che causano la latenza di inserimento dei log possono influire sui clienti di Microsoft Sentinel. I clienti che usano aree di lavoro replicate possono passare all'area secondaria per continuare a usare l'area di lavoro di Log Analytics e Sentinel. Tuttavia, se il problema di rete influisce sull'integrità del servizio Sentinel, il passaggio a un'altra area non riduce il problema.
Alcune esperienze di Monitoraggio di Azure, tra cui Application Insights e Informazioni dettagliate macchina virtuale, sono attualmente compatibili solo parzialmente con la replica e il passaggio all'area di lavoro. Per l'elenco completo, vedere Considerazioni sulla distribuzione.
Modello di determinazione prezzi
Quando si abilita la replica dell'area di lavoro, vengono addebitati i costi per la replica di tutti i dati inseriti nell'area di lavoro.
Importante
Se si inviano dati all'area di lavoro usando l'agente di Monitoraggio di Azure, l'API di inserimento log, Hub eventi di Azure o altre origini dati che usano regole di raccolta dati, assicurarsi di associare le regole di raccolta dati all'endpoint di raccolta dati dell'area di lavoro. Questa associazione garantisce che i dati inseriti vengano replicati nell'area di lavoro secondaria. Se non si associano le regole di raccolta dati all'endpoint di raccolta dati dell'area di lavoro, vengono comunque addebitati tutti i dati inseriti nell'area di lavoro, anche se i dati non vengono replicati.
Autorizzazioni obbligatorie
| Azione | Autorizzazioni obbligatorie |
|---|---|
| Abilita replica dell'area di lavoro | Le autorizzazioni Microsoft.OperationalInsights/workspaces/write e Microsoft.Insights/dataCollectionEndpoints/write, come specificato dal ruolo predefinito Collaboratore per il monitoraggio, ad esempio |
| Passare e tornare indietro (failover e failback del trigger) |
Microsoft.OperationalInsights/locations/workspaces/failover, Microsoft.OperationalInsights/workspaces/failback, Microsoft.Insights/dataCollectionEndpoints/triggerFailover/actione Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action le autorizzazioni, come fornito dal ruolo predefinito Collaboratore monitoraggio, ad esempio |
| Controllare lo stato dell'area di lavoro | Le autorizzazioni Microsoft.OperationalInsights/workspaces/read per l'area di lavoro Log Analytics fornite dal ruolo predefinito Collaboratore per il monitoraggio, ad esempio |
Abilitare e disabilitare la replica dell'area di lavoro
Per abilitare e disabilitare la replica dell'area di lavoro, usare un comando REST. Il comando attiva un'operazione a esecuzione prolungata, il che significa che l'applicazione delle nuove impostazioni può richiedere alcuni minuti. Dopo aver abilitato la replica, possono essere necessarie fino a un'ora prima che tutte le tabelle (tipi di dati) inizino la replica e alcuni tipi di dati potrebbero iniziare a replicare prima di altri. Le modifiche apportate agli schemi di tabella dopo l'abilitazione della replica dell'area di lavoro, ad esempio nuove tabelle di log personalizzate o campi personalizzati creati o i log di diagnostica configurati per i nuovi tipi di risorse, possono richiedere fino a un'ora per avviare la replica.
Uso di un cluster dedicato?
Se l'area di lavoro è collegata a un cluster dedicato, è prima necessario abilitare la replica nel cluster e solo nell'area di lavoro. Questa operazione crea un secondo cluster nell'area secondaria (senza costi aggiuntivi oltre gli addebiti per la replica), per consentire all'area di lavoro di continuare a usare un cluster dedicato anche se si esegue il failover. Ciò significa anche che le funzionalità come le chiavi gestite dal cluster continuano a funzionare (con la stessa chiave) durante il failover. Dopo aver abilitato la replica tra aree, procedere con l'abilitazione della replica per una o più aree di lavoro collegate a questo cluster.
Importante
Dopo aver abilitato la replica del cluster, modificare la destinazione della replica richiede di disabilitare la replica e riabilitarla per una nuova destinazione.
Per abilitare la replica nel cluster dedicato, usare il comando PUT seguente. Questa chiamata restituisce 202. Si tratta di un'operazione a esecuzione prolungata che può richiedere tempo per il completamento ed è possibile tenere traccia dello stato esatto come illustrato in Controllare lo stato del provisioning del cluster.
Per abilitare la replica del cluster, usare questo PUT comando:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/clusters/<cluster_name>?api-version=2025-02-01
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Dove:
-
<subscription_id>: ID sottoscrizione correlato al cluster. -
<resourcegroup_name>: gruppo di risorse che contiene la risorsa cluster di Log Analytics. -
<cluster_name>: nome del cluster dedicato. -
<primary_region>: l'area primaria per il cluster dedicato di Log Analytics. -
<secondary_region>: l'area in cui Azure Monitor crea il cluster dedicato secondario.
Controllare lo stato del provisioning del cluster
Per controllare lo stato di provisioning del cluster, eseguire questo GET comando:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/clusters/<cluster_name>?api-version=2025-02-01
Dove:
-
<subscription_id>: ID sottoscrizione correlato al cluster. -
<resourcegroup_name>: gruppo di risorse che contiene la risorsa cluster di Log Analytics. -
<cluster_name>: nome del cluster di Log Analytics.
Usare il GET comando per verificare che lo stato di provisioning del cluster cambi da Updating a Succeedede che l'area secondaria sia impostata come previsto.
Nota
Quando si abilita la replica del cluster, viene effettuato il provisioning di un nuovo cluster nella posizione secondaria. Questo processo può richiedere 1-2 ore.
Abilita replica dell'area di lavoro
Per abilitare la replica nell'area di lavoro di Log Analytics, usare questo comando PUT:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2025-02-01
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Dove:
-
<subscription_id>: ID sottoscrizione correlato all'area di lavoro. -
<resourcegroup_name>: il gruppo di risorse che contiene la risorsa dell'area di lavoro di Log Analytics. -
<workspace_name>: il nome dell'area di lavoro. -
<primary_region>: l'area primaria per l'area di lavoro di Log Analytics. -
<secondary_region>: l'area in cui Monitoraggio di Azure crea l'area di lavoro secondaria.
Per i valori location supportati, vedere Aree supportate.
Il comando PUT è un'operazione a esecuzione prolungata che può richiedere del tempo. Una chiamata con esito positivo restituisce un codice di stato 200. È possibile tenere traccia dello stato di provisioning della richiesta, come descritto in Controllare lo stato del provisioning dell'area di lavoro.
Importante
Se l'area di lavoro è collegata a un cluster dedicato, abilitare prima la replica nel cluster. Si noti anche che la posizione secondaria dell'area di lavoro deve essere identica alla posizione secondaria del cluster dedicato.
Controllare lo stato del provisioning dell'area di lavoro
Per controllare lo stato di provisioning dell'area di lavoro, eseguire questo GET comando:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2025-02-01
Dove:
-
<subscription_id>: ID sottoscrizione correlato all'area di lavoro. -
<resourcegroup_name>: il gruppo di risorse che contiene la risorsa dell'area di lavoro di Log Analytics. -
<workspace_name>: il nome dell'area di lavoro di Log Analytics.
Usare il comando GET per verificare che lo stato di provisioning dell'area di lavoro cambi da Updating a Succeeded e che l'area secondaria sia impostata come previsto.
Nota
Quando si abilita la replica per le aree di lavoro che interagiscono con Sentinel, possono essere necessari fino a 12 giorni per replicare completamente i dati Watchlist e Threat Intelligence nell'area di lavoro secondaria.
Associare le regole di raccolta dati all'endpoint di raccolta dati dell'area di lavoro
Agente di Monitoraggio di Azure, API di inserimento log e Hub eventi di Azure raccogliere i dati e inviarli alla destinazione specificata in base alla configurazione delle regole di raccolta dati.
Se sono presenti regole di raccolta dati che inviano dati all'area di lavoro primaria, è necessario associare le regole a un endpoint di raccolta dati di sistema (DCE),creato da Monitoraggio di Azure quando si abilita la replica dell'area di lavoro. Il nome dell'endpoint di raccolta dati dell'area di lavoro è identico all'ID dell'area di lavoro. Solo le regole di raccolta dati associate all'endpoint di raccolta dati dell'area di lavoro consentono la replica e il passaggio. Questo comportamento consente di specificare il set di flussi di log da replicare, che consente di controllare i costi di replica.
Per replicare i dati raccolti usando le regole di raccolta dati, associare le regole di raccolta dati all'endpoint di raccolta dati dell'area di lavoro:
Nel portale di Azure selezionare Regole di raccolta dati.
Nella schermata Regole di raccolta dati selezionare una regola di raccolta dati che invia dati all'area di lavoro di Log Analytics primaria.
Nella pagina Panoramica della regola di raccolta dati selezionare Configura DCE e selezionare l'endpoint di raccolta dati dell'area di lavoro nell'elenco disponibile:
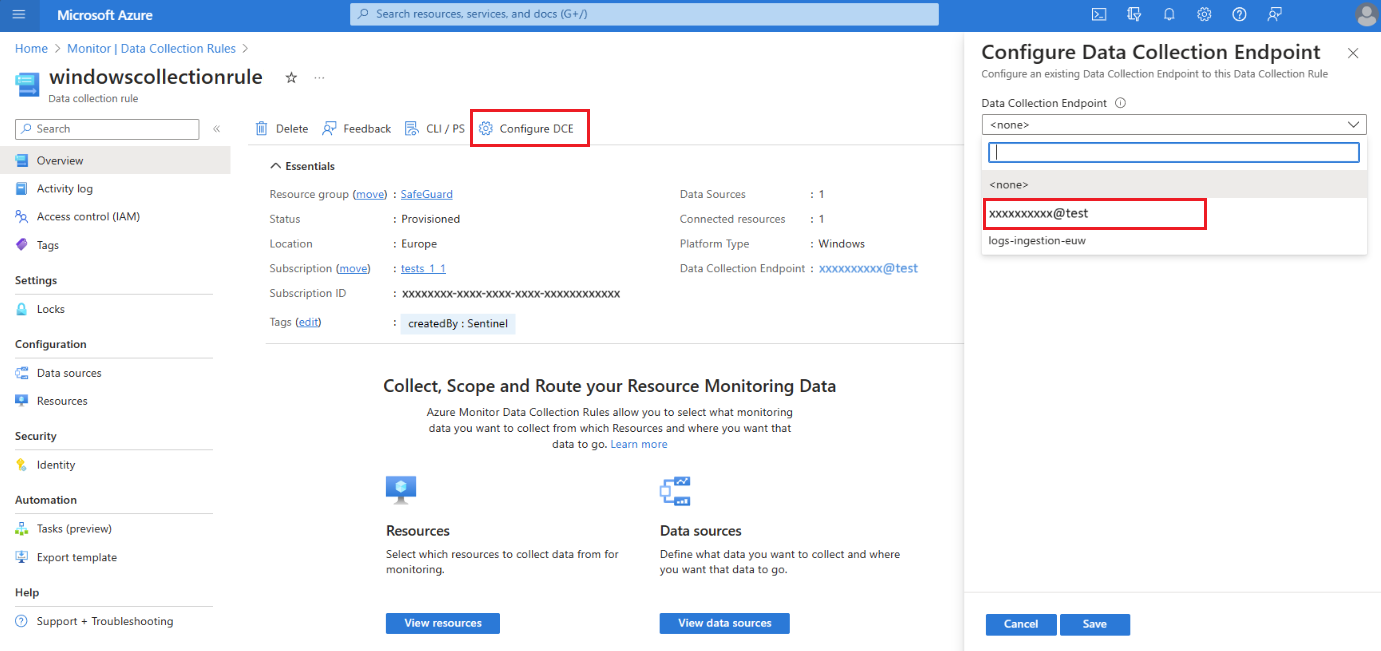
Per informazioni dettagliate sul DCE di sistema, verificare le proprietà dell'oggetto dell'area di lavoro.

Importante
Le regole di raccolta dati connesse a un endpoint di raccolta dati dell'area di lavoro possono essere destinate solo a tale area di lavoro specifica. Le regole di raccolta dati non devono essere destinate ad altre destinazioni, ad esempio altre aree di lavoro o account di Archiviazione di Azure.
Cosa verificare se la replica dell'area di lavoro non riesce
- L'area di lavoro è collegata a un cluster dedicato?
- La replica deve essere abilitata nel cluster prima di poter essere abilitata nell'area di lavoro.
- La replica del cluster e dell'area di lavoro deve essere impostata sulla stessa posizione secondaria. Ad esempio, se il cluster viene replicato in Europa settentrionale, le aree di lavoro collegate possono essere replicate solo in Europa settentrionale.
- L'API REST è stata usata per abilitare la replica?
- Verificare che sia stata usata l'API versione 2025-02-01 o successiva.
- L'area di lavoro primaria si trova in Stati Uniti orientali, Stati Uniti orientali 2 o Stati Uniti centro-meridionali?
- Stati Uniti orientali, Stati Uniti orientali 2 e Stati Uniti centro-meridionali non possono essere replicati tra loro.
- Dove si trova l'area di lavoro primaria e dove si trova l'area di lavoro secondaria? Entrambe le posizioni devono trovarsi nello stesso gruppo di aree. Ad esempio, le aree di lavoro situate nelle aree degli Stati Uniti non possono avere una replica (area secondaria) in Europa e viceversa. Per l'elenco dei gruppi di aree, vedere Aree supportate.
- Si dispone delle autorizzazioni necessarie?
- Hai concesso tempo sufficiente per il completamento dell'operazione di replica? La replica è un'operazione a esecuzione prolungata. Monitorare lo stato dell'operazione come illustrato in Controllare lo stato del provisioning dell'area di lavoro.
- Hai provato a riabilitare la replica per poter modificare la posizione secondaria dell'area di lavoro? Per modificare la posizione dell'area di lavoro secondaria, è prima necessario disabilitare la replica dell'area di lavoro, consentire il completamento dell'operazione e quindi solo la replica eseguibile in un'altra posizione secondaria.
Cosa verificare se la replica dell'area di lavoro è impostata ma i log non vengono replicati?
- La replica può richiedere fino a un'ora per iniziare l'applicazione e alcuni tipi di dati possono iniziare a replicare prima di altri.
- I log inseriti nell'area di lavoro prima dell'abilitazione della replica non vengono copiati nell'area di lavoro secondaria. Vengono replicati solo i log inseriti dopo l'abilitazione della replica.
- Se alcuni log vengono replicati e altri no, verificare che tutte le regole di raccolta dati (DCR) che trasmettono i log nell'area di lavoro siano configurate correttamente. Per visualizzare le regole di raccolta dati che riguardano l'area di lavoro, vedere la scheda Raccolta dati in Log Analytics Workspace Insights nel portale di Azure.
Disabilitare la replica dell'area di lavoro
Per disabilitare la replica per un'area di lavoro, usare questo comando PUT:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2025-02-01
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Dove:
-
<subscription_id>: ID sottoscrizione correlato all'area di lavoro. -
<resourcegroup_name>: il gruppo di risorse che contiene la risorsa area di lavoro. -
<workspace_name>: il nome dell'area di lavoro. -
<primary_region>: l'area primaria per l'area di lavoro.
Il comando PUT è un'operazione a esecuzione prolungata che può richiedere del tempo. Una chiamata con esito positivo restituisce un codice di stato 200. È possibile tenere traccia dello stato di provisioning della richiesta, come descritto in Controllare lo stato del provisioning dell'area di lavoro.
Importante
Se si usa un cluster dedicato, è necessario disabilitare la replica del cluster dopo la disabilitazione della replica per ogni area di lavoro collegata a questo cluster.
Disabilitare la replica del cluster
La disabilitazione della replica del cluster può essere eseguita solo dopo la disabilitazione della replica per tutte le aree di lavoro collegate a questo cluster (se abilitata in precedenza).
Per disabilitare la replica per un'area di lavoro, usare questo comando PUT:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/clusters/<cluster_name>?api-version=2025-02-01
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Dove:
-
<subscription_id>: ID sottoscrizione correlato al cluster. -
<resourcegroup_name>: Il gruppo di risorse che contiene la tua risorsa cluster. -
<workspace_name>: nome del cluster. -
<primary_region>: l'area primaria per il cluster.
Il comando PUT è un'operazione a esecuzione prolungata che può richiedere del tempo. Una chiamata con esito positivo restituisce un codice di stato 200. È possibile tenere traccia dello stato di provisioning della richiesta, come descritto in Controllare lo stato del provisioning dell'area di lavoro.
Nota
Dopo aver disabilitato la replica e aver eliminato il cluster replicato, i log replicati vengono eliminati e non sarà possibile accedervi di nuovo. La copia originale della posizione primaria non viene modificata in questo processo.
Importante
Il processo di rimozione della replica del cluster richiede 14 giorni. Se è necessaria una gestione immediata di questo processo, creare una richiesta di supporto di Azure.
Monitorare l'integrità dell'area di lavoro e del servizio
La latenza di inserimento o errori di query sono esempi di problemi che spesso possono essere gestiti eseguendo il failover nell'area secondaria. Tali problemi possono essere rilevati usando le notifiche di integrità dei servizi e le query di log.
Le notifiche sull'integrità dei servizi sono utili per i problemi correlati al servizio. Per identificare i problemi che influisce sull'area di lavoro specifica (e possibilmente non sull'intero servizio), è possibile usare altre misure:
Creare avvisi in base all'integrità delle risorse dell'area di lavoro
Impostare soglie personalizzate per le metriche di integrità dell'area di lavoro
Creare query di monitoraggio personalizzate per fungere da indicatori di integrità personalizzati per l'area di lavoro, come descritto in Monitorare le prestazioni dell'area di lavoro usando le query per:
- Misurare la latenza di inserimento per tabella
- Identificare se l'origine della latenza è costituita dagli agenti di raccolta o dalla pipeline di inserimento
- Monitorare le anomalie del volume di inserimento per tabella e risorsa
- Monitorare la frequenza di riuscita delle query per tabella, utente o risorsa
- Creare avvisi in base alle query
Nota
È anche possibile usare query di log per monitorare l'area di lavoro secondaria, ma tenere presente che la replica dei log viene eseguita nelle operazioni batch. La latenza misurata può variare e non indica alcun problema di integrità con l'area di lavoro secondaria. Per altre informazioni, vedere Controllare l'area di lavoro inattiva.
Passare all'area di lavoro secondaria
Durante il passaggio, la maggior parte delle operazioni funziona come quando si usa l'area di lavoro e l'area primaria. Tuttavia, alcune operazioni hanno un comportamento leggermente diverso o sono bloccate. Per altre informazioni, vedere Considerazioni sulla distribuzione.
Quando dovrei passare?
Si decide quando passare all'area di lavoro secondaria e tornare all'area di lavoro primaria in base alle prestazioni e al monitoraggio dell'integrità in corso e agli standard e ai requisiti di sistema.
Esistono diversi punti da considerare nel piano per il passaggio, come descritto nelle sottosezioni seguenti.
Tipo di problema e ambito
Il processo di commutazione instrada le richieste di inserimento e query all'area secondaria, che in genere ignora qualsiasi componente difettoso che causa latenza o errore nell'area primaria. Di conseguenza, il passaggio al passaggio non è probabilmente utile se:
- Si è verificato un problema tra aree con una risorsa sottostante. Ad esempio, se gli stessi tipi di risorse hanno esito negativo nelle aree primarie e secondarie.
- Si verifica un problema correlato alla gestione dell'area di lavoro, ad esempio la modifica della conservazione dell'area di lavoro. Le operazioni di gestione dell'area di lavoro vengono sempre gestite nell'area primaria. Durante il passaggio, le operazioni di gestione dell'area di lavoro vengono bloccate.
Durata del problema
Il passaggio non è istantaneo. Il processo di reindirizzamento delle richieste si basa sugli aggiornamenti DNS, che alcuni client prelevano entro pochi minuti, mentre altri possono richiedere più tempo. Pertanto, è utile comprendere se il problema può essere risolto entro pochi minuti. Se il problema osservato è coerente o continuo, non attendere il passaggio. Di seguito sono riportati alcuni esempi.
Inserimento: i problemi relativi alla pipeline di inserimento nell'area primaria possono influire sulla replica dei dati nell'area di lavoro secondaria. Durante il passaggio, i log vengono invece inviati alla pipeline di inserimento nell'area secondaria.
Query: se le query nell'area di lavoro primaria hanno esito negativo o si verifica un timeout, gli avvisi di ricerca log possono essere interessati. In questo scenario passare all'area di lavoro secondaria per assicurarsi che tutti gli avvisi vengano attivati correttamente.
Dati dell'area di lavoro secondaria
I log inseriti nell'area di lavoro primaria prima di abilitare la replica non vengono copiati nell'area di lavoro secondaria. Se è stata abilitata la replica dell'area di lavoro tre ore fa e si passa ora all'area di lavoro secondaria, le query possono restituire solo i dati delle ultime tre ore.
Prima di passare da un'area all'altra, l'area di lavoro secondaria deve contenere un volume utile di log. È consigliabile attendere almeno una settimana dopo aver abilitato la replica prima di attivare il passaggio. I sette giorni consentono la disponibilità di dati sufficienti nell'area secondaria.
Cambio di trigger
Prima di passare, verificare che l'operazione di replica dell'area di lavoro sia stata completata correttamente. Il passaggio ha esito positivo solo quando l'area di lavoro secondaria è configurata correttamente.
Per passare all'area di lavoro secondaria, usare questo comando POST:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2025-02-01
Dove:
-
<subscription_id>: ID sottoscrizione correlato all'area di lavoro. -
<resourcegroup_name>: il gruppo di risorse che contiene la risorsa area di lavoro. -
<secondary_region>: l'area a cui passare durante il passaggio. -
<workspace_name>: il nome dell'area di lavoro a cui passare durante il passaggio.
Il comando POST è un'operazione a esecuzione prolungata che può richiedere del tempo. Una chiamata con esito positivo restituisce un codice di stato 202. È possibile tenere traccia dello stato di provisioning della richiesta, come descritto in Controllare lo stato del provisioning dell'area di lavoro.
Cosa verificare se il cambio (failover) ha esito negativo
- L'API REST è stata usata per attivare il passaggio (failover)?
- Verificare che sia stata usata l'API versione 2025-02-01 o successiva.
- Verificare che il percorso secondario specificato nel comando di failover sia il percorso secondario impostato per questa area di lavoro. Queste informazioni sono disponibili nella visualizzazione del portale di Azure dell'area di lavoro e sull'API.
- Il cambio delle regioni richiede un ruolo di Collaboratore Log Analytics nel gruppo di risorse dell'area di lavoro e non solo nell'area di lavoro stessa.
Tornare all'area di lavoro primaria
Il processo di switchback annulla il reindirizzamento delle query e delle richieste di inserimento dei log all'area di lavoro secondaria. Quando si torna indietro, Monitoraggio di Azure torna al routing delle query e delle richieste di inserimento dei log all'area di lavoro primaria.
Quando si passa all'area secondaria, Monitoraggio di Azure replica i log dall'area di lavoro secondaria all'area di lavoro primaria. Se un'interruzione influisce sul processo di inserimento dei log nell'area primaria, è possibile che Monitoraggio di Azure completi l'inserimento dei log replicati nell'area di lavoro primaria.
Quando dovrei tornare indietro?
Esistono diversi punti da considerare nel piano di cambio, come descritto nelle sottosezioni seguenti.
Stato replica log
Prima di tornare indietro, verificare che Monitoraggio di Azure abbia completato la replica di tutti i log inseriti durante il passaggio all'area primaria. Se si torna indietro prima che tutti i log vengano replicati nell'area di lavoro primaria, le query potrebbero restituire risultati parziali fino al completamento dell'inserimento dei log.
È possibile eseguire query sull'area di lavoro primaria nel portale di Azure per l'area inattiva, come descritto in Controllare l'area di lavoro inattiva.
Integrità dell'area di lavoro primaria
Esistono due importanti elementi di integrità da controllare per la preparazione del passaggio all'area di lavoro primaria:
- Verificare che non siano presenti notifiche di integrità dei servizi in sospeso per l'area di lavoro e l'area primaria.
- Verificare che l'area di lavoro primaria inserisca i log e le query di elaborazione come previsto.
Per esempi su come eseguire query sull'area di lavoro primaria quando l'area di lavoro secondaria è attiva e ignorare il reindirizzamento delle richieste all'area di lavoro secondaria, vedere Controllare l'area di lavoro inattiva.
Switchback del trigger
Prima di tornare indietro, verificare l'Integrità dell'area di lavoro primaria e completare la replica dei log.
Il processo di switchback aggiorna i record DNS. Dopo l'aggiornamento dei record DNS, è possibile che tutti i client ricevano le impostazioni DNS aggiornate e riprendano il routing all'area di lavoro primaria.
Per tornare all'area di lavoro primaria, usare questo comando POST:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2025-02-01
Dove:
-
<subscription_id>: ID sottoscrizione correlato all'area di lavoro. -
<resourcegroup_name>: il gruppo di risorse che contiene la risorsa area di lavoro. -
<workspace_name>: il nome dell'area di lavoro a cui passare durante il cambio.
Il comando POST è un'operazione a esecuzione prolungata che può richiedere del tempo. Una chiamata con esito positivo restituisce un codice di stato 202. È possibile tenere traccia dello stato di provisioning della richiesta, come descritto in Controllare lo stato del provisioning dell'area di lavoro.
Controllare l'area di lavoro inattiva
Per impostazione predefinita, l'area attiva dell'area di lavoro è l'area in cui si crea l'area di lavoro e l'area inattiva è l'area secondaria in cui Monitoraggio di Azure crea l'area di lavoro replicata.
Quando si attiva il failover, si verifica un cambio: l’area secondaria viene attivata e l’area primaria diventa inattiva. Si supponga che sia inattiva perché non è la destinazione diretta delle richieste di query e inserimento log.
È utile eseguire una query sull'area inattiva prima di passare da un'area all'altra, per verificare che l'area di lavoro nell'area inattiva contenga i log previsti.
Eseguire query nell'area inattiva
Per eseguire query sui dati di log nell'area inattiva, usare questo comando GET:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Ad esempio, per eseguire una query semplice come Perf | count per il giorno precedente nell'area secondaria, usare:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
È possibile verificare che Monitoraggio di Azure esegua la query nell'area desiderata controllando questi campi nella tabella LAQueryLogs, che viene creata quando si abilita il controllo delle query nell'area di lavoro di Log Analytics:
-
isWorkspaceInFailover: indica se l'area di lavoro era in modalità cambio durante la query. Il tipo di dati è Boolean (True, False). -
workspaceRegion: l'area dell'area di lavoro di destinazione della query. Il tipo di dati è String.
Monitorare le prestazioni dell'area di lavoro usando query
È consigliabile usare le query in questa sezione per creare regole di avviso che segnalano possibili problemi di integrità o prestazioni dell'area di lavoro. Tuttavia, la decisione di passare al passaggio richiede un'attenta considerazione e non deve essere eseguita automaticamente.
Nella regola di query è possibile definire una condizione per passare all'area di lavoro secondaria dopo un numero specificato di violazioni. Per altre informazioni, vedere Creare o modificare una regola di avviso di ricerca log.
Due misurazioni significative delle prestazioni dell'area di lavoro includono la latenza di inserimento e il volume di inserimento. Le sezioni seguenti illustrano queste opzioni di monitoraggio.
Monitorare la latenza di inserimento end-to-end
La latenza di inserimento misura il tempo necessario per inserire i log nell'area di lavoro. La misurazione dell'ora inizia quando si verifica l'evento registrato iniziale e termina quando il log viene archiviato nell'area di lavoro. La latenza totale di inserimento è costituita da due parti:
- Latenza dell'agente: tempo richiesto dall'agente per segnalare un evento.
- Latenza della pipeline di inserimento (back-end): tempo necessario per la pipeline di inserimento per elaborare i log e scriverli nell'area di lavoro.
Tipi di dati diversi hanno una latenza di inserimento diversa. È possibile misurare l'inserimento per ogni tipo di dati separatamente o creare una query generica per tutti i tipi e una query con granularità più fine per tipi specifici di maggiore importanza. È consigliabile misurare il 90° percentile della latenza di inserimento, che è più sensibile alla modifica rispetto alla media o al 50° percentile (mediano).
Le sezioni seguenti illustrano come usare le query per controllare la latenza di inserimento per l'area di lavoro.
Valutare la latenza di inserimento di base di tabelle specifiche
Per iniziare, determinare la latenza di base di tabelle specifiche in diversi giorni.
Questa query di esempio crea un grafico del 90° percentile della latenza di inserimento nella tabella Perf:
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
Dopo aver eseguito la query, esaminare i risultati e il grafico di cui è stato eseguito il rendering per determinare la latenza prevista per tale tabella.
Monitorare e avvisare la latenza di inserimento corrente
Dopo aver stabilito la latenza di inserimento di base per una tabella specifica, creare una regola di avviso di ricerca log per la tabella in base alle modifiche della latenza in un breve periodo di tempo.
Questa query calcola la latenza di inserimento negli ultimi 20 minuti:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Poiché è possibile prevedere alcune fluttuazioni, creare una condizione della regola di avviso per verificare se la query restituisce un valore significativamente maggiore della baseline.
Determinare l'origine della latenza di inserimento
Quando si nota che la latenza totale di inserimento è in corso, è possibile usare query per determinare se l'origine della latenza è costituita dagli agenti o dalla pipeline di inserimento.
Questa query consente di visualizzare separatamente la latenza del 90° percentile degli agenti e della pipeline:
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Nota
Anche se il grafico visualizza i dati del 90° percentile come colonne in pila, la somma dei dati nei due grafici non equivale all'inserimento totale del 90° percentile.
Monitorare il volume di inserimento
Le misurazioni del volume di inserimento consentono di identificare modifiche impreviste al volume di inserimento totale o specifico della tabella per l'area di lavoro. Le misurazioni del volume di query consentono di identificare i problemi di prestazioni con l'inserimento dei log. Alcune misurazioni utili del volume includono:
- Volume di inserimento totale per tabella
- Volume di inserimento costante (standtill)
- Anomalie di inserimento: picchi e cali nel volume di inserimento
Le sezioni seguenti illustrano come usare le query per controllare il volume di inserimento per l'area di lavoro.
Monitorare il volume totale di inserimento per tabella
È possibile definire una query per monitorare il volume di inserimento per tabella nell'area di lavoro. La query può includere un avviso che verifica la presenza di modifiche impreviste ai volumi totali o specifici della tabella.
Questa query calcola il volume di inserimento totale nell'ultima ora per tabella in megabyte al secondo (MB):
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Verificare se l'inserimento è in attesa
Se si inseriscono log tramite agenti, è possibile usare l'heartbeat dell'agente per rilevare la connettività. Un heartbeat ancora può rivelare un arresto nell'inserimento dei log nell'area di lavoro. Quando i dati della query rivelano un'attività di inserimento, è possibile definire una condizione per attivare una risposta desiderata.
La query seguente controlla l'heartbeat dell'agente per rilevare i problemi di connettività:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Monitorare le anomalie di inserimento
È possibile identificare picchi e cali nei dati del volume di inserimento dell'area di lavoro in diversi modi. Usare la funzione series_decompose_anomalies() per estrarre anomalie dai volumi di inserimento monitorati nell'area di lavoro o creare un rilevatore anomalie personalizzato per supportare gli scenari univoci dell'area di lavoro.
Identificare le anomalie usando series_decompose_anomalies
La funzione series_decompose_anomalies() identifica le anomalie in una serie di valori di dati. Questa query calcola il volume di inserimento orario di ogni tabella nell'area di lavoro di Log Analytics e usa series_decompose_anomalies() per identificare le anomalie:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Per altre informazioni su come usare series_decompose_anomalies() per rilevare anomalie nei dati di log, vedere Rilevare e analizzare le anomalie usando le funzionalità di Machine Learning KQL in Monitoraggio di Azure.
Creare un rilevamento anomalie personalizzato
È possibile creare un rilevatore di anomalie personalizzato per supportare i requisiti dello scenario per la configurazione dell'area di lavoro. Questa sezione fornisce un esempio per illustrare il processo.
La query seguente calcola:
- Volume di inserimento previsto: per ora, per tabella (in base al valore mediano dei mediani, ma è possibile personalizzare la logica)
- Volume di inserimento effettivo: per ora, per tabella
Per escludere differenze non significative tra il volume di inserimento previsto e quello effettivo, la query applica due filtri:
- Frequenza di modifica: oltre il 150% o inferiore al 66% del volume previsto, per tabella
- Volume di modifica: indica se il volume aumentato o diminuito è superiore allo 0,1% del volume mensile di tale tabella
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Monitorare l'esito positivo e negativo delle query
Ogni query restituisce un codice di risposta che indica l'esito positivo o negativo. Quando la query non riesce, la risposta include anche i tipi di errore. Un aumento elevato di errori può indicare un problema con la disponibilità dell'area di lavoro o le prestazioni del servizio.
Questa query conta il numero di query restituite da un codice di errore del server:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count